1、为什么Spring和IDEA 都不推荐使用 @Autowired 注解
大家在使用IDEA开发的时候有没有注意到过一个提示,在字段上使用Spring的依赖注入注解@Autowired后会出现如下警告Field injection is not recommended (字段注入是不被推荐的);但是使用@Resource却不会出现此提示,那这是为什么呢??
我们都知道Spring常见的DI方式:
- 构造器注入:利用构造方法的参数注入依赖
- Setter注入:调用Setter的方法注入依赖
- 字段注入:在字段上使用@Autowired/Resource注解
@Autowired VS @Resource
事实上,他们的基本功能都是通过注解实现依赖注入,只不过@Autowired是Spring定义的,而@Resource是JSR-250定义的。大致功能基本相同,但是还有一些细节不同:
- 依赖识别方式:@Autowired默认是byType,可以使用@Qualifier指定Name,@Resource默认ByName,如果找不到则ByType
- 适用对象:@Autowired可以对构造器、方法、参数、字段使用,@Resource只能对方法、字段使用
- 提供方:@Autowired是Spring提供的,@Resource是JSR-250提供的
各种DI方式的优缺点
参考Spring官方文档,建议了如下的使用场景:
- 构造器注入:强依赖性(即必须使用此依赖),不变性(各依赖不会经常变动)
- Setter注入:可选(没有此依赖也可以工作),可变(依赖会经常变动)
- Field注入:大多数情况下尽量少使用字段注入,一定要使用的话,@Resource相对@Autowired对IoC容器的耦合更低
Field注入的缺点
- 不能像构造器那样注入不可变的对象
- 依赖对外部不可见,外界可以看到构造器和setter,但无法看到私有字段,自然无法了解所需依赖
- 会导致组件与IoC容器紧耦合(这是最重要的原因,离开了IoC容器去使用组件,在注入依赖时就会十分困难)
- 导致单元测试也必须使用IoC容器,原因同上
- 依赖过多时不够明显,比如我需要10个依赖,用构造器注入就会显得庞大,这时候应该考虑一下此组件是不是违反了单一职责原则
为什么IDEA只对@Autowired警告
Field注入虽然有很多缺点,但它的好处也不可忽略:那就是太方便了。使用构造器或者setter注入需要写更多业务无关的代码,十分麻烦,而字段注入大幅简化了它们。并且绝大多数情况下业务代码和框架就是强绑定的,完全松耦合只是一件理想上的事,牺牲了敏捷度去过度追求松耦合反而得不偿失。
那么问题来了,为什么IDEA只对@Autowired警告,却对@Resource视而不见呢?
@Autowired是Spring提供的,它是特定IoC提供的特定注解,这就导致了应用与框架的强绑定,一旦换用了其他的IoC框架,是不能够支持注入的。而@Resource是JSR-250提供的,它是Java标准,我们使用的IoC容器应当去兼容它,这样即使更换容器,也可以正常工作。
2、工作中常用Redis的十种场景
Redis是一种优秀的基于键值型的NoSql数据库(非关系型)
这里有两个关键字:
其中键值型,是指Redis中存储的数据都是以key、value对的形式存储,而value的形式多种多样,可以是字符串、数值、甚至json。

而NoSql则是相对于传统关系型数据库而言,有很大差异的一种数据库。
Redis的优点:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
Redis在工作中的应用列举:
1、计数器
在很多网站首页,会有一些统计首页访问次数的需求,访问次数只有一个字段,如果存到关系型数据库中,最后做汇总会很麻烦。该业务场景可以使用Redis,定义一个key,例如:WEBSITE_VISITS_NUM。
在Redis里有命令incr,实现给value值加1操作:
incr WEBSITE_VISITS_NUM
当然如果你想一次加的值大于1,可以用incrby命令,例如:
Incrby WEBSITE_VISITS_NUM 10 一次加10。
2、分布式锁(单线程,数据安全)
最常见应用场景之一,相对于例如Zookeeper分布式锁,Redis的分布式锁,有更好的性能。
代码奉上:
@Api(tags = "Redis")
@RestController
@RequestMapping("/testRedis")
@Slf4j
public class TestRedisController {private static final ThreadFactory THREAD_FACTORY = new ThreadFactoryBuilder().setNamePrefix("shouhu-").setDaemon(true).build();private static final ScheduledExecutorService daemonPool = Executors.newScheduledThreadPool(5,THREAD_FACTORY);@Resourceprivate RedisTemplate<String ,Object> redisTemplate;@GetMapping("/testSetNX")@ApiOperation("SETNX")public ResultVO<Object> testSetNX(@RequestParam Long goodsId){String key = "lock_" + goodsId;String value = UUID.randomUUID().toString();ValueOperations<String, Object> valueOperations = redisTemplate.opsForValue();ScheduledFuture<?> scheduledFuture = null;try {// 加锁Boolean ifAbsent = valueOperations.setIfAbsent(key, value, 30, TimeUnit.SECONDS);log.info("加锁{}返回值:{}",key,ifAbsent);if ((null==ifAbsent) || (!ifAbsent)){log.info("加锁失败,请稍后重试!");return ResultUtils.error("加锁失败,请稍后重试!");}// 模拟看门狗逻辑AtomicInteger count = new AtomicInteger(1);scheduledFuture = daemonPool.scheduleWithFixedDelay(() -> {log.info("看门狗第:{}次执行开始", count.get());Object cache = redisTemplate.opsForValue().get(key);if (Objects.nonNull(cache) && (value.equals(cache.toString()))) {// 重新设置有效时间为30秒redisTemplate.expire(key, 30, TimeUnit.SECONDS);log.info("看门狗第:{}次执行结束,有效时间为:{}", count.get(), redisTemplate.getExpire(key));}else {log.info("看门狗执行第:{}次异常:key:{} 期望值:{} 实际值:{}",count.get(), key, value, cache);}count.incrementAndGet();}, 10, 10, TimeUnit.SECONDS);// 执行业务逻辑TimeUnit.SECONDS.sleep(5);log.info("业务逻辑执行结束");}catch (Exception e){log.error("testSetNX exception:",e);return ResultUtils.sysError();}finally {// 释放锁,判断是否是当前线程加的锁String delVal = valueOperations.get(key).toString();if (value.equals(delVal)){Boolean delete = redisTemplate.delete(key);log.info("释放{}锁结果:{}",key,delete);// 关闭看门狗线程if (Objects.nonNull(scheduledFuture)){boolean cancel = scheduledFuture.cancel(true);log.info("关闭看门狗结果:{}",cancel);}}else {log.info("不予释放,key:{} value:{} delVal:{}",key,value,delVal);}}return ResultUtils.success("success");}}3、缓存加速
这也是工作中非常常用的一种,例如:大宗采购项目中,如果查询检斤化验单数据,先从Redis缓存中查询,如果缓存里存在,则直接拿出数据进行计算,如果不存在,则再去检斤进行查询数据,将数据保存到缓存里。
对于用户而言,下面的流程图也是常见的:
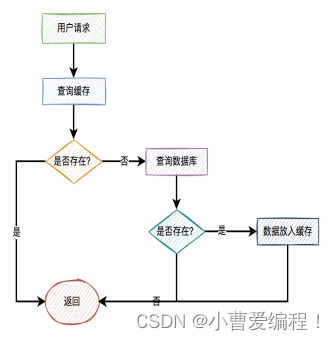
4、交集差集(Redis的无序集合应用)
例如:共同好友、推荐好友功能,我们可以使用到Redis的无序集合,命令如下:
sadd key val val --->添加
sinter key1 key2 ---->交集
sdiff key1 key2 ----->差集5、排行榜(Redis的有序集合应用)
很多网站有排行榜的功能,比如:商城中有商品销量的排行榜,游戏网站有玩家获得积分的排行榜。这种情况下,我们可以使用Sorted Set保存排行榜的数据。使用ZADD可以添加排行榜的数据,使用ZRANGE可以获取排行榜的数据。
ZADD rank:score 100 "张三"
ZADD rank:score 90 "李四"
ZADD rank:score 80 "王五"
ZRANGE rank:score 0 -1 WITHSCORES










创建主界面)
--文本分类任务)






