索引的最左匹配原则
我们先创建一张测试表,表的两个字段用来创建联合索引
CREATE TABLE test(id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,col1 INT,col2 INT,col3 INT
);CREATE INDEX idx_c1c2 ON test(col1, col2);
现在我们就可以分析查询sql脚本了
1.使用联合索引查询

我们发现查询走了联合索引,并且长度为10
2.使用col1查询

我们发现查询走了联合索引,长度为5
3.使用col2查询

我们发现查询走了全表扫描,并且是用的where条件的过滤
为什么会有这种效果产生?
这个时候我们就要去了解一下索引创建的原理了
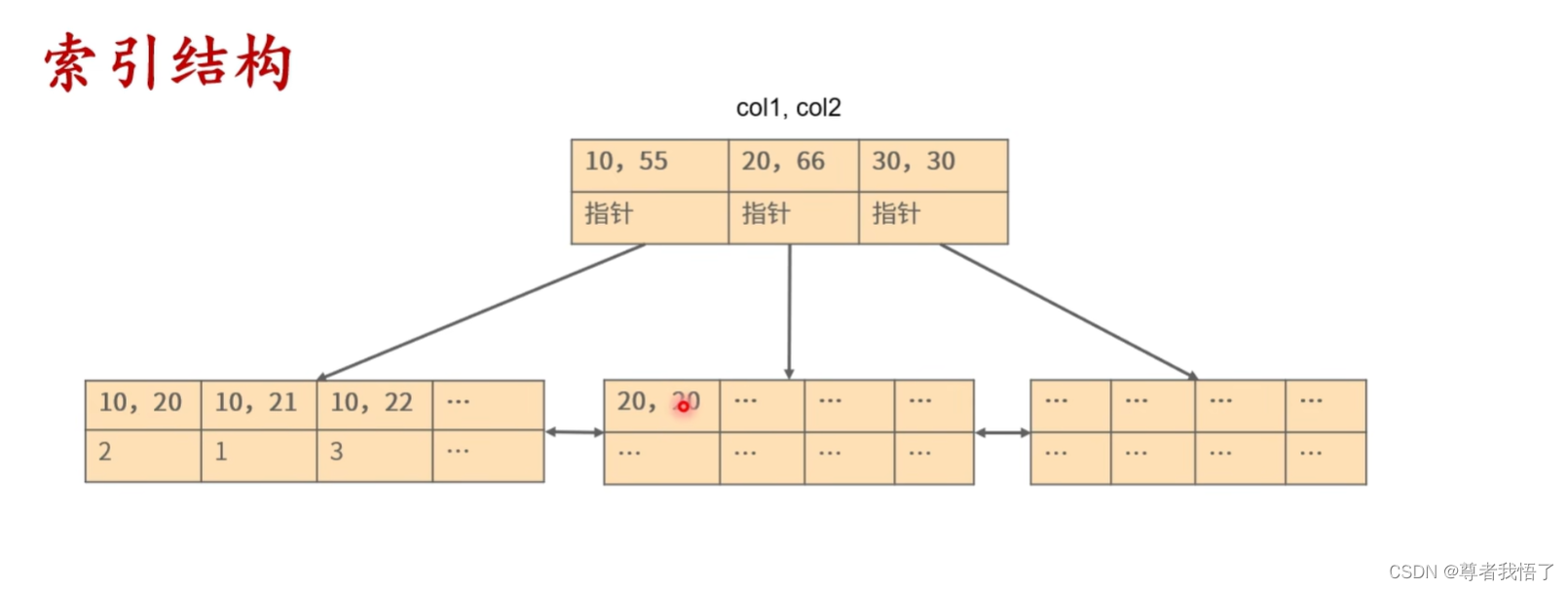
联合索引常见的原理就是叶子节点先按照col1顺序,然后再接上col2,
- 如果我们知道col1和col2的值,那就可以直接找到对应叶子节点的值,例如col1=10,col2=20,就能通过索引直接找到值为2
- 如果我们知道col1的值,不知道col2的值,同样也可以走索引,例如col1=10,那我们只需要在第一个叶子节点便利就行了,所以说走的索引长度会是5
- 如果我们知道col2的值,不知道col1的值,这时不会走索引,例如col1=20,第一个叶子节点可能有col2=20,第二个叶子节点可能有col2=20,第三个叶子节点可能有col2=20,只能全部都扫描一遍,走不到索引
综上所属,正因为联合索引的索引结构是从左到右的结构,当我们在创建联合索引的时候就要考虑那个字段会用来单独查询,那几个字段会用来联合查询,遵循最左匹配原则。





)









)



)