前言
单节点的Elasticsearch需要在处理大量数据的时候需要消耗大量内存和CPU资源,数据量大到一定程度就会产生处理瓶颈,甚至会出现宕机。

为了解决单节点ES的处理能力的瓶颈及单节点故障问题,我们考虑使用Elasticsearch集群。接下来袁老师带领大家学习如何搭建Elasticsearch的集群。
一. 集群的结构
1.单点的问题
单点的Elasticsearch存在哪些可能出现的问题呢?
- 单台机器存储容量有限,无法实现高存储。
- 单服务器容易出现单点故障,无法实现高可用。
- 单服务的并发处理能力有限,无法实现高并发。
所以,为了应对这些问题,我们需要对Elasticsearch搭建集群。
2.数据分片
首先,我们面临的第一个问题就是数据量太大,单点存储量有限的问题。大家觉得应该如何解决?
没错,我们可以把数据拆分成多份,每一份存储到不同机器节点(Node),从而实现减少每个节点数据量的目的。这就是数据的分布式存储,也叫做数据分片(Shard)。
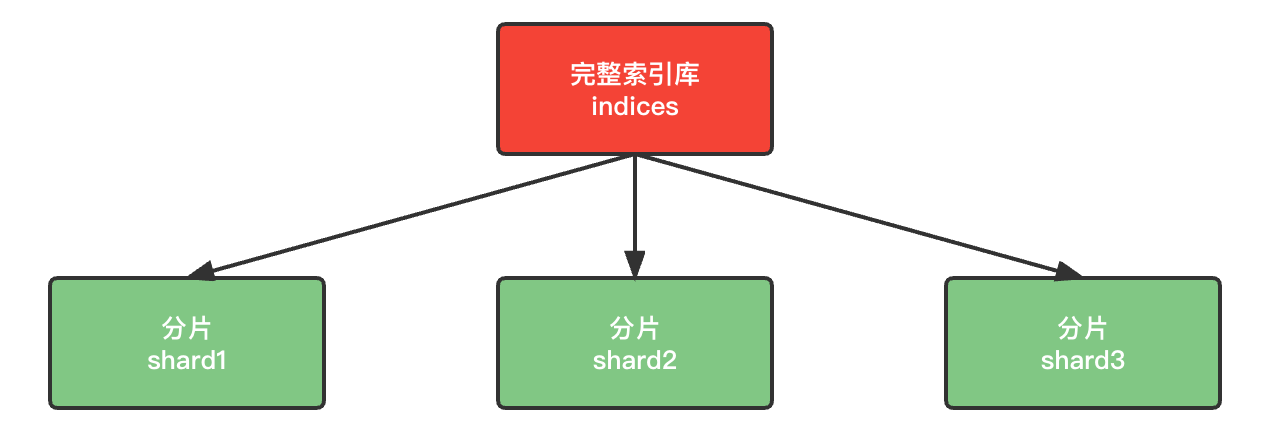
3.数据备份
数据分片解决了海量数据存储的问题,但是如果出现单点故障,那么分片数据就不再完整,这又该如何解决呢?
没错,就像大家为了备份手机数据,会额外存储一份到移动硬盘一样。我们可以给每个分片数据进行备份,存储到其它节点,防止数据丢失,这就是数据备份,也叫数据副本(replica)。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了。为了在高可用和成本间寻求平衡,我们可以这样做:
- 首先对数据分片,存储到不同节点。
- 然后对每个分片进行备份,放到对方节点,完成互相备份。
这样可以大大减少所需要的服务节点数量。如下图我们以3分片,每个分片备份一份为例。
在这个集群中,如果出现单节点故障,并不会导致数据缺失,所以保证了集群的高可用,同时也减少了节点中数据存储量。并且因为是多个节点存储数据,因此用户请求也会分发到不同服务器,并发能力也得到了一定的提升。
二. 搭建集群
1.搭建集群设计
集群需要多台机器,我们这里用一台机器来模拟,因此我们需要在一台虚拟机中部署多个Elasticsearch节点,每个Elasticsearch的端口都必须不一样。
我们将Elasticsearch的安装包解压三份出来,分别修改端口号,修改data和logs存放位置。而实际开发中,将每个Elasticsearch节点放在不同的服务器上。
我们将集群名称设计为yx-elastic,并部署3个Elasticsearch节点。集群环境如下:
| Node Name | Cluster Name | IP | HTTP | TCP |
| node-01 | yx-elastic | 127.0.0.1 | 9201 | 9301 |
| node-02 | yx-elastic | 127.0.0.1 | 9202 | 9302 |
| node-03 | yx-elastic | 127.0.0.1 | 9203 | 9303 |
TCP:集群间的各个节点进行通讯的端口,默认9300。
HTTP:表示使用HTTP协议进行访问时使用的端口(Elasticsearch-head、Kibana、ApiPost),默认端口号是9200。
2.搭建集群实现
1.将elasticsearch-6.2.4.zip压缩包解压三份,分别做以下命名。

2.修改每一个节点config目录下的elasticsearch.yml配置文件。三个节点的配置文件内容几乎一致,除了node.name、path.data、path.log、http.port、transport.tcp.port属性的值。
(1) 配置node-01节点。
# 允许跨域名访问
http.cors.enabled: true
# 当设置允许跨域,默认为*,表示支持所有域名
http.cors.allow-origin: "*"
# 允许所有节点访问
network.host: 0.0.0.0
# 集群的名称,同一个集群下所有节点的集群名称应该一致
cluster.name: yx-elastic
# 当前节点名称 每个节点不一样
node.name: node-01
# 数据的存放路径,每个节点不一样,不同es服务器对应的data和log存储的路径不能一样
path.data: /Users/yuanxin/Documents/ProgramSoftware/es-config/es-9201/data
# 日志的存放路径 每个节点不一样
path.logs: /Users/yuanxin/Documents/ProgramSoftware/es-config/es-9201/logs
# HTTP协议的对外端口,每个节点不一样,默认:9200
http.port: 9201
# TCP协议对外端口 每个节点不一样,默认:9300
transport.tcp.port: 9301
# 三个节点相互发现,包含自己,使用TCP协议的端口号
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
# 声明大于几个的投票主节点有效,请设置为(nodes / 2) + 1
discovery.zen.minimum_master_nodes: 2
# 是否为主节点
node.master: true(2) 配置node-02节点。
# 允许跨域名访问
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 0.0.0.0
# 集群的名称
cluster.name: yx-elastic
# 当前节点名称 每个节点不一样
node.name: node-02
# 数据的存放路径,每个节点不一样
path.data: /Users/yuanxin/Documents/ProgramSoftware/es-config/es-9202/data
# 日志的存放路径,每个节点不一样
path.logs: /Users/yuanxin/Documents/ProgramSoftware/es-config/es-9202/logs
# HTTP协议的对外端口,每个节点不一样
http.port: 9202
# TCP协议对外端口,每个节点不一样
transport.tcp.port: 9302
# 三个节点相互发现
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
# 声明大于几个的投票主节点有效,请设置为(nodes / 2) + 1
discovery.zen.minimum_master_nodes: 2
# 是否为主节点
node.master: true(3) 配置node-03节点。
# 允许跨域名访问
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 0.0.0.0
# 集群的名称
cluster.name: yx-elastic
# 当前节点名称,每个节点不一样
node.name: node-03
# 数据的存放路径,每个节点不一样
path.data: /Users/yuanxin/Documents/ProgramSoftware/es-config/es-9203/data
# 日志的存放路径,每个节点不一样
path.logs: /Users/yuanxin/Documents/ProgramSoftware/es-config/es-9203/logs
# HTTP协议的对外端口,每个节点不一样
http.port: 9203
# TCP协议对外端口,每个节点不一样
transport.tcp.port: 9303
# 三个节点相互发现
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
# 声明大于几个的投票主节点有效,请设置为(nodes / 2) + 1
discovery.zen.minimum_master_nodes: 2
# 是否为主节点
node.master: true3.将下载的elasticsearch-analysis-ik-6.2.4.zip的压缩包解压到集群中每个elasticsearch的plugins目录下,并将解压后的目录重命名成analysis-ik。
4.启动集群。进入elasticsearch安装目录下的bin目录下通过启动文件来启动Elasticsearch。把三个节点分别启动,启动时不要着急,要一个一个地启动。启动Elasticsearch服务即可加载IK分词器。
# Mac系统下启动方式-双击下面的文件运行
./elasticsearch# Windows系统下启动方式-在终端执行下面的文件
elasticsearch.bat三. 测试集群中创建索引库
1.Kibana访问集群
1.进入Kibana安装目录下的config目录,修改kibana.yml文件,添加Elasticsearch服务地址的配置(注释放开即可)。
# url访问的端口修改成9201或9202或9203都可以
elasticsearch.url: "http://localhost:9201"2.进入Kibana安装目录下的bin目录,通过运行启动文件来启动Kibana。前提是先启动Elasticsearch服务集群,再启动Kibana服务。
# Mac系统下启动方式-双击下面的文件运行
./kibana# Windows系统下启动方式-在终端执行下面的文件
kibana.bat3.然后访问Kibana地址http://127.0.0.1:5601,进行集群测试。
2.elasticsearch-head访问集群
1.通过谷歌浏览器打开elasticsearch-head扩展程序。
2.在打开的窗口中输入http://localhost:9201地址(可以是集群中任一一台服务器地址)来查看Elasticsearch集群的启动情况。
3.集群中创建索引库
搭建集群以后就要创建索引库了,那么问题来了,当我们创建一个索引库后,数据会保存到哪个服务节点上呢?如果我们对索引库分片,那么每个片会在哪个节点呢?
3.1.通过Kibana创建索引
通过API创建索引库,设置集群的分片和备份值。示例:
PUT /yx
{"settings": {"number_of_shards": 3,"number_of_replicas": 1}
}这里有两个属性配置:
| 属性 | 描述 |
| number_of_shards | 分片数量,默认值为5;这里设置为3 |
| number_of_replicas | 副本数量,默认值为1;这里设置为1。每个分片一个备份,一个原始数据,共计2份 |
3.2.通过elasticsearch-head创建索引
在elasticsearch-head控制台通过【索引】选项可以新建索引。这个要亲自尝试才知道。

3.3.elasticsearch-head创建索引失败
在通过elasticsearch-head创建索引时,点击新建索引窗口的【OK】按钮,没有任何响应,无法在页面新建索引。针对此问题,打开浏览器控制台,提示“Not Acceptable”错误。

解决方案见下:
1.打开elasticsearch-head安装目录下的vendor.js文件。
2.修改contentType属性的取值。
(1) 找到第6886行代码。
contentType: "application/x-www-form-urlencoded",(2) 将6886行代码改成如下内容。
contentType: "application/json;charset=UTF-8",3.修改s.contentType属性值的比较。
(1) 找到第7573行代码。
var inspectData = s.contentType === "application/x-www-form-urlencoded" &&(2) 将7573行代码改成如下内容。
var inspectData = s.contentType === "application/json;charset=UTF-8" &&4.重新通过elasticsearch-head工具在控制台点击【索引】选项进行新建索引的测试。
3.4.使用elasticsearch-head查看集群
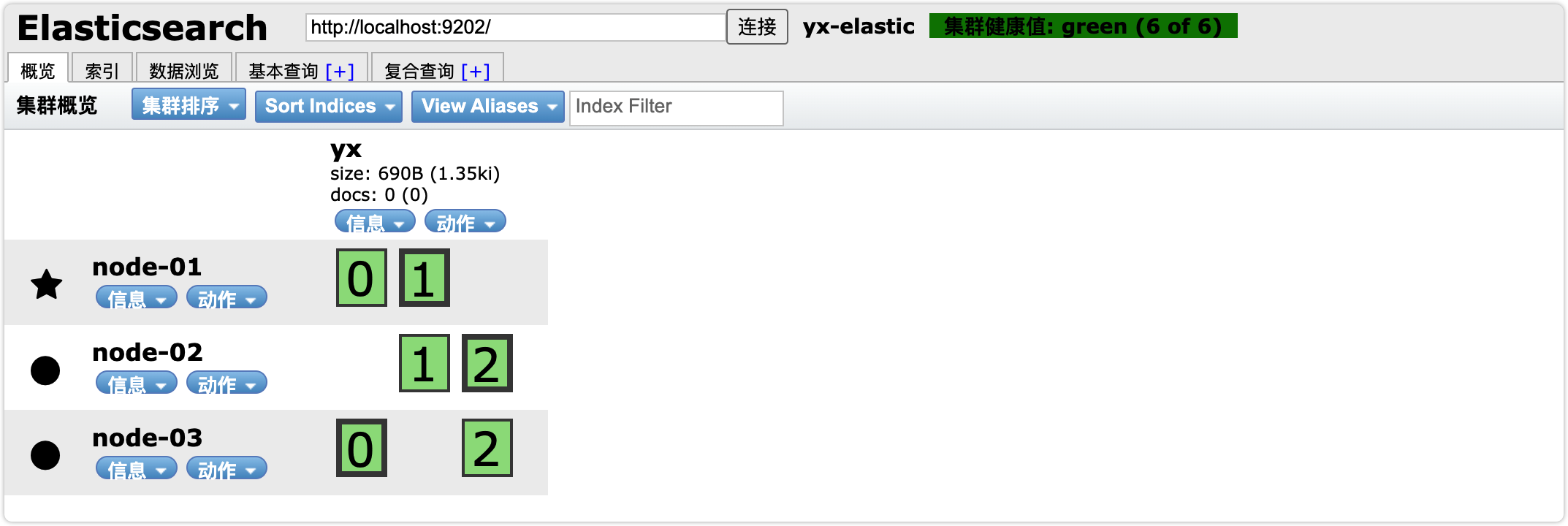
通过Chrome浏览器的elasticsearch-head插件查看索引,我们可以查看到分片的存储结构:
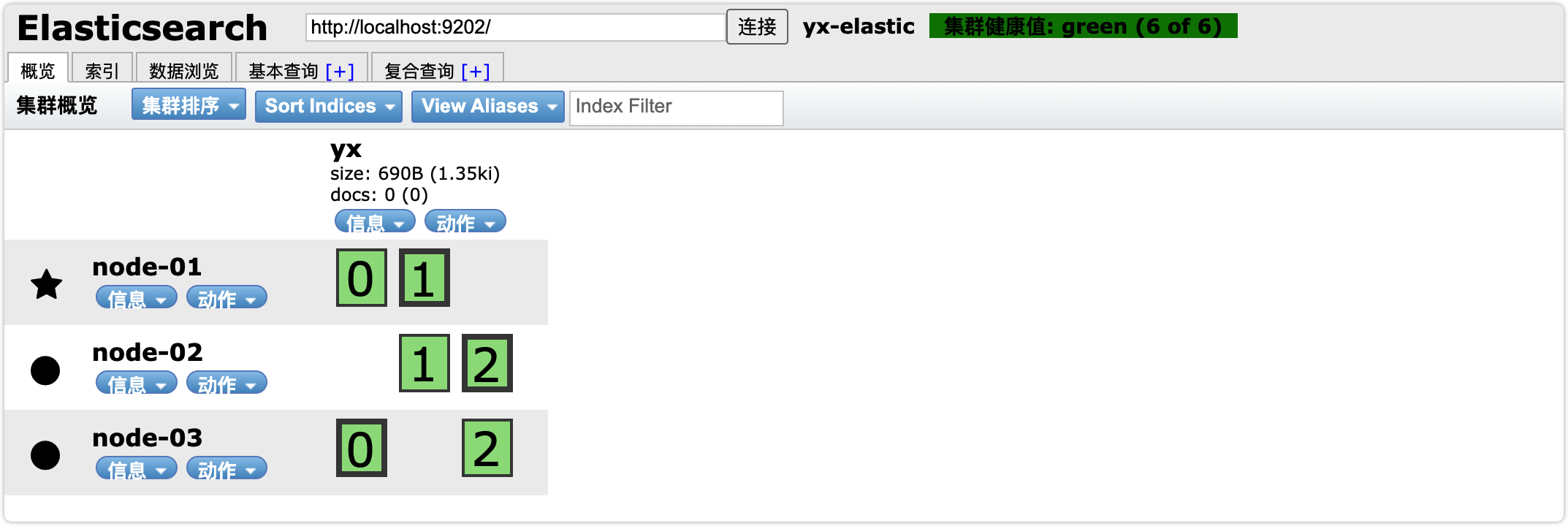
可以看到,yx这个索引库,有三个分片,分别是0、1、2,每个分片有1个副本,共6份。
- node-01上保存了0号分片和1号分片的副本
- node-02上保存了1号分片和2号分片的副本
- node-03上保存了2号分片和0号分片的副本
四. 集群工作原理
1.shard与replica机制
1.一个index包含多个shard,也就是一个index存在多个服务器上。
2.每个shard都是一个最小工作单元,承载部分数据,比如有三台服务器,现在有三条数据,这三条数据在三台服务器上各方一条。
3.增减节点时,shard会自动在nodes中负载均衡。
4.primary shard(主分片)和replica shard(副本分片),每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard。
5.replica shard是primary shard的副本,负责容错,以及承担读请求负载。
6.primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改。
7.primary shard的默认数量是5,replica默认是1(每个主分片一个副本分片),默认有10个shard,5个primary shard,5个replica shard。
8.primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replicashard放在同一个节点上。
2.集群写入数据
在Elasticsearch集群中写入数据的步骤:
1.客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)。
2.coordinating node对document进行路由,将请求转发给对应的node,根据一定的算法选择对应的节点进行存储。
3.实际上,node上的primary shard处理请求,将数据保存在本地,然后将数据同步到replica node。
4.coordinating node如果发现primary node和所有的replica node都搞定之后,就会返回请求到客户端。
这个路由简单的说就是取模算法,比如说现在有3台服务器,这个时候传过来的id是5,那么5%3=2,就放在第2台服务器。
3.ES查询数据
3.1.倒排序算法
查询有个算法叫倒排序。简单的说就是,通过分词把词语出现的id进行记录下来,在查询的时候先去查到哪些id包含这个数据,然后再根据id把数据查出来。
3.2.查询过程
1.客户端发送一个请求给协调节点(coordinate node)。
2.协调节点将搜索的请求转发给所有的shard对应的primary shard或replica shard。
3.查询阶段(query phase),每一个shard将自己搜索的结果(其实也就是一些唯一标识),返回给协调节点,由协调节点进行数据的合并、排序和分页等操作,产出最后的结果。
4.获取阶段(fetch phase),接着由协调节点,根据唯一标识去各个节点进行拉取数据,最终返回给客户端。
五. 结语
本节我们主要学习了Elasticsearch集群的相关内容,Elasticsearch集群解决了三高问题,高存储、高可用和高并发。主要从ES的集群架构、如何搭建ES集群,带领大家一步步从零搭建了一个ES集群环境。然后通过Kibana和elasticsearch-head工具访问集群环境进行测试,最后讲解了ES的基本操作。关于Elasticsearch集群相关的内容就给大家介绍到这里。
今天的内容就分享到这里吧。关注「袁庭新」,干货天天都不断!

)


















下载编译以及调通测试demo)