本文首发自博客文章 如何评估一个RAG(检索增强生成)系统
RAG 概念最初来源于 2020 年 Facebook 的一篇论文,这是 Facebook 博客对论文内容的进一步解释 👉《检索增强生成:简化智能自然语言处理模型的创建》。大家都知道在今天构建一个 RAG 应用的概念证明很容易,但要正经投入生产却非常困难,俗称「一周出 Demo、半年用不好 🫠」,要使 RAG 应用的性能达到令人满意的状态尤其困难,如何正确的评估 RAG 应用是当前一个热门的研究主题,例如 RAG 三元组指标、ROUGE、ARES、BLEU 等。RAG 流程中包含三大组件:
- 数据索引组件:数据向量和索引创建的工作
- 检索器组件:为 LLM 检索额外的上下文信息,以回答查询。
- 生成器组件:基于检索到的信息增强的提示生成答案。
评估 RAG 流程时,针对数据索引组件(包含数据提取、嵌入、创建索引等)没有太多评估工作,而对检索器和生成器组件,需要充分测试以了解 RAG 流程是否仍需要改进以及在哪些方面需要改进。
我的新书《LangChain编程从入门到实践》 已经开售!推荐正在学习AI应用开发的朋友购买阅读!

1. 实践经验
这个是我实践探索出的经验,当前还比较粗,我选取了流畅有用、上下文支持率、上下文有效率 3 个指标进行的评估,且听我一一解释。
流畅有用
这个好理解,流畅侧重生成的内容是否流畅连贯,以当下大模型的能力基本不存在这方面问题,就算胡说八道,但是表达也是流畅自然的,其次有用指的是生成的内容是否有用,用户正常使用过程中很容易感知,而且这部分的指标收集来源也是用户交互数据,系统推上去后,每条回答都有一个点赞 👍 点踩 👎 的按钮。
上下文支持率(a)
检索到的上下文内容在全部的生成内容中占比多少,用于评估最终结果中到底用了多少检索到的知识库内容。
上下文支持率 = 有检索到的上下文信息进行支撑的生成内容 / 总的生成内容
上下文有效率(b)
检索到的和问题意图关联程度较强的上下文片段与检索到的全部上下文片段的占比,用于评估检索到的上下文信息质量
上下文有效率 = 与问题强相关的上下文片段/检索到的全部上下文片段
最后计算出上下文效率和上下文支持率的调和平均数 H(调和平均数的计算方法是将所有数值的倒数求和,然后再取这个和的倒数,受极端值影响较小)
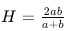
然后后台每一条问答,都会有 a,b,H 三个指标数据进行标记。
总结
有意思的是,我按照自己摸索的这套方案做出一个版本后,去搜相关资料才发现和 《生成式搜索引擎中验证性评估》这篇论文的思路挺相近的,不过论文中探讨的更严谨,正在做这方面工作的朋友可以去读一下,或者去看下Devv(一款面向开发者的新一代 AI 搜索引擎)作者的解读,我这里结合他的解读快速过下论文中的方案:
论文提到了一个值得信赖的 Generative Search Engine 的先决条件就是:可验证性(verifiability)。理想的 RAG 系统应该是:
- 高引用召回率(high citation recall),即所有的生成内容都有引用(外部知识)充分支持
- 高引用精度(high citation precision),即每个引用是否真的支持生成的内容
实际上这两个指标不可能做到 100%,根据论文中的实验结果,现有的 Generative Search Engine 生成的内容经常包含无据陈述和不准确的引文,这两个数据分别是 51.5% 和 74.5%。

于是采用了 4 个指标来进行评估:
- fluency,流畅性,生成的文本是否流畅连贯(例如 xxx 算是流畅的,并用 Five-point Likert 量表来进行计算,从 Strongly Disagree 到 Strongly Agree)
- perceived utility,实用性,生成的内容是否有用 (让评测者对「The response is a helpful and informative answer to the query」这个说法的同意程度进行打分)
- citation recall,引文召回率,引文支持的生成内容 / 总的生成内容 (和我的上下文支持率差不多含义)
- citation precision,引文精度,与特定主题相关的文献数量 / 检索到的内容 (和我的上下文有效率概念也近似)
一个优秀的 GSE (生成式搜索引擎)系统应该在 citation recall 和 citation precision 上都获得比较高的评分。
F1 分数是精确率和召回率的调和平均数,它为了同时考虑精确率和召回率的影响,是二者之间的一种平衡。F1 分数的计算公式为:

F2 分数是一个更为一般化的版本,它允许调整精确率和召回率的相对重要性。F2 分数通过引入一个参数 β,可以对精确率和召回率进行加权。具体来说,当 β>1 时,召回率的权重大于精确率;当 β<1 时,精确率的权重大于召回率。F2 分数就是在这个公式中设 β=2,使得召回率的重要性高于精确率。Fβ 分数的计算公式为:

这两种分数都用于评估模型的性能,特别是在数据不平衡的情况下,它们比单纯的准确率更能反映模型的性能。
2. RAGAs
RAGAs(Retrieval-Augmented Generation Assessment)是一个框架(GitHub、文档),该框架考虑检索系统识别相关和重点上下文段落的能力,LLM 以忠实方式利用这些段落的能力,以及生成本身的质量。为了了解 RAG 应用性能是否在提高,必须通过评估指标和评估数据集进行定量评估。
评估数据
最开始的 RAGAs 在评估数据集时,不必依赖人工标注的标准答案,而是通过底层的大语言模型 (LLM) 来进行评估(提供了自动测试数据生成的工具),不过 RAGAs 现在已经扩展了需要依赖真实标签的指标(例如,context_recall 和 answer_correctness)(详见 评估指标)。
为了评估 RAG 流程,RAGAs 需要以下几种数据信息:
question:RAG 流程的输入,即用户查询问题。answer:RAG 流程生成的答案,也就是最终输出结果。contexts:用于回答question的从外部知识源检索到的上下文。ground_truths(真实答案):question的真实答案。这是唯一需要人工标注的信息。这个信息仅在评估context_recall这一指标时才需要。(详见 评估指标)。
评估指标
RAGAs 提供了一些 指标,可用于从组件层面和整体流程两个方面评估 RAG 流程的性能。
在组件层面上,RAGAs 提供了评估检索组件(context_relevancy 和 context_recall)和生成组件(faithfulness 和 answer_relevancy)的指标,所有指标的评分范围在 [0, 1] 之间,分数越高表示性能越出色:
- context_precision(上下文精度) :衡量与查询问题最相关的上下文片段是否都被优先展示在前几项。该指标通过
问题、真实答案和上下文来计算。 - context_recall(上下文召回率) :衡量是否检索到了所有必要信息以回答问题。该指标基于
真实答案(框架中唯一基于人工标注的真实数据的指标)和上下文计算得出。 - faithfulness(事实一致性) :衡量生成答案的事实准确性。从给定上下文中正确的陈述数量除以生成答案中陈述的总数。该指标结合了
问题、上下文和答案。 - answer_relevance(答案相关性) :衡量生成答案与问题的相关性。该指标使用
问题和答案计算得出。例如,对于问题 “北京在哪里,它的首都是什么?”,答案 “北京位于亚洲。” 的答案相关性会很低,因为它只回答了问题的一半。
在整体流程 上,例如 答案的语义相似度 和 答案的正确性可以作为评估 RAG 整体流程的指标。
使用 RAGAs 评估 RAG
下面是一个使用 RAGAs 评估 RAG 应用的过程,主要代码来自这篇文章。
RAG 应用示例
代码部分还是以 LangChain 为例:
import requests
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitterurl = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:f.write(res.text)# 加载数据
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()# 分块数据
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
接下来,使用 OpenAI 嵌入模型为每个块生成向量嵌入,并将它们存储在向量数据库中。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
from dotenv import load_dotenv,find_dotenv# 从 .env 文件加载 OpenAI API 密钥
load_dotenv(find_dotenv())# 设置向量数据库
client = weaviate.Client(embedded_options = EmbeddedOptions()
)# 填充向量数据库
vectorstore = Weaviate.from_documents(client = client,documents = chunks,embedding = OpenAIEmbeddings(),by_text = False
)# 定义向量存储为检索器以启用语义搜索
retriever = vectorstore.as_retriever()
最后,设置一个提示模板和 OpenAI LLM,并将它们与检索器组件结合成一个 RAG 流程。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser# 定义 LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)# 定义提示模板
template = """您是一个问答任务的助手。
使用以下检索到的上下文片段回答问题。
如果您不知道答案,只需说您不知道。
最多使用两个句子,保持答案简洁。
问题:{question}
上下文:{context}
答案:
"""prompt = ChatPromptTemplate.from_template(template)# 设置 RAG 流程
rag_chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser()
)
准备评估数据
由于 RAGAs 在评估数据集时,不必依赖人工标注的标准答案,所以评估数据集所需的准备工作是最小的。只需要准备 问题 和 真实答案 对,从中可以推导出其他所需信息,如下所示:
from datasets import Dataset# 问题
questions = ["美国总统对 Justice Breyer 说了什么?","美国总统对 Intel 的 CEO 说了什么?","美国总统对枪支暴力说了什么?",]
# 真实答案
ground_truths = [["美国总统说 Justice Breyer 致力于服务国家,并感谢他的服务。"],["美国总统说 Pat Gelsinger 准备将 Intel 的投资增加到 1000 亿美元。"],["美国总统要求国会通过经过验证的措施来减少枪支暴力。"]]
answers = []
contexts = []# 推导信息
for query in questions:answers.append(rag_chain.invoke(query))contexts.append([docs.page_content for docs in retriever.get_relevant_documents(query)])# 转换为字典
data = {"question": questions, # 问题"answer": answers, # 答案"contexts": contexts, # 上下文"ground_truths": ground_truths # 真实答案
}# 将字典转换为数据集
dataset = Dataset.from_dict(data)
如果不关注 context_recall 指标,就不必提供 ground_truths 数据,只需 question 数据即可。
进行应用评估
从 ragas.metrics 导入所有想要使用的指标,然后使用 evaluate() 函数,传入相关的指标和准备好的数据集即可。
from ragas import evaluate
from ragas.metrics import (faithfulness,answer_relevancy,context_recall,context_precision,
)result = evaluate(dataset = dataset,metrics=[context_precision,context_recall,faithfulness,answer_relevancy,],
)df = result.to_pandas()
下面是最终的 RAGAs 得分(上下文相关性、上下文召回率、忠实度和答案相关性):

context_precision(上下文精度):上下文精确度的值在 0 到 1 之间,数值越接近 1,表示检索结果的相关性越高,即检索到的信息与查询问题的相关度越紧密,如果上下文精确度的值接近 0,则意味着检索结果中包含的相关项很少或者排名非常靠后,这表明检索系统的性能需要改进。context_recall(上下文召回率):LLM 评估检索到的上下文包含了正确回答问题所需的相关信息。faithfulness(事实一致性):虽然 LLM 判断第一个和最后一个问题的答案正确,但第二个问题的答案错误地声称「美国总统没有提到 Intel 的 CEO」,其事实一致性被判断为 0.5。answer_relevance(答案相关性):所有生成的答案都被判断为与问题相关性较高,都大于 0.8。
3. RAG 对大语言模型的影响
这个来自论文《Benchmarking Large Language Models in Retrieval-Augmented Generation》,定性分析了不同大模型在进行 RAG 时基本能力的表现,包括噪声鲁棒性、拒答、信息整合和反事实鲁棒性4 个测试维度,虽然论文题目强调是 RAG 对大模型的输出效果影响,但等同于对 RAG 流程的生成器组件评估,可以作为一种思路。

在对比模型上,选用 ChatGPT , ChatGLM-6B , ChatGLM2-6B , Vicuna-7b-v1.3 , Qwen-7B- Chat , BELLE-7B-2M 等模型。
噪声鲁棒性(Noise Robustness)
模型能从噪声文档中提取有用信息。噪声文档定义为与问题相关但不包含任何相关信息的文档。
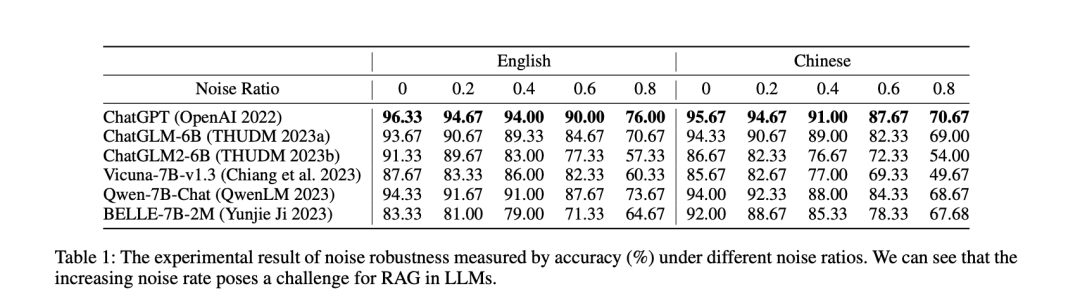
当噪声率超过 80%时,模型的准确性就会明显下降。例如,ChatGPT 的性能从 96.33%降至 76.00%,而 ChatGLM2-6B 的性能则从 91.33%降至 57.33%,RAG 可以有效改善 LLM 的回复,即使在有噪声的情况下,LLM 也能表现出不错的性能。
拒答(Negative Rejection)
当检索到的文档中不存在所需的知识点时,模型应拒绝回答问题。
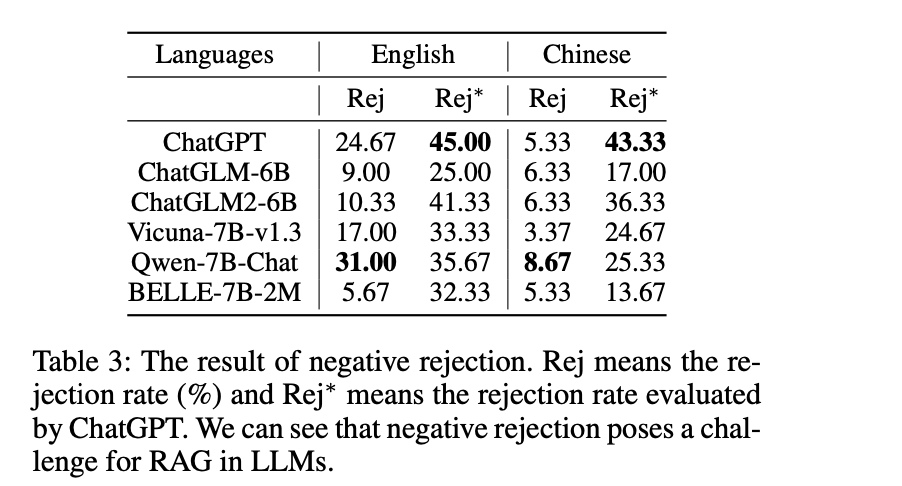
上图显示了评估只提供噪声文档时的拒答率,除了通过精确匹配来评估拒答率(Rej 指标)外,还利用 ChatGPT 来确定大模型的回复是否包含任何拒绝信息(Rej∗ 指标),可以看到大模型很容易被噪声文档误导,从而导致错误的答案。
信息整合(information integration)
评估模型能否回答需要整合多个文档信息的复杂问题。
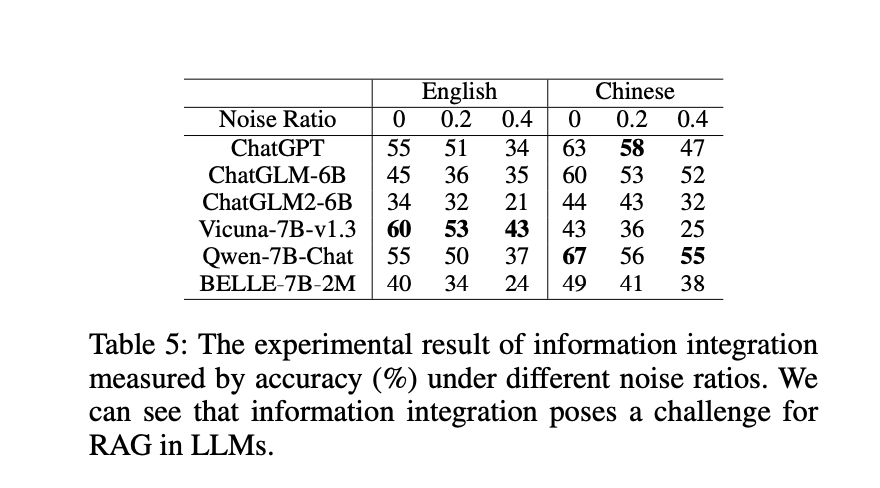
可以看到,即使在没有噪声的情况下,大模型的最高准确率也只能达到英文 60%和中文 67%,加入噪声后,最高准确率下降到 43%和 55%;当噪声比为 0.4 时,性能下降明显,但对于简单问题,只有在噪声比为 0.8 时才会出现明显下降,复杂问题更容易受到噪声的干扰。大模型难以有效整合信息,不适合直接回答复杂问题。
反事实鲁棒性(CounterfactualRobustness)
评估当通过指令向 LLMs 发出关于检索信息中潜在风险的警告时,大模型能否识别检索文档中已知事实错误的风险。
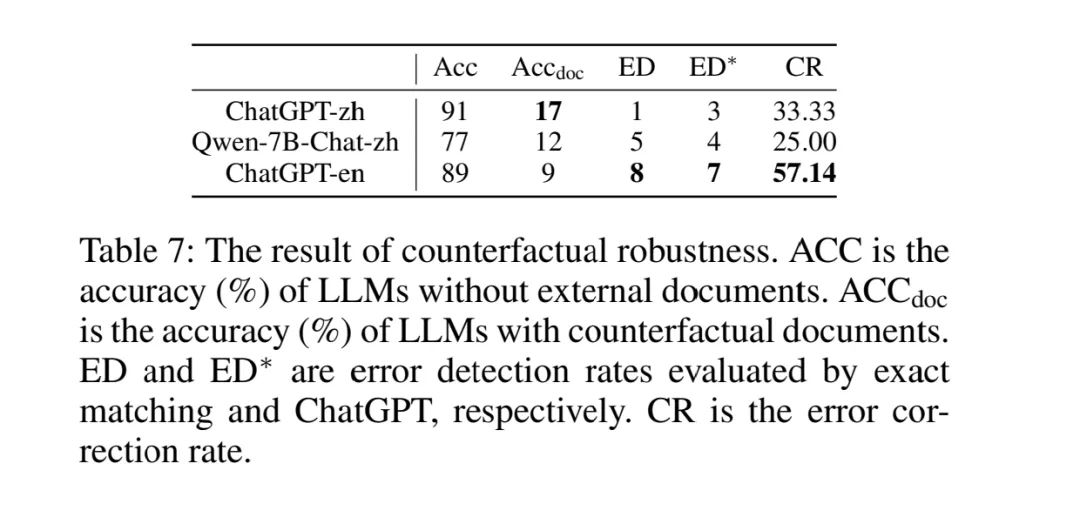
横轴包括以下指标:不包含任何文档的准确率、包含反事实文档的准确率、错误检测率和错误纠正率。可以看到,大模型很难识别和纠正文档中的事实错误,很容易被包含错误事实的文件误导。
总结
总体上 RAGAs 框架中的指标拆的比较细,考虑的比较全面,大家可以重点阅读下项目整体文档,然后借鉴下部分指标整合进自己的设计,而生成式搜索引擎中的方案,从实践出发,提炼的指标虽然少,但是能够很好的评估出 RAG 应用的效果,直接采用,系统也不需要过多工作量。
欢迎关注公众号,获取更多信息。

在JAVA中的应用)

comm)


)





)






)