1.本文速览
本篇文章是我为接下来的 MyBatis 源码分析系列文章写的一个导读文章。本篇文章从 MyBatis 是什么(what),为什么要使用(why),以及如何使用(how)等三个角度进行了说明和演示。由于文章的篇幅比较大,这里特地拿出一章用于介绍本文的结构和内容。那下面我们来看一下本文的章节安排:

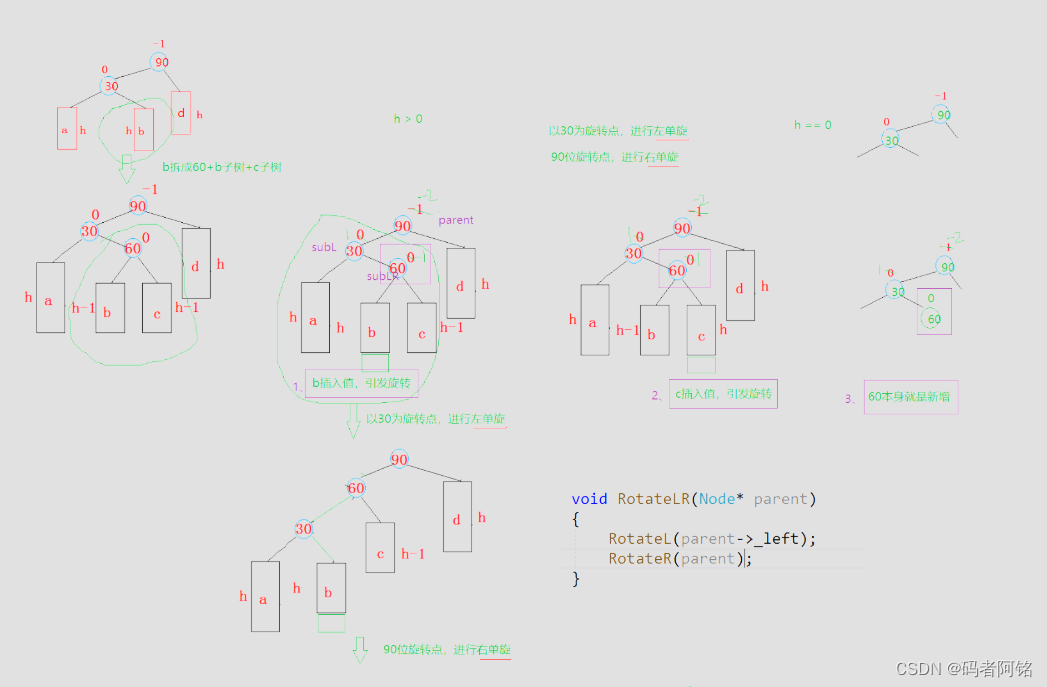
如上图,本文的大部分篇幅主要集中在了第3章和第4章。第3章演示了几种持久层技术的用法,并在此基础上,分析了各种技术的使用场景。通过分析 MyBatis 的使用场景,说明了为什么要使用 MyBatis 这个问题。第4章主要用于介绍 MyBatis 的两种不同的用法。在 4.1 节,演示单独使用 MyBatis 的过程,演示示例涉及一对一和一对多的查询场景。4.2 节则是介绍了 MyBatis 和 Spring 整合的过程,并在最后演示了如何在 Spring 中使用 MyBatis。除了这两章内容,本文的第2章和第5章内容比较少,就不介绍了。
以上就是本篇文章内容的预览,如果这些内容大家都掌握,那么就不必往下看了。当然,如果没掌握或者是有兴趣,那不妨继续往下阅读。好了,其他的就不多说了,咱们进入正题吧。
2.什么是 MyBatis
MyBatis 的前身是 iBatis,其是 Apache 软件基金会下的一个开源项目。2010年该项目从 Apache 基金会迁出,并改名为 MyBatis。同期,iBatis 停止维护。
MyBatis 是一种半自动化的 Java 持久层框架(persistence framework),其通过注解或 XML 的方式将对象和 SQL 关联起来。之所以说它是半自动的,是因为和 Hibernate 等一些可自动生成 SQL 的 ORM(Object Relational Mapping) 框架相比,使用 MyBatis 需要用户自行维护 SQL。维护 SQL 的工作比较繁琐,但也有好处。比如我们可控制 SQL 逻辑,可对其进行优化,以提高效率。
MyBatis 是一个容易上手的持久层框架,使用者通过简单的学习即可掌握其常用特性的用法。这也是 MyBatis 被广泛使用的一个原因。
3.为什么要使用 MyBatis
我们在使用 Java 程序访问数据库时,有多种选择。比如我们可通过编写最原始的 JDBC 代码访问数据库,或是通过 Spring 提供的 JdbcTemplate 访问数据库。除此之外,我们还可以选择 Hibernate,或者本篇的主角 MyBatis 等。在有多个可选项的情况下,我们为什么选择 MyBatis 呢?要回答这个问题,我们需要将 MyBatis 与这几种数据库访问方式对比一下,高下立判。当然,技术之间通常没有高下之分。从应用场景的角度来说,符合应用场景需求的技术才是合适的选择。那下面我会通过写代码的方式,来比较一下这几种数据库访问技术的优缺点,并会在最后说明 MyBatis 的适用场景。
这里,先把本章所用到的一些公共类和配置贴出来,后面但凡用到这些资源的地方,大家可以到这里进行查看。本章所用到的类如下:
public class Article {private Integer id;private String title;private String author;private String content;private Date createTime;// 省略 getter/setter 和 toString
}
数据库相关配置放在了 jdbc.properties 文件中,详细内容如下:
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/coolblog?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=TRUE
jdbc.username=root
jdbc.password=****
表记录如下:

下面先来演示 MyBatis 访问数据库的过程。
3.1 使用 MyBatis 访问数据库
前面说过,MyBatis 是一种半自动化的 Java 持久化框架,使用 MyBatis 需要用户自行维护 SQL。这里,我们把 SQL 放在 XML 中,文件名称为 ArticleMapper.xml。相关配置如下:
<mapper namespace="xyz.coolblog.dao.ArticleDao"><resultMap id="articleResult" type="xyz.coolblog.model.Article"><id property="id" column="id"/><result property="title" column="title"/><result property="author" column="author"/><result property="content" column="content"/><result property="createTime" column="create_time"/></resultMap><select id="findByAuthorAndCreateTime" resultMap="articleResult">SELECT`id`, `title`, `author`, `content`, `create_time`FROM`article`WHERE`author` = #{author} AND `create_time` > #{createTime}</select>
</mapper>
上面的 SQL 用于从article表中查询出某个作者从某个时候到现在所写的文章记录。在 MyBatis 中,SQL 映射文件需要与数据访问接口对应起来,比如上面的配置对应xyz.coolblog.dao.ArticleDao接口,这个接口的定义如下:
public interface ArticleDao {List<Article> findByAuthorAndCreateTime(@Param("author") String author, @Param("createTime") String createTime);
}
要想让 MyBatis 跑起来,还需要进行一些配置。比如配置数据源、配置 SQL 映射文件的位置信息等。本节所使用到的配置如下:
<configuration><properties resource="jdbc.properties"/><environments default="development"><environment id="development"><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}"/><property name="url" value="${jdbc.url}"/><property name="username" value="${jdbc.username}"/><property name="password" value="${jdbc.password}"/></dataSource></environment></environments><mappers><mapper resource="mapper/ArticleMapper.xml"/></mappers>
</configuration>
到此,MyBatis 所需的环境就配置好了。接下来把 MyBatis 跑起来吧,相关测试代码如下:
public class MyBatisTest {private SqlSessionFactory sqlSessionFactory;@Beforepublic void prepare() throws IOException {String resource = "mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);inputStream.close();}@Testpublic void testMyBatis() throws IOException {SqlSession session = sqlSessionFactory.openSession();try {ArticleDao articleDao = session.getMapper(ArticleDao.class);List<Article> articles = articleDao.findByAuthorAndCreateTime("coolblog.xyz", "2018-06-10");} finally {session.commit();session.close();}}
}
在上面的测试代码中,prepare 方法用于创建SqlSessionFactory工厂,该工厂的用途是创建SqlSession。通过 SqlSession,可为我们的数据库访问接口ArticleDao接口生成一个代理对象。MyBatis 会将接口方法findByAuthorAndCreateTime和 SQL 映射文件中配置的 SQL 关联起来,这样调用该方法等同于执行相关的 SQL。
上面的测试代码运行结果如下:
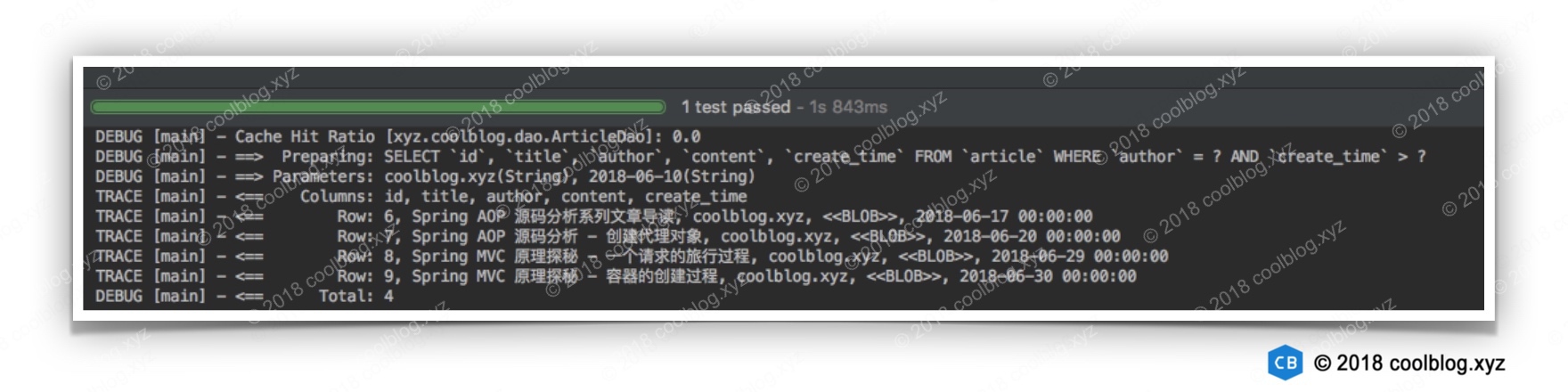
如上,大家在学习 MyBatis 框架时,可以配置一下 MyBatis 的日志,这样可把 MyBatis 的调试信息打印出来,方便观察 SQL 的执行过程。在上面的结果中,==>符号所在的行表示向数据库中输入的 SQL 及相关参数。<==符号所在的行则是表示 SQL 的执行结果。上面输入输出不难看懂,这里就不多说了。
关于 MyBatis 的优缺点,这里先不进行总结。后面演示其他的框架时再进行比较说明。
演示完 MyBatis,下面,我们来看看通过原始的 JDBC 直接访问数据库过程是怎样的。
3.2 使用 JDBC 访问数据库
3.2.1 JDBC 访问数据库的过程演示
在初学 Java 编程阶段,多数朋友应该都是通过直接写 JDBC 代码访问数据库。我这么说,大家应该没异议吧。这种方式的代码流程一般是加载数据库驱动,创建数据库连接对象,创建 SQL 执行语句对象,执行 SQL 和处理结果集等,过程比较固定。下面我们再手写一遍 JDBC 代码,回忆一下初学 Java 的场景。
public class JdbcTest {@Testpublic void testJdbc() {String url = "jdbc:mysql://localhost:3306/myblog?user=root&password=1234&useUnicode=true&characterEncoding=UTF8&useSSL=false";Connection conn = null;try {Class.forName("com.mysql.cj.jdbc.Driver");conn = DriverManager.getConnection(url);String author = "coolblog.xyz";String date = "2018.06.10";String sql = "SELECT id, title, author, content, create_time FROM article WHERE author = '" + author + "' AND create_time > '" + date + "'";Statement stmt = conn.createStatement();ResultSet rs = stmt.executeQuery(sql);List<Article> articles = new ArrayList<>(rs.getRow());while (rs.next()) {Article article = new Article();article.setId(rs.getInt("id"));article.setTitle(rs.getString("title"));article.setAuthor(rs.getString("author"));article.setContent(rs.getString("content"));article.setCreateTime(rs.getDate("create_time"));articles.add(article);}System.out.println("Query SQL ==> " + sql);System.out.println("Query Result: ");articles.forEach(System.out::println);} catch (ClassNotFoundException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();} finally {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}
}
代码比较简单,就不多说了。下面来看一下测试结果:
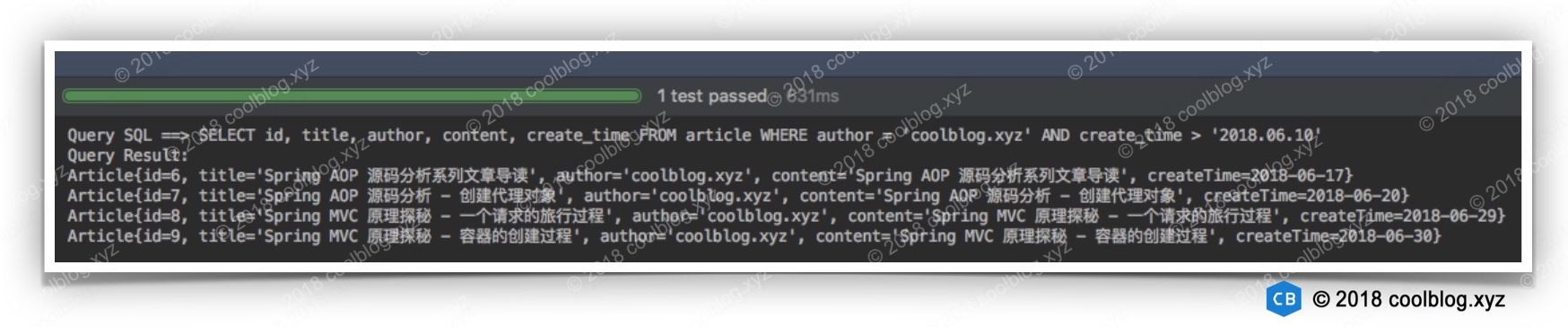
上面代码的步骤比较多,但核心步骤只有两部,分别是执行 SQL 和处理查询结果。从开发人员的角度来说,我们也只关心这两个步骤。如果每次为了执行某个 SQL 都要写很多额外的代码。比如打开驱动,创建数据库连接,就显得很繁琐了。当然我们可以将这些额外的步骤封装起来,这样每次调用封装好的方法即可。这样确实可以解决代码繁琐,冗余的问题。不过,使用 JDBC 并非仅会导致代码繁琐,冗余的问题。在上面的代码中,我们通过字符串对 SQL 进行拼接。这样做会导致两个问题,第一是拼接 SQL 可能会导致 SQL 出错,比如少了个逗号或者多了个单引号等。第二是将 SQL 写在代码中,如果要改动 SQL,就需要到代码中进行更改。这样做是不合适的,因为改动 Java 代码就需要重新编译 Java 文件,然后再打包发布。同时,将 SQL 和 Java 代码混在一起,会降低代码的可读性,不利于维护。关于拼接 SQL,是有相应的处理方法。比如可以使用 PreparedStatement,同时还可解决 SQL 注入的问题。
除了上面所说的问题,直接使用 JDBC 访问数据库还会有什么问题呢?这次我们将目光转移到执行结果的处理逻辑上。从上面的代码中可以看出,我们需要手动从 ResultSet 中取出数据,然后再设置到 Article 对象中。好在我们的 Article 属性不多,所以这样做看起来也没什么。假如 Article 对象有几十个属性,再用上面的方式接收查询结果,会非常的麻烦。而且可能还会因为属性太多,导致忘记设置某些属性。以上的代码还有一个问题,用户需要自行处理受检异常,这也是导致代码繁琐的一个原因。哦,还有一个问题,差点忘了。用户还需要手动管理数据库连接,开始要手动获取数据库连接。使用好后,又要手动关闭数据库连接。不得不说,真麻烦。
没想到直接使用 JDBC 访问数据库会有这么多的问题。如果在生产环境直接使用 JDBC,怕是要被 Leader 打死了。当然,视情况而定。如果项目非常小,且对数据库依赖比较低。直接使用 JDBC 也很方便,不用像 MyBatis 那样搞一堆配置了。
3.2.2 MyBatis VS JDBC
上面说了一大堆 JDBC 的坏话,有点过意不去,所以下面来吐槽一下 MyBatis 吧。与 JDBC 相比,MyBatis 缺点比较明显,它的配置比较多,特别是 SQL 映射文件。如果一个大型项目中有几十上百个 Dao 接口,就需要有同等数量的 SQL 映射文件,这些映射文件需要用户自行维护。不过与 JDBC 相比,维护映射文件不是什么问题。不然如果把同等数量的 SQL 像 JDBC 那样写在代码中,那维护的代价才叫大,搞不好还会翻车。除了配置文件的问题,大家会发现使用 MyBatis 访问数据库好像过程也很繁琐啊。它的步骤大致如下:
- 读取配置文件
- 创建 SqlSessionFactoryBuilder 对象
- 通过 SqlSessionFactoryBuilder 对象创建 SqlSessionFactory
- 通过 SqlSessionFactory 创建 SqlSession
- 为 Dao 接口生成代理类
- 调用接口方法访问数据库
如上,如果每次执行一个 SQL 要经过上面几步,那和 JDBC 比较起来,也没什优势了。不过这里大家需要注意,SqlSessionFactoryBuilder 和 SqlSessionFactory 以及 SqlSession 等对象的作用域和生命周期是不一样的,这一点在 MyBatis 官方文档中说的比较清楚,我这里照搬一下。SqlSessionFactoryBuilder 对象用于构建 SqlSessionFactory,只要构建好,这个对象就可以丢弃了。SqlSessionFactory 是一个工厂类,一旦被创建就应该在应用运行期间一直存在,不应该丢弃或重建。SqlSession 不是线程安全的,所以不应被多线程共享。官方推荐的使用方式是有按需创建,用完即销毁。因此,以上步骤中,第1、2和第3步只需执行一次。第4和第5步需要进行多次创建。至于第6步,这一步是必须的。所以比较下来,MyBatis 的使用方式还是比 JDBC 简单的。同时,使用 MyBatis 无需处理受检异常,比如 SQLException。另外,把 SQL 写在配置文件中,进行集中管理,利于维护。同时将 SQL 从代码中剥离,在提高代码的可读性的同时,也避免拼接 SQL 可能会导致的错误。除了上面所说这些,MyBatis 会将查询结果转为相应的对象,无需用户自行处理 ResultSet。
总的来说,MyBatis 在易用性上要比 JDBC 好太多。不过这里拿 MyBatis 和 JDBC 进行对比并不太合适。JDBC 作为 Java 平台的数据库访问规范,它仅提供一种访问数据库的能力。至于使用者觉得 JDBC 流程繁琐,还要自行处理异常等问题,这些还真不怪 JDBC。比如 SQLException 这个异常,JDBC 没法处理啊,抛给调用者处理也是理所应当的。至于繁杂的步骤,这仅是从使用者的角度考虑的,从 JDBC 的角度来说,这里的每个步骤对于完成一个数据访问请求来说都是必须的。至于 MyBatis,它是构建在 JDBC 技术之上的,对访问数据库的操作进行了简化,方便用户使用。综上所述,JDBC 可看做是一种基础服务,MyBatis 则是构建在基础服务之上的框架,它们的目标是不同的。
3.3 使用 Spring JDBC 访问数据库
上一节演示了 JDBC 访问数据的过程,通过演示及分析,大家应该感受到了直接使用 JDBC 的一些痛点。为了解决其中的一些痛点,Spring JDBC 应运而生。Spring JDBC 在 JDBC 基础上,进行了比较薄的包装,易用性得到了不少提升。那下面我们来看看如何使用 Spring JDBC。
我们在使用 Spring JDBC 之前,需要进行一些配置。这里我把配置信息放在了 application.xml 文件中,后面写测试代码时,让容器去加载这个配置。配置内容如下:
<context:property-placeholder location="jdbc.properties"/><bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"><property name="driverClassName" value="${jdbc.driver}" /><property name="url" value="${jdbc.url}" /><property name="username" value="${jdbc.username}" /><property name="password" value="${jdbc.password}" />
</bean>
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate"><property name="dataSource" ref="dataSource" />
</bean>
如上,JdbcTemplate封装了一些访问数据库的方法,下面我们会通过此对象访问数据库。演示代码如下:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:application.xml")
public class SpringJdbcTest {@Autowiredprivate JdbcTemplate jdbcTemplate;@Testpublic void testSpringJdbc() {String author = "coolblog.xyz";String date = "2018.06.10";String sql = "SELECT id, title, author, content, create_time FROM article WHERE author = '" + author + "' AND create_time > '" + date + "'";List<Article> articles = jdbcTemplate.query(sql, (rs, rowNum) -> {Article article = new Article();article.setId(rs.getInt("id"));article.setTitle(rs.getString("title"));article.setAuthor(rs.getString("author"));article.setContent(rs.getString("content"));article.setCreateTime(rs.getDate("create_time"));return article;});System.out.println("Query SQL ==> " + sql);System.out.println("Spring JDBC Query Result: ");articles.forEach(System.out::println);}
}
测试结果如下:
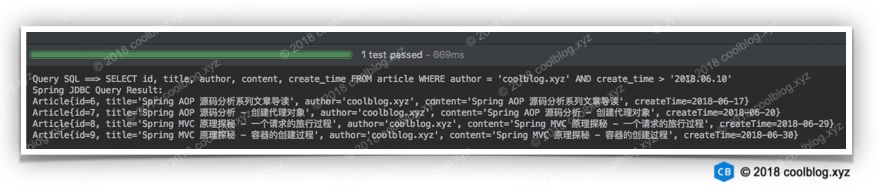
从上面的代码中可以看得出,Spring JDBC 还是比较容易使用的。不过它也是存在一定缺陷的,比如 SQL 仍是写在代码中。又比如,对于较为复杂的结果(数据库返回的记录包含多列数据),需要用户自行处理 ResultSet 等。不过与 JDBC 相比,使用 Spring JDBC 无需手动加载数据库驱动,获取数据库连接,以及创建 Statement 对象等操作。总的来说,易用性上得到了不少的提升。
这里就不对比 Spring JDBC 和 MyBatis 的优缺点了。Spring JDBC 仅对 JDBC 进行了一层比较薄的封装,相关对比可以参考上一节的部分分析,这里不再赘述。
3.4 使用 Hibernate 访问数据库
本节会像之前的章节一样,我会先写代码进行演示,然后再对比 Hibernate 和 MyBatis 的区别。需要特别说明的是,我在工作中没有用过 Hibernate,对 Hibernate 也仅停留在了解的程度上。本节的测试代码都是现学现卖的,可能有些地方写的会有问题,或者不是最佳实践。所以关于测试代码,大家看看就好。若有不妥之处,也欢迎指出。
3.4.1 Hibernate 访问数据库的过程演示
使用 Hibernate,需要先进行环境配置,主要是关于数据库方面的配置。这里为了演示,我们简单配置一下。如下:
<hibernate-configuration><session-factory><property name="hibernate.connection.driver_class">com.mysql.cj.jdbc.Driver</property><property name="hibernate.connection.url">jdbc:mysql://localhost:3306/myblog?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=TRUE</property><property name="hibernate.connection.username">root</property><property name="hibernate.connection.password">****</property><property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</property><property name="hibernate.show_sql">true</property><mapping resource="mapping/Article.hbm.xml" /></session-factory>
</hibernate-configuration>
下面再配置一下实体类和表之间的映射关系,也就是上面配置中出现的Article.hbm.xml。不过这个配置不是必须的,可用注解进行替换。
<hibernate-mapping package="xyz.coolblog.model"><class table="article" name="Article"><id name="id" column="id"><generator class="native" /></id><property name="title" column="title" /><property name="author" column="author" /><property name="content" column="content" /><property name="createTime" column="create_time" /></class>
</hibernate-mapping>
测试代码如下:
public class HibernateTest {private SessionFactory buildSessionFactory;@Beforepublic void init() {Configuration configuration = new Configuration();configuration.configure("hibernate.cfg.xml");buildSessionFactory = configuration.buildSessionFactory();}@Afterpublic void destroy() {buildSessionFactory.close();}@Testpublic void testORM() {System.out.println("-----------------------------✨ ORM Query ✨--------------------------");Session session = null;try {session = buildSessionFactory.openSession();int id = 6;Article article = session.get(Article.class, id);System.out.println("ORM Query Result: ");System.out.println(article);System.out.println();} finally {if (Objects.nonNull(session)) {session.close();}}}@Testpublic void testHQL() {System.out.println("-----------------------------✨ HQL Query ✨+--------------------------");Session session = null;try {session = buildSessionFactory.openSession();String hql = "from Article where author = :author and create_time > :createTime";Query query = session.createQuery(hql);query.setParameter("author", "coolblog.xyz");query.setParameter("createTime", "2018.06.10");List<Article> articles = query.list();System.out.println("HQL Query Result: ");articles.forEach(System.out::println);System.out.println();} finally {if (Objects.nonNull(session)) {session.close();}}}@Testpublic void testJpaCriteria() throws ParseException {System.out.println("---------------------------✨ JPA Criteria ✨------------------------");Session session = null;try {session = buildSessionFactory.openSession();CriteriaBuilder criteriaBuilder = session.getCriteriaBuilder();CriteriaQuery<Article> criteriaQuery = criteriaBuilder.createQuery(Article.class);// 定义 FROM 子句Root<Article> article = criteriaQuery.from(Article.class);// 构建查询条件SimpleDateFormat sdf = new SimpleDateFormat("yyyy.MM.dd");Predicate greaterThan = criteriaBuilder.greaterThan(article.get("createTime"), sdf.parse("2018.06.10"));Predicate equal = criteriaBuilder.equal(article.get("author"), "coolblog.xyz");// 通过具有语义化的方法构建 SQL,等价于 SELECT ... FROM article WHERE ... AND ...criteriaQuery.select(article).where(equal, greaterThan);Query<Article> query = session.createQuery(criteriaQuery);List<Article> articles = query.getResultList();System.out.println("JPA Criteria Query Result: ");articles.forEach(System.out::println);} finally {if (Objects.nonNull(session)) {session.close();}}}
}
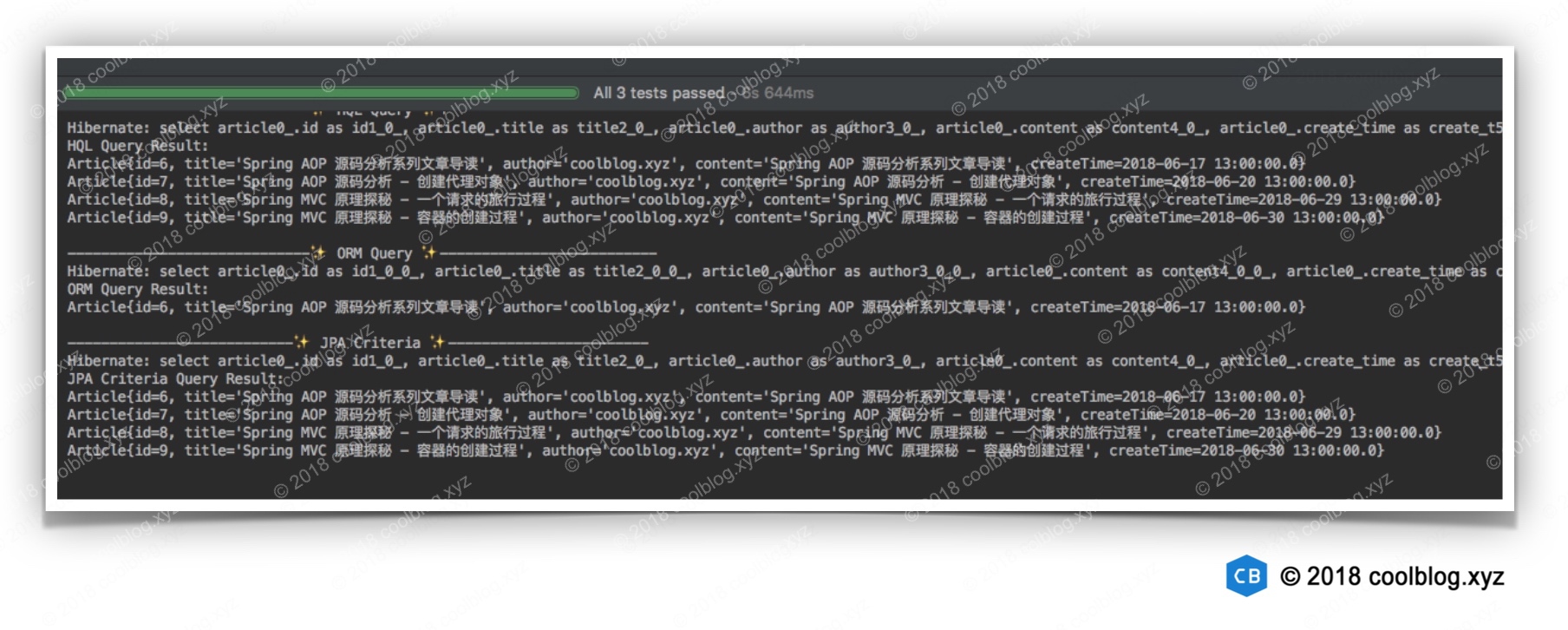
这里我写了三种不同的查询方法,对于比较简单的查询,可以通过OID的方式进行,也就是testORM方法中对应的代码。这种方式不需要写 SQL,完全由 Hibernate 去生成。生成的 SQL 如下:
select article0_.id as id1_0_0_, article0_.title as title2_0_0_, article0_.author as author3_0_0_, article0_.content as content4_0_0_, article0_.create_time as create_t5_0_0_
from article article0_
where article0_.id=?
第二种方式是通过HQL进行查询,查询过程对应测试类中的testHQL方法。这种方式需要写一点 HQL,并为其设置相应的参数。最终生成的 SQL 如下:
select article0_.id as id1_0_, article0_.title as title2_0_, article0_.author as author3_0_, article0_.content as content4_0_, article0_.create_time as create_t5_0_
from article article0_
where article0_.author=? and create_time>?
第三种方式是通过 JPA Criteria 进行查询,JPA Criteria 具有类型安全、面向对象和语义化的特点。使用 JPA Criteria,我们可以用写 Java 代码的方式进行数据库操作,无需手写 SQL。第二种方式和第三种方式进行的是同样的查询,所以生成的 SQL 区别不大,这里就不贴出来了。
下面看一下测试代码的运行结果:
3.4.2 MyBatis VS Hibernate
在 Java 中,就持久层框架来说,MyBatis 和 Hibernate 都是很热门的框架。关于这两个框架孰好孰坏,在网上也有很广泛的讨论。不过就像我前面说到那样,技术之间通常没有高低之分,适不适合才是应该关注的点。这两个框架之间的区别是比较大的,下面我们来聊聊。
从映射关系上来说,Hibernate 是把实体类(POJO)和表进行了关联,是一种完整的 ORM (O/R mapping) 框架。而 MyBatis 则是将数据访问接口(Dao)与 SQL 进行了关联,本质上算是一种 SQL 映射。从使用的角度来说,使用 Hibernate 通常不需要写 SQL,让框架自己生成就可以了。但 MyBatis 则不行,再简单的数据库访问操作都需要有与之对应的 SQL。另一方面,由于 Hibernate 可自动生成 SQL,所以进行数据库移植时,代价要小一点。而由于使用 MyBatis 需要手写 SQL,不同的数据库在 SQL 上存在着一定的差异。这就导致进行数据库移植时,可能需要更改 SQL 的情况。不过好在移植数据库的情况很少见,可以忽略。
上面我从两个维度对 Hibernate 和 MyBatis 进行了对比,但目前也只是说了他们的一些不同点。下面我们来分析一下这两个框架的适用场景。
Hibernate 可自动生成 SQL,降低使用成本。但同时也要意识到,这样做也是有代价的,会损失灵活性。比如,如果我们需要手动优化 SQL,我们很难改变 Hibernate 生成的 SQL。因此对于 Hibernate 来说,它适用于一些需求比较稳定,变化比较小的项目,譬如 OA、CRM 等。
与 Hibernate 相反,MyBatis 需要手动维护 SQL,这会增加使用成本。但同时,使用者可灵活控制 SQL 的行为,这为改动和优化 SQL 提供了可能。所以 MyBatis 适合应用在一些需要快速迭代,需求变化大的项目中,这也就是为什么 MyBatis 在互联网公司中使用的比较广泛的原因。除此之外,MyBatis 还提供了插件机制,使用者可以按需定制插件。这也是 MyBatis 灵活性的一个体现。
分析到这里,大家应该清楚了两个框架之前的区别,以及适用场景。楼主目前在一家汽车相关的互联网公司,公司发展的比较快,项目迭代的也比较快,各种小需求也比较多。所以,相比之下,MyBatis 是一个比较合适的选择。
3.5 本章小结
本节用了大量的篇幅介绍常见持久层框架的用法,并进行了较为详细的分析和对比。看完这些,相信大家对这些框架应该也有了更多的了解。好了,其他的就不多说了,我们继续往下看吧。
4.如何使用 MyBatis
本章,我们一起来看一下 MyBatis 是如何使用的。在上一章,我简单演示了一下 MyBatis 的使用方法。不过,那个太简单了,本章我们来演示一个略为复杂的例子。不过,这个例子复杂度和真实的项目还是有差距,仅做演示使用。
本章包含两节内容,第一节演示单独使用 MyBatis 的过程,第二节演示 MyBatis 是如何和 Spring 进行整合的。那其他的就不多说了,下面开始演示。
4.1 单独使用
本节演示的场景是个人网站的作者和文章之间的关联场景。在一个网站中,一篇文章对应一名作者,一个作者对应多篇文章。下面我们来看一下作者和文章的定义,如下:
public class AuthorDO implements Serializable {private Integer id;private String name;private Integer age;private SexEnum sex;private String email;private List<ArticleDO> articles;// 省略 getter/setter 和 toString
}public class ArticleDO implements Serializable {private Integer id;private String title;private ArticleTypeEnum type;private AuthorDO author;private String content;private Date createTime;// 省略 getter/setter 和 toString
}
如上,AuthorDO 中包含了对一组 ArticleDO 的引用,这是一对多的关系。ArticleDO 中则包含了一个对 AuthorDO 的引用,这是一对一的关系。除此之外,这里使用了两个常量,一个用于表示性别,另一个用于表示文章类型,它们的定义如下:
public enum SexEnum {MAN,FEMALE,UNKNOWN;
}public enum ArticleTypeEnum {JAVA(1),DUBBO(2),SPRING(4),MYBATIS(8);private int code;ArticleTypeEnum(int code) {this.code = code;}public int code() {return code;}public static ArticleTypeEnum find(int code) {for (ArticleTypeEnum at : ArticleTypeEnum.values()) {if (at.code == code) {return at;}}return null;}
}
本篇文章使用了两张表,分别用于存储文章和作者信息。这两种表的内容如下:

下面来看一下数据库访问层的接口定义,如下:
public interface ArticleDao {ArticleDO findOne(@Param("id") int id);
}public interface AuthorDao {AuthorDO findOne(@Param("id") int id);
}
与这两个接口对应的 SQL 被配置在了下面的两个映射文件中。我们先来看一下第一个映射文件 AuthorMapper.xml 的内容。
<!-- AuthorMapper.xml -->
<mapper namespace="xyz.coolblog.dao.AuthorDao"><resultMap id="articleResult" type="Article"><id property="id" column="article_id" /><result property="title" column="title"/><result property="type" column="type"/><result property="content" column="content"/><result property="createTime" column="create_time"/></resultMap><resultMap id="authorResult" type="Author"><id property="id" column="id"/><result property="name" column="name"/><result property="age" column="age"/><result property="sex" column="sex" typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler"/><result property="email" column="email"/><collection property="articles" ofType="Article" resultMap="articleResult"/></resultMap><select id="findOne" resultMap="authorResult">SELECTau.id, au.name, au.age, au.sex, au.email,ar.id as article_id, ar.title, ar.type, ar.content, ar.create_timeFROMauthor au, article arWHEREau.id = ar.author_id AND au.id = #{id}</select>
</mapper>
注意看上面的<resultMap/>配置,这个标签中包含了一个一对多的配置<collection/>,这个配置引用了一个 id 为articleResult的。除了要注意一对多的配置,这里还要下面这行配置:
<result property="sex" column="sex" typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler"/>
前面说过 AuthorDO 的sex属性是一个枚举,但这个属性在数据表中是以整型值进行存储的。所以向数据表写入或者查询数据时,要进行类型转换。写入时,需要将SexEnum转成int。查询时,则需要把int转成SexEnum。由于这两个是完全不同的类型,不能通过强转进行转换,所以需要使用一个中间类进行转换,这个中间类就是 EnumOrdinalTypeHandler。这个类会按照枚举顺序进行转换,比如在SexEnum中,MAN的顺序是0。存储时,EnumOrdinalTypeHandler 会将MAN替换为0。查询时,又会将0转换为MAN。除了EnumOrdinalTypeHandler,MyBatis 还提供了另一个枚举类型处理器EnumTypeHandler。这个则是按照枚举的字面值进行转换,比如该处理器将枚举MAN和字符串 “MAN” 进行相互转换。
上面简单分析了一下枚举类型处理器,接下来,继续往下看。下面是 ArticleMapper.xml 的配置内容:
<!-- ArticleMapper.xml -->
<mapper namespace="xyz.coolblog.dao.ArticleDao"><resultMap id="authorResult" type="Author"><id property="id" column="author_id"/><result property="name" column="name"/><result property="age" column="age"/><result property="sex" column="sex" typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler"/><result property="email" column="email"/></resultMap><resultMap id="articleResult" type="Article"><id property="id" column="id" /><result property="title" column="title"/><result property="type" column="type" typeHandler="xyz.coolblog.mybatis.ArticleTypeHandler"/><result property="content" column="content"/><result property="createTime" column="create_time"/><association property="author" javaType="Author" resultMap="authorResult"/></resultMap><select id="findOne" resultMap="articleResult">SELECTar.id, ar.author_id, ar.title, ar.type, ar.content, ar.create_time,au.name, au.age, au.sex, au.emailFROMarticle ar, author auWHEREar.author_id = au.id AND ar.id = #{id}</select>
</mapper>
如上,ArticleMapper.xml 中包含了一个一对一的配置<association/>,这个配置引用了另一个 id 为authorResult的。除了一对一的配置外,这里还有一个自定义类型处理器ArticleTypeHandler需要大家注意。这个自定义类型处理器用于处理ArticleTypeEnum枚举类型。大家如果注意看前面贴的ArticleTypeEnum的源码,会发现每个枚举值有自己的编号定义。比如JAVA的编号为1,DUBBO的编号为2,SPRING的编号为8。所以这里我们不能再使用EnumOrdinalTypeHandler对ArticleTypeHandler进行类型转换,需要自定义一个类型转换器。那下面我们来看一下这个类型转换器的定义。
public class ArticleTypeHandler extends BaseTypeHandler<ArticleTypeEnum> {@Overridepublic void setNonNullParameter(PreparedStatement ps, int i, ArticleTypeEnum parameter, JdbcType jdbcType)throws SQLException {// 获取枚举的 code 值,并设置到 PreparedStatement 中ps.setInt(i, parameter.code());}@Overridepublic ArticleTypeEnum getNullableResult(ResultSet rs, String columnName) throws SQLException {// 从 ResultSet 中获取 codeint code = rs.getInt(columnName);// 解析 code 对应的枚举,并返回return ArticleTypeEnum.find(code);}@Overridepublic ArticleTypeEnum getNullableResult(ResultSet rs, int columnIndex) throws SQLException {int code = rs.getInt(columnIndex);return ArticleTypeEnum.find(code);}@Overridepublic ArticleTypeEnum getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {int code = cs.getInt(columnIndex);return ArticleTypeEnum.find(code);}
}
对于自定义类型处理器,可继承 BaseTypeHandler,并实现相关的抽象方法。上面的代码比较简单,我也进行了一些注释。应该比较好理解,这里就不多说了。
前面贴了实体类,数据访问类,以及 SQL 映射文件。最后还差一个 MyBatis 的配置文件,这里贴出来。如下:
<!-- mybatis-congif.xml -->
<configuration><properties resource="jdbc.properties"/><typeAliases><typeAlias alias="Article" type="xyz.coolblog.model.ArticleDO"/><typeAlias alias="Author" type="xyz.coolblog.model.AuthorDO"/></typeAliases><typeHandlers><typeHandler handler="xyz.coolblog.mybatis.ArticleTypeHandler" javaType="xyz.coolblog.constant.ArticleTypeEnum"/></typeHandlers><environments default="development"><environment id="development"><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}"/><property name="url" value="${jdbc.url}"/><property name="username" value="${jdbc.username}"/><property name="password" value="${jdbc.password}"/></dataSource></environment></environments><mappers><mapper resource="mapper/AuthorMapper.xml"/><mapper resource="mapper/ArticleMapper.xml"/></mappers>
</configuration>
下面通过一个表格简单解释配置中出现的一些标签。
| 标签名称 | 用途 |
|---|---|
| properties | 用于配置全局属性,这样在配置文件中,可以通过占位符 ${} 进行属性值配置 |
| typeAliases | 用于定义别名。如上所示,这里把xyz.coolblog.model.ArticleDO的别名定义为Article,这样在 SQL 映射文件中,就可以直接使用别名,而不用每次都输入长长的全限定类名了 |
| typeHandlers | 用于定义全局的类型处理器,如果这里配置了,SQL 映射文件中就不需要再次进行配置。前面为了讲解需要,我在 SQL 映射文件中也配置了 ArticleTypeHandler,其实是多余的 |
| environments | 用于配置事务,以及数据源 |
| mappers | 用于配置 SQL 映射文件的位置信息 |
以上仅介绍了一些比较常用的配置,更多的配置信息,建议大家去阅读MyBatis 官方文档。
到这里,我们把所有的准备工作都做完了。那么接下来,写点测试代码测试一下。
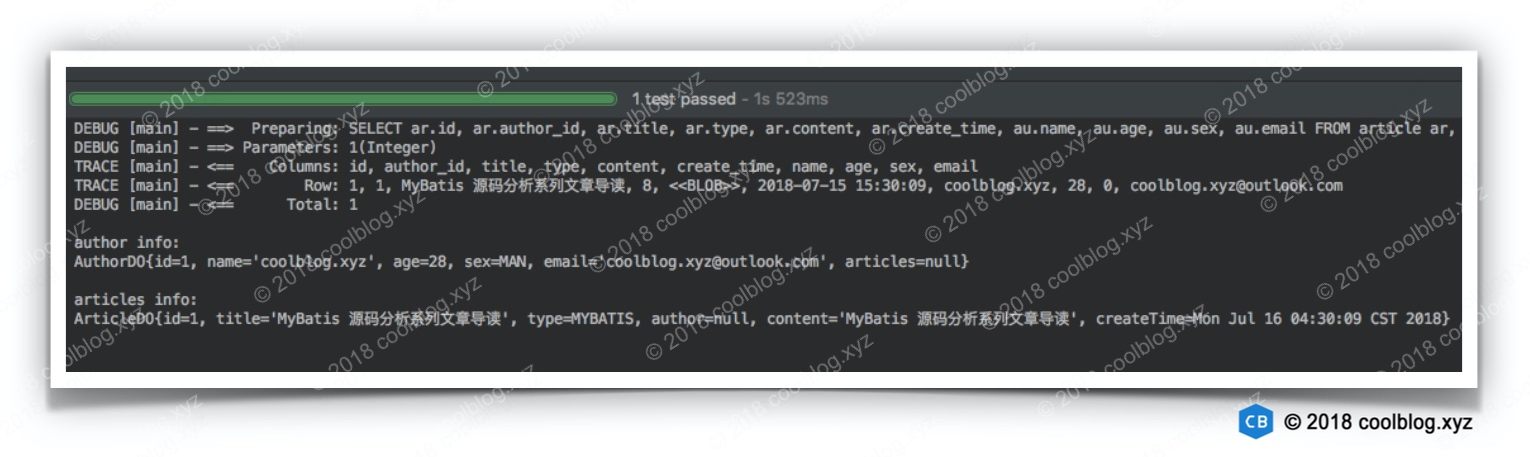
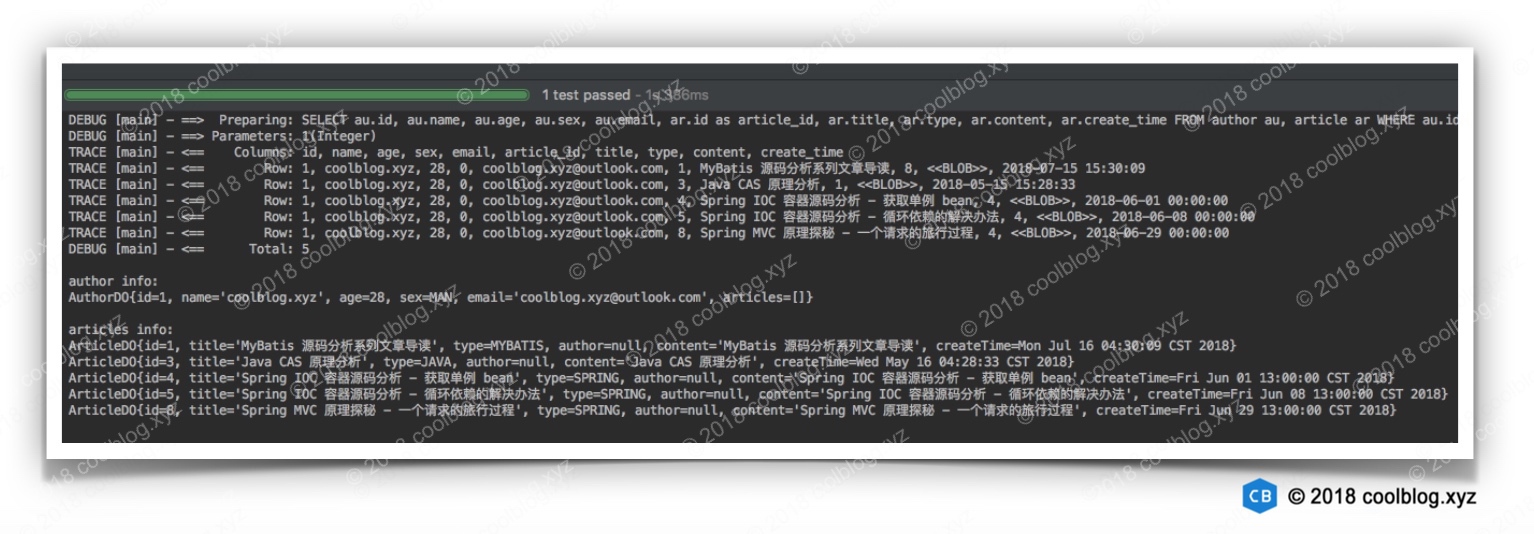
public class MyBatisTest {private SqlSessionFactory sqlSessionFactory;@Beforepublic void prepare() throws IOException {String resource = "mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);inputStream.close();}@Testpublic void testOne2One() {SqlSession session = sqlSessionFactory.openSession();try {ArticleDao articleDao = session.getMapper(ArticleDao.class);ArticleDO article = articleDao.findOne(1);AuthorDO author = article.getAuthor();article.setAuthor(null);System.out.println();System.out.println("author info:");System.out.println(author);System.out.println();System.out.println("articles info:");System.out.println(article);} finally {session.close();}}@Testpublic void testOne2Many() {SqlSession session = sqlSessionFactory.openSession();try {AuthorDao authorDao = session.getMapper(AuthorDao.class);AuthorDO author = authorDao.findOne(1);List<ArticleDO> arts = author.getArticles();List<ArticleDO> articles = Arrays.asList(arts.toArray(new ArticleDO[arts.size()]));arts.clear();System.out.println();System.out.println("author info:");System.out.println(author);System.out.println();System.out.println("articles info:");articles.forEach(System.out::println);} finally {session.close();}}
}
第一个测试方法用于从数据库中查询某篇文章,以及相应作者的信息。它的运行结果如下:
第二个测试方法用于查询某位作者,及其所写的所有文章的信息。它的运行结果如下:
到此,MyBatis 的使用方法就介绍完了。由于我个人在平时的工作中,也知识使用了 MyBatis 的一些比较常用的特性,所以本节的内容也比较浅显。另外,由于演示示例比较简单,这里也没有演示 MyBatis 比较重要的一个特性 – 动态 SQL。除了以上所述,有些特性由于没有比较好的场景去演示,这里也就不介绍了。比如 MyBatis 的插件机制,缓存等。对于一些较为生僻的特性,比如对象工厂,鉴别器。如果不是因为阅读了 MyBatis 的文档和一些书籍,我还真不知道它们的存在,孤陋寡闻了。所以,对于这部分特性,本文也不会进行说明。
综上所述,本节所演示的是一个比较简单的示例,并非完整示例,望周知。
4.2 在 Spring 中使用
在上一节,我演示了单独使用 MyBatis 的过程。在实际开发中,我们一般都会将 MyBatis 和 Spring 整合在一起使用。这样,我们就可以通过 bean 注入的方式使用各种 Dao 接口。MyBatis 和 Spring 原本是两个完全不相关的框架,要想把两者整合起来,需要一个中间框架。这个框架一方面负责加载和解析 MyBatis 相关配置。另一方面,该框架还会通过 Spring 提供的拓展点,把各种 Dao 接口及其对应的对象放入 bean 工厂中。这样,我们才可以通过 bean 注入的方式获取到这些 Dao 接口对应的 bean。那么问题来了,具有如此能力的框架是谁呢?答案是mybatis-spring。那其他的不多说了,下面开始演示整合过程。
我的测试项目是基于 Maven 构建的,所以这里先来看一下 pom 文件的配置。
<project><!-- 省略项目坐标配置 --><properties><spring.version>4.3.17.RELEASE</spring.version></properties><dependencies><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.4.6</version></dependency><dependency><groupId>org.mybatis</groupId><artifactId>mybatis-spring</artifactId><version>1.3.2</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-core</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-beans</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-jdbc</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-test</artifactId><version>${spring.version}</version><scope>test</scope></dependency><!-- 省略其他依赖 --></dependencies>
</project>
为了减少配置文件所占的文章篇幅,上面的配置经过了一定的简化,这里只列出了 MyBatis 和 Spring 相关包的坐标。继续往下看,下面将 MyBatis 中的一些类配置到 Spring 的配置文件中。
<!-- application-mybatis.xml -->
<beans><context:property-placeholder location="jdbc.properties"/><!-- 配置数据源 --><bean id="dataSource" class="org.apache.ibatis.datasource.pooled.PooledDataSource"><property name="driver" value="${jdbc.driver}" /><property name="url" value="${jdbc.url}" /><property name="username" value="${jdbc.username}" /><property name="password" value="${jdbc.password}" /></bean><!-- 配置 SqlSessionFactory --><bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><!-- 配置 mybatis-config.xml 路径 --><property name="configLocation" value="classpath:mybatis-config.xml"/><!-- 给 SqlSessionFactory 配置数据源,这里引用上面的数据源配置 --><property name="dataSource" ref="dataSource"/><!-- 配置 SQL 映射文件 --><property name="mapperLocations" value="mapper/*.xml"/></bean><!-- 配置 MapperScannerConfigurer --><bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><!-- 配置 Dao 接口所在的包 --><property name="basePackage" value="xyz.coolblog.dao"/></bean>
</beans>
如上,上面就是将 MyBatis 整合到 Spring 中所需的一些配置。这里,我们将数据源配置到 Spring 配置文件中。配置完数据源,接下来配置 SqlSessionFactory,SqlSessionFactory 的用途大家都知道,不用过多解释了。再接下来是配置 MapperScannerConfigurer,这个类顾名思义,用于扫描某个包下的数据访问接口,并将这些接口注册到 Spring 容器中。这样,我们就可以在其他的 bean 中注入 Dao 接口的实现类,无需再从 SqlSession 中获取接口实现类。至于 MapperScannerConfigurer 扫描和注册 Dao 接口的细节,这里先不说明,后续我会专门写一篇文章分析。
将 MyBatis 配置到 Spring 中后,为了让我们的程序正常运行,这里还需要为 MyBatis 提供一份配置。相关配置如下:
<!-- mybatis-config.xml -->
<configuration><settings><setting name="cacheEnabled" value="true"/></settings><typeAliases><typeAlias alias="Article" type="xyz.coolblog.model.ArticleDO"/><typeAlias alias="Author" type="xyz.coolblog.model.AuthorDO"/></typeAliases><typeHandlers><typeHandler handler="xyz.coolblog.mybatis.ArticleTypeHandler" javaType="xyz.coolblog.constant.ArticleTypeEnum"/></typeHandlers>
</configuration>
这里的 mybatis-config.xml 和上一节的配置不太一样,移除了数据源和 SQL 映射文件路径的配置。需要注意的是,对于 <settings/> 必须配置在 mybatis-config.xml 中。其他的配置都不是必须项,可放在 Spring 的配置文件中,这里偷了个懒。
到此,Spring 整合 MyBatis 的配置工作就完成了,接下来写点测试代码跑跑看。
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:application-mybatis.xml")
public class SpringWithMyBatisTest implements ApplicationContextAware {private ApplicationContext applicationContext;/** 自动注入 AuthorDao,无需再通过 SqlSession 获取 */ @Autowiredprivate AuthorDao authorDao;@Autowiredprivate ArticleDao articleDao;@Beforepublic void printBeanInfo() {ListableBeanFactory lbf = applicationContext;String[] beanNames = lbf.getBeanDefinitionNames();Arrays.sort(beanNames);System.out.println();System.out.println("----------------☆ bean name ☆---------------");Arrays.asList(beanNames).subList(0, 5).forEach(System.out::println);System.out.println();AuthorDao authorDao = (AuthorDao) applicationContext.getBean("authorDao");ArticleDao articleDao = (ArticleDao) applicationContext.getBean("articleDao");System.out.println("-------------☆ bean class info ☆--------------");System.out.println("AuthorDao Class: " + authorDao.getClass());System.out.println("ArticleDao Class: " + articleDao.getClass());System.out.println("\n--------xxxx---------xxxx---------xxx---------\n");}@Testpublic void testOne2One() {ArticleDO article = articleDao.findOne(1);AuthorDO author = article.getAuthor();article.setAuthor(null);System.out.println();System.out.println("author info:");System.out.println(author);System.out.println();System.out.println("articles info:");System.out.println(article);}@Testpublic void testOne2Many() {AuthorDO author = authorDao.findOne(1);System.out.println();System.out.println("author info:");System.out.println(author);System.out.println();System.out.println("articles info:");author.getArticles().forEach(System.out::println);}@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.applicationContext = applicationContext;}
}
如上代码,为了证明我们的整合配置生效了,上面专门写了一个方法,用于输出ApplicationContext中bean的信息。下面来看一下testOne2One测试方法的输出结果。
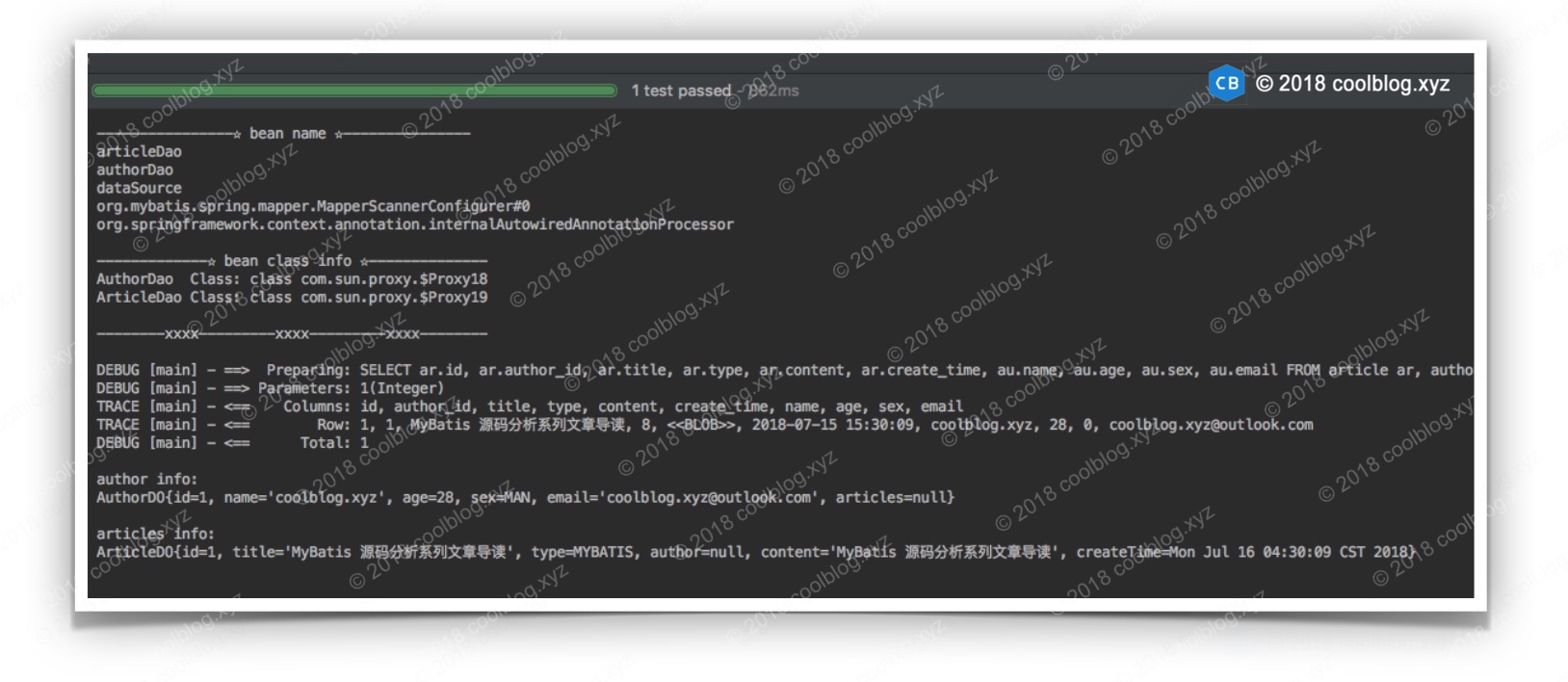
如上所示,bean name 的前两行就是我们的 Dao 接口的名称,它们的实现类则是 JDK 的动态代理生成的。然后testOne2One方法也正常运行了,由此可知,我们的整合配置生效了。
5.总结
到此,本篇文章就接近尾声了。本篇文章对 MyBatis 是什么,为何要使用,以及如何使用等三个方面进行阐述和演示。总的来说,本文的篇幅应该说清楚了这三个问题。本篇文章的篇幅比较大,读起来应该比较辛苦。不过好在内容不难,理解起来应该没什么问题。本篇文章的篇幅超出了我之前的预期,文章太大,出错的概率也会随之上升。所以如果文章有错误的地方,希望大家能够指明。
好了,本篇文章就到这里了,感谢大家的阅读。
参考
- MyBatis 官方文档
- 《MyBatis从入门到精通》- 刘增辉
- MyBatis和Hibernate相比,优势在哪里?- 知乎
- mybatis 与 hibernate 的区别和应用场景 - 无法确定文章作者,就不贴链接了,请自行搜索
原文地址:https://www.tianxiaobo.com/2018/07/16/MyBatis-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%E7%B3%BB%E5%88%97%E6%96%87%E7%AB%A0%E5%AF%BC%E8%AF%BB/