文章目录
- 问题
- 并发消费
- 触发时机
- 客户端发起请求 CONSUMER_SEND_MSG_BACK
- Broker处理CONSUMER_SEND_MSG_BACK请求
- 顺序消费
- Q&A
- 消费的时候是一批的消息, 如果其中某条消费失败了,是所有的消息都会被重试吗?
- 用户可以自己控制重试次数、重试间隔时间吗?
- 批量消费消息,能否自己控制重试的起始偏移量?比如10条消息,第5条失败了,那么只重试第5条和后面的所有。
- 重试的消息是如何被重新消费的?
- 如果关闭了broker的写权限,对消息消费的重试有没影响?
问题
- 消费的时候是一批的消息, 如果其中某条消费失败了,是所有的消息都会被重试吗?
- 用户可以自己控制重试次数、重试间隔时间吗
- 批量消费消息,能否自己控制重试的起始偏移量?比如10条消息,第5条失败了,那么只重试第5条和后面的所有。
- 重试的消息是如何被重新消费的?
- 如果关闭了broker的写权限,对消息消费的重试有没影响?
- 如果一个Topic被相同ConsumerGroup 不同consumer 顺序消费和并发消费会怎么样?
更详细请看:Rocketmq并发消费失败重试机制
并发消费
触发时机
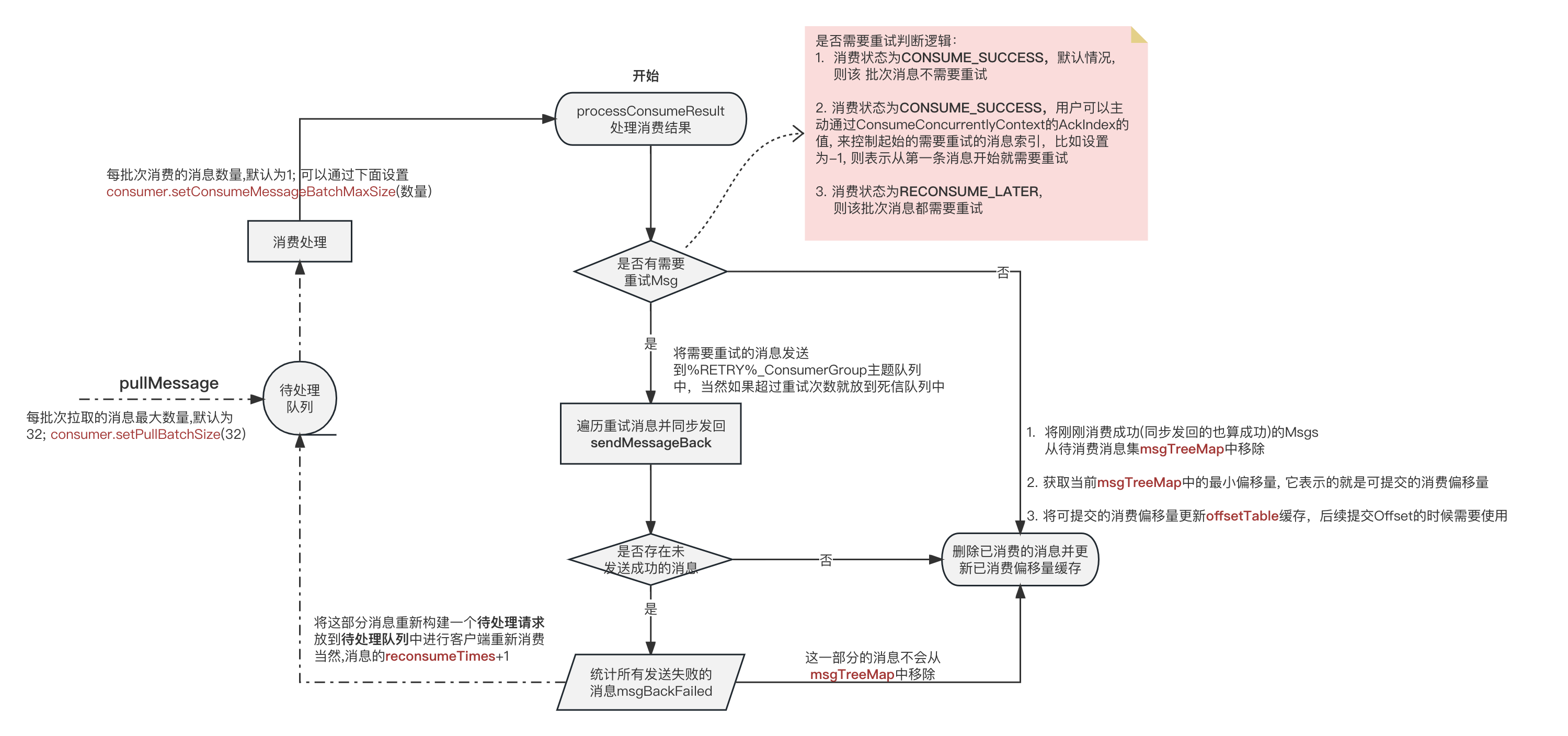
消费者在消费完成之后, 需要处理消费的结果, 是成功或失败
ConsumeMessageConcurrentlyService#processConsumeResult
/*** 石臻臻的杂货铺* vx: shiyanzu001**/public void processConsumeResult(final ConsumeConcurrentlyStatus status,final ConsumeConcurrentlyContext context,final ConsumeRequest consumeRequest){int ackIndex = context.getAckIndex();if (consumeRequest.getMsgs().isEmpty())return;switch (status) {case CONSUME_SUCCESS:if (ackIndex >= consumeRequest.getMsgs().size()) {ackIndex = consumeRequest.getMsgs().size() - 1;}// 这个意思是,就算你返回了消费成功,但是你还是可以通过设置ackIndex 来标记从哪个索引开始时消费失败了的;从而记录到 消费失败TPS的监控指标中;int ok = ackIndex + 1;int failed = consumeRequest.getMsgs().size() - ok;this.getConsumerStatsManager().incConsumeOKTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), ok);this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), failed);break;case RECONSUME_LATER:ackIndex = -1;this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(),consumeRequest.getMsgs().size());break;default:break;}List<MessageExt> msgBackFailed = new ArrayList<>(consumeRequest.getMsgs().size());for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {MessageExt msg = consumeRequest.getMsgs().get(i);// Maybe message is expired and cleaned, just ignore it.if (!consumeRequest.getProcessQueue().containsMessage(msg)) {log.info("Message is not found in its process queue; skip send-back-procedure, topic={}, "+ "brokerName={}, queueId={}, queueOffset={}", msg.getTopic(), msg.getBrokerName(),msg.getQueueId(), msg.getQueueOffset());continue;}boolean result = this.sendMessageBack(msg, context);if (!result) {msg.setReconsumeTimes(msg.getReconsumeTimes() + 1);msgBackFailed.add(msg);}}if (!msgBackFailed.isEmpty()) {consumeRequest.getMsgs().removeAll(msgBackFailed);this.submitConsumeRequestLater(msgBackFailed, consumeRequest.getProcessQueue(), consumeRequest.getMessageQueue());}//..... 部分代码省略....}
上面省略了部分代码, 上面代码是主要的针对发送失败的消息 发送回Broker的情况;
光看代码理解的意思如下
- 如果处理结果为CONSUME_SUCCESS,无需重试, 则记录一下监控指标, 消费成功TPS 、和 消费失败TPS ; 这里用户是可以自己通过设置
context.setAckIndex()来设置ACK的索引值的; 比如你本批次消息量10条, 你这里设置为4; 则表示前面5条成功,后面5条失败; 当然了,这里并不会给失败的做重试; - 如果处理结果为RECONSUME_LATER, 则表示需要重试, 将该批次的所有消息遍历同步发送回Broker中; 如果某个同步请求失败,则会记录下来; 一会在本地客户端重新消费 ;
- 将这些消息从 待消费消息TreeMap中移除掉(同步发回Broker请求失败除外),并获得当前TreeMap中最小的值;
- 更新本地缓存中的已消费偏移量的值; 以便可以提交消费Offset
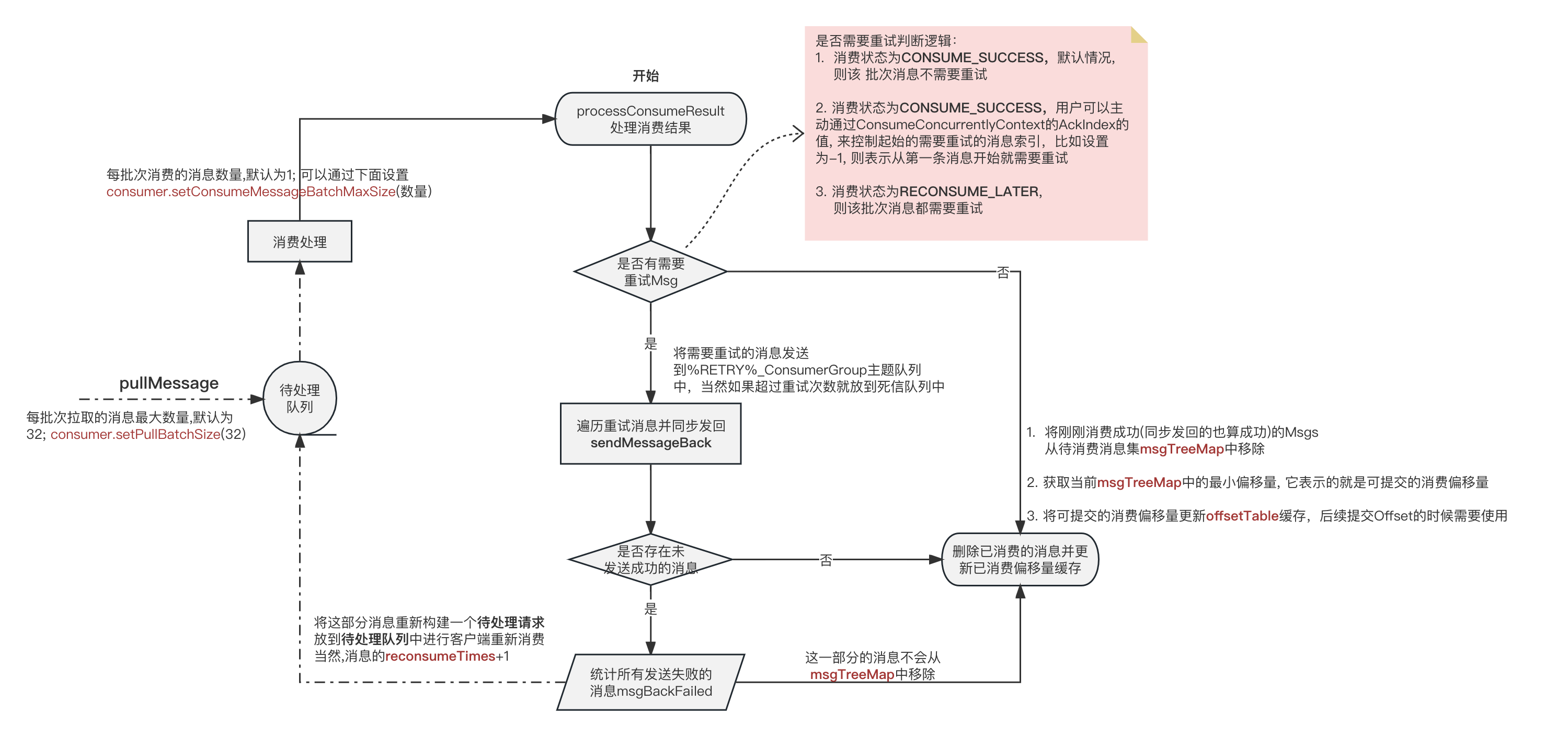
看图,再讲几个重点
-
需要重试的消息, 会优先被发回重试队列中,发送成功之后它会被当做消费成功, 这样做的目的是为了不要让某个消息消费失败就阻碍了整个消费Offset的提交;
比如, 1、2、3、4 四条消息, 第1条消费失败,其他都成功, 那么就因为最小的Offset 1 失败了导致后面的都不能标标记为成功去提交。
所以让1也设置为成功,就不会成为阻塞点,当然要把它发送到重试队列中等待重试。 -
可提交的消费Offset的值永远是TreeMap中的最小值, 这个TreeMap存放的就是pullMessage获取到的所有待消费Msg。消费成功就删除。
比如, 1、2、3、4 四条消息。1、2 消费成功删除了,那么最小的就是3这个偏移量,那么它之前的都可以提交了;如果2、3、4都消费成功并且删除了,但是1还在,那么可提交的偏移量还是当前最小的值1 ;
用户可自己决定从哪条消息开始重试
上面其实已经说了, 用户可以通过入参ConsumeConcurrentlyContext来设置ackIndex控制重试的起始索引;
/*** 石臻臻的杂货铺* vx: shiyanzu001**/consumer.registerMessageListener((MessageListenerConcurrently) (msg, context) -> {System.out.printf(" ----- %s 消费消息: %s 本批次大小: %s ------ ", Thread.currentThread().getName(), msg, msg.size());for (int i = 0; i < msg.size(); i++) {System.out.println("第 " + i + " 条消息, MSG: " + msg.get(i));try{// 消费逻辑}catch(Exception e){// 这条消息失败, 从这条消息以及其后的消息都需要重试context.setAckIndex(i-1);return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}} return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;});
PS: 目前所看为版本(5.1.3), 笔者始终觉得ackIndex这个设置有点问题;
- 消费成功的时候,设置ackIndex才会生效,既然用户返回的都是成功,则表示它并不需要重试; 设置这个值总感觉很别扭。
- 消费失败的时候,ackIndex被强制设置为了-1,表示所有的都要重试, 正常情况来说,批量消费的时候,碰到其中一条失败,那么就应该从这条的索引开始往后的消息都需要重试,前面已经消费的并且成功的并不需要重试;
关于这一点,我更倾向于这是一个Bug; 或者设计缺陷
优化建议:
- 为了兼容之前的逻辑,成功的状态的逻辑就不去修改了
- 失败的情况,没有必要强制设置为-1,导致全部重试, 让用户自己也能够通过ackIndex来设置重试的部分消息,而不用全部重试
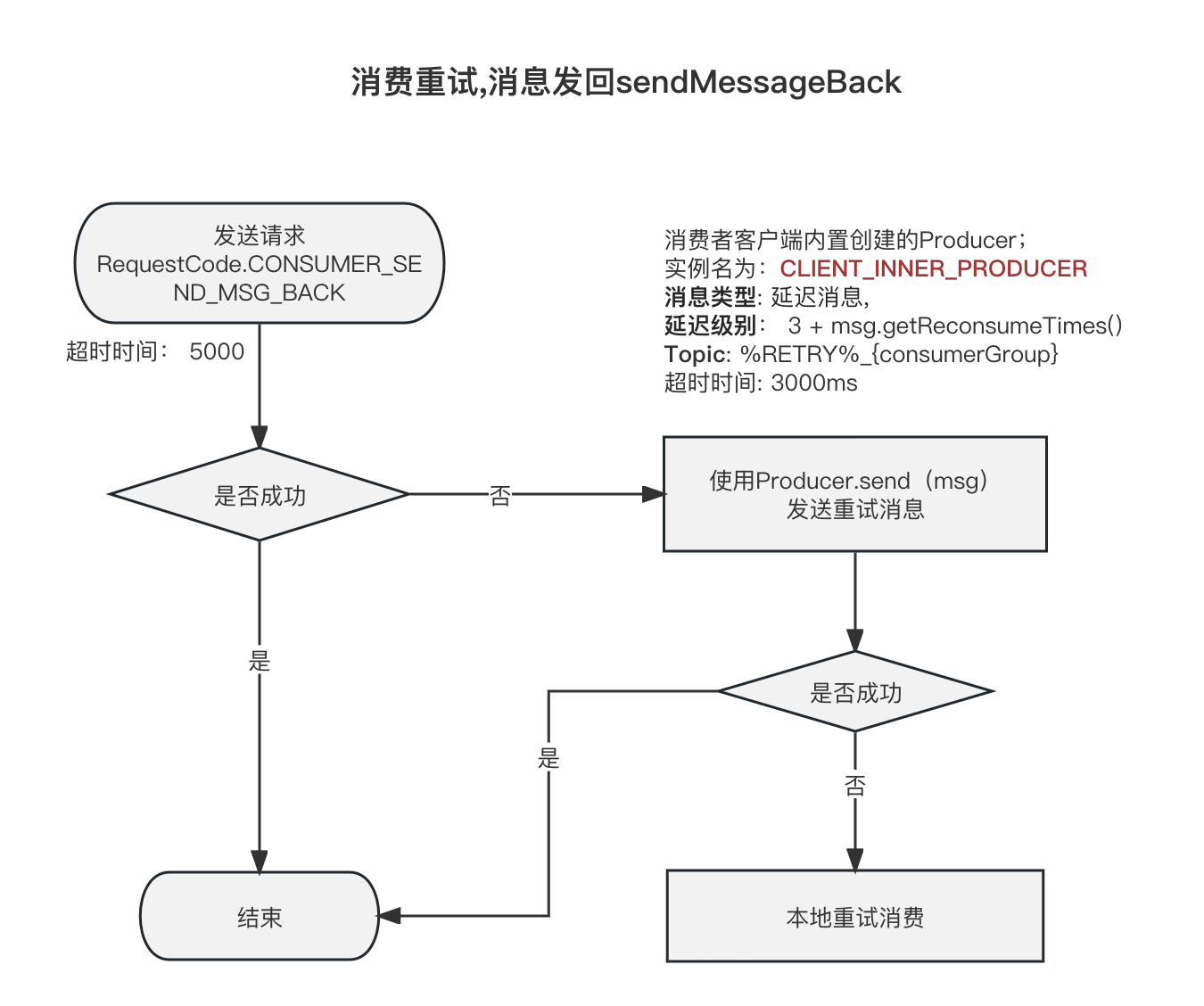
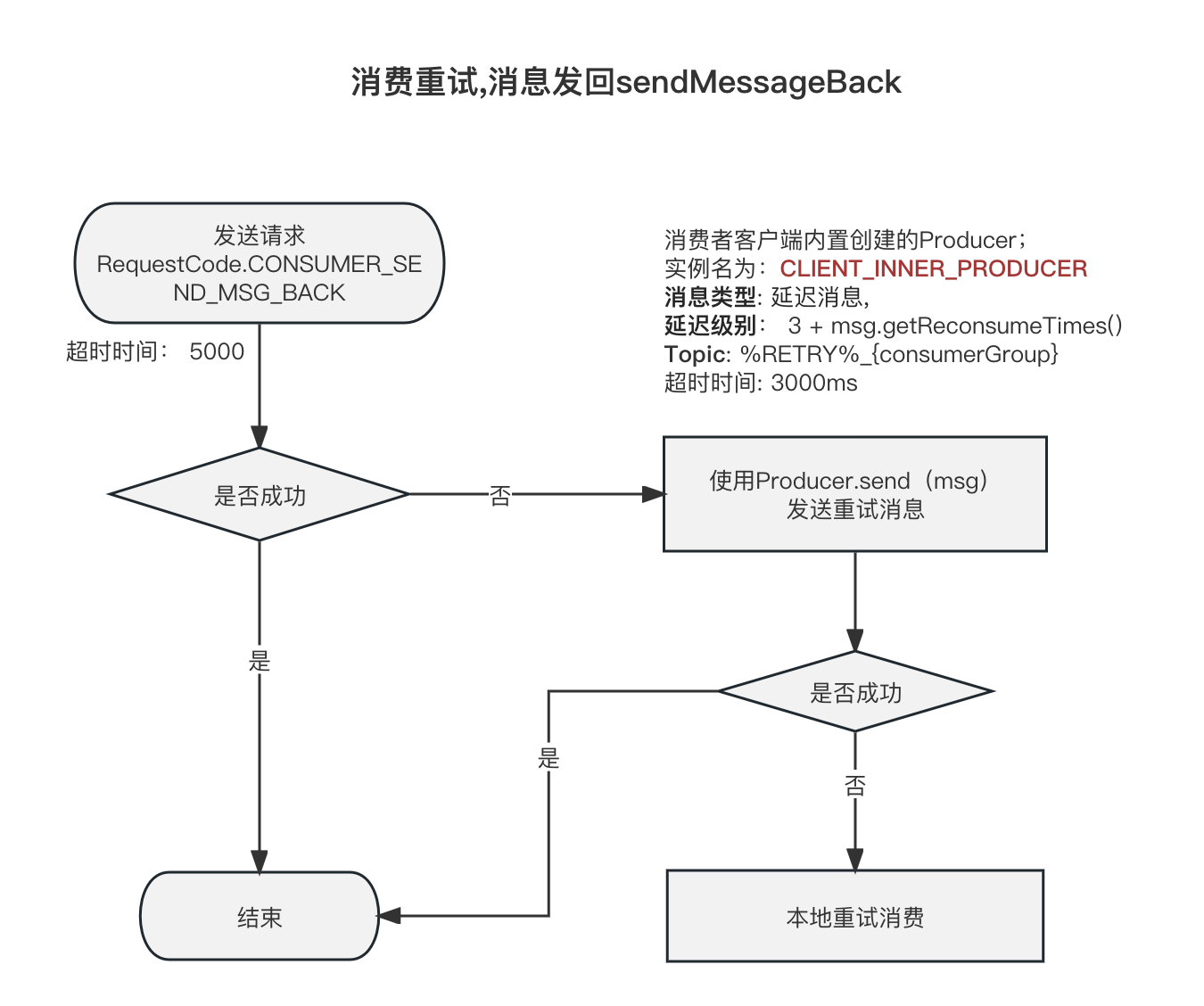
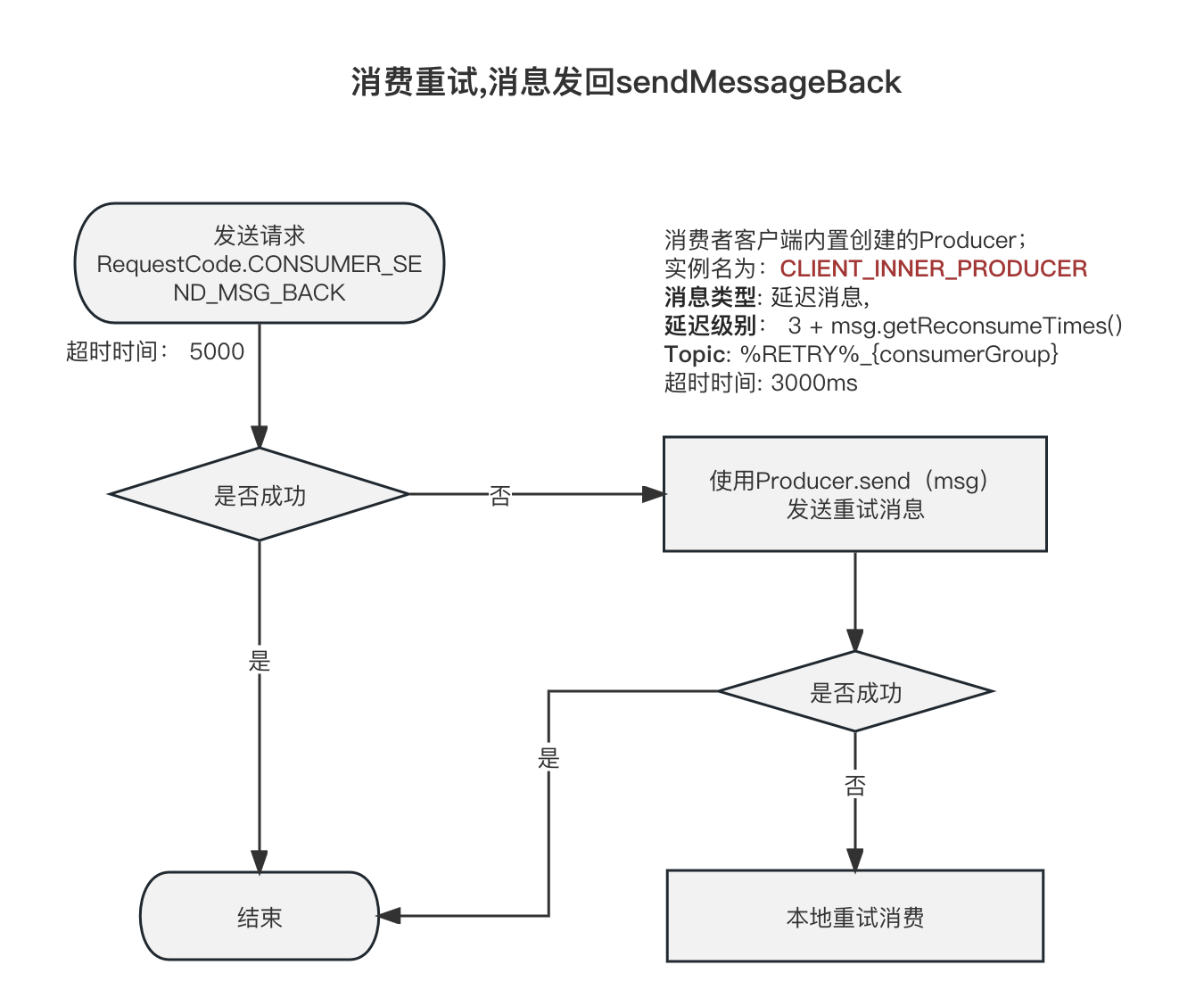
客户端发起请求 CONSUMER_SEND_MSG_BACK
如果该批次的消息消费失败, 则会尝试重试,
重试会尝试一条一条的把Message发回去
DefaultMQPushConsumerImpl#sendMessageBack
请求头 ConsumerSendMsgBackRequestHeader
| 属性 | 说明 |
|---|---|
| group | GroupName |
| originTopic | Topic |
| offset | 该消息的在Log中的偏移量 |
| delayLevel | 延迟重试等级;也是重试策略级别;[-1:不重试,直接放到死信队列中、0:Broker控制重试频率、>0 : 客户端控制重试频率 ] ; 如果大于0的情况,重试的时候会延迟对应的延迟等级(延迟消息); 如果是0的情况, 延迟等级为已经重试的次数+3, 意思是每重试一次延迟增加一个等级; 这里说的延迟等级就是18个级别的延迟消息 |
| originMsgId | 消息ID |
| maxReconsumeTimes | 最大重试次数,并发模式下,默认16;在有序模式下,默认 Integer.MAX_VALUE。 |
| bname | BrokerName |
目标地址
Message所在Broker的地址
msg.getStoreHost()
请求方式
同步请求
请求流程
/*** 石臻臻的杂货铺* wx: szzdzhp001**/private void sendMessageBack(MessageExt msg, int delayLevel, final String brokerName, final MessageQueue mq)throws RemotingException, MQBrokerException, InterruptedException, MQClientException {boolean needRetry = true;try {// 部分代码忽略....String brokerAddr = (null != brokerName) ? this.mQClientFactory.findBrokerAddressInPublish(brokerName): RemotingHelper.parseSocketAddressAddr(msg.getStoreHost());this.mQClientFactory.getMQClientAPIImpl().consumerSendMessageBack(brokerAddr, brokerName, msg,this.defaultMQPushConsumer.getConsumerGroup(), delayLevel, 5000, getMaxReconsumeTimes());} catch (Throwable t) {log.error("Failed to send message back, consumerGroup={}, brokerName={}, mq={}, message={}",this.defaultMQPushConsumer.getConsumerGroup(), brokerName, mq, msg, t);if (needRetry) {//以发送普通消息的形式发送重试消息sendMessageBackAsNormalMessage(msg);}} finally {msg.setTopic(NamespaceUtil.withoutNamespace(msg.getTopic(), this.defaultMQPushConsumer.getNamespace()));}}
- 首次发送的超时时间为 5000ms;请求是
RequestCode.CONSUMER_SEND_MSG_BACK - 如果上面的请求发送失败, 则兜底策略为,直接发送普通消息;但是Topic为%RETRY%{consumerGroup};延迟等级为
3 + msg.getReconsumeTimes(); 这里发送消息的Producer客户端是Consumer在构建实例的时候创建的内置的Producer客户端,客户端实例名是:CLIENT_INNER_PRODUCER; 这个发送也是同步发送;超时时间是3000 - 如果上面都失败了,抛出异常了,才会进行本地客户端重试消费(延迟5秒);
本地客户端重试是一直重试还是有次数限制?
如果一直失败,并且都是客户端重试,没有次数限制,并且每次都是延迟5秒消费;它会成为消费Offset的阻塞点;后续的消息都有被重新消费的可能性(比如客户端重启)
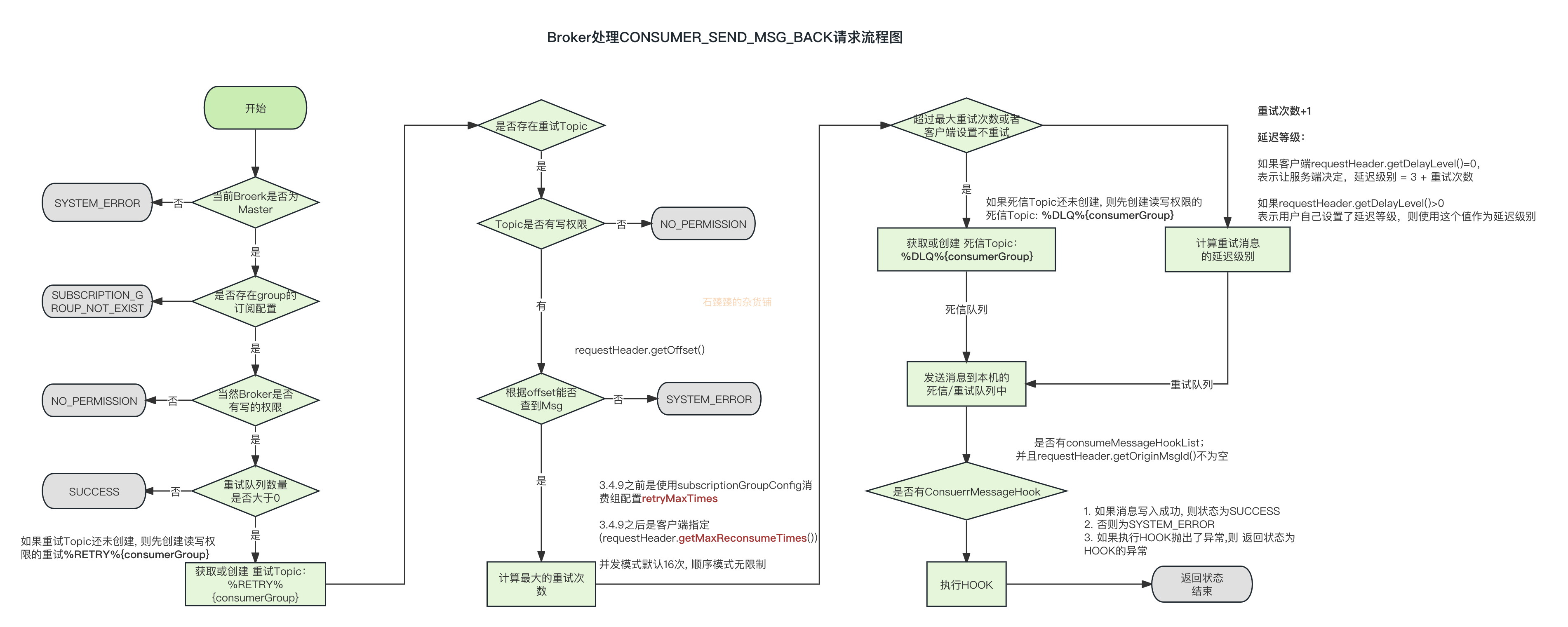
Broker处理CONSUMER_SEND_MSG_BACK请求
AbstractSendMessageProcessor#consumerSendMsgBack
- 如果当前Broker不是Master则返回系统异常错误码
- 如果消费Group订阅关系不存在则返回错误码
- 如果
brokerPermission权限不可写则返回无权限错误码 - 如果当前Group的重试队列数量
retryQueueNums<=0 返回无权限错误码 - 如果该Group的重新Topic不存在则创建一个,TopicName:%RETRY%GroupName;读写权限
- 根据入参
offset查找该Message; 如果没有查询到则返回系统异常错误码 - 如果该消息重试次数已经超过了最大次数,或者重试策略为不重试的话,则将消息发送到死信队列里面;死信队列Topic: %DLQ%GroupName
- 如果还没有超过重试次数, 则将消息发送到重试Topic里面:%RETRY%GroupName
- 如果有ConsumeMessageHook列表的话,则执行一下
consumeMessageAfter方法 - 返回Response。
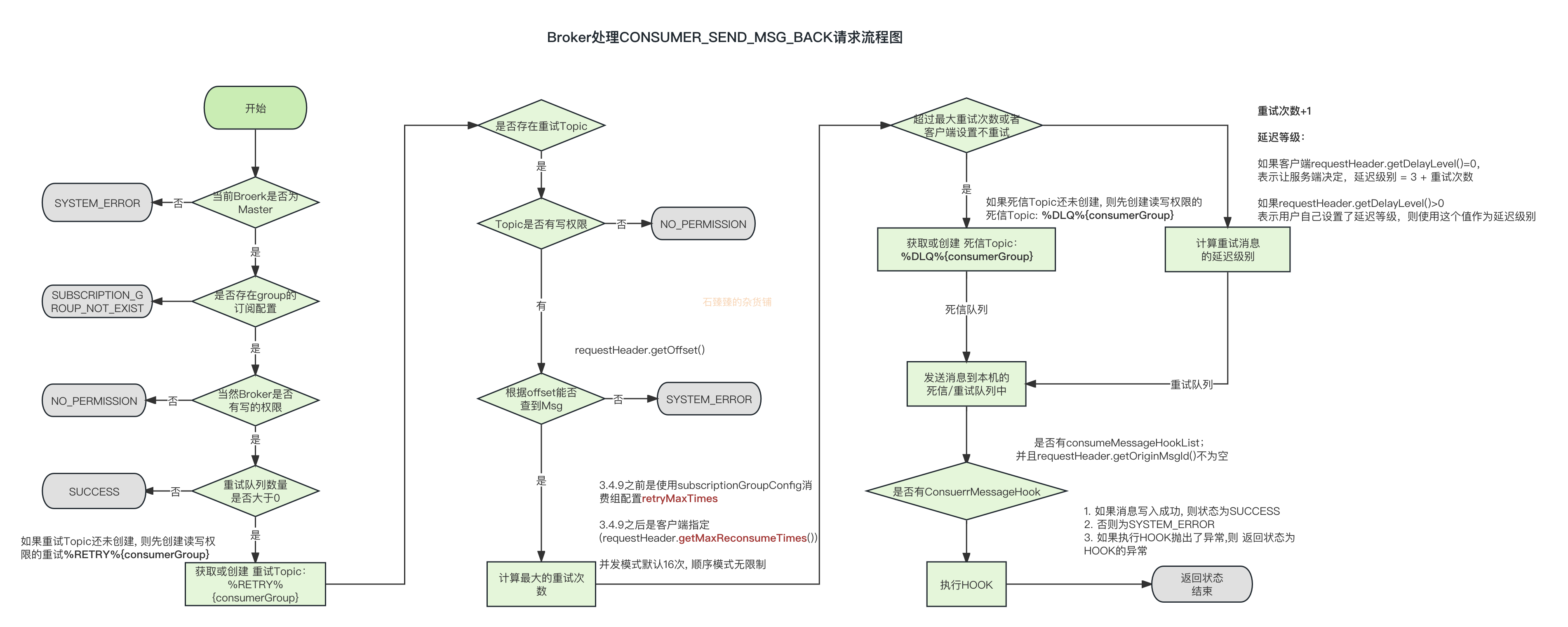
注意: 一条消息无论重试多少次,这些重试消息的 Message ID 不会改变。所以就需要我们消费者端做好消费幂等操作。
顺序消费
顺序消费完毕执行处理结果的流程
ConsumeMessageOrderlyService#processConsumeResult
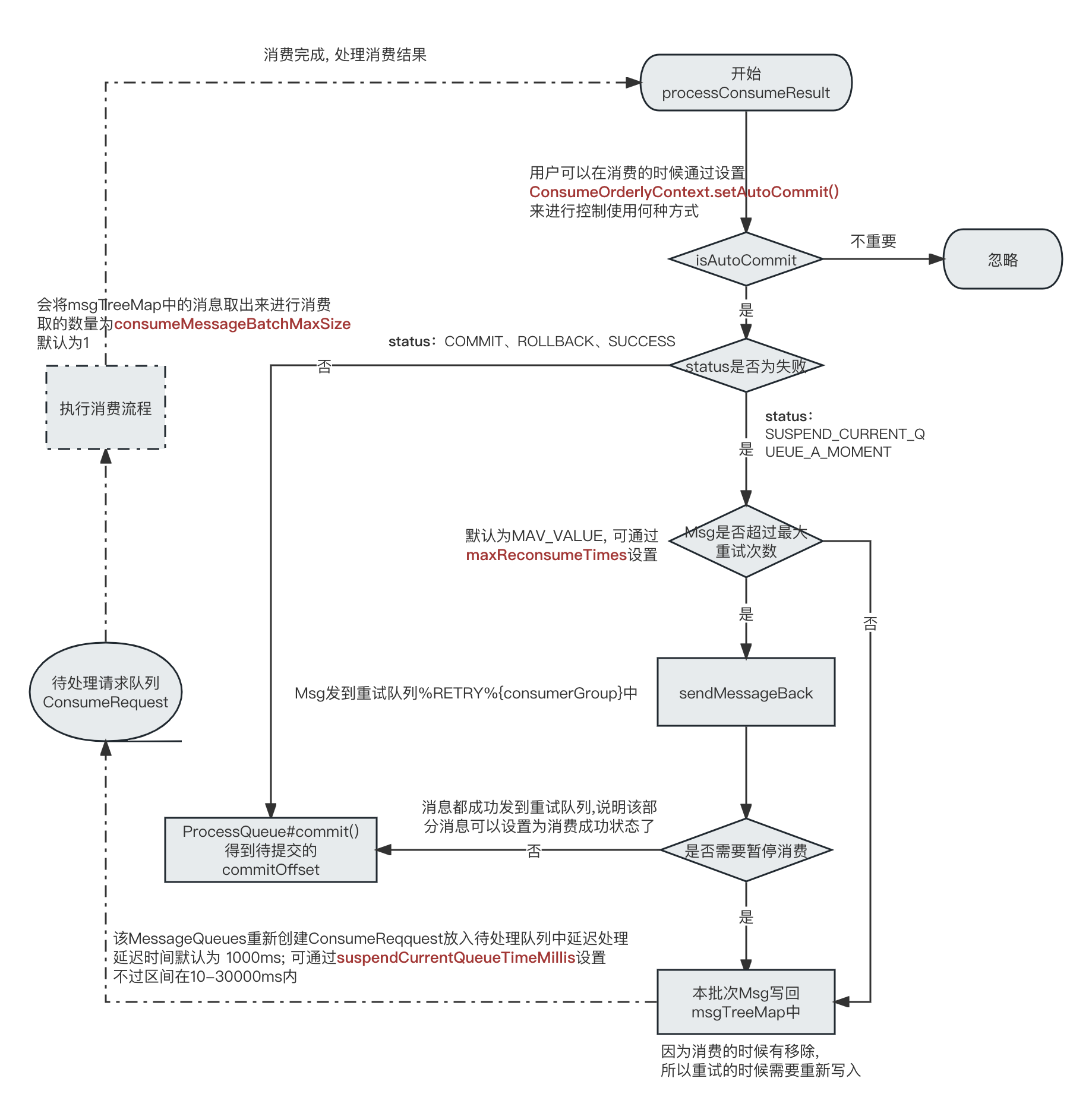
几个重要点
- 顺序消费针对同一个ProcessQueue只会有一个消费任务ConsumeRequest在执行
- 用户返回SUSPEND_CURRENT_QUEUE_A_MOMENT则会重试, 重试流程会根据是否超过最大重试次数来决定要不要讲消息发回重试队列中。
- 这个发回重试队列是直接使用的Consumer内置Producer实例直接向重试Topic %RETRY%{consumerGroup}发送的;
- 这个最大重试次数一般是INTEGER.MAXVALUE;所以一般不会超过,那么就会一直在本地重试,每次重试的时候都是延迟1s; 这个过程并不会将消息写回到Broker中。
- 如果某个消息一直消费失败, 那么整个队列消费都会被阻塞。
Q&A
消费的时候是一批的消息, 如果其中某条消费失败了,是所有的消息都会被重试吗?
如果在消费的时候,你返回的是ConsumeConcurrentlyStatus#RECONSUME_LATER, 则表示本次消费失败,需要重试,则本次分配到的Msgs都会被重试;
本次分配的Msgs数量是由consumer.setConsumeMessageBatchMaxSize(1)决定的;默认就是1;表示一次消费一条消息;
用户可以自己控制重试次数、重试间隔时间吗?
可以。
控制重试次数:
3.4.9 之前是使用subscriptionGroupConfig消费组配置retryMaxTimes
3.4.9 之后是客户端指定(requestHeader.getMaxReconsumeTimes())
这里可以通过Consumer#setMaxReconsumeTimes(最大次数)来设置值
并发模式默认16次重试的间隔时间:
默认情况下,都是Broker端来控制的重试间隔时间,间隔时间是用延迟消息来实现的,比如Broker端的延迟级别为3+重试次数; 默认情况下第一次重试对应的等级 3的时间间隔为:10s;
想要自定义重试的间隔时间的话,那么就需要自己在消费的时候来处理了,比如
/*** 石臻臻的杂货铺* vx: shiyanzu001**/consumer.registerMessageListener((MessageListenerConcurrently) (msg, context) -> {System.out.printf(" ----- %s 消费消息: %s 本批次大小: %s ------ ", Thread.currentThread().getName(), msg, msg.size());for (int i = 0; i < msg.size(); i++) {System.out.println("第 " + i + " 条消息, MSG: " + msg.get(i));if(消费失败){// 延迟等级5 = 延迟1分钟; context.setDelayLevelWhenNextConsume(5);// 或者你也可以根据重试的次数来递增延迟级别context.setDelayLevelWhenNextConsume(3 + msg.get(i).getReconsumeTimes());}// 需要重试return ConsumeConcurrentlyStatus.RECONSUME_LATER;}return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;});
批量消费消息,能否自己控制重试的起始偏移量?比如10条消息,第5条失败了,那么只重试第5条和后面的所有。
可以
但是目前仅限于返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS的情况。如果是返回的ConsumeConcurrentlyStatus.RECONSUME_LATER,则整批的消息都会重试。
具体,请看下面的代码
consumer.registerMessageListener((MessageListenerConcurrently) (msg, context) -> {System.out.printf(" ----- %s 消费消息: %s 本批次大小: %s ------ ", Thread.currentThread().getName(), msg, msg.size());for (int i = 0; i < msg.size(); i++) {System.out.println("第 " + i + " 条消息, MSG: " + msg.get(i));try{// 消费逻辑}catch(Exception e){// 这条消息失败, 从这条消息以及其后的消息都需要重试context.setAckIndex(i-1);return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}} return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;});
笔者认为,这里应该同样支持 消费失败(RECONSUME_LATER)的情况,来允许用户控制从哪个消息开始才需要重试。
重试的消息是如何被重新消费的?
需要重试的消息,会将消息写入到 %RETRY%{consumerGroup} 重试队列中,等延迟时间一到,客户端会重新消费这些消息。
如果超出重试次数,则会放入到死信队列%DLQ%{consumerGroup}中。不会再重试
如果关闭了broker的写权限,对消息消费的重试有没影响?
答: 有影响。
消费重试的机制是,先往Broker发回重试消息,如果你把写权限关闭了,那么这个流程就阻塞了,就会在本地客户端一直重试, 无限次数的延迟5s进行消费。
当然,如果一直本地重试的话,这个Msg就会成功消费的一个阻塞点,所有它后面的Offset就算被消费了,也提交不了。
所以关闭Broker写权限还是需要慎重。
更详细请看:Rocketmq并发消费失败重试机制








)

)








