目录
引言
一、GlusterFS简介
(一)基本介绍
(二)GlusterFS特点
(三)GlusterFS术语
(四)GlusterFS工作流程
二、GlusterFs的卷类型
(一)卷类型
(二)卷比较
三、部署GlusterFS群集
(一)磁盘分区
(二)修改主机名
(三)安装GlusterFS
1.准备好GlusterFS包
2.搭建yum仓库
3.yum安装
4.添加节点到存储信任池
5.创建卷
5.1 创建分布式卷
5.2 创建条带卷
5.3 创建复制卷
5.4 创建分布式条带卷
5.5 创建分布式复制卷
5.6 开启卷
6.卷操作
(二)客户端进行测试
1.客户端安装GlusterFS
2.挂载卷
3.创建测试文件
4.查看文件状态
5.模拟破坏测试
引言
在大数据时代背景下,随着企业与个人数据量的爆炸式增长,传统的单机文件系统已经无法满足日益增长的数据存储和访问需求。在此背景下,一种名为GlusterFS的开源分布式文件系统应运而生,以其卓越的可扩展性、高可用性和高性能特性,为海量数据存储提供了有力支持。本文将深入探讨GlusterFS的工作原理、核心特性以及实际应用场景
一、GlusterFS简介
(一)基本介绍
GlusterFS是一个完全开源、无中心设计的分布式文件系统,旨在构建大规模、弹性扩展、高性能的存储解决方案。它将多个物理存储设备汇聚成一个巨大的、虚拟的、全局统一命名空间的存储池,使得数据可以在整个集群中透明地分布和共享。
GlusterFS 是一个开源的分布式文件系统,它允许将多个物理存储设备(如硬盘)通过网络聚合在一起,形成一个大规模的、可扩展的、并行访问的存储池。GlusterFS 采用无中心的设计架构,没有单点故障,具备高可用性和高性能的特点。
在 GlusterFS 中,数据以分布式的、虚拟的、全局统一命名空间的方式进行管理。这意味着,无论实际的数据存储在集群中的哪个节点上,对用户来说都是透明的,可以像操作本地文件系统一样操作远程存储资源。
GlusterFS 主要适用于以下场景:
大规模数据存储:能够处理PB级的数据存储需求,且可以根据需要动态扩展存储容量。
高并发访问:通过多节点并行处理I/O请求,提高系统的读写性能和响应速度。
高可用性:支持多种冗余策略,确保在部分硬件故障时数据仍能正常访问
(二)GlusterFS特点
1.可扩展性和高性能
横向扩展:GlusterFS设计之初就考虑到了极高的可扩展性,能够通过添加更多的存储节点来轻松扩展存储容量和吞吐量,支持从几个TB到数PB级别的存储规模。
高性能:GlusterFS通过分布式并行处理I/O请求,优化了读写性能,特别是针对大数据集的读取操作,通过条带化、镜像和分布式复制等存储策略,可以大幅提升数据访问效率。
2.高可用性
无单点故障:GlusterFS没有中央元数据服务器,而是通过分布式元数据管理来避免单点故障,确保即使某个节点失效,整个文件系统仍然能够保持运行。
冗余和自动恢复:支持多种数据保护模式,包括复制、分布式复制和奇偶校验等,能够在节点故障时迅速恢复数据服务。
3.全局统一命名空间
提供了一个全局的、统一的文件命名空间,使得用户可以从单一入口点访问整个集群内的所有文件,简化了数据管理。
4.弹性卷管理
灵活的存储卷管理机制允许管理员根据业务需求调整存储策略,比如增加或减少冗余级别,或者动态地向现有卷添加新存储节点。
5.弹性哈希算法
使用弹性的哈希算法将数据分布在整个集群中,确保数据分布的均衡和高效定位。
6.标准协议支持
支持行业标准的网络协议,例如NFS、SMB/CIFS、HTTP/REST等,使得不同操作系统和应用程序都能够方便地访问存储资源。
7.POSIX兼容性
兼容POSIX标准,使得大多数符合POSIX要求的应用程序可以直接在GlusterFS之上运行。
8.用户空间设计
利用用户空间的FUSE(Filesystem in Userspace)技术,使得系统设计更加灵活,能够快速迭代和改进。
(三)GlusterFS术语
Brick: Bricks是GlusterFS中最基本的存储单元,它们通常是物理服务器上指定的目录路径。每个brick代表了一块存储空间,所有的brick组合起来形成了一个大的、分布式的存储池。
Volume: Volume是在GlusterFS中组织和管理存储的一种逻辑实体,它是由一个或多个brick组成,通过特定的存储模式(如分布式、复制、条带化等)将bricks联合起来,形成一个具有特定属性的虚拟文件系统。
Cluster: Cluster指的是连接在一起并参与GlusterFS服务的一组服务器节点。这些节点通过网络互相协作,共同提供存储服务。
FUSE:是一个内核模块,允许用户创建自己的文件系统,无须修改内核代码。
伪文件系统
VFS:内核空间对用户空间提供的访问磁盘的虚拟接口
(四)GlusterFS工作流程
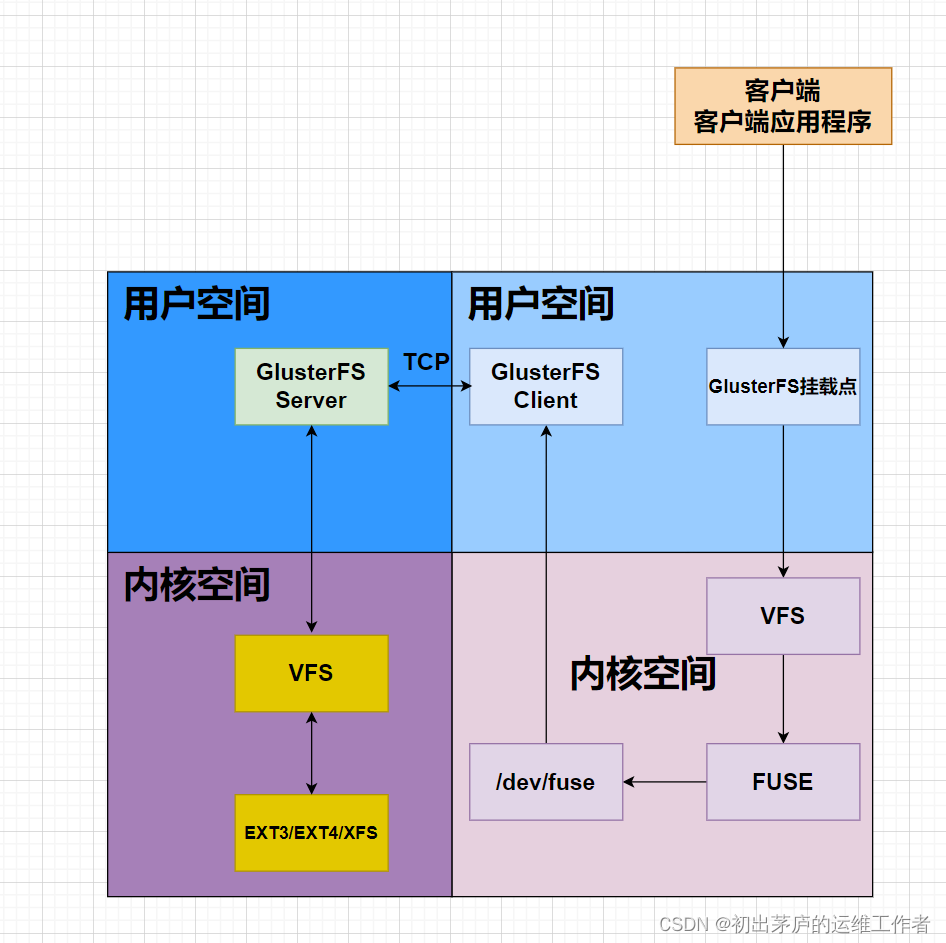
1.客户端访问数据
客户端或客户端应用程序访问GlusterFS
客户端通过挂载点访问GlusterFS分布式文件系统,就像访问常规的本地文件系统一样。
客户端应用程序发出对文件系统的读写请求。
2.操作系统内核处理
当客户端操作系统接收到应用程序的I/O请求时,它通过VFS层处理这个请求。
如果是Linux系统,客户端通常通过FUSE内核模块或内建的Kernel Module,因为FUSE只是一个伪文件系统,不能直接对接客户端,只能通过缓存区/dev/fuse与客户端对接
3.GlusterFS客户端
GlusterFS客户端负责将操作系统传递来的I/O请求转换为对GlusterFS服务端的调用。
客户端使用GlusterFS的API与集群中的各个节点进行通信,确定数据的位置。
根据GlusterFS的卷配置和弹性HASH算法,客户端计算出数据应该存储或读取的brick(存储节点)。
弹性HASH算法使得数据在多个brick之间均衡分布,且能在集群动态变化时重新分布数据。
4.数据传输
客户端通过网络将请求发送到对应的brick节点。
brick节点接收到请求后,通过VFS接口,在本地文件系统上执行相应的读写操作。
5.卷类型影响的处理方式
根据卷的类型(如分布式卷、复制卷、条带卷、分布式复制卷等),请求的处理方式会有所不同
6.返回结果
brick完成操作后,将结果通过网络传回给客户端。
客户端再将处理结果反馈给操作系统,进而由操作系统通知应用程序
二、GlusterFs的卷类型
(一)卷类型
GlusterFs的卷类型有七种:即分布式卷、条带卷、复制卷、分布式条带卷、分布式复制卷、条带复制卷和分布式条带复制卷。
分布式卷
又称哈希卷,文件通过散列函数(hash algorithm)分配到集群中的brick上,没有数据冗余,容量较大,但不具备容错能力。
条带卷
类似RAID0,文件被分割成多个数据块,均匀分布到各brick上,实现并行读写,提高性能,但也缺乏冗余,单个brick故障会导致数据丢失。
复制卷
类似RAID1,文件在多个brick上创建相同的副本,提供了数据冗余和高可用性,但磁盘利用率相对较低。
分布式条带卷
结合了分布式卷和条带卷的特点,文件被条带化后分布到多个brick上,可以获得更好的性能和一定的扩展性,但同样不自带冗余。
分布式复制卷
将分布式卷与复制卷结合,提供分布式存储的同时还保证数据的冗余。
条带复制卷
结合条带卷和复制卷,既能实现数据条带化以提高性能,又能做到数据的冗余备份。
分布式条带复制卷
综合了分布式、条带化和复制三种策略,提供最佳的性能和冗余
(二)卷比较
以上七种卷的类型,只需要掌握以下五种即可
| 卷类型 | 存储方式 | 冗余能力 | 应用场景 |
| 分布式卷 | 以文件为单位,将文件整个散列各个brick当中 | 不具备 | 当不需要数据冗余时,可以用于存储 大量的非关键数据 |
| 条带卷 | 将文件分块,通过轮询的方式,存放在各个brick当中 | 不具备 | 需要高可用性和数据安全性的场景, 如数据库和关键业务系统。 |
| 复制卷 | 将文件存放在某一个brick当中,另一个brick做镜像备份 | 具备 | 需要高带宽和并行读写性能的场景, 如流媒体服务、大数据分析等 |
| 分布式条带卷 | 结合了分布式和条带卷的特点,文件不仅在多个brick间分布,而且会将每个文件进行分块存储 | 不具备 | 分布式条带卷通常适用于对性能要求 很高,同时可以接受较低冗余度或通 过其他方式保证数据安全性的应用环 境,如高性能计算、大规模数据分析 和内容分发等 |
| 分布式复制卷 | 结合了分布式和复制卷的特点,文件不仅在多个brick间分布,而且在每个子卷内做复制,提供高可用性和扩展性 | 具备 | 既要扩展存储容量又要保证数据冗余 的复杂环境。 |
可根据不同的使用场景,选择不同的卷类型,提高效率
三、部署GlusterFS群集
环境准备
| 类型 | IP地址 | 主机名 | 磁盘设备 | 挂载点 |
| server1 | 192.168.83.30 | gfs1 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb /data/sdc /data/sdd /data/sde |
| server2 | 192.168.83.40 | gfs2 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb /data/sdc /data/sdd /data/sde |
| server3 | 192.168.83.50 | gfs3 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb /data/sdc /data/sdd /data/sde |
| server4 | 192.168.83.60 | gfs4 | /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 | /data/sdb /data/sdc /data/sdd /data/sde |
| 客户端 | 192.168.83.100 | gfs-client |
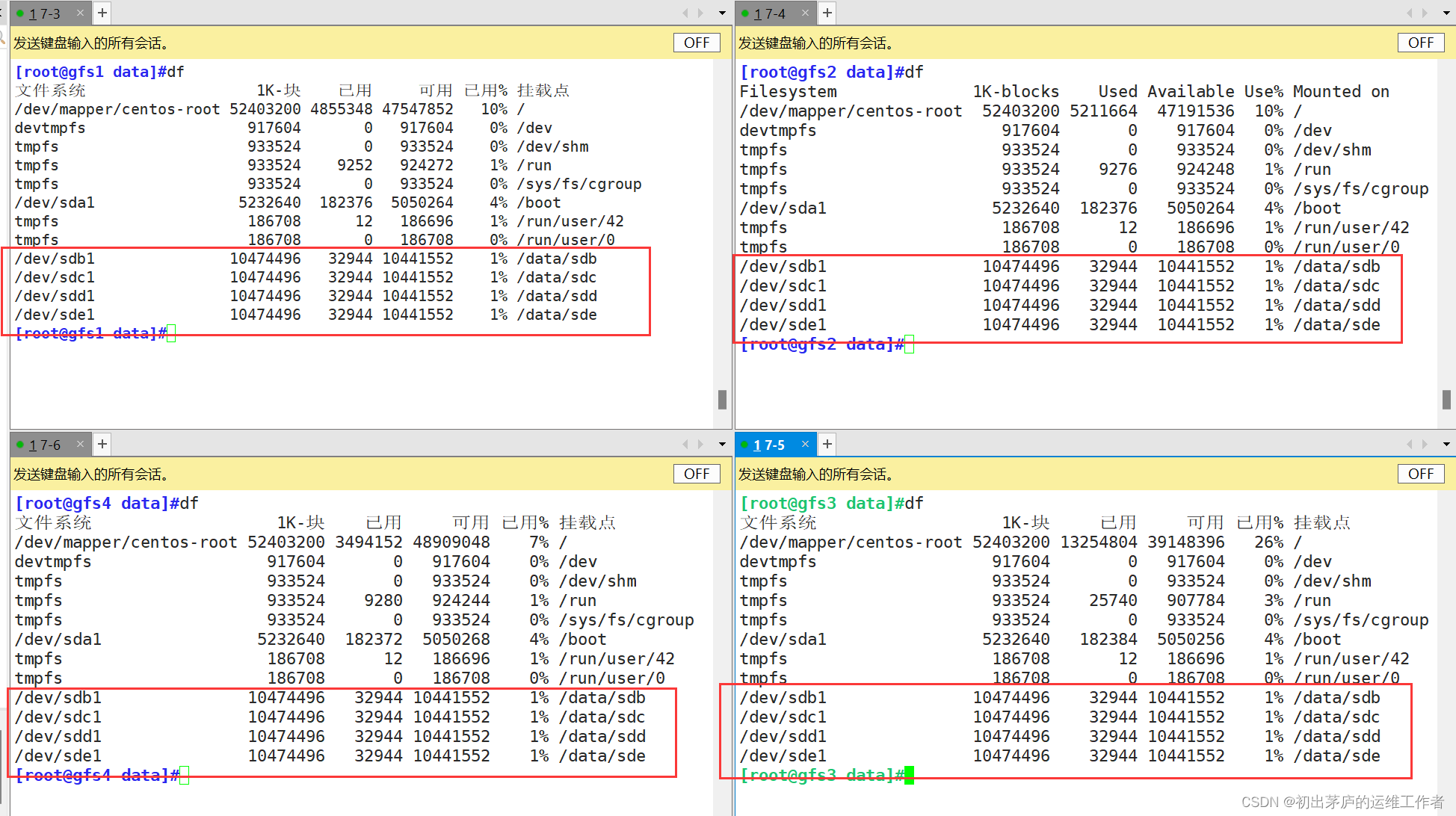
(一)磁盘分区
首先在每一台服务器上添加磁盘,并进行磁盘分区,而后进行挂载
#!/bin/bash
DEV=`ls /dev/sd* |grep -o 'sd[b-z]'|uniq`
#将ls /dev/sd* |grep -o 'sd[b-z]'|uniq得到的值,赋予DEV变量
for i in $DEV #使用循环脚本,进行磁盘分区
do
echo -e "n\np\n\n\n\nw\n" |fdisk /dev/${i} &>>/dev/null
#免交互式进行磁盘分区
mkfs.xfs /dev/${i}"1"&>> /dev/null
#格式化磁盘分区
mkdir -p /data/${i} &>>/dev/null
#在/data/目录下建立与磁盘同名的目录,用于挂载
echo "/dev/${i}1 /data/${i} xfs defaults 0 0" >> /etc/fstab
#将挂载信息导入fstab文件,做开启自动挂载
done
mount -a &>> /dev/null
#刷新挂载信息,将磁盘立即挂载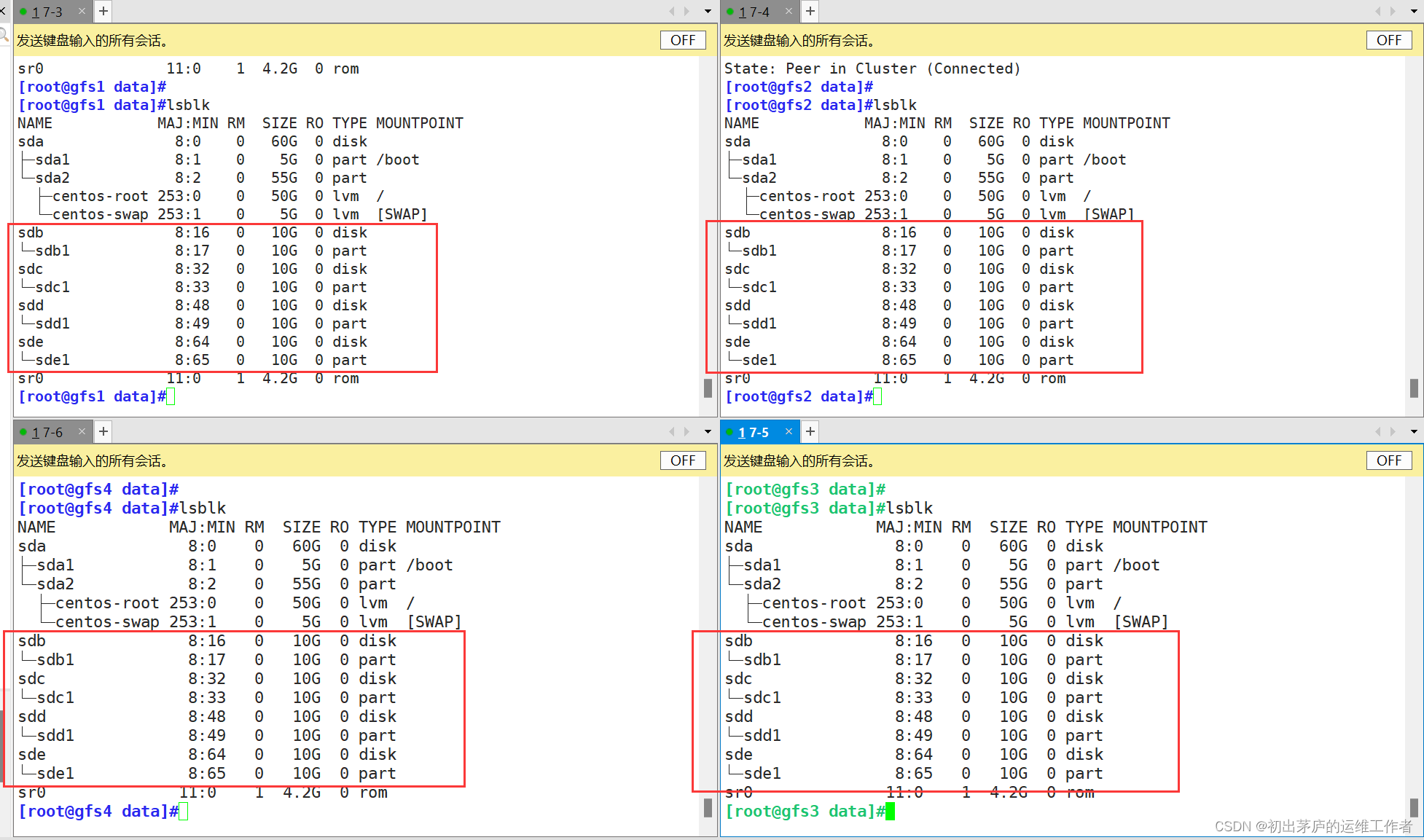
(二)修改主机名
在每一台server服务器上操作
修改主机名,并在/etc/hosts文件中添加相对应的IP地址与主机名

(三)安装GlusterFS
在所有节点上安装GlusterFS服务
1.准备好GlusterFS包
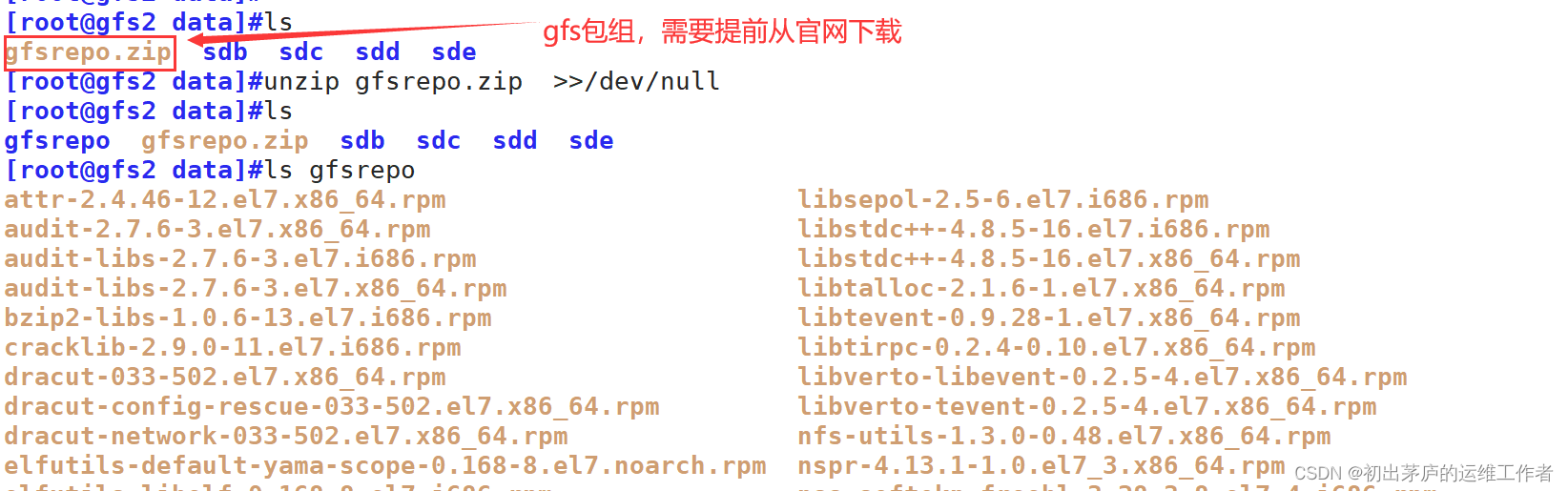
2.搭建yum仓库
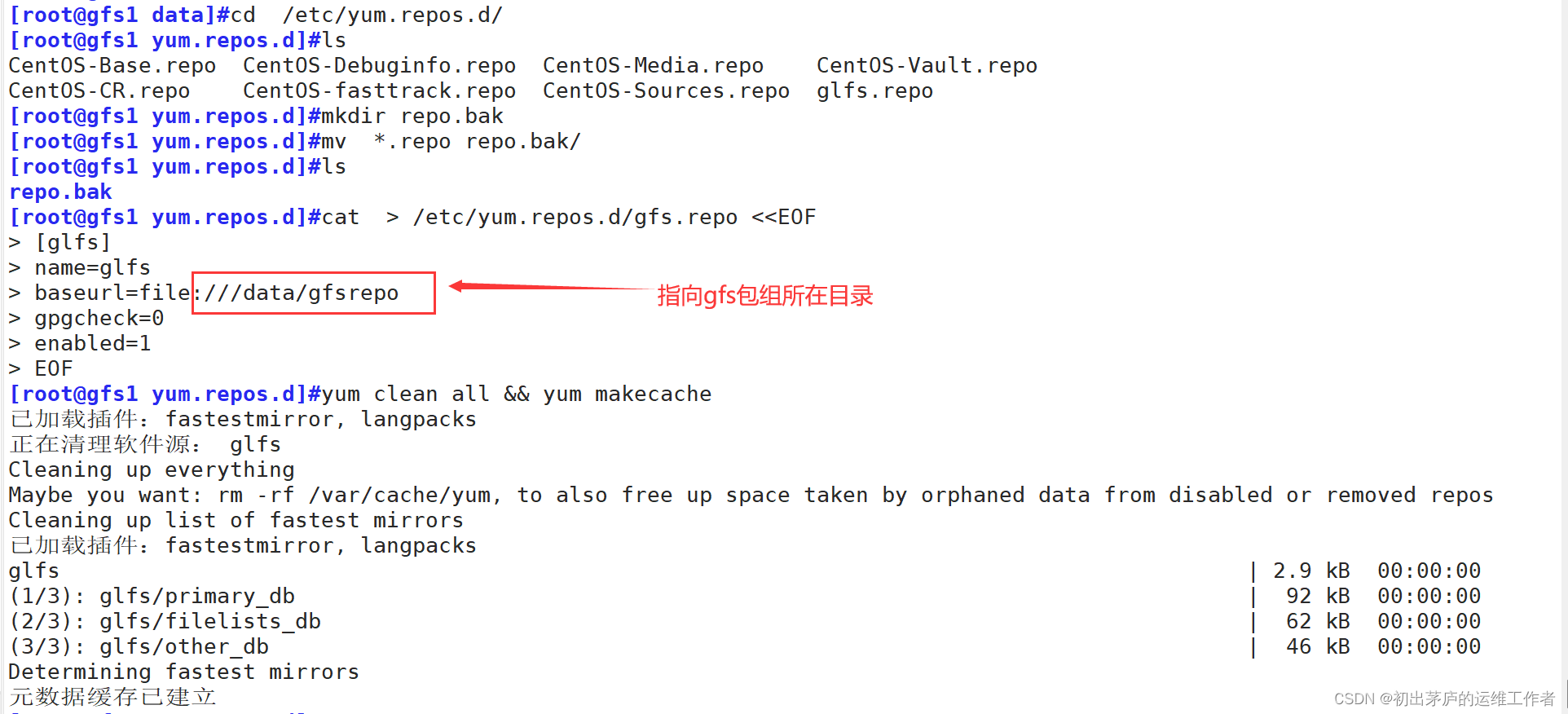
3.yum安装
直接安装会因为版本原因报错,需要先执行:
yum remove glusterfs-api.x86_64 glusterfs-cli.x86_64 glusterfs.x86_64 glusterfs-libs.x86_64 glusterfs-client-xlators.x86_64 glusterfs-fuse.x86_64 -y
将原先的服务进行移除,而后安装

每台服务器相同的操作,进行安装
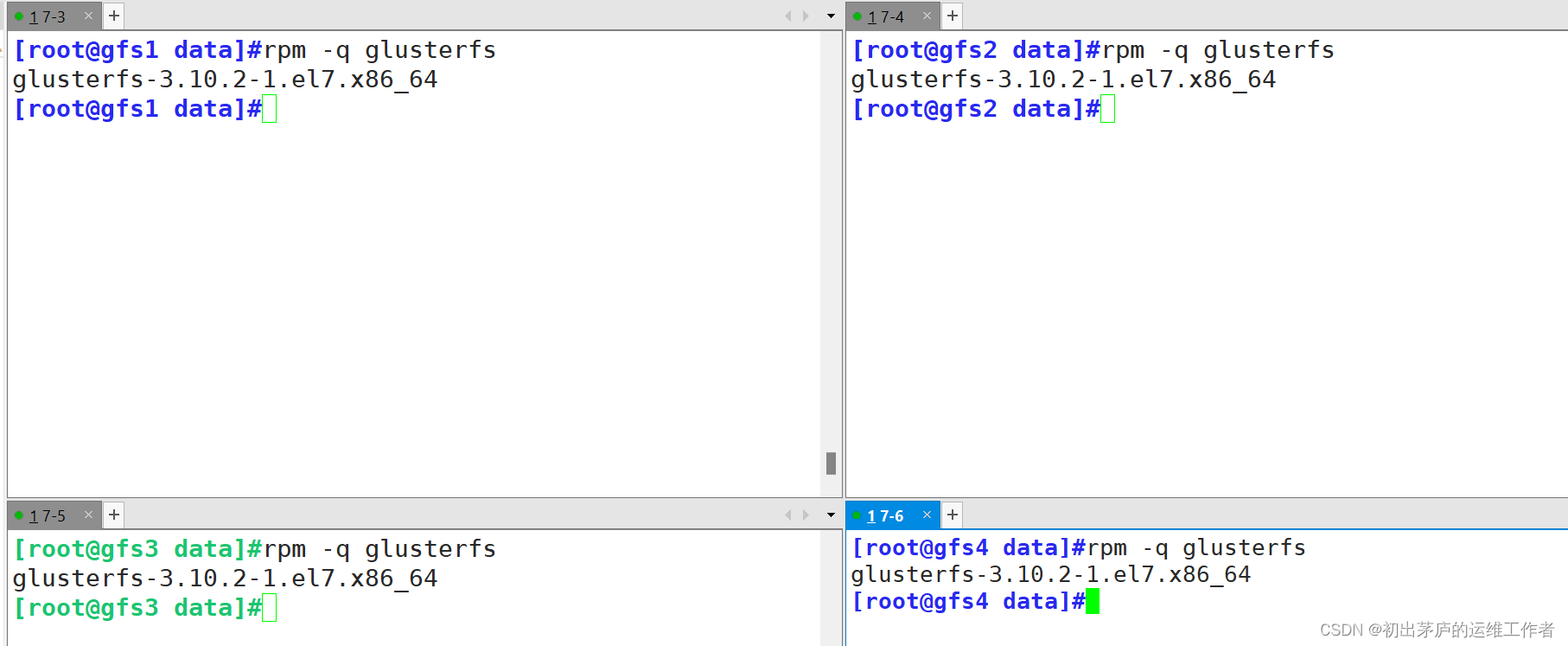
安装完毕后,启动服务
systemctl start glusterd.service
systemctl enable glusterd.service
4.添加节点到存储信任池
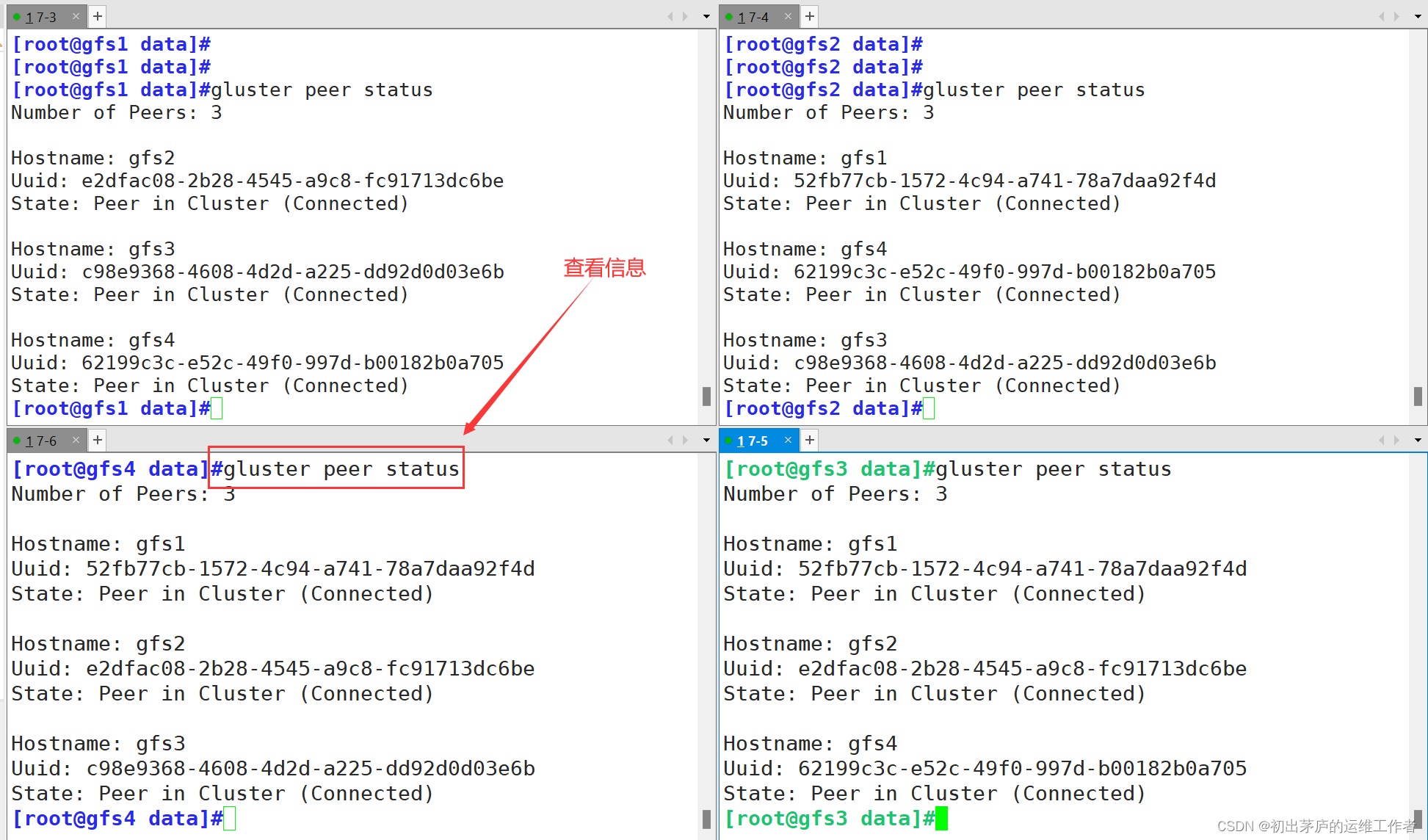
只需要在其中一台服务器进行操作,所有的服务器都会同步

在每个Node节点上查看群集状态
使用:gluster peer status 命令
5.创建卷
同样只需要在一台服务器上操作即可
创建卷的规划如下
| 卷类型 | 卷名 | brick |
| 分布式卷 | fb_volume | gfs1(/data/sdb)、gfs2(/data/sdb) |
| 条带卷 | td_volume | gfs1(/data/sdc)、gfs2(/data/sdc) |
| 复制卷 | fz_volume | gfs3(/data/sdb)、 gfs4(/data/sdb) |
| 分布式条带卷 | fbtd_volume | gfs1(/data/sdd)、gfs2(/data/sdd)gfs3(/data/sdd)、 gfs4(/data/sdd) |
| 分布式复制卷 | fbfz_volume | gfs1(/data/sde)、gfs2(/data/sde)gfs3(/data/sde)、 gfs4(/data/sde) |
5.1 创建分布式卷
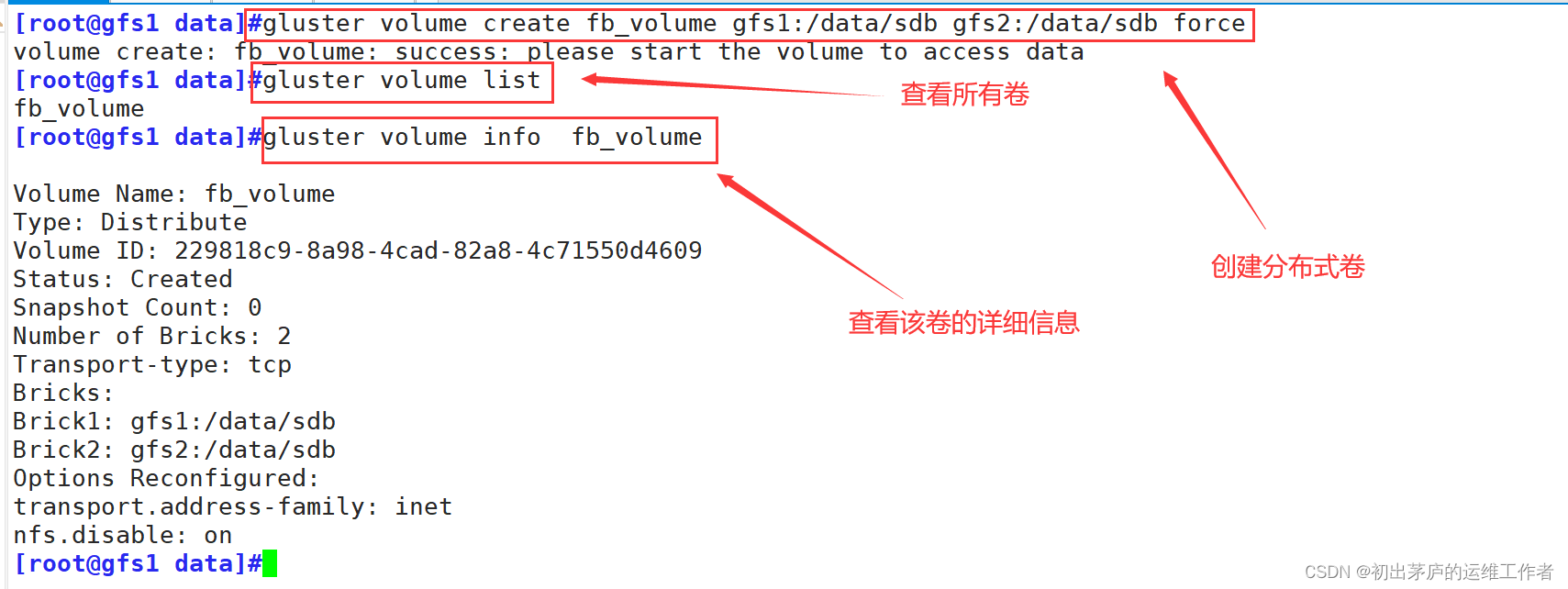
gluster volume create #创建卷
fb_volume #卷的名称,可以根据实际需求定义任意合适的卷名
gfs1:/data/sdb #表示集群中的一个节点(服务器)gfs1
gfs2:/data/sdb #同样的,gfs2节点上的/data/sdb目录也将作为卷的一部分
force #这是一个可选参数,用于强制创建卷5.2 创建条带卷
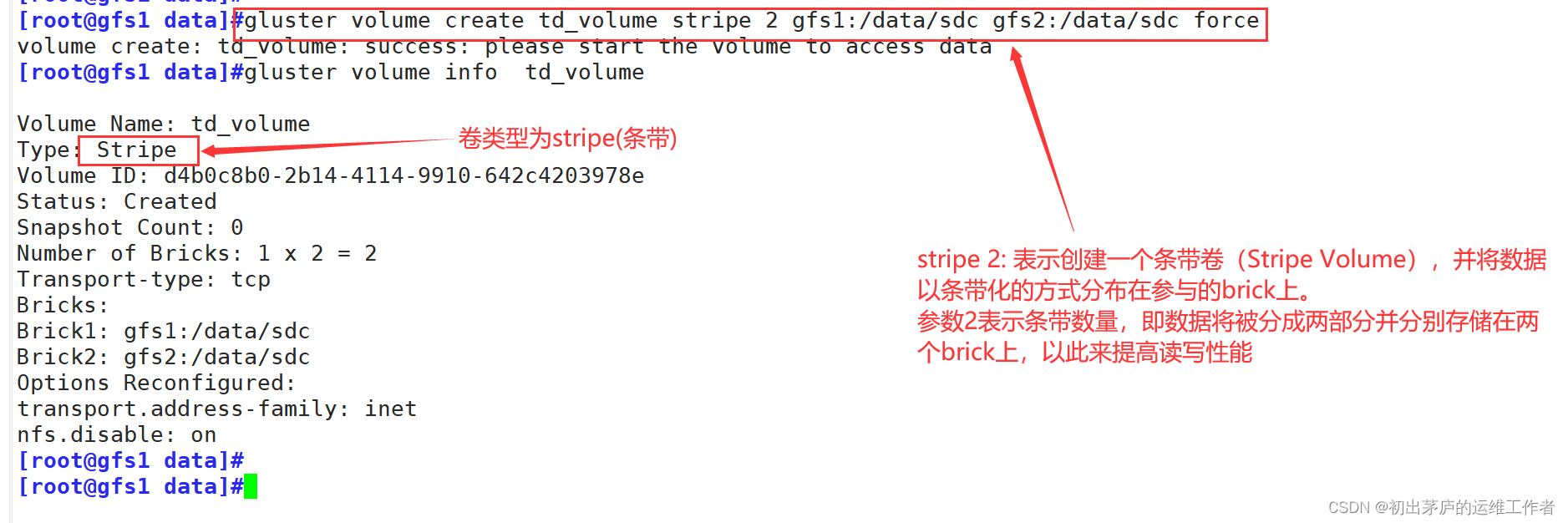
创建完条带卷后
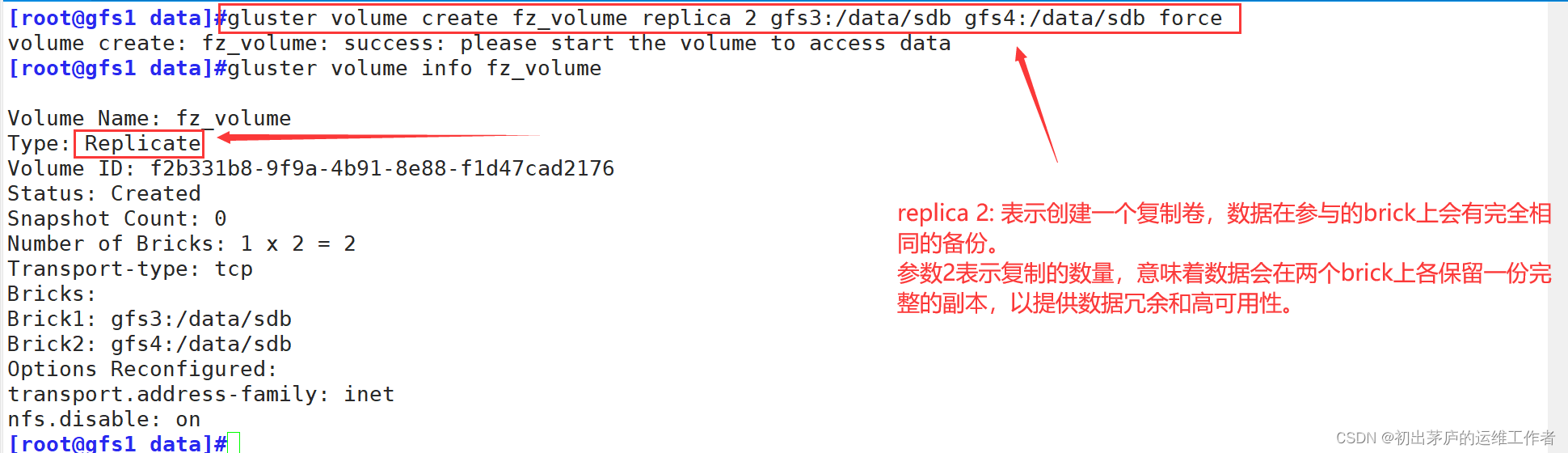
5.3 创建复制卷
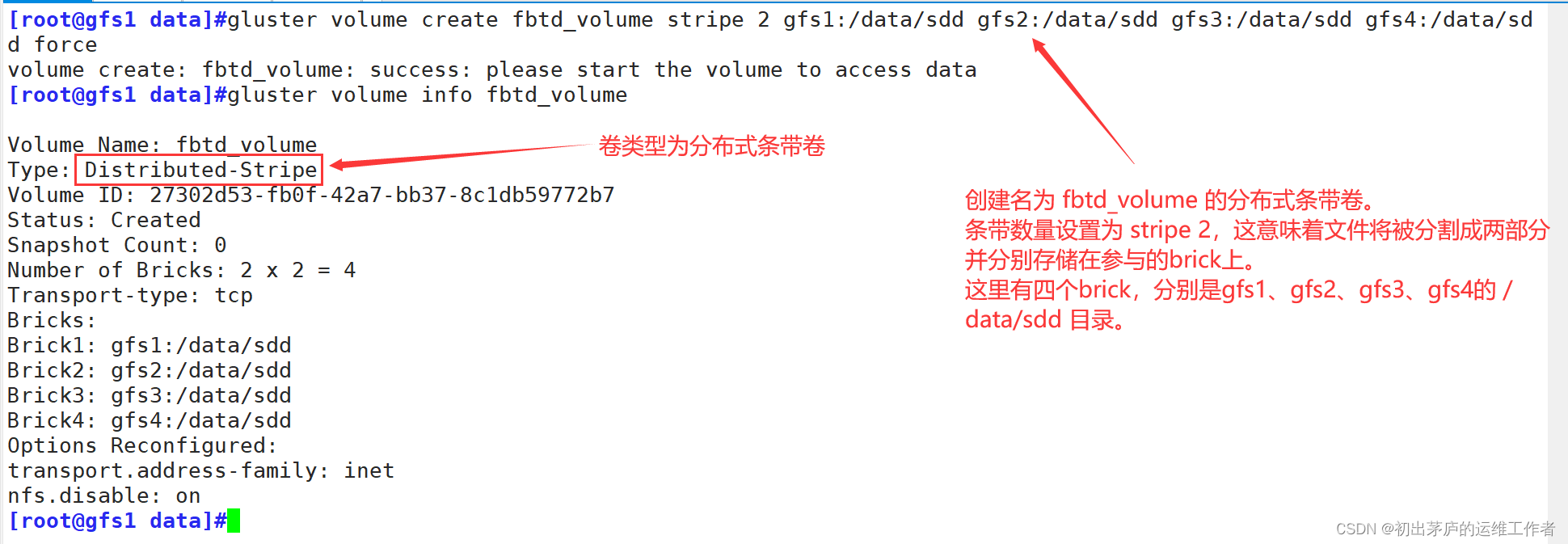
5.4 创建分布式条带卷
5.5 创建分布式复制卷

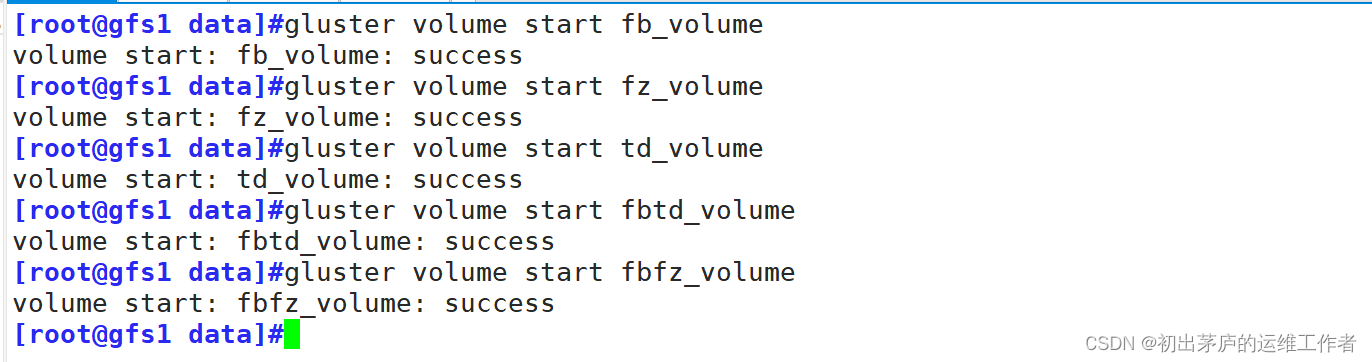
5.6 开启卷
创建完毕后,需要开启卷
命令格式为:gluster volume start volume_name

6.卷操作
查看GlusterFS卷
gluster volume list
查看所有卷的信息
gluster volume info x
查看所有卷的状态
gluster volume status
开启一个卷
gluster volume start volume_name
停止一个卷
gluster volume stop volume_name
删除一个卷
gluster volume delete volume_name
注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
设置卷的访问控制
仅拒绝
gluster volume set dis-rep auth.deny IP地址
(二)客户端进行测试
1.客户端安装GlusterFS
与客户端基本一致,首先需要准备好包组

搭建yum仓库

下载gluster客户端工具
yum remove glusterfs-api.x86_64 glusterfs-cli.x86_64 glusterfs.x86_64 glusterfs-libs.x86_64 glusterfs-client-xlators.x86_64 glusterfs-fuse.x86_64 -y >>/dev/null#移除最新版本,否则可能报错,新版本可能不支持条带卷yum -y install glusterfs glusterfs-fuse >>/dev/null#下载gluster客户端工具2.挂载卷
在客户端创建挂载目录

同样在/etc/hosts文件中添加域名解析信息
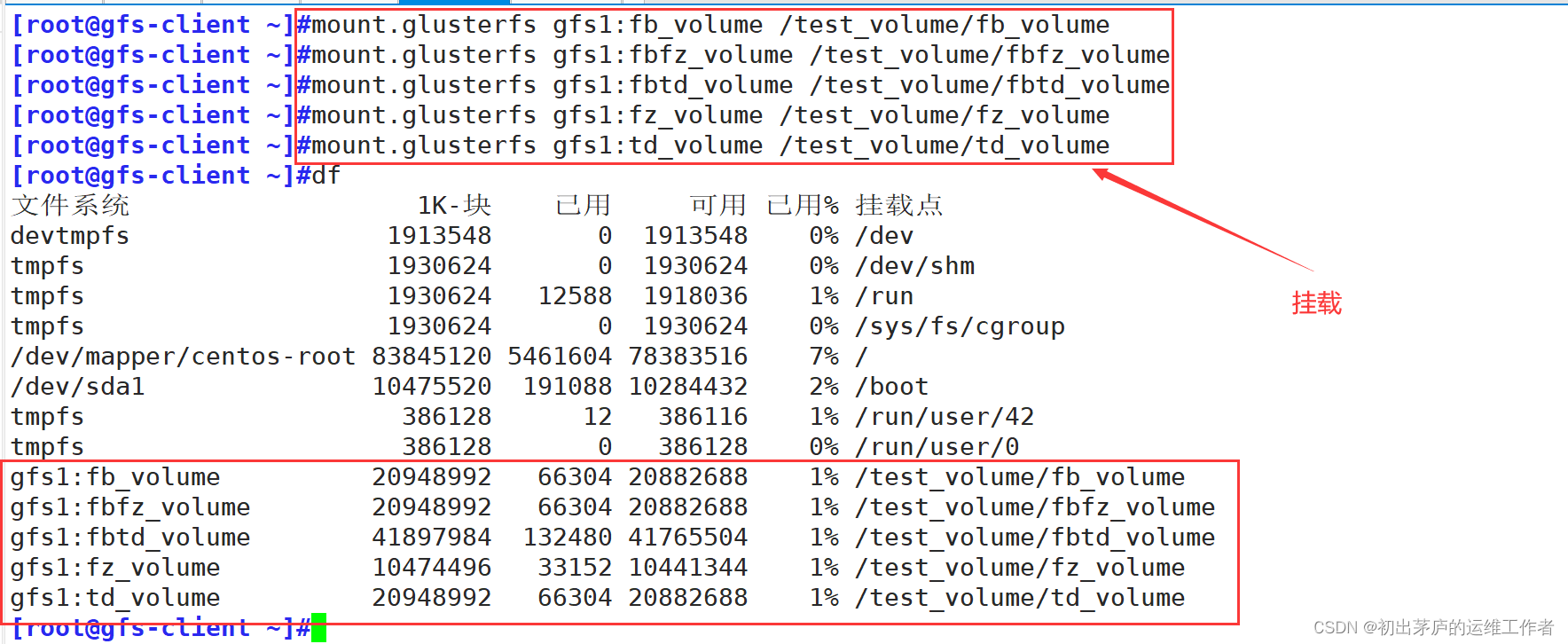
将各个卷一一进行挂载
使用mount.glusterfs工具进行挂载
3.创建测试文件
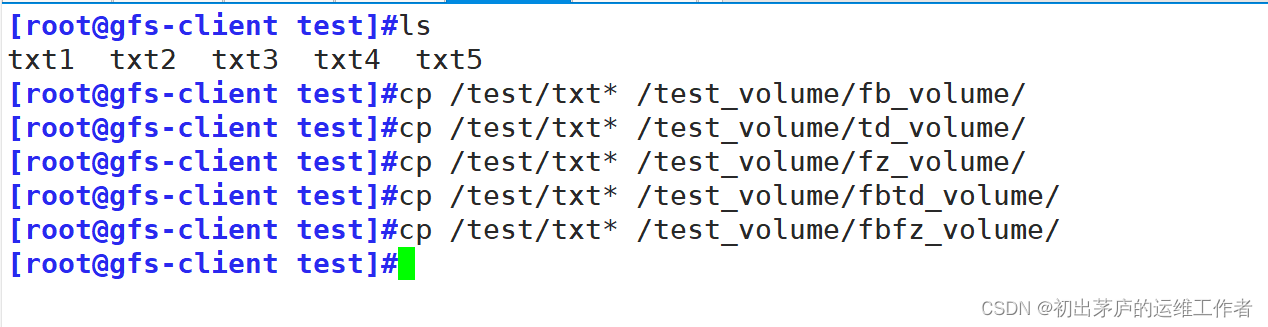
创建好文件后,将它们复制到各类卷挂载点当中
4.查看文件状态
在gluster服务器上查看文件存储的状态
4.1 查看分布式卷文件存储状态

可以看到,分布式卷,是将文件整个散列在卷的各个brick上,没有备份
4.2 查看条带卷文件存储状态

而条带卷是将文件进行分片,而后进行存储,简单来说就是一个文件,有几个brick,就会分成几份进行存储,没有备份
4.3 查看复制文件存储状态

复制卷会将文件整个存储在其中一个brick上,而后另一个brick进行映射复制,这样做的好处就是增强的数据的安全性,但是性能会有所降低
4.4 查看分布式条带卷文件存储状态
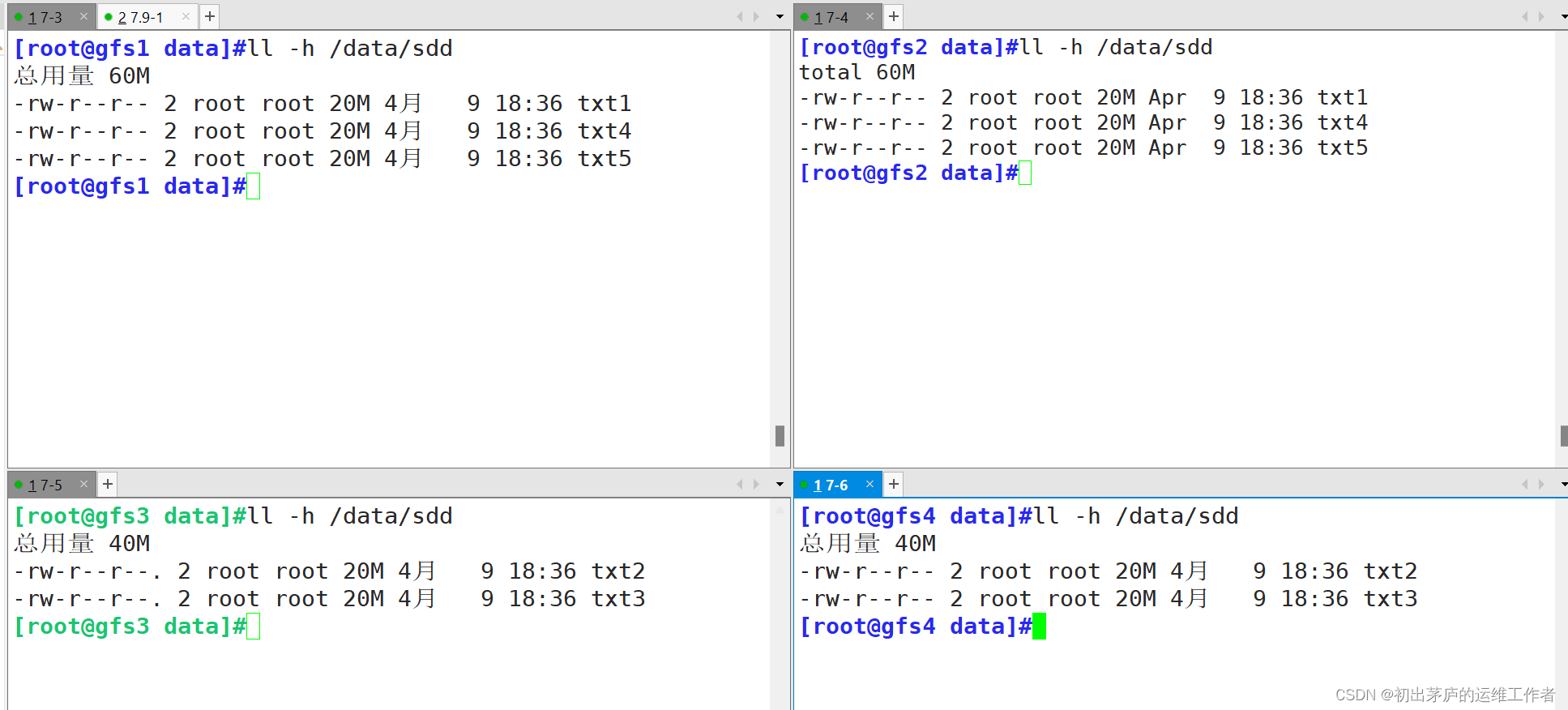
分布式条带卷,会将文件在多个brick中存储,而后进行分片
4.5 查看分布式复制卷文件存储状态
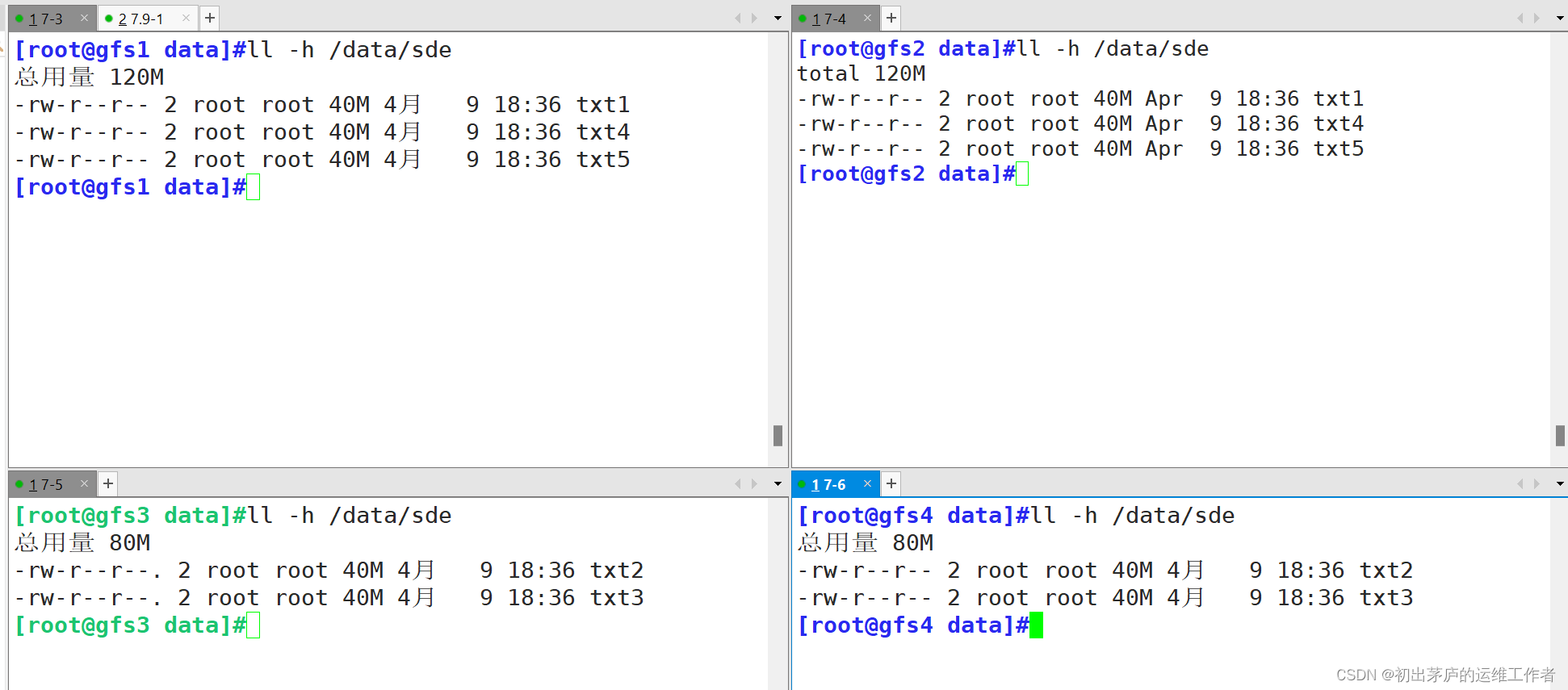
分布式复制卷,会将文件整个分布在各个brick中,而且会有对应的其它brick进行映射备份,即扩展了存储容量,又达到了备份效果
5.模拟破坏测试
首先关闭一个节点服务器,比如关闭gfs2
[root@gfs2 data]#shutdown #关机
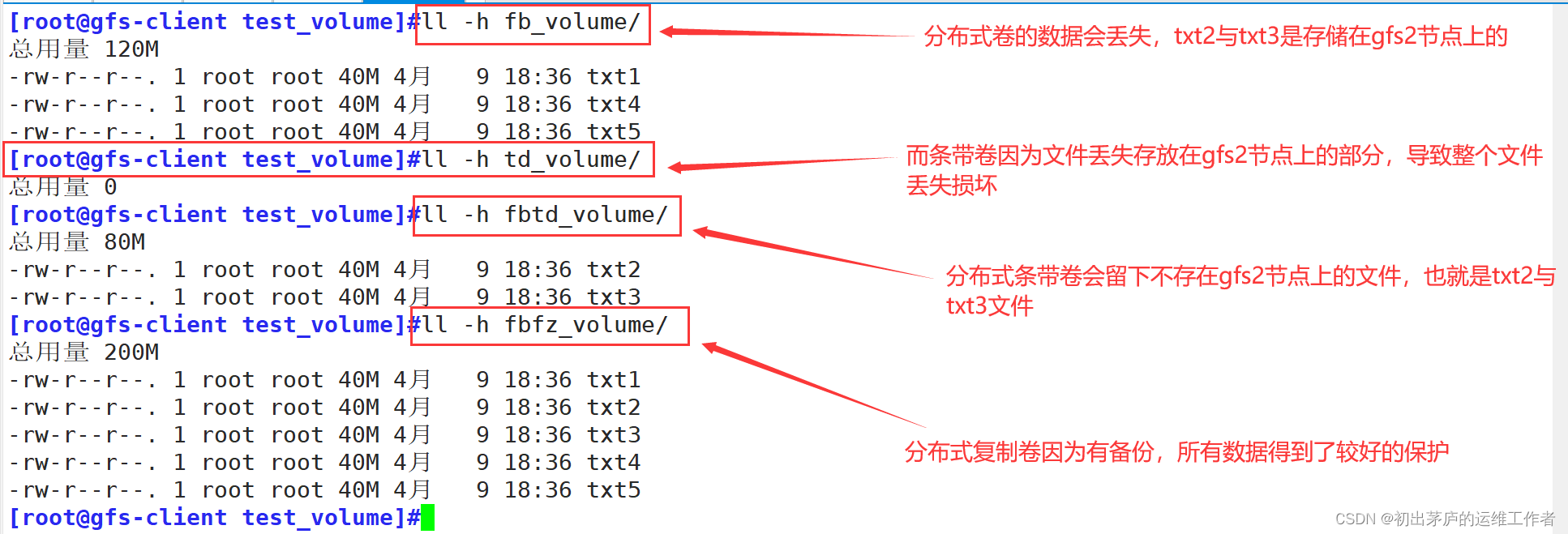
可以看出,有复制功能的卷,会较好的保护数据
总结
主要了解各种卷的类型与应用场景
| 卷类型 | 存储方式 | 冗余能力 | 应用场景 |
| 分布式卷 | 以文件为单位,将文件整个散列各个brick当中 | 不具备 | 当不需要数据冗余时,可以用于存储 大量的非关键数据 |
| 条带卷 | 将文件分块,通过轮询的方式,存放在各个brick当中 | 不具备 | 需要高可用性和数据安全性的场景, 如数据库和关键业务系统。 |
| 复制卷 | 将文件存放在某一个brick当中,另一个brick做镜像备份 | 具备 | 需要高带宽和并行读写性能的场景, 如流媒体服务、大数据分析等 |
| 分布式条带卷 | 结合了分布式和条带卷的特点,文件不仅在多个brick间分布,而且会将每个文件进行分块存储 | 不具备 | 分布式条带卷通常适用于对性能要求 很高,同时可以接受较低冗余度或通 过其他方式保证数据安全性的应用环 境,如高性能计算、大规模数据分析 和内容分发等 |
| 分布式复制卷 | 结合了分布式和复制卷的特点,文件不仅在多个brick间分布,而且在每个子卷内做复制,提供高可用性和扩展性 | 具备 | 既要扩展存储容量又要保证数据冗余 的复杂环境。 |











)


)




)