【中文医疗词嵌入模型】SMedBERT:结构化知识图谱 + 混合注意力机制 + 提及-邻居上下文建模
- 提出背景
- SMedBERT 具体到点的设计逻辑
- SMedBERT的背景
- SMedBERT的工作原理
- SMedBERT 具体实现细节
- 3.1 符号和模型
- 3.2 Top-K Entity Sorting
- 3.3 提及-邻居混合注意力
- 3.4 提及-邻居上下文建模
- 数据与效果
- 4.1 数据来源
- 4.2 基线
- 4.3 内在评价
- 4.4 下游任务结果
- 4.5 实体命中率的影响
- 4.6 邻近实体数量的影响
- 4.7 消融研究
提出背景
最近在做医学文本处理,最好是有一个医学嵌入模型,去重会准确很多,但找到的都是通用嵌入模型,不是医学嵌入模型。
人工是找不到了,让AI搜索找遍论文,才找到了SMedBERT。
论文:https://aclanthology.org/2021.acl-long.457.pdf
代码:https://github.com/MatNLP/SMedBERT
SMedBERT是一种融合了大规模医学文本和结构化医学知识图谱的预训练语言模型,通过专门设计的注意力机制和上下文建模显著提高了中文医学自然语言处理任务的性能。
SMedBERT 具体到点的设计逻辑
SMedBERT 面临的具体问题是中文医学领域的语言理解和信息提取准确度需要提高,特别是如何有效地从医学文本中学习并应用复杂的医学知识。
SMedBERT = 利用结构化知识图谱 + 混合注意力机制 + 提及-邻居上下文建模
-
子解法1:结构化知识图谱
- 之所以用结构化知识图谱,是因为医学术语和概念之间存在复杂的关系,这些关系可以通过结构化数据更准确地建模。
- 例如,通过知识图谱可以了解“糖尿病”和“视网膜病变”的关系,这有助于提升实体识别和关系提取的准确度。
-
子解法2:混合注意力机制
- 之所以用混合注意力机制,是因为需要区分和加权不同实体类型对特定医学提及的影响,从而增强语义表示的准确性。
- 例如,在处理含有“糖尿病”提及的文本时,模型通过这种机制能够识别出“胰岛素抵抗”对“糖尿病”概念的语义贡献大于其他一些不那么重要的关联术语。
-
子解法3:提及-邻居上下文建模
- 之所以用提及-邻居上下文建模,是因为它能够利用知识图谱中的全局上下文来增强低频提及的语义表示,改善模型对稀有术语的处理能力。
- 例如,对于较少出现在训练数据中的“罕见糖尿病并发症”提及,这种方法可以通过与之相关联的常见并发症(如“肾病”)的信息来提升其表示。
这个设计思路,其实可以比作是打造一个专业的医学顾问团队。
如果你是一个医生,面对一个复杂的病例,你会怎么做?
首先,你可能会查阅各种医学资料和手册。
- 这就像是利用结构化知识图谱,因为这些资料和手册详细记录了医学术语和概念之间的复杂关系,帮助你理解疾病之间的联系。
接着,你可能需要与你的同事进行讨论,尤其是那些在某些领域拥有更多经验的专家。
- 这就类似于混合注意力机制,你会特别注意那些在特定病症上有深入研究的专家的意见,因为他们的见解对你解决问题可能会有更大的帮助。
最后,如果遇到一些罕见或特殊的病例,你可能还会通过病例报告、研究文献,甚至是国际病例数据库来寻找相似案例,看看其他医生是怎么诊断和治疗的。
- 这就像是提及-邻居上下文建模,通过寻找和稀有病症相关的其他信息,帮助你更好地理解和处理这个案例。
所以,这个设计思路就好比是建立了一个虚拟的“医学顾问团队”,每个成员都擅长处理不同的问题,而你就是团队中的协调者,通过合理地利用每个“成员”的专长,来共同解决面前的医学难题。
SMedBERT的背景
- 开放领域PLMs,如BERT和RoBERTa,通过双向Transformer和自监督学习任务为各种NLP任务提供了强大的基础。
- 知识增强PLMs(KEPLMs),如ERNIE和KnowBERT,通过融入外部知识(例如知识图谱中的实体和关系)来增强模型的语言理解能力。
- 医学领域PLMs,如BioBERT和PubMedBERT,特化于处理医学领域的文本,通过域内的持续学习或从头开始学习来解决特定的领域挑战,例如专业术语和概念。
SMedBERT的工作原理
SMedBERT结合了以上三种方法的优点,并在此基础上引入了结构化语义知识,特别是从知识图谱中提取的关于医学实体及其邻居的信息。
具体来说,SMedBERT通过以下两个核心技术创新来提高对医学文本的理解能力:
- 提及-邻居混合注意力:结合提及的实体和它们在知识图谱中的邻居实体(例如疾病与症状之间的关系),来增强文本中的实体表示。
- 提及-邻居上下文建模:通过自监督学习任务,如掩蔽邻居建模和掩蔽提及建模,促进文本中的实体与其在知识图谱中的全局上下文之间的交互,从而提升语义表示的丰富性和准确性。

图2提供了SMedBERT的模型架构,分为左右两部分:
-
左侧 展示了SMedBERT的总体架构,包括文本编码器(T-Encoder)、知识编码器(K-Encoder)、预训练任务(如掩码语言模型(MLM)和提及-邻居上下文建模),以及异构信息融合模块。
-
右侧 则详细介绍了提及-邻居上下文建模预训练任务,这包括掩蔽邻居建模和掩蔽提及建模。
掩蔽邻居建模关注的是利用提及(如文本中的词语)来丰富邻居实体的表示(如知识图谱中的实体)。
掩蔽提及建模则是反过来,利用邻居实体来提升提及的表示质量。
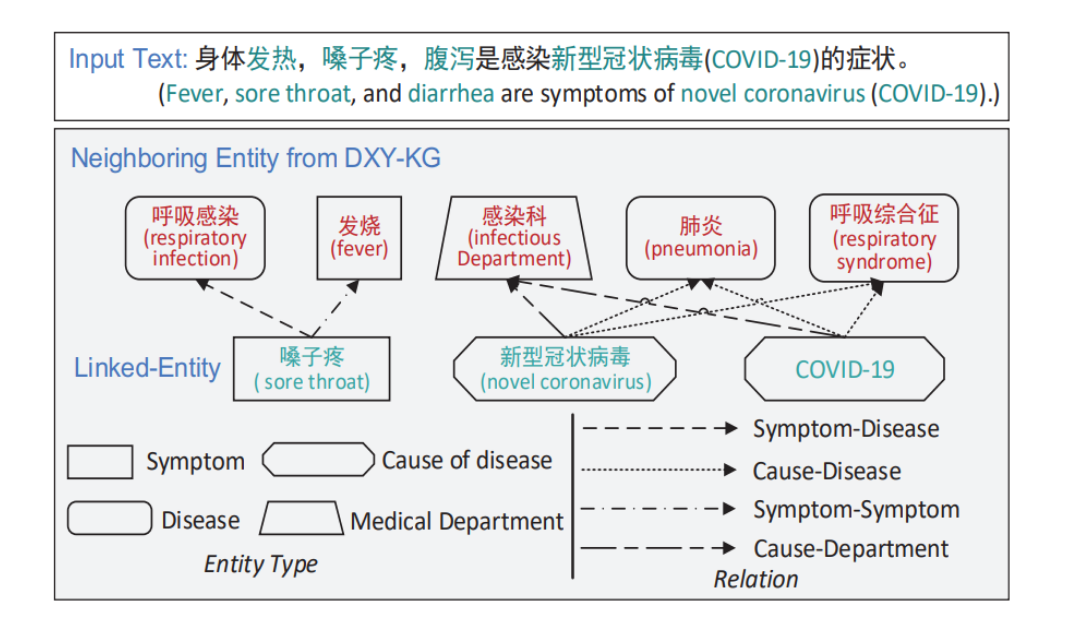
图展示了一个输入文本和相关联的知识图谱信息。
输入文本提到发烧、咽痛和腹泻是新型冠状病毒(COVID-19)的症状。
然后,图中显示了从知识图谱中提取的邻近实体信息,如“呼吸感染”(respiratory infection)、“发热”(fever)、“呼吸综合症”(respiratory syndrome)和“肺炎”(pneumonia),它们都与“新型冠状病毒”(novel coronavirus)相关联。
这些邻近实体之间的关系通过不同的线条表示,如症状与疾病之间的关系、病因与疾病之间的关系等。
假设有一段医学报告:“患者因持续咳嗽、发热和呼吸困难入院,初步诊断为COVID-19引起的肺炎。”
在处理这段文本时,SMedBERT如下工作:
- 实体识别:识别“COVID-19”和“肺炎”为关键医学实体。
- 知识图谱查询:查询与“COVID-19”和“肺炎”相关的知识图谱,包括它们之间的关系以及相关的症状和治疗方法。
- 提及-邻居混合注意力:利用从知识图谱中提取的信息,增强“COVID-19”和“肺炎”的文本表示,例如通过考虑“发热”和“呼吸困难”作为“肺炎”的典型症状。
- 提及-邻居上下文建模:通过自监督学习任务,加深模型对“COVID-19”和“肺炎”及其关系的理解,例如预测与“肺炎”相关的症状,从而提高对这些医学实体的表示质量。
通过这种方法,SMedBERT不仅能够理解单独的医学术语,还能够把握这些术语之间的复杂关系和它们在医学知识体系中的位置,从而在医学领域的自然语言处理任务中实现更高的性能。
SMedBERT 具体实现细节
3.1 符号和模型
在处理一篇关于糖尿病的医学文本时,SMedBERT首先将文本中的每个词汇(比如与糖尿病相关的术语)编码成隐藏特征。
假设有一个句子:“糖尿病常常与心脏疾病有关联。”,模型会将“糖尿病”和“心脏疾病”这些词汇变成一系列的向量 {h1, h2, …, hN}。
在训练语料中的每一个提及(如“糖尿病”),都与知识图谱中的实体集合E相对应,并形成实体和关系的三元组(S),比如(糖尿病,关联,心脏疾病)。
通过TransR算法,模型得到每个实体和关系的嵌入向量(Γ_ent 和 Γ_rel)。
3.2 Top-K Entity Sorting
SMedBERT需要确定哪些邻近实体最有助于理解“糖尿病”这个提及。
它使用PEPR算法,一种改进的个性化PageRank算法,来对知识图谱中的实体进行排序,从而选择与“糖尿病”最相关的前K个实体。
例如,模型可能会决定“胰岛素”、“胰岛素抵抗”、“高血糖”是糖尿病最重要的邻近实体。
3.3 提及-邻居混合注意力
这个组件增强了文本中“糖尿病”这类提及的语义表示,通过结合邻近实体的信息:
- 邻近实体类型注意力:对于糖尿病,SMedBERT计算每种类型的邻近实体,比如症状或并发症,对糖尿病的影响。
- 节点注意力:模型关注与“糖尿病”相关的具体实体(如“胰岛素抵抗”)在文本中的表示,并调整它们的影响力。
- 位置注入模块:这部分确保提及的上下文位置信息被用于帮助模型理解例如“糖尿病通常发生在老年人中”的这类句子。
3.4 提及-邻居上下文建模
最后,SMedBERT通过两种自监督预训练任务,充分利用知识图谱中的结构化语义知识来增强提及“糖尿病”的表示:
- 掩蔽邻居建模(MNeM):模型可能会掩蔽与“糖尿病”关联的邻近实体(如“高血糖”)并尝试预测它,从而深化对邻近实体的语义理解。
- 掩蔽提及建模(MMeM):相反地,模型通过邻近实体“胰岛素治疗”或“饮食控制”来增强对掩蔽的“糖尿病”提及的表示。
通过这些步骤,SMedBERT不仅能理解“糖尿病”这个词本身,还能了解它与其他医学术语的关系,以及它在医学领域中的广泛意义和联系。
这种增强的表示能够帮助提升模型在自动医学问答、文本分类、患者报告分析等医学NLP任务中的表现。
数据与效果
SMedBERT在实验中表现出较之前方法的显著提升。在内在评价的无监督语义相似性任务中,特别是在有许多共享邻居的正样本对数据集D2上,SMedBERT相比所有基线模型的表现提升了1.36%。
在包含至少一个低频提及的正样本对数据集D3中,SMedBERT的表现也有显著提升,增加了1.01%,这表明该模型在增强低频提及的表示方面尤为有效。
在下游任务的评估中,例如命名实体识别(NER)和关系提取(RE),SMedBERT与最强基线模型相比,在两个NER数据集上分别提升了0.88%和2.07%,在RE任务上提升了0.68%和0.92%。
在问答(QA)、问题匹配(QM)和自然语言推理(NLI)任务中,SMedBERT也一致地提升了性能,分别增加了0.90%,0.89%和0.63%。
这些结果明确表明,SMedBERT通过整合领域特定的结构化语义知识,能够在多个医学NLP任务中显著改善结果。
4.1 数据来源
预训练数据:经过预处理的预训练语料库包含5,937,695个文本段落和3,028,224,412个令牌(约4.9GB)。
使用TransR算法在两个可信数据源上训练了知识图谱嵌入,包括来自OpenKG的“SymptomIn-Chinese”和“DXY-KG”,分别包含139,572和152,508个实体。两个知识图谱中的三元组数量分别是1,007,818和3,764,711。
任务数据:使用四个大规模的ChineseBLUE数据集来评估模型,这些数据集是中文医学NLP任务的基准。
还在由DXY公司和CHIP提供的真实应用场景数据集上测试了模型,包括命名实体识别(DXY-NER)、关系提取(DXY-RE, CHIP-RE)和问答(WebMedQA)。
4.2 基线
对比了SMedBERT与一般的PLMs、特定领域PLMs和在中文医学语料上预训练并注入了知识嵌入的KEPLMs:
- 一般PLMs:包括BERT-base、BERT-wwm和RoBERTa。
- 特定领域PLMs:因为中文医学领域的PLMs很少,包括MC-BERT和使用本文语料预训练的BioBERT-zh。
- KEPLMs:使用两个在医学语料上持续预训练的KEPLMs作为基线模型,包括ERNIE-THU和KnowBERT。为了公平对比,只选取了注入相同知识图谱嵌入的KEPLMs。
4.3 内在评价
设计了一个无监督的语义相似性任务来评估SMedBERT的语义表示能力。
从知识图谱中提取所有具有等价关系的实体对作为正样本。
每个正样本对的一个实体作为查询实体,另一个作为正候选,用于采样其他实体作为负候选。
此外,还对模型在强化低频提及表示的能力进行了验证。
4.4 下游任务结果
在与输入文本中实体密切相关的NER和RE任务上评估了模型。
在NER和RE任务中,与在开放领域语料上训练的PLMs相比,加入了医学语料和知识事实的KEPLMs取得了更好的结果。
SMedBERT在两个NER数据集和RE任务上都取得了显著提升。
此外,还在问答(QA)、问题匹配(QM)和自然语言推理(NLI)任务上评估了SMedBERT,表现也一致提升。
4.5 实体命中率的影响
探索了不同实体命中率下模型在NER和RE任务上的表现,这个比率控制了样本中知识增强提及跨度的比例。
结果表明,性能在命中率增加初期显著提升,然后保持稳定,说明异构知识有助于改善语言理解能力,但太多知识事实并不能进一步提高模型性能,因为会引入知识噪声。
4.6 邻近实体数量的影响
在DXY-NER和DXY-RE的测试集上,进一步评估了模型在不同K值下的表现。
结果显示,SMedBERT在不同任务上在K=10左右时能够达到最佳性能,随着K的增加,模型性能先增后减,这也表明注入过多邻近实体知识可能会影响性能。
4.7 消融研究
选择了三个重要的模型组件进行消融研究,结果表明,去除这些机制后,模型性能仍与强基线ERNIE-med相当。
特别是去除混合注意力模块后,模型性能下降最多,表明注入丰富的异构邻近实体知识是有效的。
总体而言,实验结果表明,注入领域特定的结构化语义知识可以显著提升模型在医学NLP任务中的表现。




)




FineBI-平台新增用户留存分析】)

![P4119 [Ynoi2018] 未来日记](http://pic.xiahunao.cn/P4119 [Ynoi2018] 未来日记)







