题目
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次。
说明: 所有数字(包括目标数)都是正整数。解集不能包含重复的组合。
- 示例 1:
- 输入: candidates = [10,1,2,7,6,1,5], target = 8,
- 所求解集为:
[[1, 7],[1, 2, 5],[2, 6],[1, 1, 6] ]
- 示例 2:
- 输入: candidates = [2,5,2,1,2], target = 5,
- 所求解集为:
[[1,2,2],[5] ]
思路
这道题目和上一道组合总和有如下区别:
- 本题candidates 中的每个数字在每个组合中只能使用一次。
- 本题数组candidates的元素是有重复的,而上道题是无重复元素的数组candidates
本题的难点在于区别2中:集合(数组candidates)有重复元素,但还不能有重复的组合。
一些同学可能想了:我把所有组合求出来,再用set或者map去重,这么做很容易超时!
所以要在搜索的过程中就去掉重复组合。
所谓去重,其实就是使用过的元素不能重复选取。
都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上使用过,一个维度是同一树层上使用过。没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因。
那么问题来了,我们是要同一树层上使用过,还是同一树枝上使用过呢?
回看一下题目,元素在同一个组合内是可以重复的,怎么重复都没事,但两个组合不能相同。
所以我们要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重。
为了理解去重我们来举一个例子,candidates = [1, 1, 2], target = 3,(方便起见candidates已经排序了)
强调一下,树层去重的话,需要对数组排序!
选择过程树形结构如图所示:
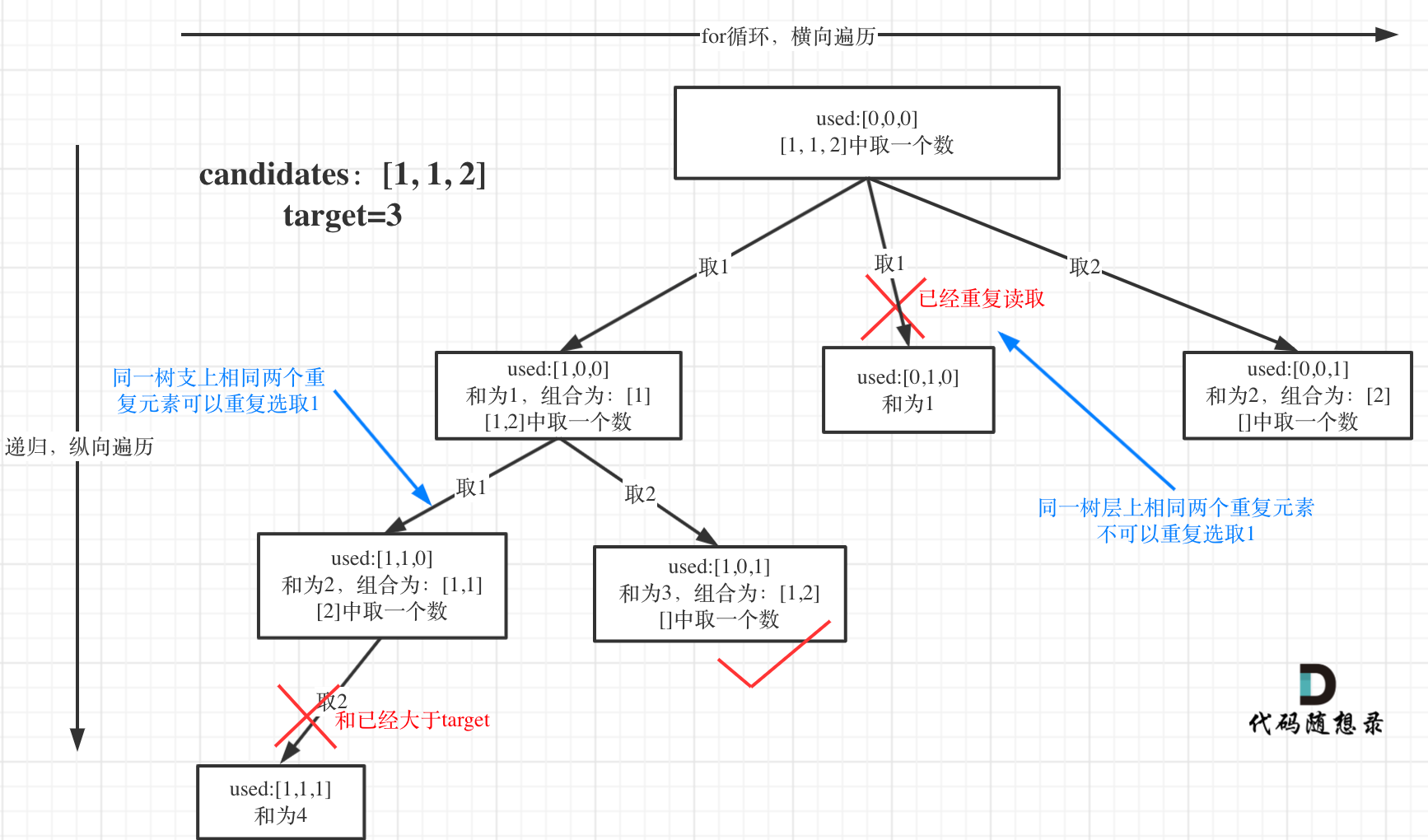
回溯三部曲
1、递归函数参数
此题还需要加一个bool型数组used,用来记录同一树枝上的元素是否使用过。这个集合去重的重任就是used来完成的。
vector<vector<int>> result; // 存放组合集合
vector<int> path; // 符合条件的组合
void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {
2、递归终止条件
与上题相同,终止条件为 sum > target 和 sum == target。
if (sum > target) { // 这个条件其实可以省略return;
}
if (sum == target) {result.push_back(path);return;
}
sum > target 这个条件其实可以省略,因为在递归单层遍历的时候,会有剪枝的操作,下面会介绍到。
3、单层搜索的逻辑
前面我们提到:要去重的是“同一树层上的使用过”,如何判断同一树层上元素(相同的元素)是否使用过了呢。
如果candidates[i] == candidates[i - 1] 并且 used[i - 1] == false,就说明:前一个树枝,使用了candidates[i - 1],也就是说同一树层使用过candidates[i - 1]。
此时for循环里就应该做continue的操作。
这块比较抽象,如图:
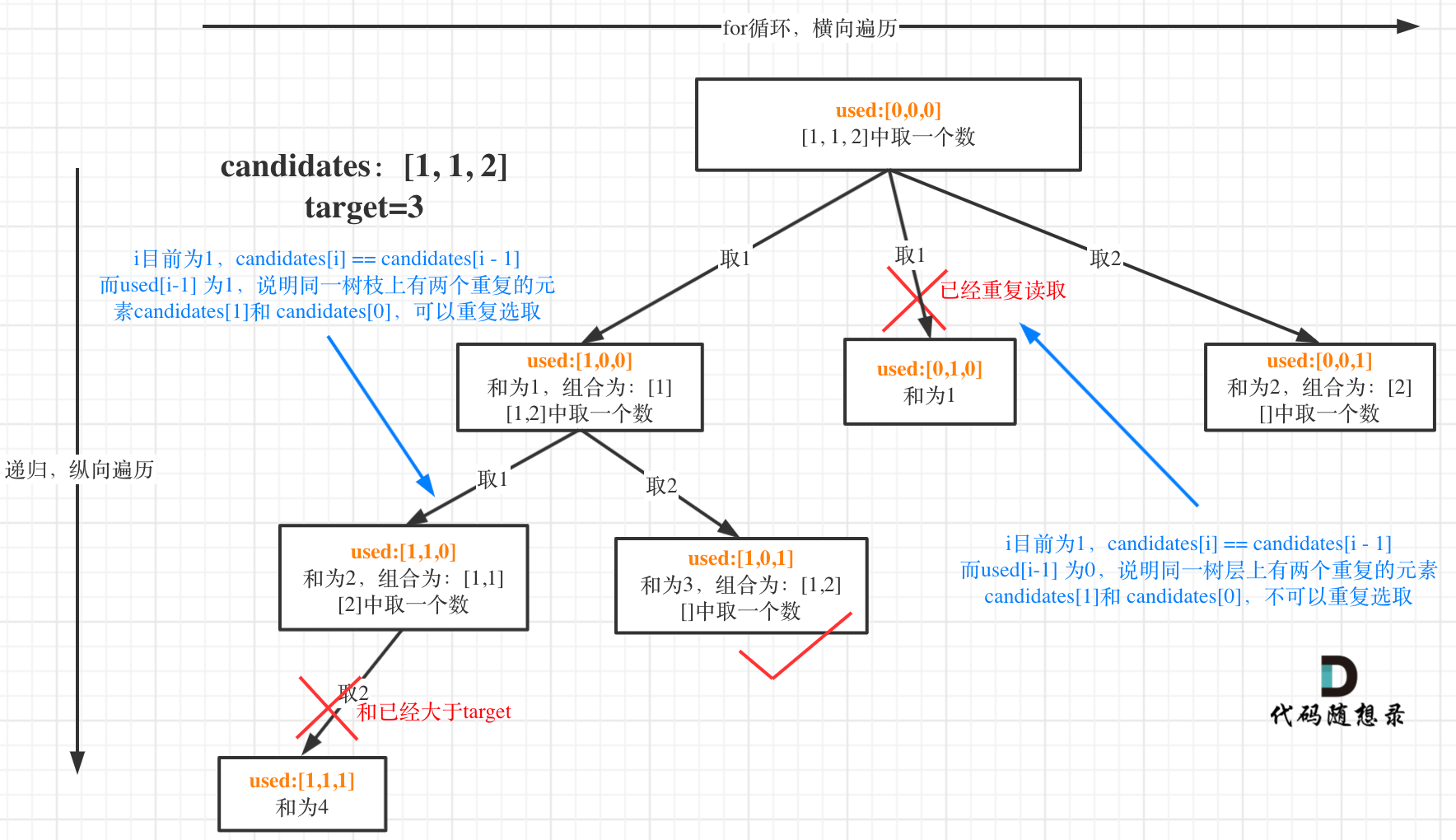
我在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
- used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
- used[i - 1] == false,说明同一树层candidates[i - 1]使用过
可能有人想,为什么 used[i - 1] == false 就是同一树层呢,因为同一树层,used[i - 1] == false 才能表示,当前取的 candidates[i] 是从 candidates[i - 1] 回溯而来的。
而 used[i - 1] == true,说明是进入下一层递归,去下一个数,所以是树枝上,如图所示:
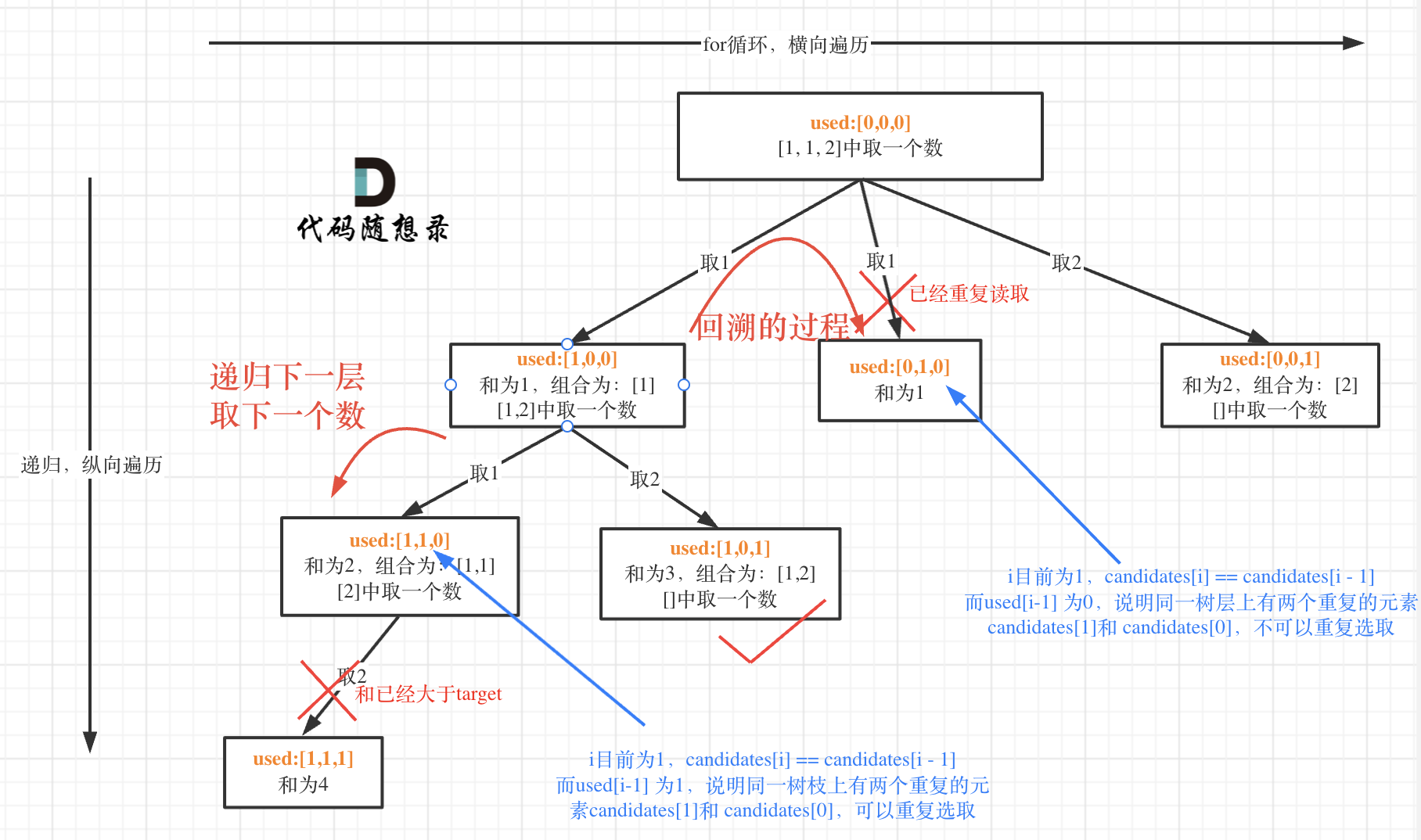
这块去重的逻辑很抽象,网上搜的题解基本没有能讲清楚的,如果大家之前思考过这个问题或者刷过这道题目,看到这里一定会感觉通透了很多!
那么单层搜索的逻辑代码如下:
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过// used[i - 1] == false,说明同一树层candidates[i - 1]使用过// 要对同一树层使用过的元素进行跳过if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {continue;}sum += candidates[i];path.push_back(candidates[i]);used[i] = true;backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1:这里是i+1,每个数字在每个组合中只能使用一次used[i] = false;sum -= candidates[i];path.pop_back();
}
注意sum + candidates[i] <= target为剪枝操作
回溯三部曲分析完了,整体C++代码如下:
class Solution {
private:vector<vector<int>> result;vector<int> path;void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {if (sum == target) {result.push_back(path);return;}for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过// used[i - 1] == false,说明同一树层candidates[i - 1]使用过// 要对同一树层使用过的元素进行跳过if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {continue;}sum += candidates[i];path.push_back(candidates[i]);used[i] = true;backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次used[i] = false;sum -= candidates[i];path.pop_back();}}public:vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {vector<bool> used(candidates.size(), false);path.clear();result.clear();// 首先把给candidates排序,让其相同的元素都挨在一起。sort(candidates.begin(), candidates.end());backtracking(candidates, target, 0, 0, used);return result;}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
这里直接用startIndex来去重也是可以的, 就不用used数组了。
class Solution {
private:vector<vector<int>> result;vector<int> path;void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {if (sum == target) {result.push_back(path);return;}for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {// 要对同一树层使用过的元素进行跳过,所以条件为i>startindex,因为递归进入的一定不满足这个条件,故不会进入这个分支if (i > startIndex && candidates[i] == candidates[i - 1]) {continue;}sum += candidates[i];path.push_back(candidates[i]);backtracking(candidates, target, sum, i + 1); // 和组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次sum -= candidates[i];path.pop_back();}}public:vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {path.clear();result.clear();// 首先把给candidates排序,让其相同的元素都挨在一起。sort(candidates.begin(), candidates.end());backtracking(candidates, target, 0, 0);return result;}
};
,通用函数)



_kaic)
)
)






)

)


