目录
点云数据处理
数据清洗
数据降噪和简化
数据配准
特征提取
数据增强
数据组织
性能考量
PointNet
PointNet++
编辑
算法问题
改进方法
三维重建
重建算法
架构模块
流程步骤
标记说明
优点和挑战
点云数据处理
数据清洗
-
去噪:点云数据通常包含噪声。可以使用统计滤波、半径滤波或其他噪声移除算法来清除噪点。
-
异常值移除:通过分析点云数据的统计特性,移除偏离平均值或中位数特别远的点,这些通常是由于传感器误差造成的。
数据降噪和简化
-
体素化:用体素网格(3D像素)代替大量的点,这可以大幅减少数据量,同时保持空间结构。
-
下采样:使用均匀采样、随机采样或远点采样等方法来减少点数,提高处理速度。
数据配准
-
预对齐:如果数据来自不同的传感器或不同的时间点,可能需要进行粗配准,以确保它们在同一坐标系中。
-
标准化:对点云数据进行缩放和旋转,使其拥有统一的尺度和方向。
特征提取
-
曲面特征:提取曲率、法线等几何特征,这对于后续的分割和识别工作非常有帮助。
-
颜色特征:如果点云带有RGB信息,可以将颜色特征和几何特征结合起来使用。
数据增强
-
仿真数据:使用仿真生成的点云数据来增强训练集,特别是对于难以在现实世界中收集的情况。
-
数据插值:对于稀疏区域,可以使用插值算法来估计缺失的点,但要小心保持数据的真实性。
数据组织
-
空间索引:使用KD-Tree、八叉树等数据结构来优化查询和检索操作,对于大规模数据来说尤为重要。
-
分批处理:如果点云数据量非常大,需要分批次处理,以避免内存溢出。
性能考量
-
计算资源:预处理步骤可能需要大量计算资源。优化算法和使用GPU加速是提高效率的关键。
-
内存管理:在处理大规模点云数据时,有效的内存管理至关重要,以避免延迟和程序崩溃。
通过以上预处理步骤,可以确保点云数据质量和一致性,为SLAM和语义分割任务打下坚实基础。这些步骤对于处理大规模数据集来说是通用的,而对于具体的实现细节,可能还需要根据具体情况进行调整和优化。
PointNet

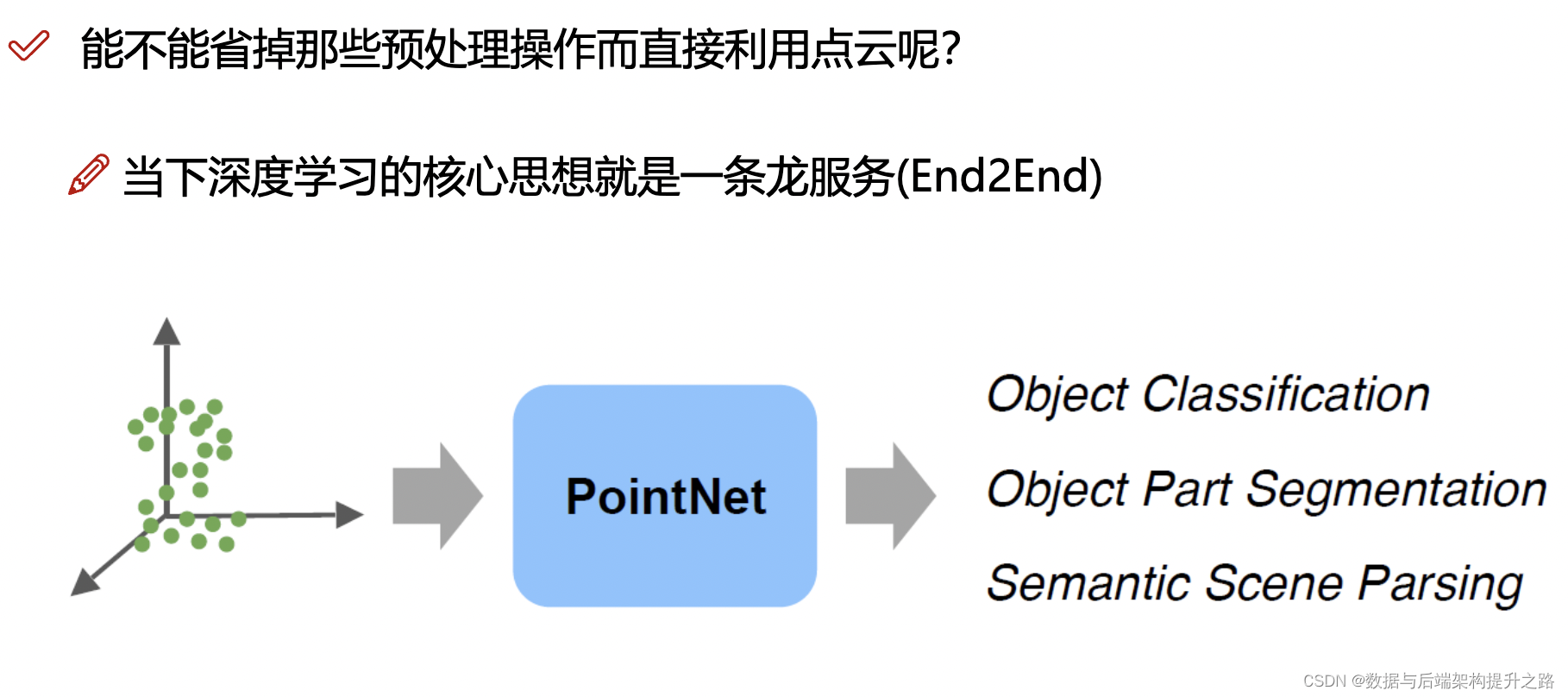
PointNet是一个深度学习算法,它用于三维点云的处理和分析。它的主要创新是能够直接从点云数据中学习特征,而不需要将数据转换成其他格式,比如体素(Voxel)或图像。PointNet能够处理无序的点集,并且对于点的输入顺序不敏感。这使得PointNet在三维对象识别和分类、场景语义分割和其他三维数据处理任务中非常有效。

PointNet通过使用多层感知器(MLP)网络,学习点的空间编码,并通过一个对称函数(例如最大池化函数)来确保对输入点的置换不变性。这是处理点云数据的一个重要特性,因为点云通常是无序的,并且相同的3D形状可以以任何顺序表示其点。
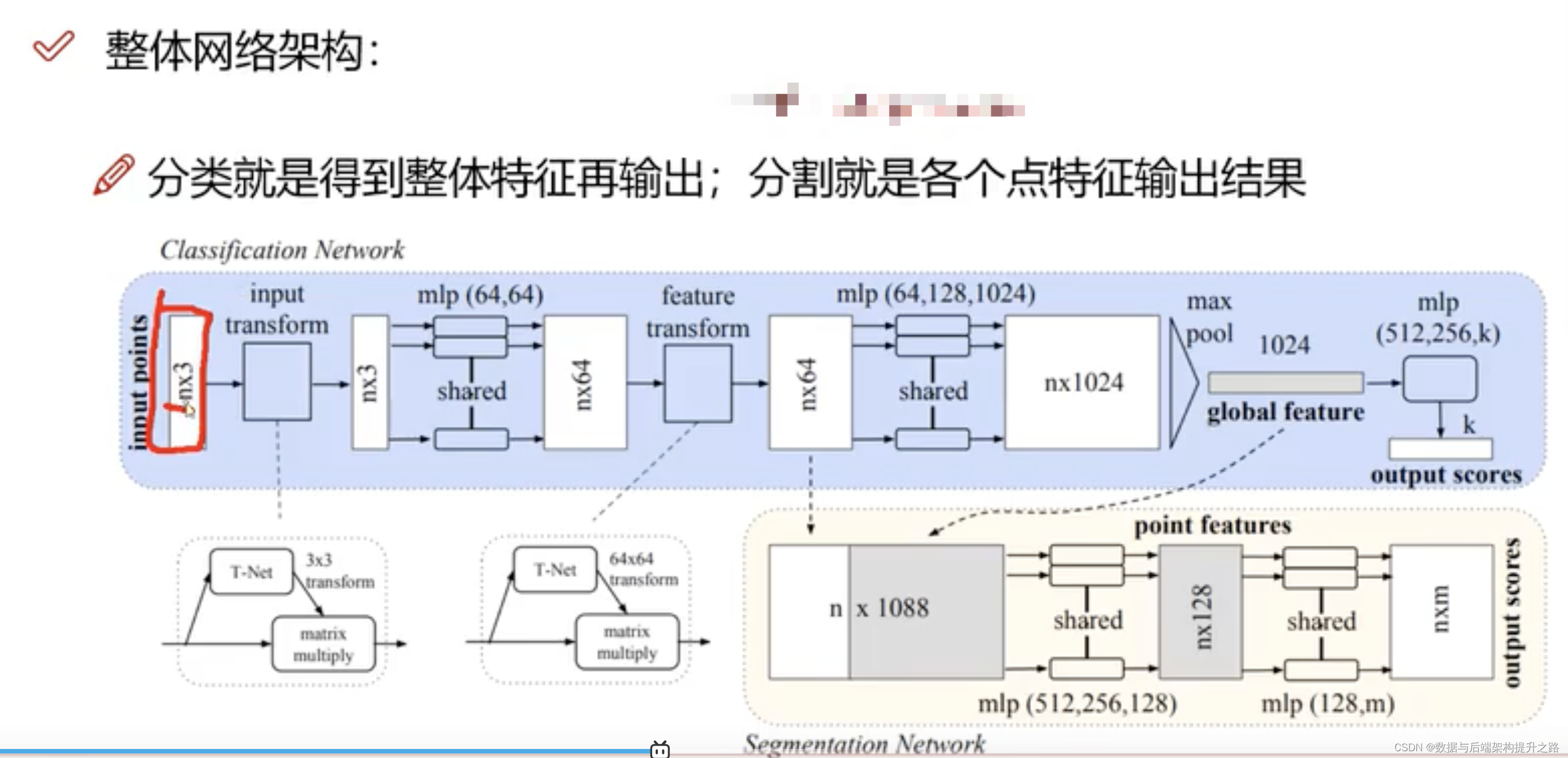

PointNet++

PointNet++的核心思想,包括分层特征学习、基于区域的处理、最远点采样选择区域中心、以及半径参数控制局部区域大小等。PointNet++在各种3D点云理解任务上,如物体分类和部件分割,都取得了比原始PointNet更好的性能表现。

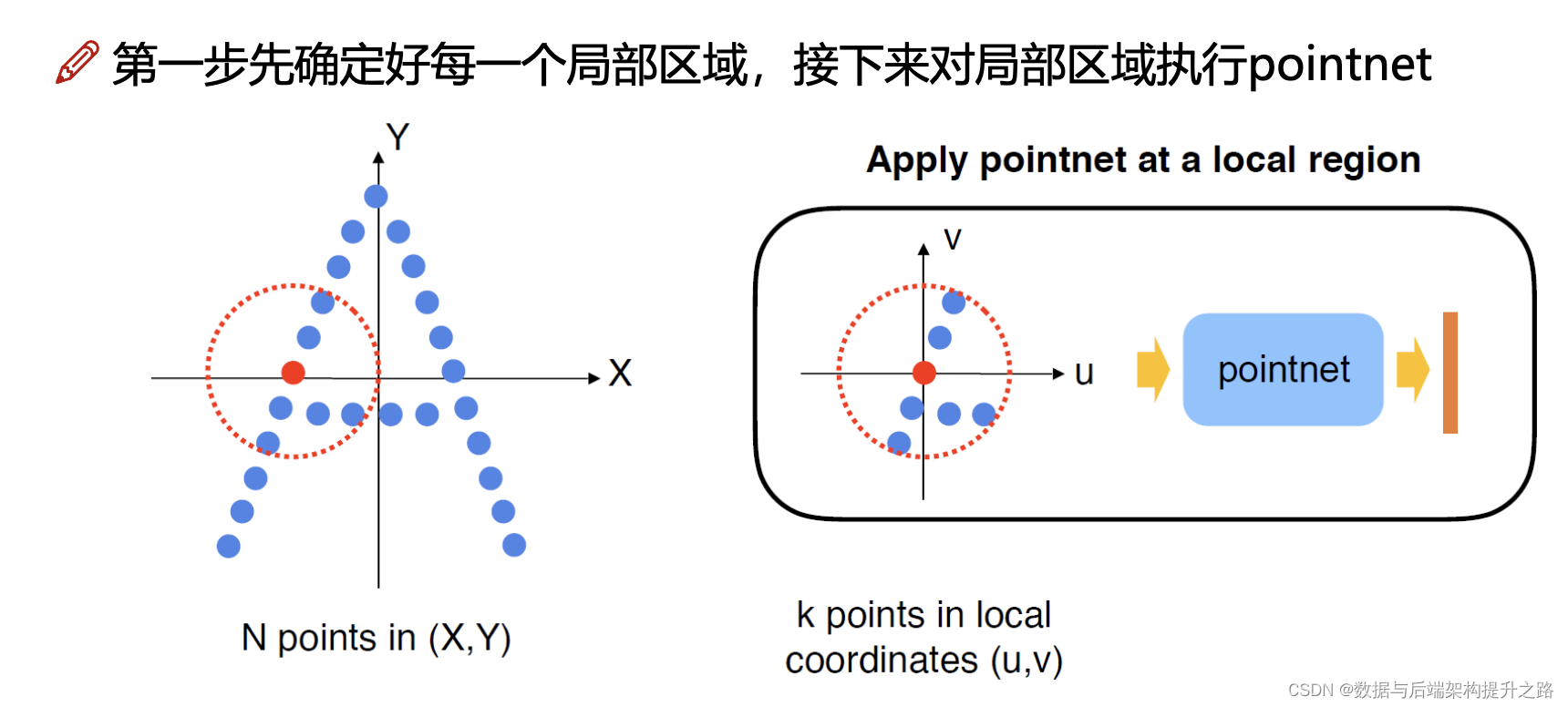

- 分组(gouping)
例如:输入为batch*1024*6(1024个点,每个点对应3个坐标3个法向量信息)
分组后输出为:batch*128*16*6(128个中心点,每个簇16个样本)
实际计算时是选择多种半径,多种样本点个数,目的是特征更丰富PointNet++
例如:半径=(0.1,0.2,0.4);对应簇的样本个数(16,32,64)
- 对各组进行特征提取
先进行维度变换(b*npoints*nsample*features,8*128*16*6->8*6*16*128)
进行卷积操作(例如:in=6,out=64)就得到提取的特征(8*64*16*128)
注意当前每个簇都是16个样本点,我们要每一个簇对应一个特征
按照pointnet,做MAX操作,得到8*64*128
- 继续做多次采样,分组,卷积:
例如:采样中心点(1024->512->128)
每一次操作时,都要进行特征拼接(无论半径为0.1,0.2,0.4;以及簇采样点个数)
最终都得到batch*中心点个数*特征(但是特征个数可能不同)
执行拼接操作(b*512*128,b*512*256,b*512*512)->(b*512*896)
- 经过多次采样,分组,pointnet得到最终整体特征,再进行分类

整个过程是一个典型的深度学习中的特征层次化提取过程,用于从原始数据中自动学习到有用的特征。在三维点云的处理中,这种方法特别有效,因为它能处理原始点云数据的无序性,并能从不同的尺度捕捉到形状和结构的特征。通过这样的处理,神经网络能够学习到复杂的模式,从而在各种任务上达到很好的性能。
算法问题

改进方法



三维重建
重建算法
GitHub - zju3dv/NeuralRecon: Code for "NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video", CVPR 2021 oral

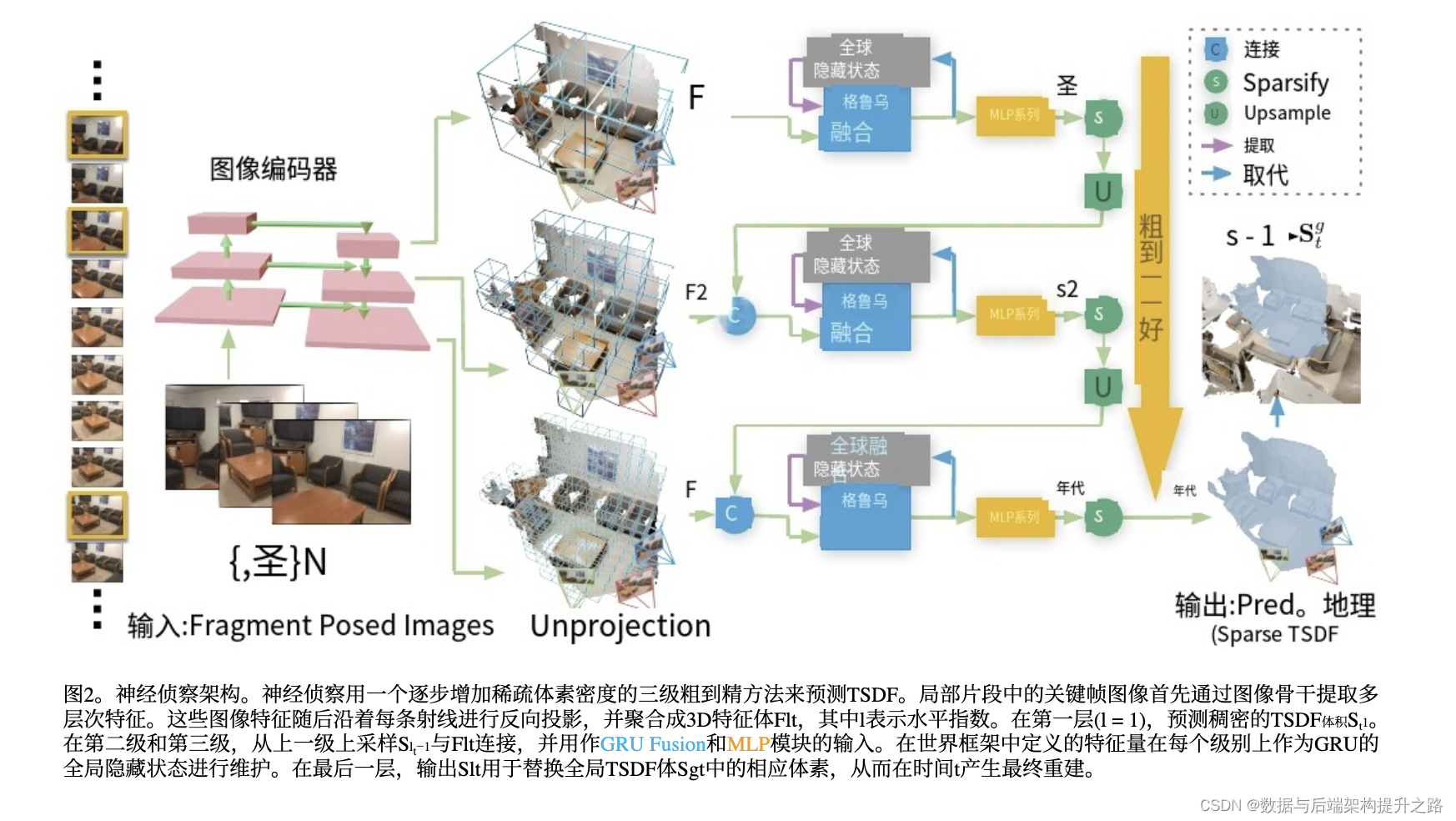
这张图片描述了一个名为“NeuralRecon”的三维重建系统的架构,这个系统采用了一种粗到细(coarse-to-fine)的方法来处理图像,并生成预测的几何结构。
架构模块
- 图像编码器: 该模块从输入视频帧中提取特征。
- GRU: 该模块是一个循环神经网络,用于编码视频中的时间信息。
- MLP: 该模块是一个全连接神经网络,用于预测场景中每个像素的深度。
- 融合: 该模块结合了 MLP 和 GRU 模块的预测。
- 上采样: 该模块将粗略深度预测上采样到所需分辨率。
- 稀疏化: 该模块从深度图中移除异常预测。
流程步骤
图像编码器(Image Encoder):
- 输入为多个片段的定位图像,这可能是由一个或多个视角拍摄的同一场景的序列图像。
- 图像编码器提取每个图像的特征。
粗到细处理(Coarse-to-Fine):
- 粗步骤:系统首先在一个较粗的尺度上建立场景的初步3D表示。
- 细步骤:随后在更细的尺度上逐渐细化这个表示。
特征融合(GRU Fusion):
- 在每个尺度上,都使用GRU来融合来自不同图像的特征。GRU能够在序列数据中有效地传递信息,并保留之前图像的状态信息。
MLP:
- 每个尺度的融合特征都通过MLP进行进一步处理。
输出:
- 最终输出为预测的几何结构,使用稀疏的TSDF(Truncated Signed Distance Field)表示。
标记说明
- 绿色箭头(C):表示特征在不同尺度间的串联(Concatenate)。
- 黄色箭头(S):表示稀疏化操作(Sparsify),可能是为了减少计算复杂度。
- 蓝色箭头(U):表示上采样(Upsample),在粗到细的策略中上采样是为了细化特征。
- 粉色块(Extract/Replace):表示从大尺度特征中提取细节,并替换原有的粗尺度特征。
优点和挑战
- 优点:高效灵活,因为该系统不依赖于传统的顺序RNN处理,同时它避免了GRU不稳定和计算成本高的问题。
- 挑战:虽然该系统避免了传统逐帧处理的消耗,但处理速度慢和GRU不稳定仍然是需要解决的问题。系统需要维持一个全局隐藏状态,这可能会对计算资源造成压力。
这个系统的创新之处在于使用了多尺度的方法结合深度学习来处理SLAM问题,并利用GRU网络来维持时序信息,从而提高了三维重建的效率和准确性。
)


















