主键
指定某个字段作为主键,这个字段内容无法为空,而且他的内容不能重复作为唯一的标识
主键还有自增和非自增,比如你创建了一个表,你设置了自增,他就会按编号依次自动加一
我创建了一个名为tarro的数据库,本章表全在这个库里进行编写
primary key就主键,在哪个字段后面,哪个就是主键
create table a (id int primary key auto_increment , name varchar(10));# auto_increment就是自增创建完了之后,往里面插入俩数据看一下
insert into a(name) values ("张三"),("李四");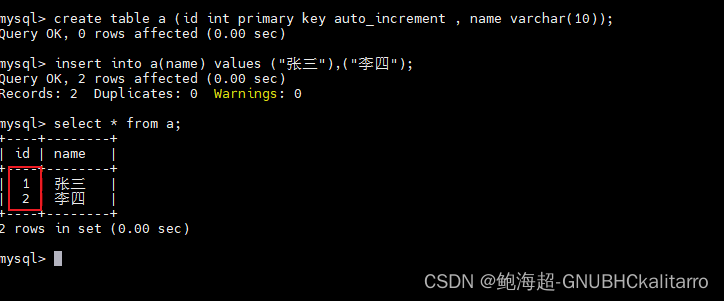
可以发现我们根本就没有去写id的内容,这就是自增
再去创建一个不自增的表看一下
create table b (id int primary key , name varchar(10));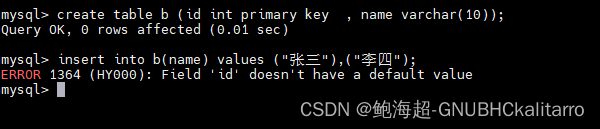
直接就保存了,因为id是主键,我们只插入了name的内容,id没有插入也就意味着id是空的,但是主键不能为空所以他就报错了
事务
保证成批操作要么完全执行,要么完全不执行,维护数据的完整性。也就是要么成功要么失败。
一个事务中包含多条sql语句,而且这些sql语句之间存在一定的关系
也就是当数据不行的时候,我们可以进行数据回滚
事物远远不止这些,本章先介绍一下基础操作
我现在往b的数据库里插入一行数据
insert into b values (1,"张三"),(2,"李四");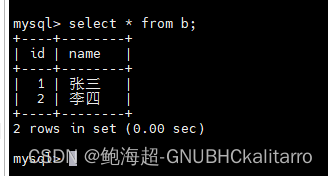
开启一下事务
begin;insert into b values (3,"zs"),(4,"ls");当数据没有问题的时候就可以进行提交
commit;再去添加几个数据
insert into b values (5,"张三2"),(6,"李四2");然后假装不小心退出了mysql
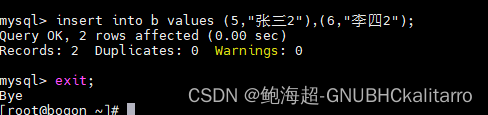
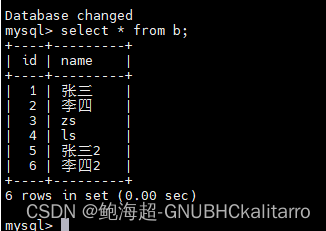
发现提交上了
因为当我们开启了事务,当你出现了问题退出了mysql,他会自动帮你提交,如果你不行自动提你可以这样做
set autocommit = 0;这样就把自动提交禁用了,现在你开启了事务以后,即使中通退出,mysql也不会帮你自动提交了
要是想恢复把0改成1就行
下面展示一下数据回滚,先开启事务
begin;insert into b values (7,"张三2"),(8,"李四2");插入俩数据

发现这俩数据不行,需要回滚回之前的数据
rollback;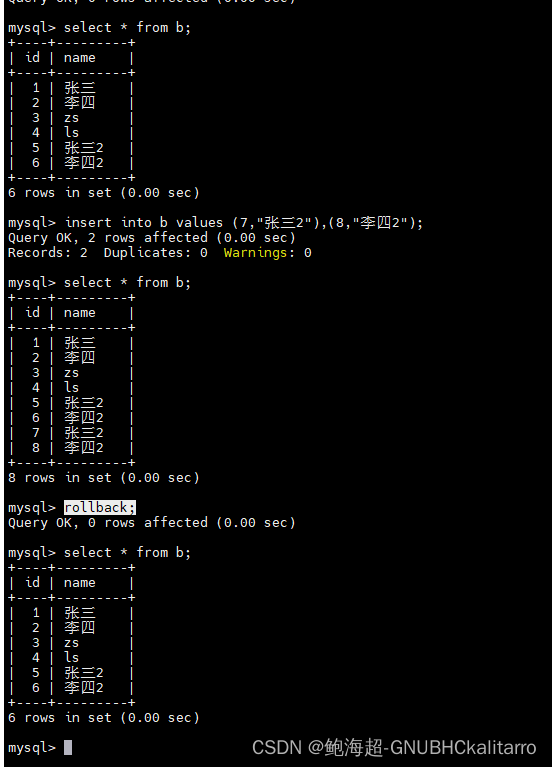
这样就回滚回来了,最后进行提交一下
commit;索引
什么是索引?
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
索引能够加快客户端的查询速度
为什么要有索引呢?
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能
非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引分类 1.普通索引index :加速查找 2.唯一索引主键索引:primary key :加速查找+约束(不为空且唯一)唯一索引:unique:加速查找+约束 (唯一) 3.联合索引-primary key(id,name):联合主键索引-unique(id,name):联合唯一索引-index(id,name):联合普通索引 4.全文索引fulltext :用于搜索很长一篇文章的时候,效果最好。 5.空间索引spatial :了解就好,几乎不用
本章作为简单的了解所以我这只讲个普通索引,后面再mysql8版本文章会详细讲到
创建索引的案例
create table tro(id int ,#可以在这加primary key#id int index #不可以这样加索引,因为index只是索引,没有约束一说,#不能像主键,还有唯一约束一样,在定义字段的时候加索引name char(20),age int,email varchar(30),#primary key(id) #也可以在这加index(id) #可以这样加);alter table tro add unique index (`age`);添加唯一索引alter table tro add primary key(id); #添加住建索引,也就是给id字段增加一个主键约束create index dgf on tro(id,name); #添加普通联合索引
查看这个表创建的索引
show index from tro\G;删除索引
drop index dgf on tro; #删除普通联合索引 drop index name on tro; #删除普通索引 drop index age on tro; #删除唯一索引,就和普通索引一样,不用在index前加unique来删,直接就可以删了 alter table tro drop primary key; #删除主键(因为它添加的时候是按照alter来增加的,那么我们也用alter来删)
索引案例
准备一个表,先把刚刚创建的tro表先删除一下,下面我要创建一个名字为tro但是结构是别的样子的表
create table tro(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
我创建完了这个表,我要去添加海量的数据,但是我不可能去一个一个手写,所以我要使用储存过程来写入海量数据,储存过程你可以理解为自定义函数
delimiter $$ #声明存储过程的结束符号为$$,默认为;
create procedure auto_insert1()
BEGINdeclare i int default 1; #类似于shell脚本中的i=1while(i<300000)
doinsert into tro values(i,concat('egon',i),'male',concat('egon',i,'@dgf'));set i=i+1;end while;
END$$ #$$结束
delimiter ; #重新声明分号为结束符号
我这写入了30万个数据,如果你的设备性能好,可以把他改为300万,这样才能看出来效果,其实30万就够
再去查看一下刚刚写的储存过程
show create procedure auto_insert1\G 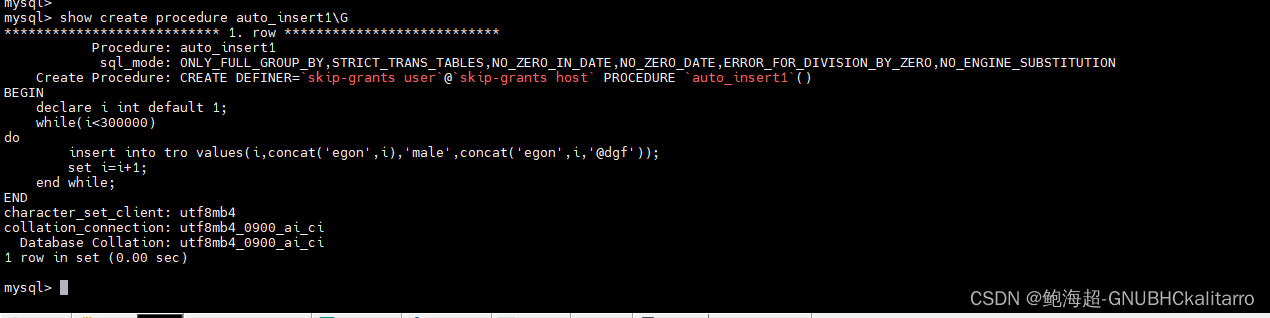
核对表名没问题以后直接就运行起来
call auto_insert1();然后耐心等待
在等待期间你可以去删除储存过程,使用完了你可以讲这个删除或者是保留(你可以再连接一个终端,然后再进去mysql继续操作)
drop procedure auto_insert1;然后耐心等待,直至数据插入结束

现在看一下数据
select * from tro;
发现有299999条数据这样就可以了
现在没有做任何的索引,我去查一个指定的数据
select * from tro where id = 66666;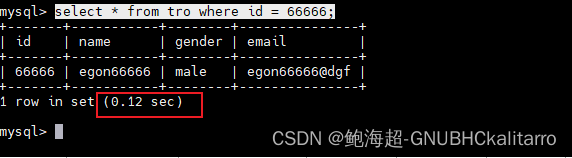
虽然也很快,但是看好这个数值,现在我去加个索引
create index idx on tro(id);加完索引再去查询数据
直接就0.00速度直接快了很多
这样就创建索引成功了







】)



)
:一文学懂进程,线程和协程)






