【Python】科研代码学习:十七 模型参数合并,safetensors / bin
- 前言
- 解决代码
- 知识点:safetensors 和 bin 的区别?
- 知识点:save_pretrained 还会新增的文件
- 知识点:在保存模型参数时,大小发生了成倍的变化
前言
- 众所周知,LLM的模型参数一般保存在
.safetensors或者.bin结尾的大文件

- 但是通过一个
RLHF的一个训练后,使用了FSDP分布式训练器
所以把文件参数保存在了.pt文件中
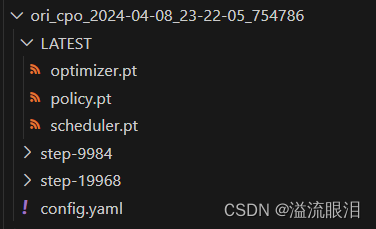
- 那么问题来了,保存的参数我如何合并到模型里去,做其他推理任务呢?
解决代码
- 经过复杂的尝试和询问,然后使用下面的几个方法就成功了
第一步,加载初始的模型,使用.from_pretrained即可加载本地模型的参数
第二步,加载policy.pt里面的state的内容,使用model.load_state_dict即可使用这些参数来覆盖原始模型的参数
第三步,保存模型参数到文件夹,使用model.save_pretrained即可
def FSDP_model_merge(model_path : str, pt_path : str, output_path : str):print("Loading Model")model = LlamaForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16)print("Loading Checkpoint")model.load_state_dict(torch.load(pt_path)['state'])print("Saving Model")model.save_pretrained(output_path,safe_serialization=True, torch_dtype=torch.float16)print("Done")
知识点:safetensors 和 bin 的区别?
- 【知乎】
简单来说,bin是通用的二进制存储文件
safetensors是更加安全的文件,专门存储张量数据
所以这两者都可以存模型的参数 - 如何设置保存的时候使用哪个格式?
model.save_pretrained()方法里面的safe_serialization设置成True的话,就会用safetensors格式了,注意不同transformers版本的该方法的safe_serialization的默认值是不同的(较新的版本该值默认为True,较老的为False) - 看了下,貌似对于文件保存的大小来说,几乎没什么差异
知识点:save_pretrained 还会新增的文件
- 在
model.save_pretrained方法调用后,在文件夹中其实还会新增/替换这几个文件:
config.json
generation_config.json
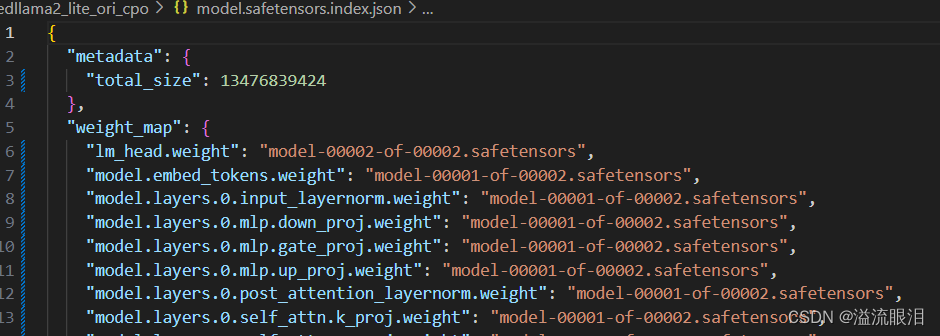
model.safetensors.index.json model.safetensors.index.json的文件主要是参数和文件的存储关系映射
以及可以从total_size中查看模型的参数大小
比如这里,13476839424,除以 1 0 9 10^9 109 之后为 13 13 13,即该模型参数大小大约为 13 G 13G 13G
然后后面可以看到保存了哪些参数权重,比如有mlp.down_proj等
generation_config.json主要是生成任务的参数,还有transformers库的版本号
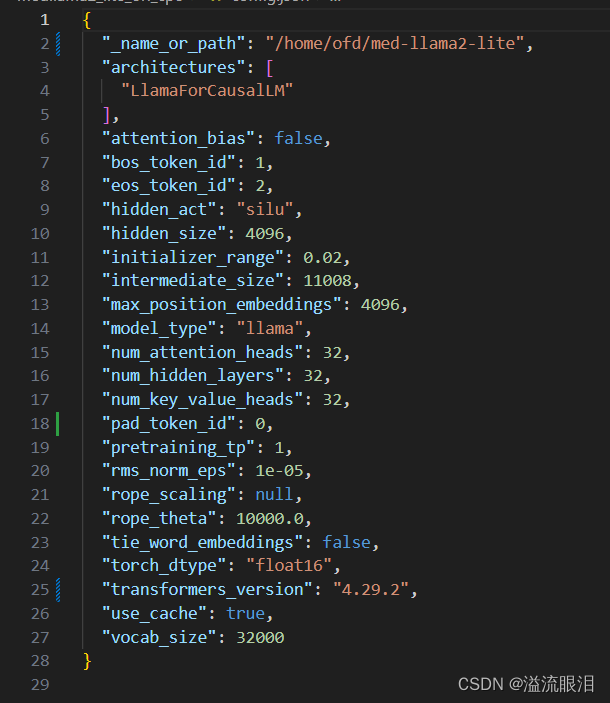
config.json比较重要,是记录该模型的重要参数
有模型的架构LlamaForCausalLM,中间各种网络的参数,词汇表大小等。
知识点:在保存模型参数时,大小发生了成倍的变化
- 这次就遇到了这个问题,我一开始还以为是合并时两份参数加在一起而没有覆盖导致的
最终文件大小加倍了 - 但最后是发现
torch_dtype原本是float16,我直接保存的话类型变成了float32,因此文件大小翻倍了
在加载和保存处设置好数据类型即可。
【这启示我们,对于精度类型还是得注意清楚的,比如在训练的时候使用混合精度等问题】 - 最终发现,在
model.safetensors.index.json里面,多了一个self_attn.rotary_emb.inv_freq参数,但这个貌似对于内存不是特别影响,应该问题是不大的
total_size只打了7k多
并且它原本是参数分成了三份,这次分成了两份,这个也会有变化。








)







发送邮件)


