01 引言
单分区写入在一些需要全局顺序消息的场景中具备重要应用价值。在一些严格保序场景下,需要将分区数设置为 1,并且只用单个生产者来发送数据,从而确保消费者可以按照原始顺序读取所有数据。此时,Kafka 的单分区写入性能将会决定整个系统的吞吐上限。在我们的实践中发现,Kafka 由于其本身线程模型实现上的制约,并没有将单分区写入性能的极限发挥出来。本文今天将具体解读 Kafka 线程模型的不足以及 AutoMQ 如何对其进行改进优化,从而实现更好的单分区写入性能。
02 Apache Kafka 串行处理模型解析
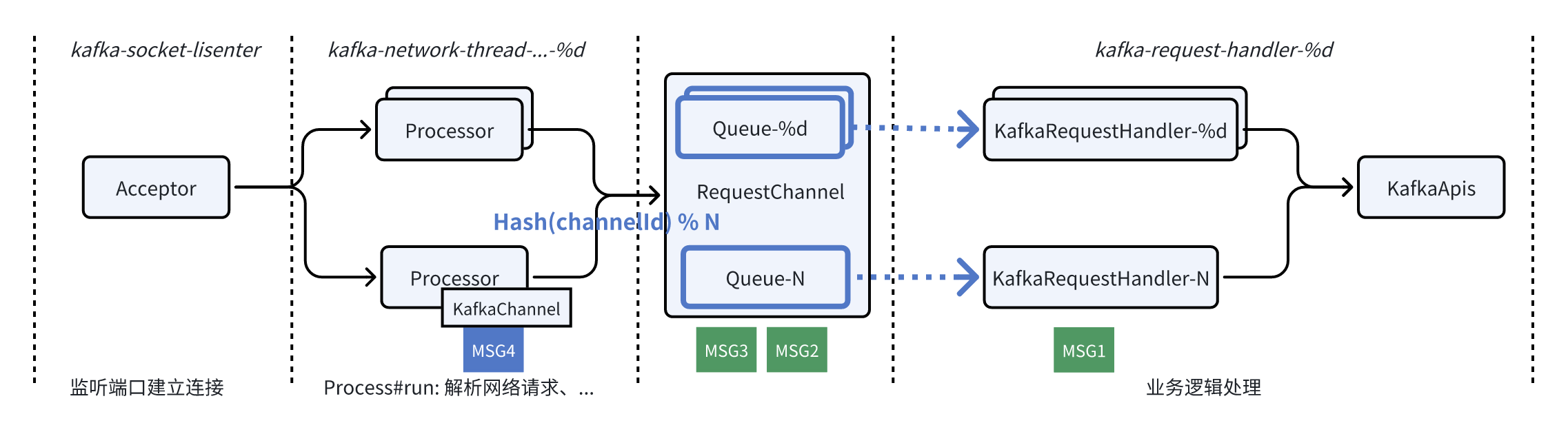
Apache Kafka 的串行处理模型网络框架主要由 5 个类组成:
1. SocketServer:网络框架的核心类,包含 Acceptor 和 Processor 部分
- Acceptor:监听端口,处理新建连接请求,并将连接分发给 Processor;
- Processor:网络线程,通过num.network.threads 配置数量。单个 TCP 连接有且只有一个 Processor 负责,Processor#run 方法驱动连接后续的生命周期管理,从网络解析请求和将响应写入到网络;
2. KafkaChannel:单个 TCP 连接的抽象,维护了连接的状态信息,被Processor持有;
3. RequestChannel:Processor 从网络解析完请求后将请求放到到单队列 RequestChannel 中,再由 KafkaRequestHandler 拉走多线程并发处理;
4. KafkaRequestHandler:业务逻辑处理 / IO 线程,通过 num.io.threads配置数量,从 RequestChannel 获取到请求后,调用 KafkaApis 进行业务逻辑处理;
5. KafkaApis:具体的业务逻辑处理类,会根据请求类型分发到不同的处理方法;
网络框架核心类和类之间的交互,对应到 Apache Kafka 的线程模型如下图:
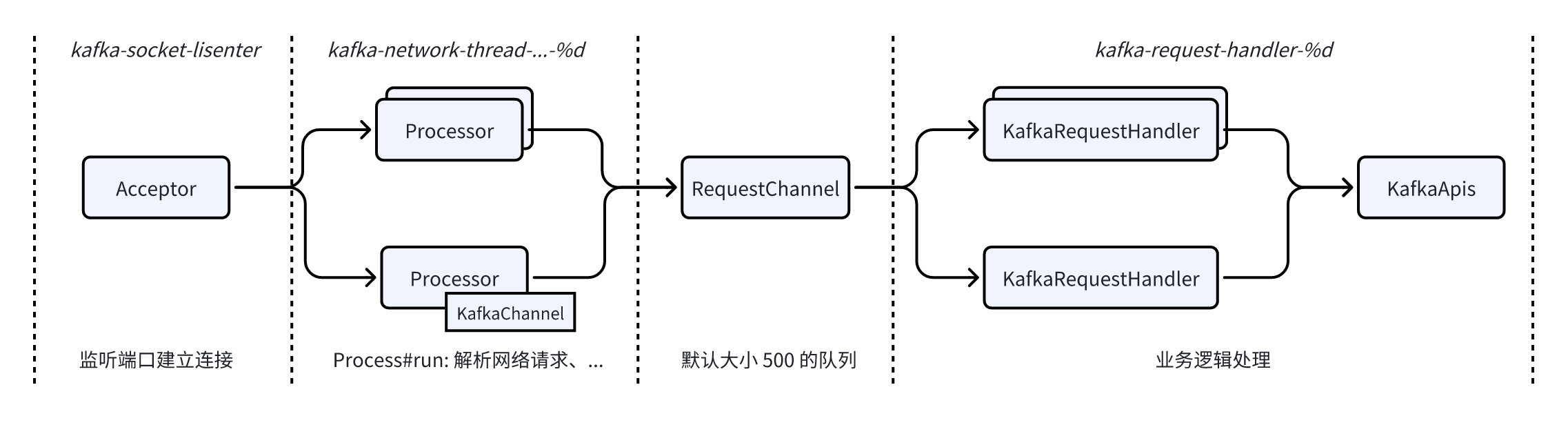
可以看到 Kafka 的线程模型和我们使用 Netty 开发的服务端程序类似:
ꔷ kafka-socket-listener 对应到 Boss EventLoopGroup:负责接受客户端连接。当一个新的连接到来时,Boss EventLoopGroup 会接受连接,并将接受的连接注册到 Worker EventLoopGroup;
ꔷ kafka-network-thread 对应到 Worker EventLoopGroup:处理连接的所有 I/O 事件,包括读取数据,写入数据,以及处理连接的生命周期事件;
ꔷ kafka-request-handler:为了防止业务逻辑阻塞网络线程,通常会将业务逻辑剥离到单独的线程池异步执行;
那为什么称 Apache Kafka 是串行处理模型呢?这就和它的 KafkaChannel mute 状态机有关了,状态机如下图所示:
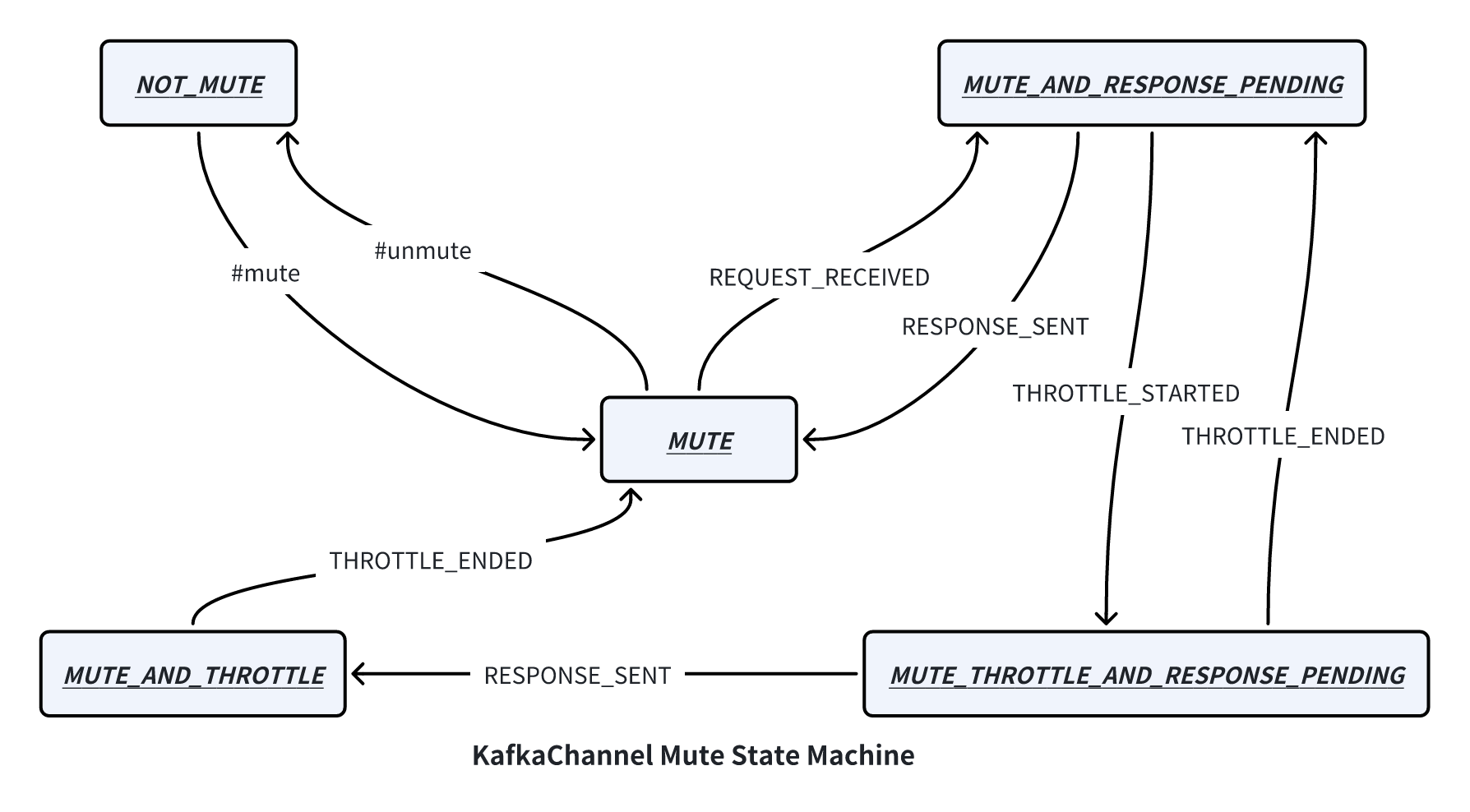
ꔷ 接收请求:当 Processor 从网络里解析出一个完整的请求,首先会将请求添加到 RequestChannel 中,然后调用 #mute 方法将 KafkaChannel 从 NOT_MUTE 状态变成 MUTE 状态,并且发送 REQUEST_RECEIVED 事件将状态变更为 MUTE_AND_RESPONSE_PENDING 状态。注意:直到这个请求收到对应的响应之前,Processor 都不会再尝试 NOT_MUTE 状态的连接里面读取更多的请求(Processor#processCompletedReceives);
ꔷ 返回响应:当 KafkaApis 将请求处理完毕,将响应返回给 KafkaChannel,首先发送 RESPONSE_SENT 事件将状态从MUTE_AND_RESPONSE_PENDING 变更为 MUTE 状态,然后再调用 #unmute 方法将状态变更为 NOT_MUTE,这时候 Processor 才会从该连接里面解析更多的请求(Processor#processNewResponses);
ꔷ Qutota 限制:Quota 限制导致的流控流程就不在本文提及了,感兴趣的小伙伴可以深入研究一下 Processor 类;
Apache Kafka 通过 KafkaChannel 的状态机可以保障:对于单个连接,这个连接有且只有一个请求在被处理,等上个请求处理完成响应后,才会继续处理下一个请求。这也是为什么称 Apache Kafka 是串行处理模型。
在消息生产请求场景,假设一个 1MB 消息生产请求的网络解析、校验定序和持久化(ISR 同步/ 刷盘)总共需要 5ms,那么一个连接的处理能力上限为 200 请求/每秒,单生产者单分区的吞吐上限也就为 200MB/s。
以下图为例,即使客户端设置 max.in.flight.requests.per.connection = 5,MSG1 ~MSG4 “同时” 到达服务端,MSG4 也要等待前面 3 个请求都处理完成响应后,才能开始处理,最终 MSG4 的发送耗时为 4T。
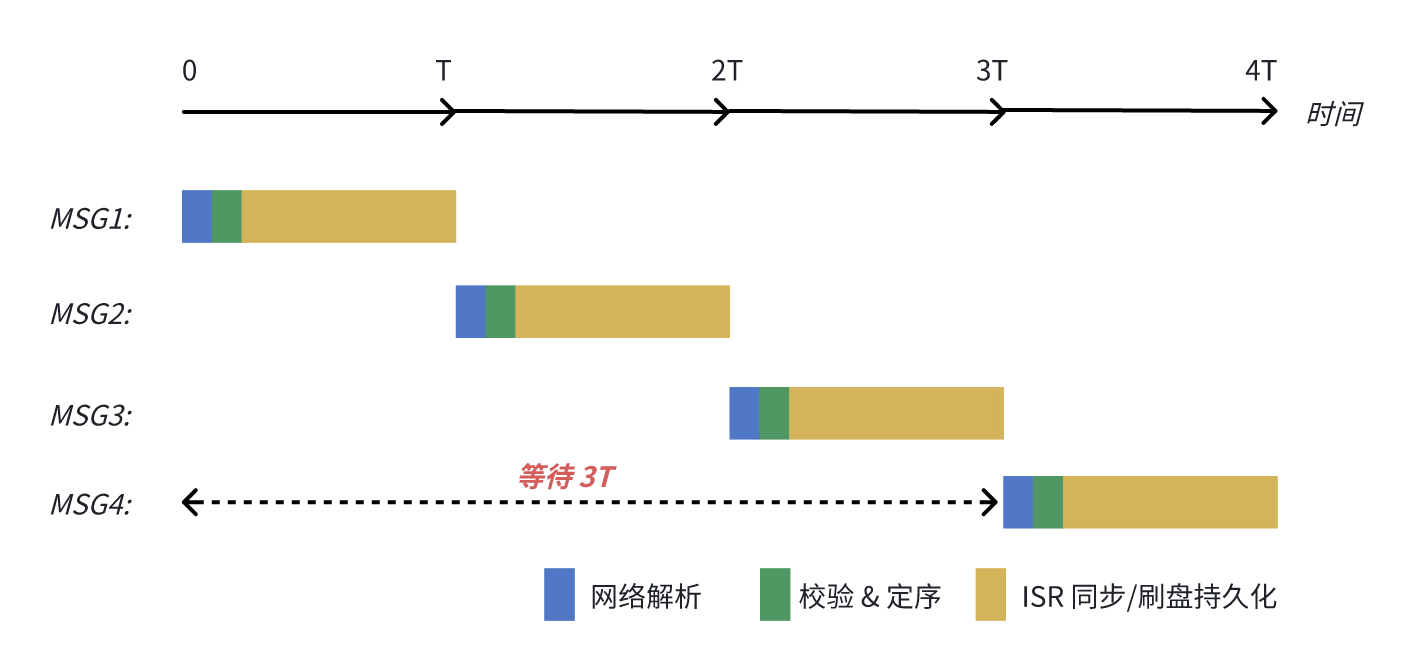
既然串行处理模型不是那么高效,为什么 Apache Kafka 要这么设计?
其中一个核心的原因:通过串行处理模型,Apache Kafka 能够较为简单就可以实现单连接请求处理的顺序性。例如在事务中发送多条消息的时候,消息会携带序列号来标识顺序,Broker 会检验持久化消息前会检查请求的序列号是否是依次递增的,如果不是依次递增的话,则返回 OUT_OF_ORDER_SEQUENCE_NUMBER 错误。如果从网络中解析完后并行处理这些请求,就可能导致消息乱序问题。
03 AutoMQ 流水线处理模型
那么有没有既能保证请求处理的顺序性又能高效的方式呢?
首先来看顺序性,Apache Kafka 的顺序性要求体现在 3 个阶段:
1. 网络解析:Kafka 协议是基于 TCP 协议的,那么网络解析必然是顺序 & 串行的,从网络中读取完上个请求的数据才能读取下一个请求;
2. 校验 & 定序:单连接的请求必须要顺序的进行校验 & 定序,要不然就会出现消息乱序问题;
3. 持久化:消息存储在磁盘的顺序必须和消息发送的顺序保持一致;
顺序性总结出来等价于:网络解析串行处理、校验 & 定序串行处理和保序持久化。聪明的读者会发现,“3 个阶段内串行处理”并不等价于“3 个阶段间串行处理”。
那么高效的秘诀就在于如何将这 3 个阶段间进行并行化加速。
因此 AutoMQ 参照 CPU 的流水线将 Kafka 的处理模型优化成流水线模式,兼顾了顺序性和高效两方面:
1. 顺序性:TCP 连接与线程绑定,对于同一个 TCP 连接有且只有一个网络线程在解析请求,并且有且只有一个 RequestHandler 线程在进行业务逻辑处理;
2. 高效:
不同阶段流水线化,网络线程解析完 MSG1 后就可以立马解析 MSG2,无需等待 MSG1 持久化完成。同理 RequestHandler 对 MSG1 进行完校验 & 定序后,立马就可以开始处理 MSG2;
同时为了进一步提高持久化的效率,AutoMQ 还会将数据攒批进行刷盘持久化;
在相同的场景下,原来 Apache Kafka 完成 4 批消息的处理耗时需要 4T,在 AutoMQ 的流水线处理模型下,处理耗时缩短到 1.x T。
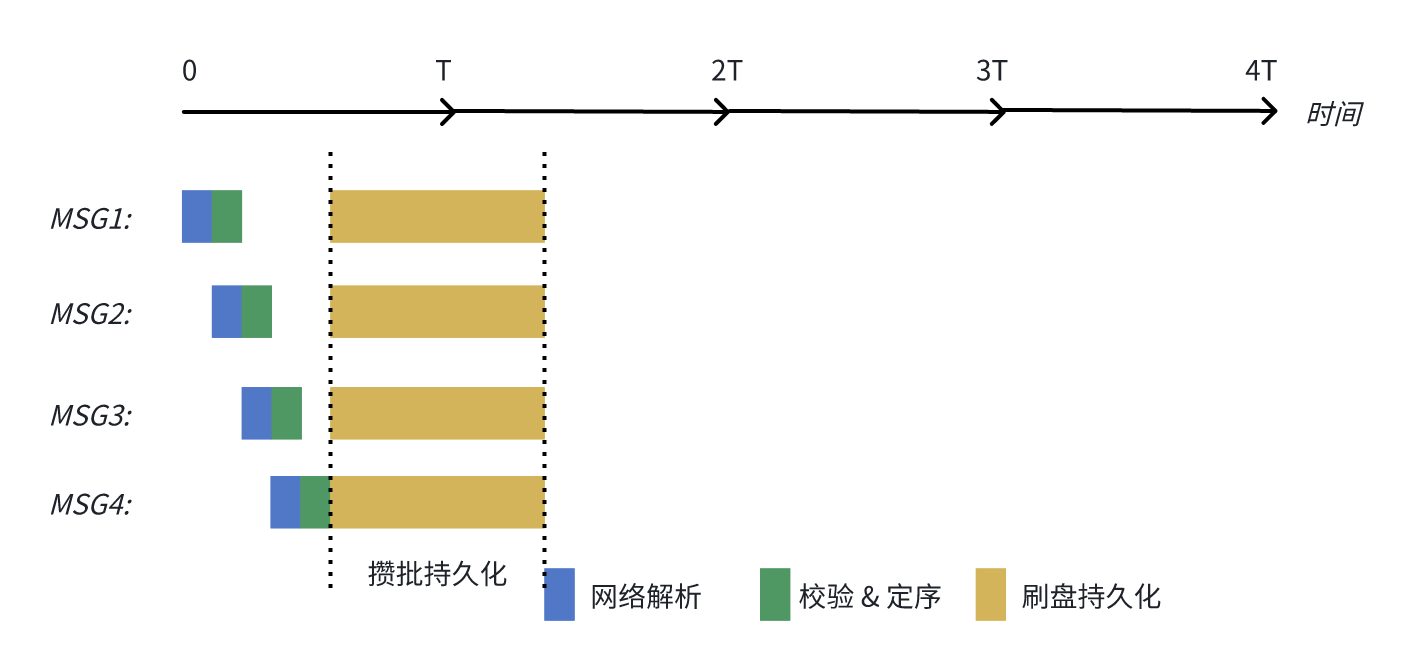
接下来再来从实现层面探索一下 AutoMQ 是如何实现流水线处理模型的。
首先是 KafkaChannel 的 mute 状态机做了简化,状态机只保留了两个状态 MUTE 和 NOT_MUTE。相比原来,收到请求后不再 #mute 对应的连接,不再全链路串行处理请求,这样就可以充分利用网络解析层的能力,“源源不断”的从连接中解析新的请求。同时为了支持 Quota 能力和防止过载场景过多 Inflight 的请求导致内存 OOM,新增了 Flag 来标记当前 MUTE 状态的原因,有且仅有 Flag 被清空时,连接才会变回 NOT_MUTE 可读状态。

优化完网络层处理效率的问题,再来看看 3 阶段并行化后,在业务逻辑层如何做到顺序处理。
AutoMQ 将 RequestChannel 进行了多队列改造:
ꔷ 队列和 KafkaRequestHandler 一一映射,数量保持一致;
ꔷ Processor 解析完请求后,根据 hash(channelId) % N 来决定路由到特定的队列;
通过多队列模式,可以做到对于相同连接的请求都被放入相同一个队列,并且只被特定的 KafkaRequestHandler 进行业务逻辑处理,保障了检验 & 定序阶段内部的顺序处理。
同时为了进一步提高持久化的效率,AutoMQ 还会将数据攒批进行刷盘持久化:
ꔷ 在处理消息生产请求时,KafkaRequestHandler 在进行校验定序后,无需等待数据持久化,即可继续处理下一个请求,提高了业务逻辑处理线程的利用率;
ꔷ AutoMQ 后台存储线程会根据攒批大小和攒批时间触发刷盘,并且持久化成功后再异步返回给网络层响应,提升了持久化的效率;
04 优化效果测试
4.1 测试环境准备
为了确保选择合适的 ECS 和 EBS 规格,保证计算和存储本身不会成为瓶颈,本次测试选择了如下的机型和云盘:
ꔷ r6i.8xlarge:32C256G、EBS 吞吐基线 1250 MB/s;
ꔷ 系统盘 EBS 卷:5000 IOPS、吞吐基线 1000 MB/s;
Broker 配置采用log.flush.interval.messages=1 :在硬件规格相同得情况下,通过强制刷盘模拟 Apache Kafka ISR 多 AZ 副本同步延迟,同时对齐 Apache Kafka 和 AutoMQ 的持久化等级;
测试使用的 Kafka 和 AutoMQ 版本如下:
ꔷ AutoMQ:1.1.0 https://github.com/AutoMQ/automq/releases/tag/1.1.0-rc0
ꔷ Apache Kafka:3.7.0 https://downloads.apache.org/kafka/3.7.0/kafka\_2.13-3.7.0.tgz
4.2 压测脚本
使用 Kafka 自带的工具脚本模拟测试负载
# 压测目标吞吐 350MB/s
bin/kafka-producer-perf-test.sh --topic perf --num-records=480000 --throughput 6000 --record-size 65536 --producer-props bootstrap.servers=localhost:9092 batch.size=1048576 linger.ms=1# 压测目标吞吐 150 MB/s
bin/kafka-producer-perf-test.sh --topic perf --num-records=480000 --throughput 2400 --record-size 65536 --producer-props bootstrap.servers=localhost:9092 batch.size=1048576 linger.ms=14.3 测试结果分析
单生产者单分区极限吞吐性能测试对比如下。从测试的结果列表中我们可以看到:
ꔷ AutoMQ 的极限吞吐是 Apache Kafka 的 2 倍,达到了 350MB/s;
ꔷ AutoMQ 在极限吞吐下的 P99 延时是 Apache Kafka 的 1 / 15,仅为 11ms;

05 结语
AutoMQ 通过网络处理模型的优化,将 Apache Kafka 的串行处理模型优化成了流水线处理模型,使得单分区的写入性能获得了成倍的性能提升,从而让单分区全局顺序消息可以满足更多场景的性能要求。尽管 AutoMQ 通过流水线处理模型极大得提升了极限吞吐和降低了延迟,但仍旧建议业务尽可能找到合理的数据分区的方式,避免单生产者单分区的场景,并且尽可能避免分区热点。单分区的能力始终是有上限的,一味的堆高单分区的吞吐,不仅集群弹性粒度变大导致弹性的经济性下降,而且单分区高吞吐对下游的消费者的无法横向扩展的单机处理性能也提出了挑战。
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ


)







)






![[通俗易懂]《动手学强化学习》学习笔记1-第1章 初探强化学习](http://pic.xiahunao.cn/[通俗易懂]《动手学强化学习》学习笔记1-第1章 初探强化学习)
)
