Transformer是一个利用注意力机制来提高模型训练速度的模型,因其适用于并行化计算以及本身模型的复杂程度使其在精度和性能上都要高于之前流行的循环神经网络。
一、Transformer模型整体结构
标准的Transformer结构如下图所示,是一个编码器-解码器架构,其编码器和解码器均有一个编码层和若干相同的Transformer模块层堆叠组成。
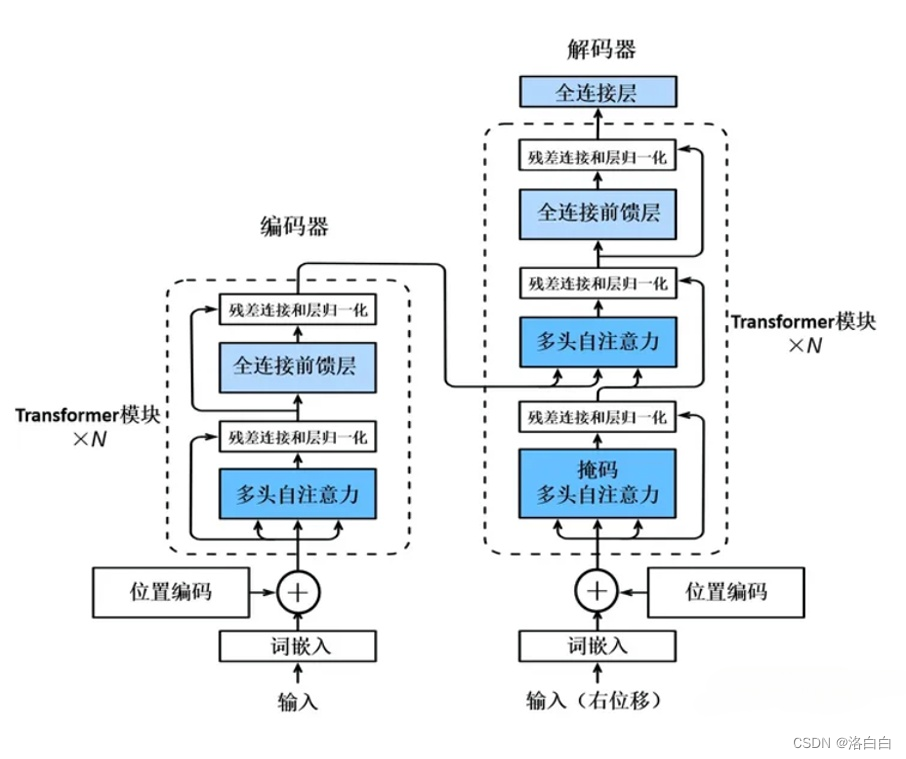
1.1 Encoder–Decoder结构
神经网络均可理解为是一个黑箱模型,Transformer的黑箱主要由两部分组成:Encoders和
Decoders.。以文本翻译任务为例,输入文本会先经过Encoders模块(编码器),该模块对文本数据
进行编码;编码后的文本数据再被传入Decoders模块(解码器),该模块对文本数据进行解码得到
最终的翻译结果。
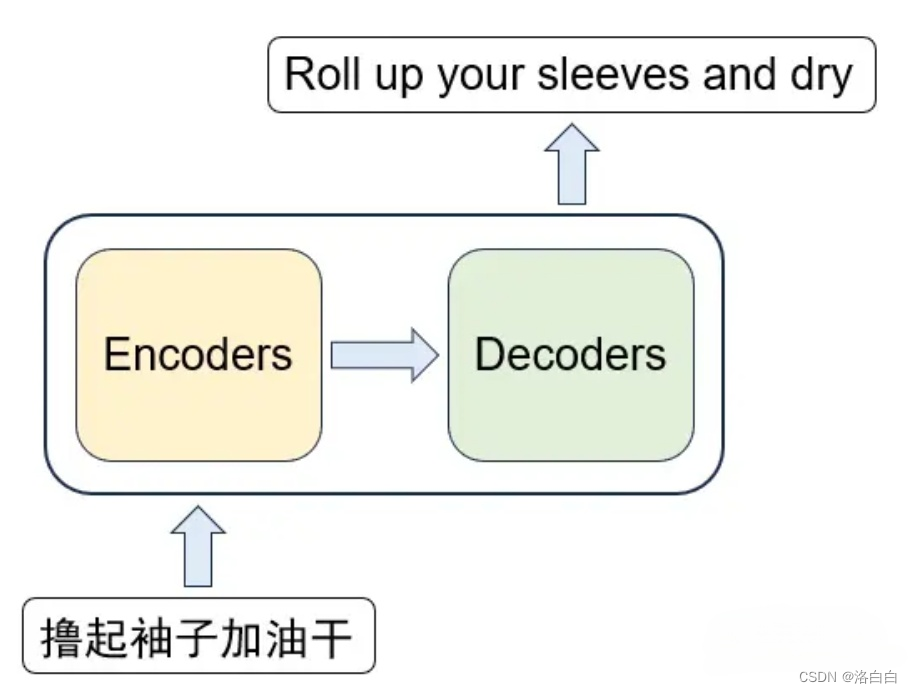
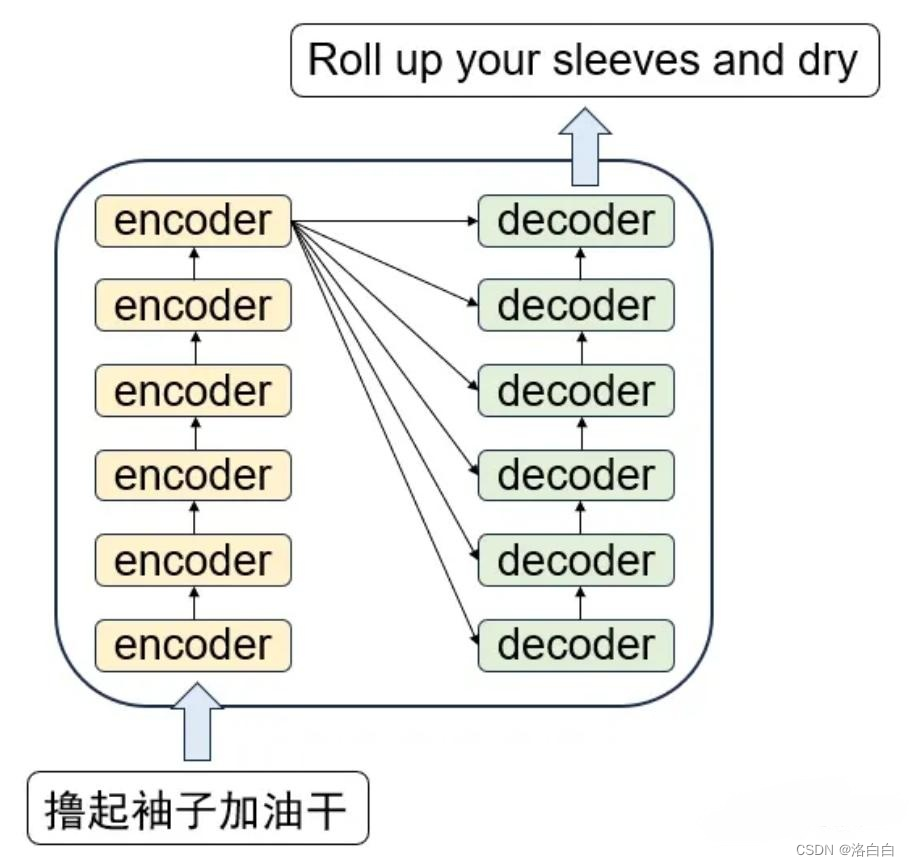
上述的编、解码模块都是由多个编码器组成的,经典的Transformer模型一般都是6个编码器和6个
解码器。在编码模块,每个编码器的输出作为下一个编码器的输入;而在解码模块,则是每个解码
器的输出结合整个编码模块的输出作为下一个解码器的输入。
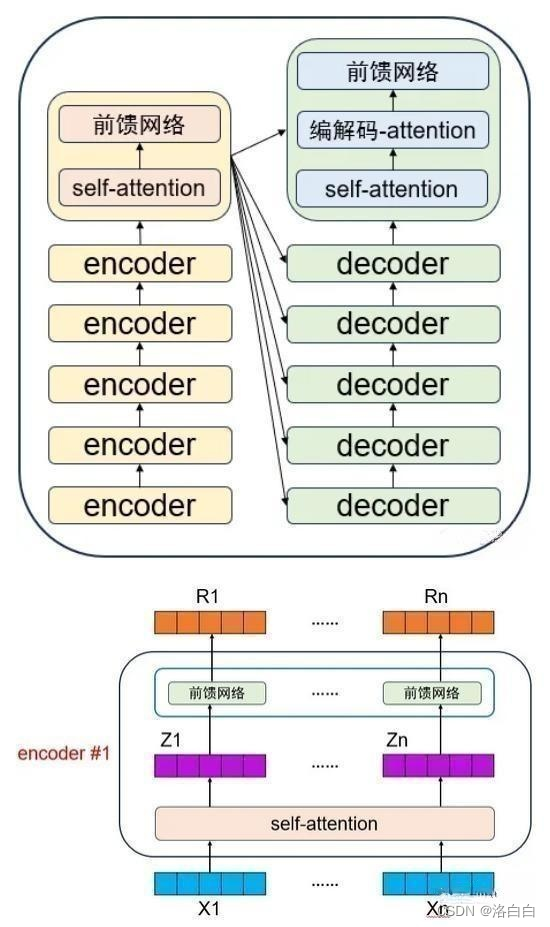
1.2编解码器组成部分
每个编码器内部又可以分为“self-attention”和"前馈网络”两个部分,每个解码器则分
为“self-attention”、"编解码-attention”和"前馈网络”三个部分。
二、模型输入
原始文本→令牌化(Tokenization)→嵌入(Embedding)一模型
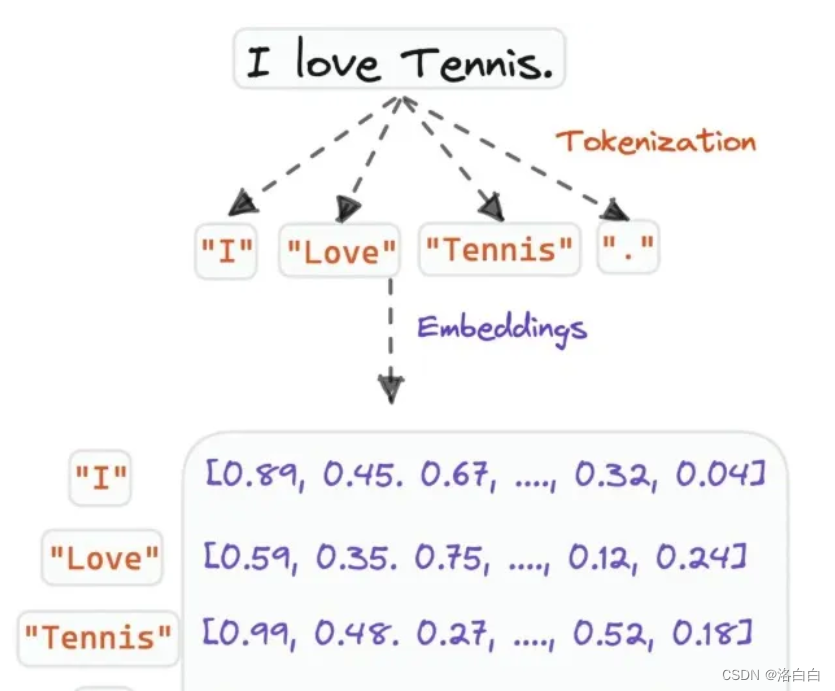 Transformert模型的输入是文本经转换(embedding./嵌入)后的向量矩阵,矩阵则是由输入文本中
Transformert模型的输入是文本经转换(embedding./嵌入)后的向量矩阵,矩阵则是由输入文本中
每个单词的表示向量组成,表示向量由每个单词的词向量和位置向量相加得到。

之间的关系,我们可以捕捉到语句的上下文和含义。自注意力作为一种沟通机制,用来帮助建立这
些关系,以概率分数表示。下面会逐步解释概率/注意力分数的计算过程。

3.1self-attention:结构
在上一章节的介绍中提到,模型输入(self-attention的接收)是单词的表示向量或上一编解码器的输
出,而下图所示,在进行注意力分数计算的时候需要用到Q,K,V三个向量。Q,K,V也正是通过sf
attention的输入经矩阵运算(线性变换)得到的。
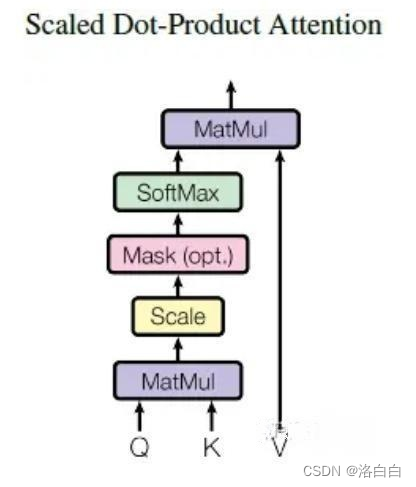
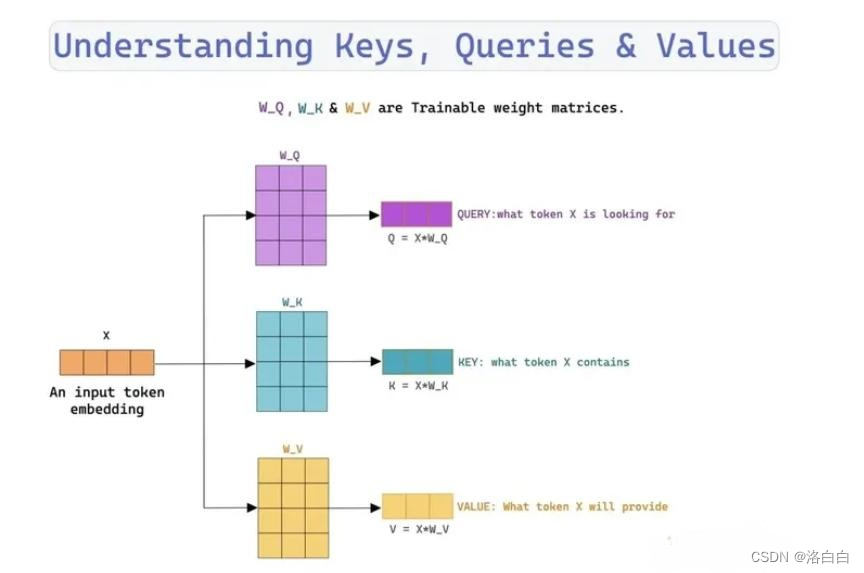
3.2Q,K,V的计算
首先对这三个向量进行字面解释:
·查询向量(Query Vector)
·键向量(Key Vector)
,值向量(Value Vector)
这三个向量都是通过self-attention的输入与三个对应的权重矩阵(Wo,WK,Wv)进行矩阵乘法
运算得到的。这三个权重矩阵最开始是随机初始化得到的,在训川练过程中依据梯度下降进行更新。
3.3self-attention输出
在得到输入矩阵对应的Q,KV之后,就可以进行计算self-attention的输出了,计算公式如下:
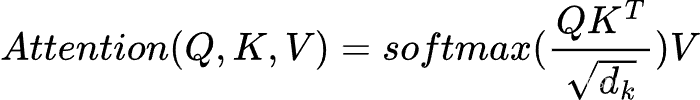
式中,d为K矩阵的列数,即K向量维度。
之后再利用softmax函数对每一行分数进行标准化,结果表示每个单词对于其他单词的attention
系数,保证系数均为正数且每一行相加结果为1。
将标准化后的注意力分数矩阵与矩阵V相乘,得到最后的self-attention输出,输出矩阵也可以理解为在输入矩阵的基础上编码了其他单词的上下文信息。总之,self-attention就是基于一系列矩阵操作,实现了单词间的权重计算。
四、编码器(Encoders)结构
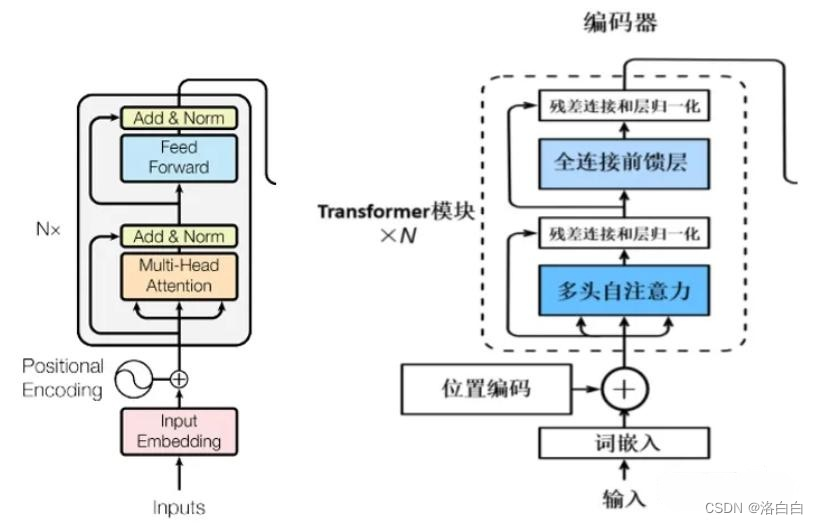 如上图所示,完整的编码部分由N个encoder组成,每个encodert包含多头自注意力(Multi-Head
如上图所示,完整的编码部分由N个encoder组成,每个encodert包含多头自注意力(Multi-Head
Attention)->残差与归一化(Add&Norm)->前馈网络(Feed Forward->残差与归一化(Add&
Norm).
多头注意力在上节中已经进行了介绍,现在了解一下残差与归一化和前馈网络部分。
五、解码器结构
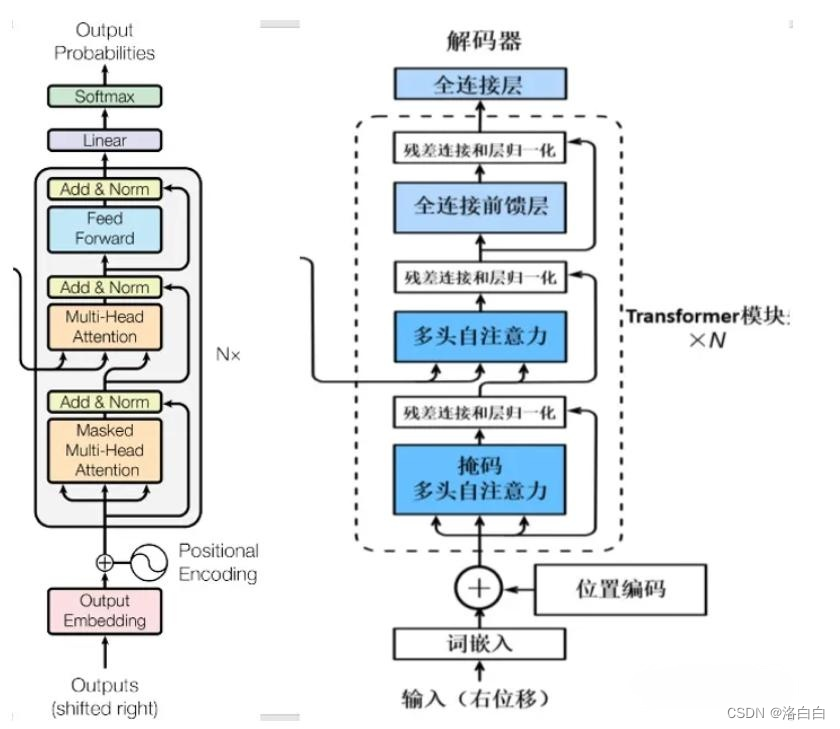
上图为Transformer的Decoders结构,与Encoders相似,但是存在一些区别:
·包含两个Multi–Head Attention层。
·第一个Multi-Head Attention层采用了Masked(掩码)操作,目的是防止查询矩阵Q去对序列中尚未解码的后续位置来施加注意力操作。
·第二个Multi–Head Attention层的键矩阵K和值矩阵V是从Encoders的最后一层的输出编码信息矩阵C中进行计算而来的,而查询矩阵Q是使用Decoders中的上一个解码器decoder的输出计算。
·最后有一个Softmax层计算下一个翻译单词的概率。
参考链接:其由谷歌团队在2017年发表的论文
《Attention is All You Need)》[1706.03762]Attention Is All You Need(axiv.org)提出,论
相关的Tensorflow代码:tensorflow./tensora2 tensor:Library of deep learning models and
datasets designed to make deep learning more accessible and accelerate ML research.
(github.com)。


![[C语言]——动态内存经典笔试题分析](https://img-blog.csdnimg.cn/direct/82c045b02e934674992d3e36f5118a25.png)