给朋友新建的wp网站,没有内容怎么办,总不能一篇篇的挨个写入吧。用wp提供的录入模块就可以了
参考 wp说明文档
获取docx内容保存到wp
资料有个docx文件,但文件格式混乱,好在有目录,可以基于目录,对文章分割,用正则拆分存入wp
首先用pandoc把docx转为md文件,速度较慢,且没有进度展示,稍等
pandoc -f docx -t markdown --extract-media ./ -o output.md input.docx
-f docx:指定源文件为 docx 格式(from)
-t markdown:指定我们要转为 md 格式(to)
–extract-media ./:将图片文件导出到目录 ./
-o output.md:表示输出的文件名为 output.md(output)
input.docx:表示要转换的文件为 input.docx
转换好后,可看到目录形如:
[杏苏散 164](#杏苏散-1)[华盖散 167](#section-56)[桑菊饮 169](#section-59)[桑杏汤 171](#桑杏汤-1)
用vscode正则提取出标题
\[(.*?)\s\d+\].*\n{0,1} 换为 "$1",
通过调整最终得到 ["补肺汤","玉屏风散","百合固金汤","沙参麦冬汤"]
re.search()方法扫描整个字符串,并返回第一个成功的匹配。如果匹配失败,则返回None。
不严格判断后面数字的话,用正则 \[(.*?)\s.* $1, 替换页可以。这里 注意是 \ 不是 /
替换过程中,忘记给中文加双引号了,生成了[补肺汤,玉屏风散] ,用vscode处理一下([一-龟]{2,}) 替换为 "$1"
最终处理得到了如下json数据,存入目录.json文件中
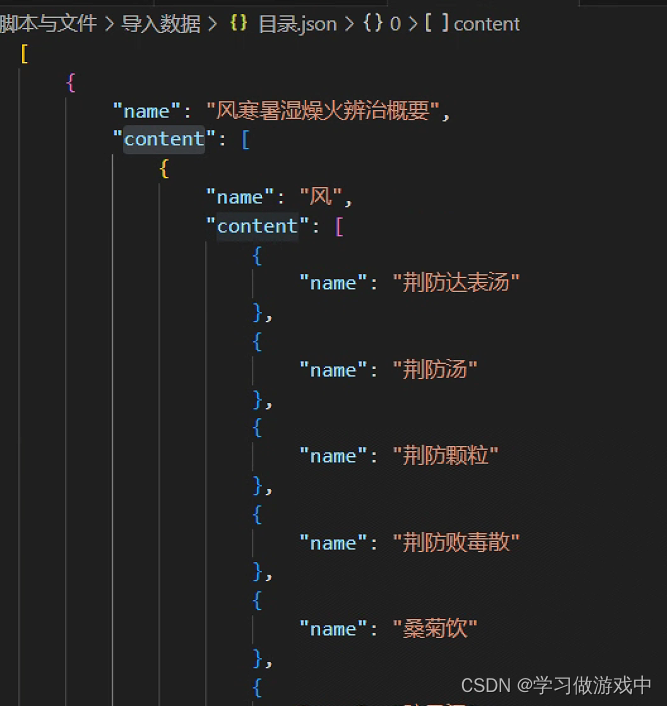
保存文章到wp
import json
import re
from wordpress_xmlrpc import Client, WordPressPost
from wordpress_xmlrpc.methods.posts import GetPosts, NewPost
from wordpress_xmlrpc.methods.users import GetUserInfo
from markdown2 import Markdownwp = Client('http://localhost:82/xmlrpc.php', 'asa', 'asa')
post = WordPressPost()
markdowner = Markdown()with open('目录.json', 'r',encoding="utf8") as f:content = f.read()p_class = json.loads(content)path = "截取部分doc文档内容.md"
with open(path, "r", encoding="utf-8") as f:content_all = f.read()def get_art(name):"""根据名字获取对应药方"""pattern = re.compile(</











)


)



