摘要
随着信息技术的飞速发展和数字化转型的深入推进,云原生架构已成为企业数字化转型的重要基石。Docker容器、Serverless和微服务等技术作为云原生的核心组成部分,正在不断推动着企业应用架构的革新与升级。本文旨在总结近期在云原生实践、容器技术、Serverless应用以及微服务架构等方面的最新研究成果和实践经验,为企业提供更高效、更灵活、更可靠的云原生解决方案。

Docker容器、Serverless和微服务等技术的作用
Docker容器技术的广泛应用为企业带来了前所未有的应用部署和管理的便利。通过容器化应用,企业可以快速构建、部署和扩展应用,同时降低运维成本和提升应用的可移植性。此外,容器技术还为企业提供了更好的资源隔离和安全性保障,有效防范了潜在的安全风险。

Serverless架构的兴起为企业带来了无服务器计算的全新体验。Serverless架构允许企业专注于业务逻辑的开发,而无需关心底层服务器的运维和管理。这种按需使用、自动伸缩的计算模式极大地降低了企业的运营成本,并提升了应用的响应速度和可扩展性。同时,Serverless架构还为企业提供了更加灵活的资源调度和更高效的资源利用率。
微服务架构的普及使得企业应用更加模块化和松耦合。通过将大型应用拆分成一系列小型、独立的服务,微服务架构提高了应用的可维护性和可扩展性。此外,微服务架构还促进了企业内部的团队协作和沟通,提高了开发效率和质量。
《2023腾讯云容器和函数计算技术实践精选集》阅读体验
《2023腾讯云容器和函数计算技术实践精选集》详细阐述了云原生实践中的具体案例和经验,内容涵盖了云监控、调度器设计、应用资源配置等多个方面。其中,Stable Diffusion腾讯云云原生容器部署实践案例集更是让我受益匪浅。在阅读这一案例集的过程中,我获得了极其深刻和丰富的体验,它不仅让我对Stable Diffusion模型有了更深入的理解,也让我对云原生架构有了更全面的认识。
AI绘图在各行业领域具有革命性作用,显著提升了工作效率和质量。它广泛应用于插画、游戏UI、平面包装、服装设计和模特拍摄以及建筑效果图等多个场景。插画师和概念艺术家可以利用AI绘图作为创作基础或灵感来源;游戏开发者通过AI生成大量UI图片和图标,节省时间和成本;平面包装设计师则利用AI的模糊方向和概念特性快速生成图案;服装设计师和模特拍摄行业也能借助AI进行创意设计和试穿效果预览;建筑领域则开始尝试使用AI生成效果图,提高设计师与客户之间的沟通效率。行业客户通常利用Stable Diffusion预训练模型结合微调插件,如LoRA和ControlNet,来输出符合业务场景需求的图片素材。
通过学习《Stable Diffusion 腾讯云云原生容器部署实践》案例,我学到了:
- 1、使用容器服务 TKE 和文件存储 CFS 在腾讯云上的轻松部署 Stable Diffusion
- 2、使用 qGPU,提高GPU的使用率
- 3、通过云原生 API 网关对外提供 Stable Diffusion 服务
- 4、优化 Stable Diffusion 推理性能
- 5、通过 COS 内容审核能力处理 Stable Diffusion API 输出
部署 Stable Diffusion
Stable Diffusion 是一种深度学习的文本到图像模型,由 Runway 和慕尼黑大学合作构建,第一个版本于 2021 年发布。目前主流版本包含 v1.5、v2 和 v2.1。它主要用于生成基于文本描述的详细图像,也应用于其他任务,如修复图像、生成受文本提示引导的图像到图像的转换等。
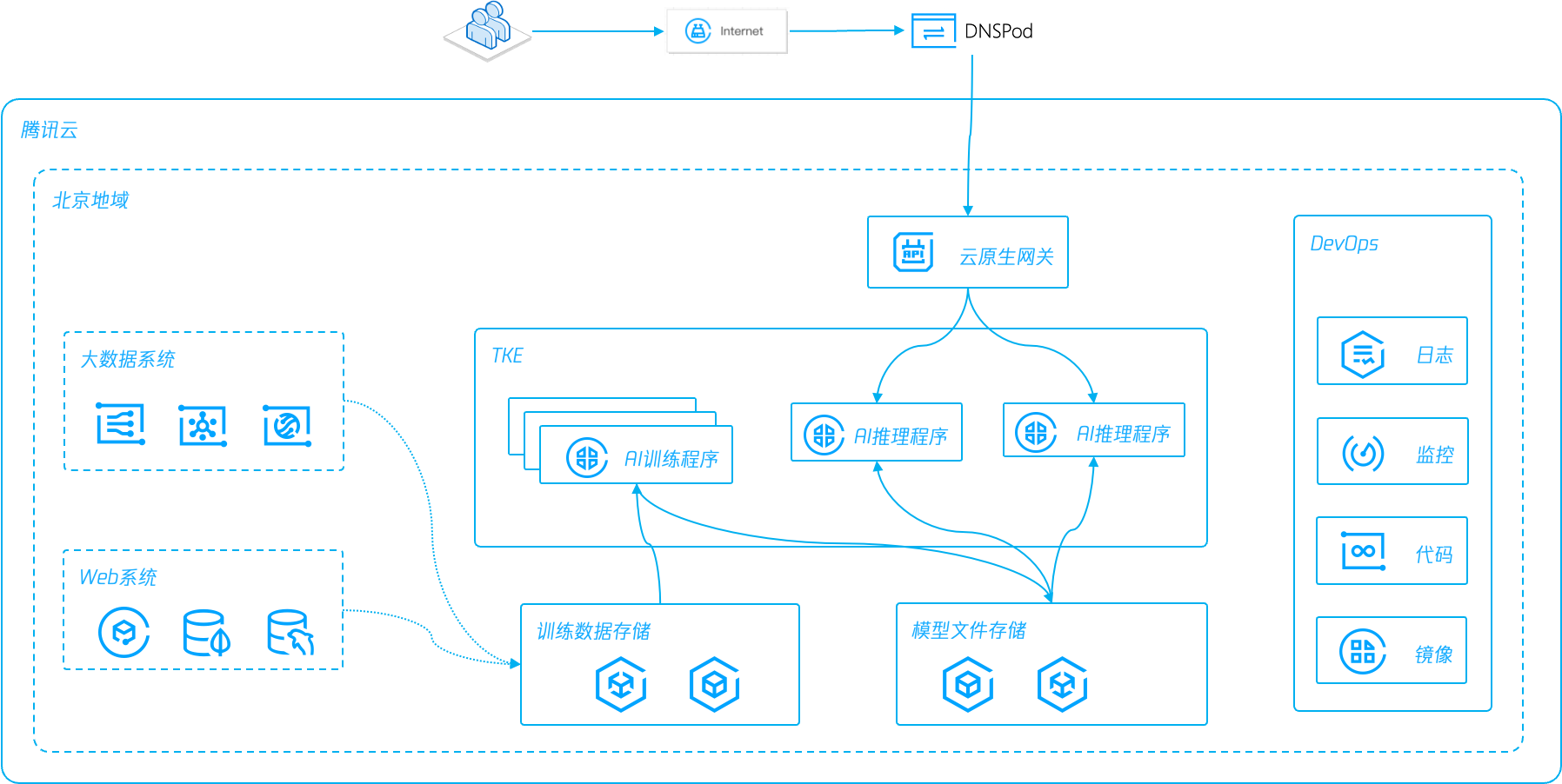
部署 Stable Diffusion架构图:
搭建步骤
- 准备需使用 Stable Diffusion 容器镜像
GitHub 下载 Stable Diffusion web UI(https://github.com/AUTOMATIC1111/stable-diffusion-webui) 代码,制作 Docker 镜像。也可使用以下命令获取:
docker pull gpulab.tencentcloudcr.com/ai/stable-diffusion:1.0.7
将准备好的 Stable Diffusion 容器镜像上传到容器镜像仓库 TCR
- 准备待部署 Stable Diffusion 的 TKE 集群
- 开通并创建 TKE 集群,操作步骤详情可参见 创建容器服务集群(https://cloud.tencent.com/document/product/457/32189)。在创建集群时,Kubernetes 版本选择最新的1.26.1,容器网络插件选择 Global Router,其他选项默认即可。
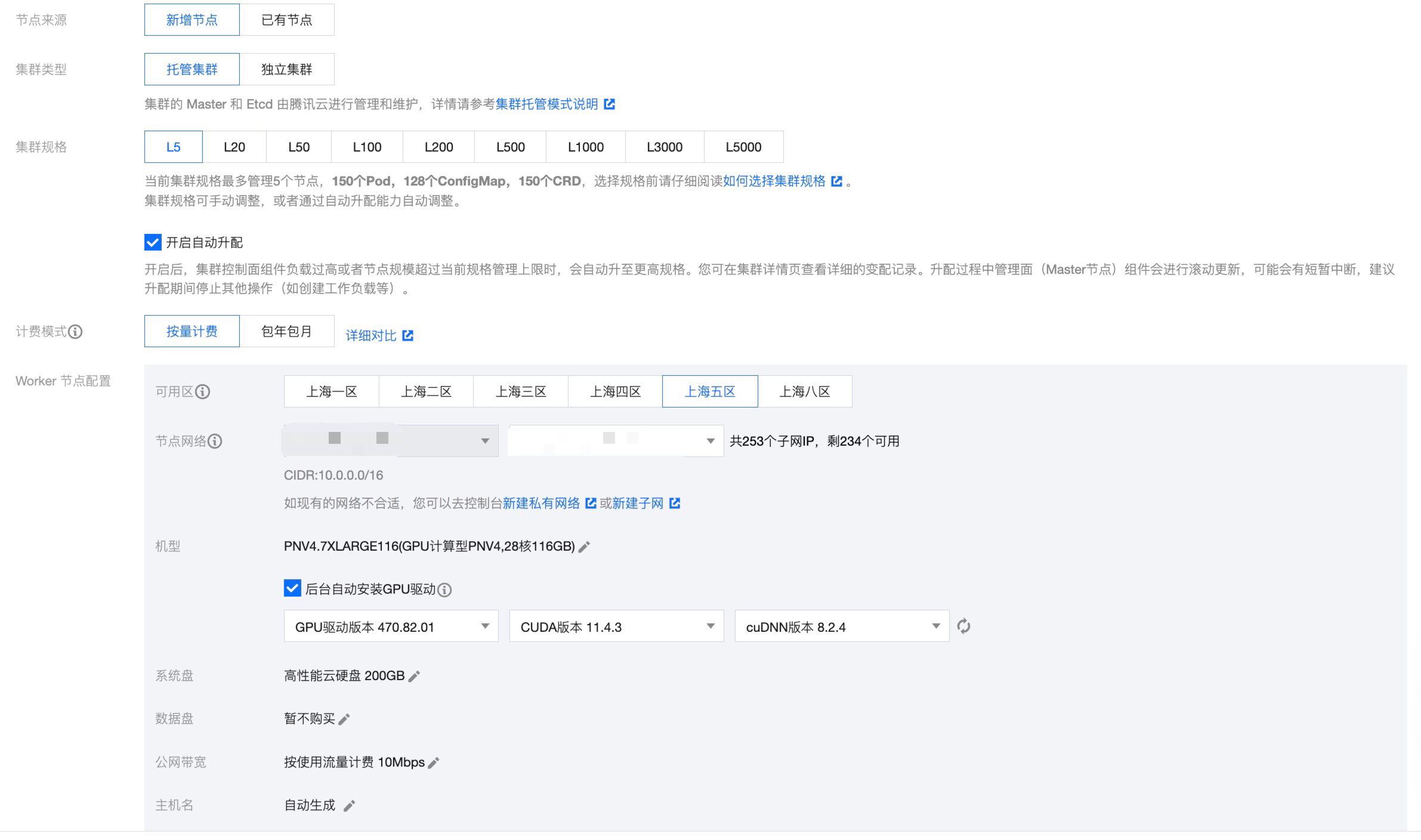
- 集群选择托管类型,Worker 节点选择 GPU 计算型PNV4 - A10,安装 GPU470驱动,CUDA 版本11.4.3,cuDNN 版本 8.2.4。如下图所示:
3. 根据部署对 GPU 共享的需求,您可以选择开启 qGPU,如何开启qGPU接下来的步骤会讲。
- 通过 TKE+CFS 快速部署 Stable Diffusion Web UI
-
创建存放模型的文件存储 CFS
- 开通 CFS 服务,创建文件系统及挂载点时选择与集群相同的 VPC 和子网。在 CFS 远程挂载点,新建 /models/Stable-diffusion 目录。挂载点和文件操作,详情可参见 创建文件系统及挂载点(https://cloud.tencent.com/document/product/582/9132)。
- 下载 v1-5-pruned-emaonly.safetensors 模型文件至 /models/Stable-diffusion,地址见:runwayml/stable-diffusion-v1-5(https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main)。
-
创建静态 PV/PVC
-
在 容器服务控制台(https://console.cloud.tencent.com/tke2/cluster?rid=1) 中创建 CFS 类型 StorageClass,并选择共享实例。操作步骤可参见 通过控制台创建 StorageClass(https://cloud.tencent.com/document/product/457/44235#.E6.8E.A7.E5.88.B6.E5.8F.B0.E6.93.8D.E4.BD.9C.E6.8C.87.E5.BC.95)。

-
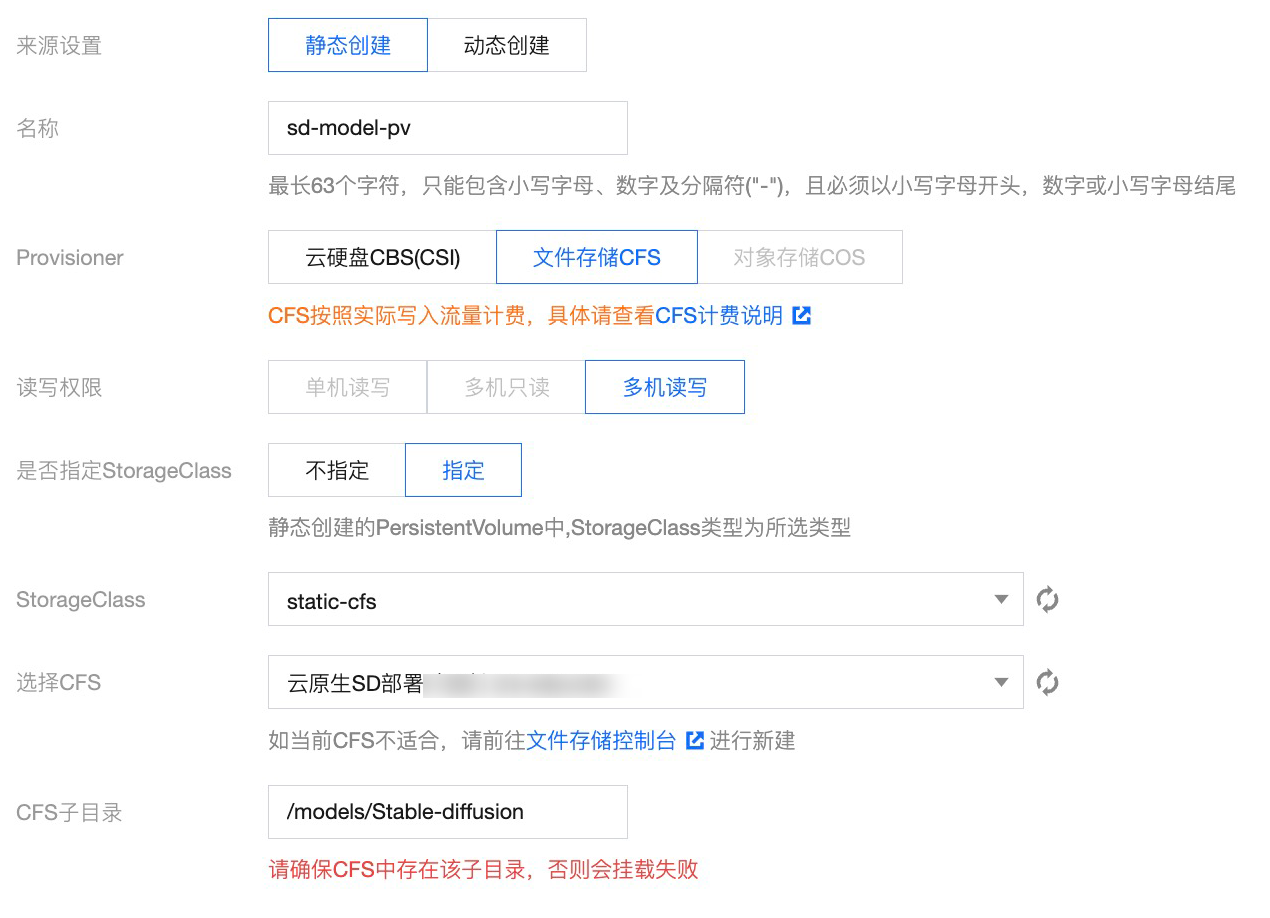
使用 CFS 中新建的 /models/Stable-diffusion 目录以及已创建的 StorageClass,静态创建 PV/PVC。
创建 PV 如下图所示:
创建 PVC 如下图所示:
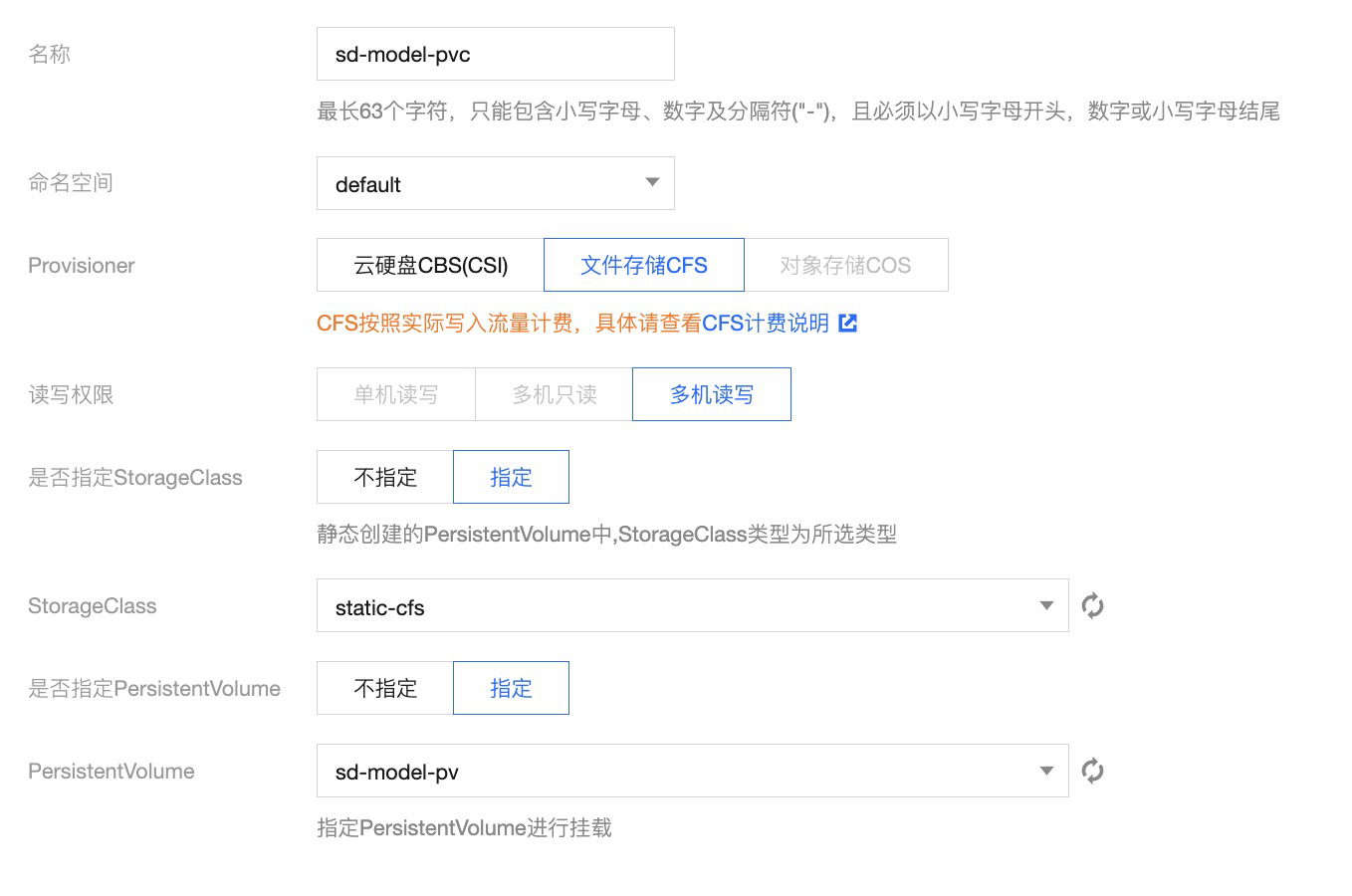
-
如果您有其他模型目录挂载的需求,同样需要在 CFS 挂载点中新建子目录,并进行 PV/PVC 的静态创建。Stable Diffusion Web UI 服务的 models 子目录结构如下:
-
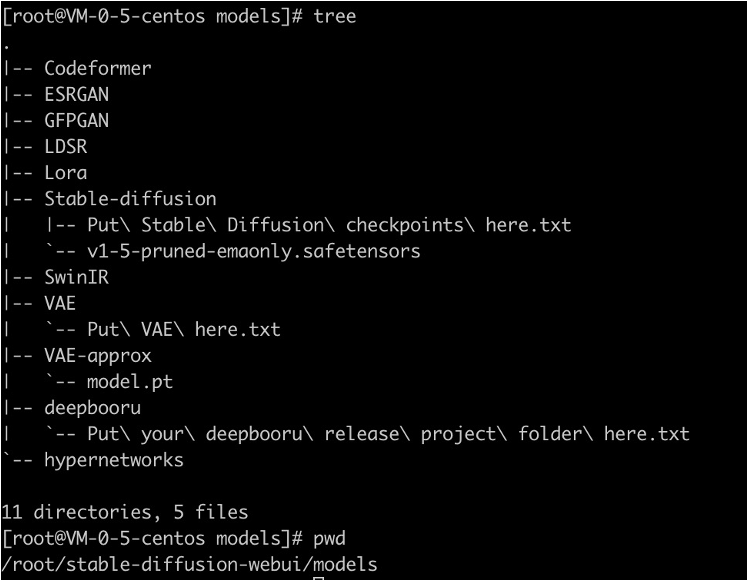
-
创建 Stable Diffusion Web UI 工作负载
-
在 容器服务控制台 中,选择左侧导航中的集群。
-
在集群详情页,选择工作负载 > Deployment,单击新建,开始部署 stable-diffusion-webui 镜像。
-
在新建 Deployment 页,填写 Deployment 基本信息,其中数据卷选择添加数据卷。
-
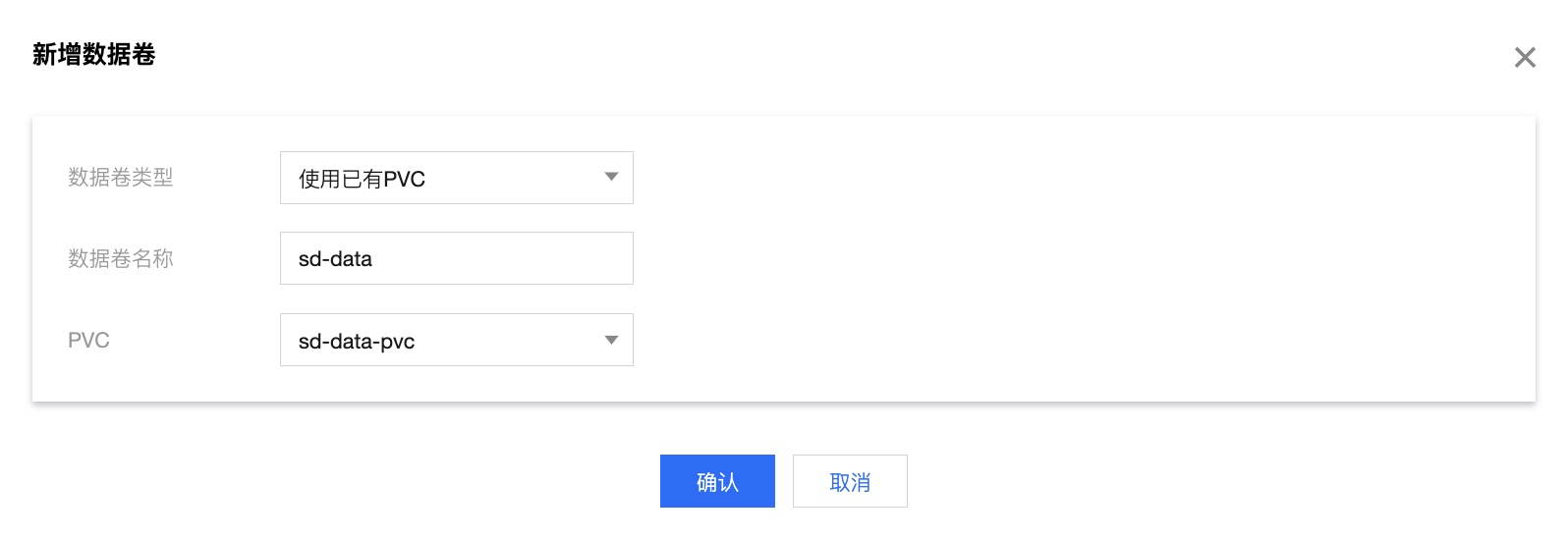
在新增数据卷页,数据卷类型选择使用已有 PVC,添加 已创建的 PVC,完成后单击确认。
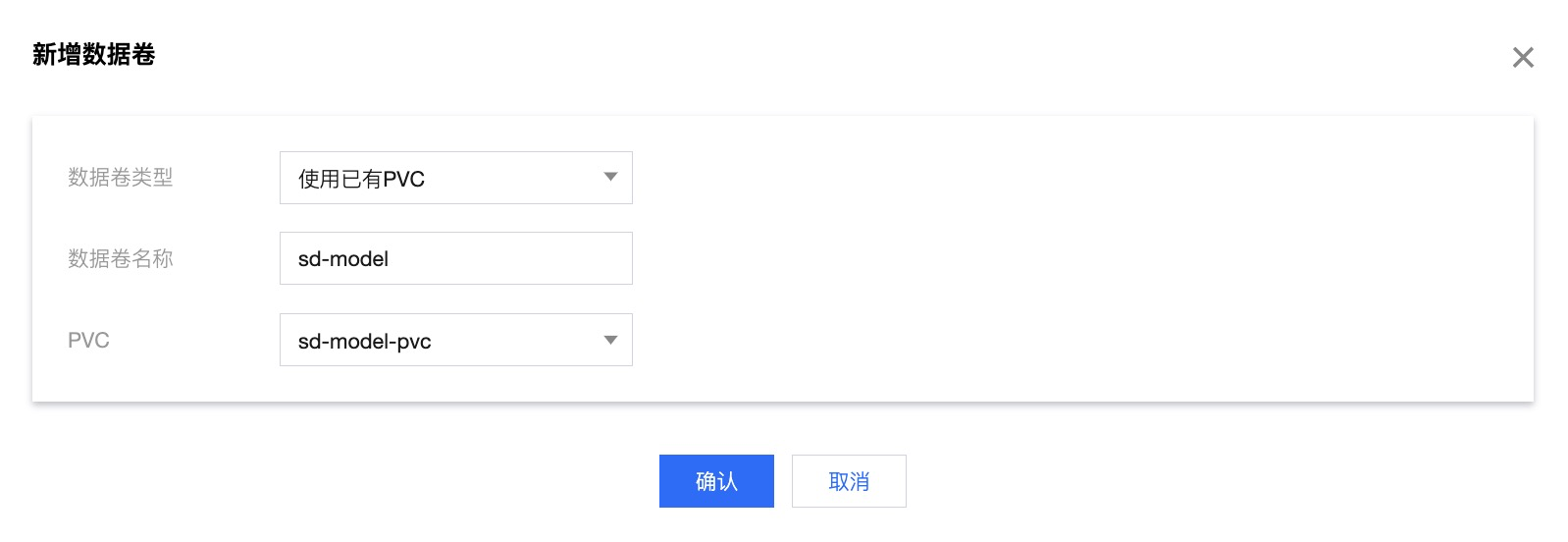
-
在实例内容器中,单击选择镜像,选择已保存在 TCR 中的 stable-diffusion-webui 镜像。
-
将新建的数据卷进行挂载点配置。挂载点与 CFS 远程目录对应关系如表格所示:


-
展开显示高级设置,添加运行参数–listen,将 stable-diffusion-webui 进程监听在0.0.0.0上。
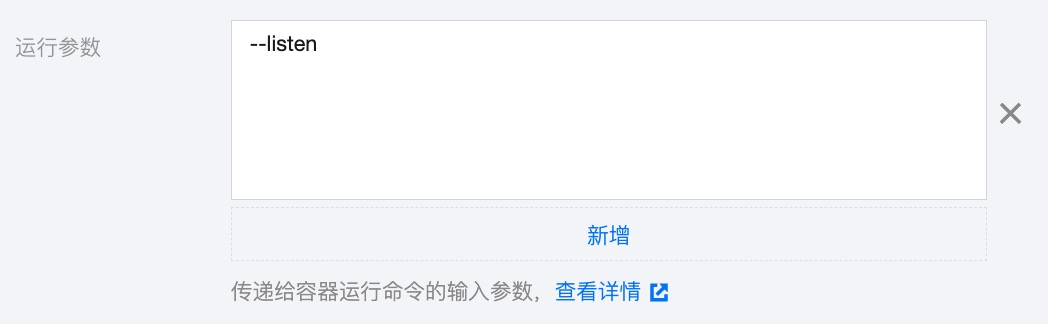
-
将 GPU 资源的卡数设置为1,如果开启了 qGPU,您还可以填写0.1-1之间的数值,对 GPU 卡进行虚拟化切分。
-
创建 Deployment 对应的 Service,并选择公网 LB 访问,对外暴露7860端口访问。
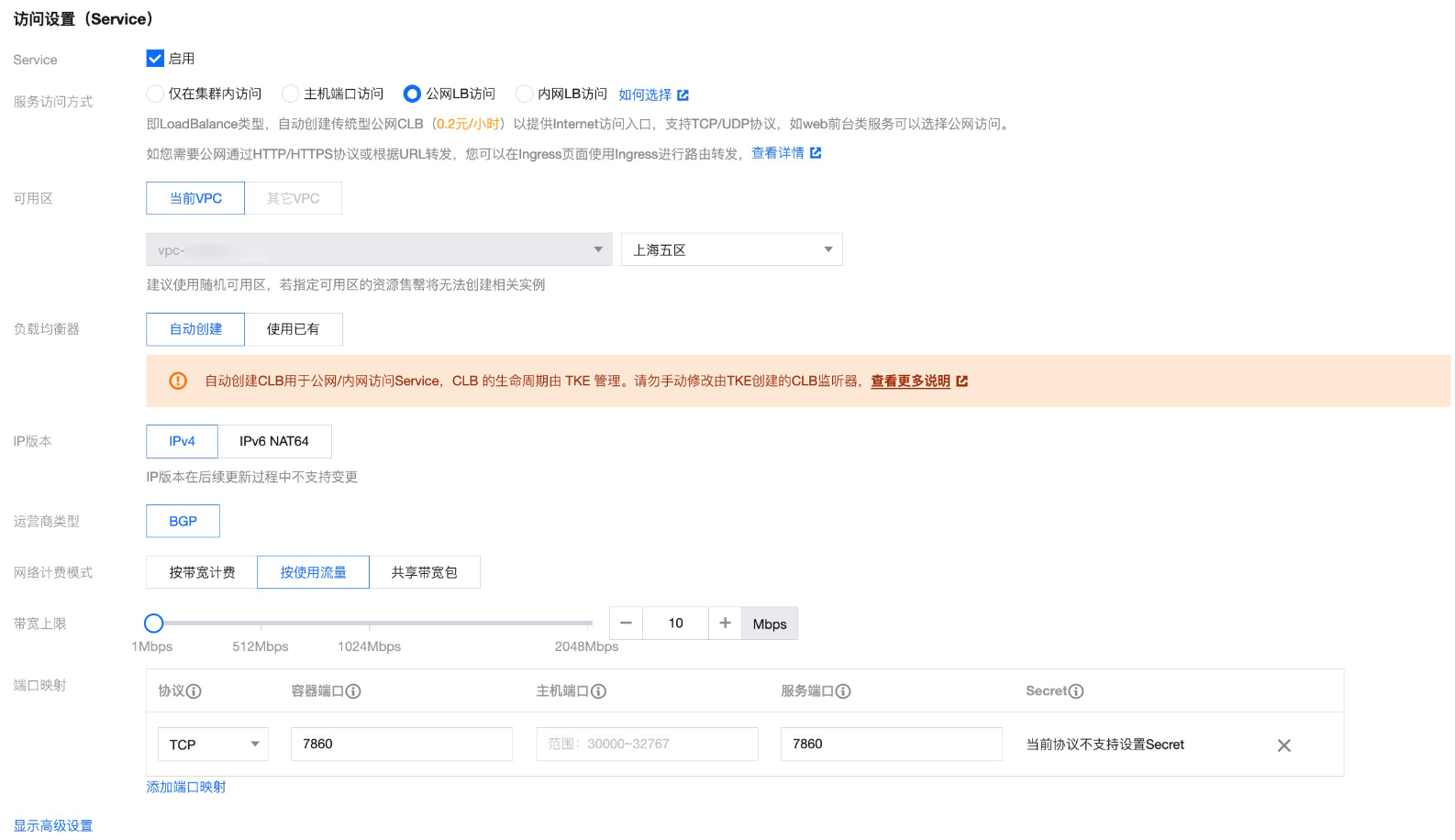
-
通过 CLB 公网 IP 地址,您就可以成功访问 Stable Diffusion Web UI 服务了。
-
进阶教程
1、如何使用 qGPU
Stable Diffusion Web UI 服务以串行方式处理请求,如果您希望增加推理服务的并发性能,可以考虑扩展 Deployment 的 Pod 数量,以轮询的方式响应请求。在这里,我们采用 TKE qGPU 能力,将多个实例 Pod 运行在同一张 A10 卡上。在保障业务稳定性的前提下,切分显卡资源,降低部署成本。
采用 qGPU 方式,您需要先将 Pod 的资源申请方式进行修改。例如,如果您计划在单卡上部署2个 Pod,您需要在 YAML 文件中将 tke.cloud.tencent.com/qgpu-core 从100更改为50,也就是将50%的算力分配给每个 Pod。同时,您还需要将 tke.cloud.tencent.com/qgpu-memory 的数值设置为 A10 显存的一半。
resources:limits:cpu: "20"memory: 50Gitke.cloud.tencent.com/qgpu-core: "50"tke.cloud.tencent.com/qgpu-memory: "10"
Deployment YAML 文件更新完成后,调整 Pod 数量为2个,即可实现负载均衡的 Stable Diffusion 轮询模式。
2、通过云原生 API 网关对外提供 Stable Diffusion 服务
- 开通云原生网关,选择和 TKE 集群、CFS 同 VPC 的实例。
- 在 腾讯云微服务引擎控制台(https://console.cloud.tencent.com/tse) 上,选择实例名称,进入实例详情页。
- 选择路由管理 > 服务来源,单击新建,在新建服务来源中选择容器服务,绑定 TKE 集群。
- 选择路由管理 > 服务,单击新建,新建网关服务。选择服务列表时,选择部署 Deployment 时启用的 Service 进行映射。云原生网关会自动拉取 TKE Service 关联的 Pod IP。当 Pod IP 变化时,动态更新网关服务里的 Upstream 配置项。
- 单击服务名,新建访问路由。在基本信息配置中,将请求方法设置为 ANY,Host 填写云原生网关的公网 IP。如果后期绑定域名使用,Host 还需要加上域名地址。如下图所示:
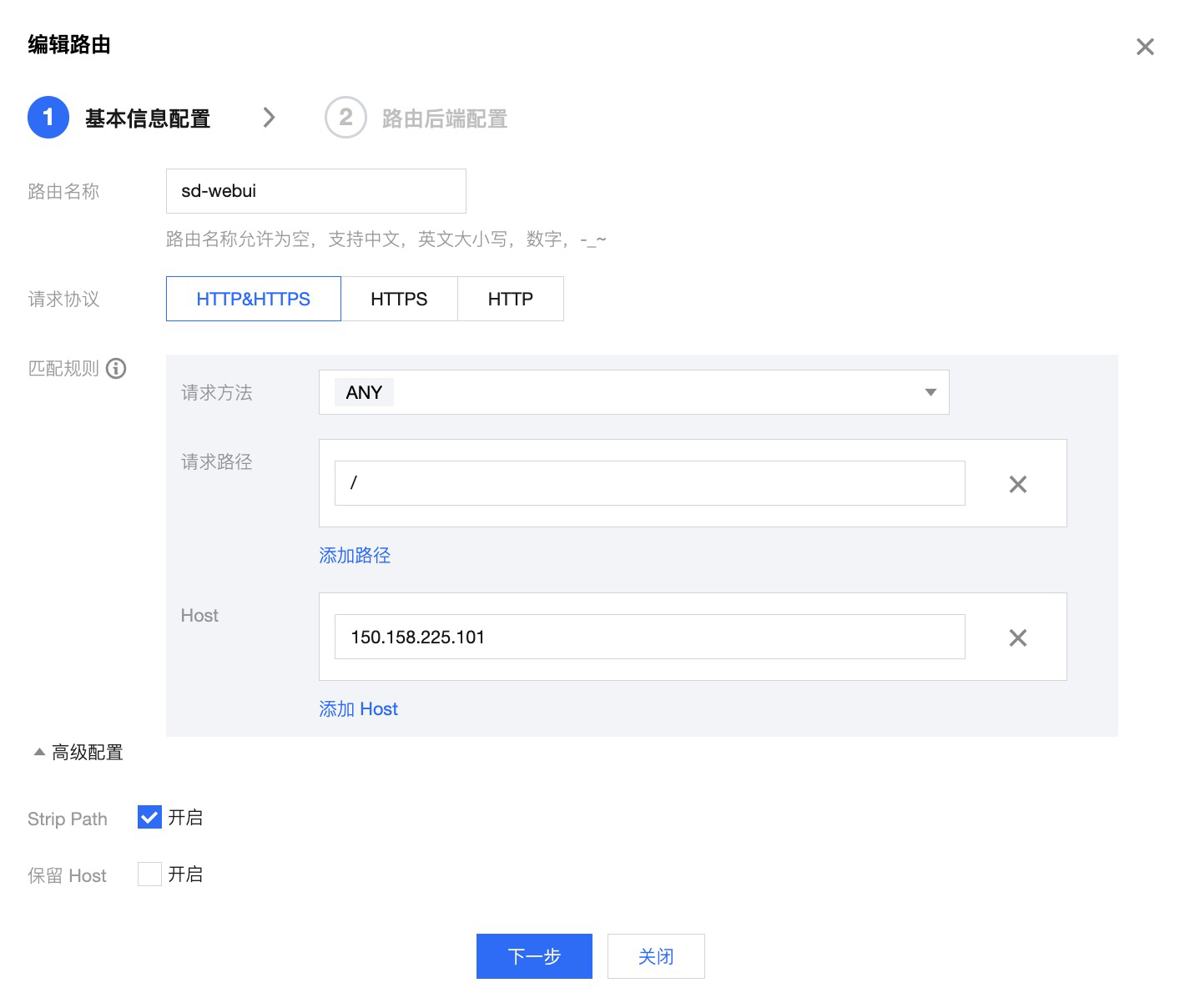
- 根据资源用量和计划访问请求数,您可以选择配置网关限流策略,并自定义限流响应内容。
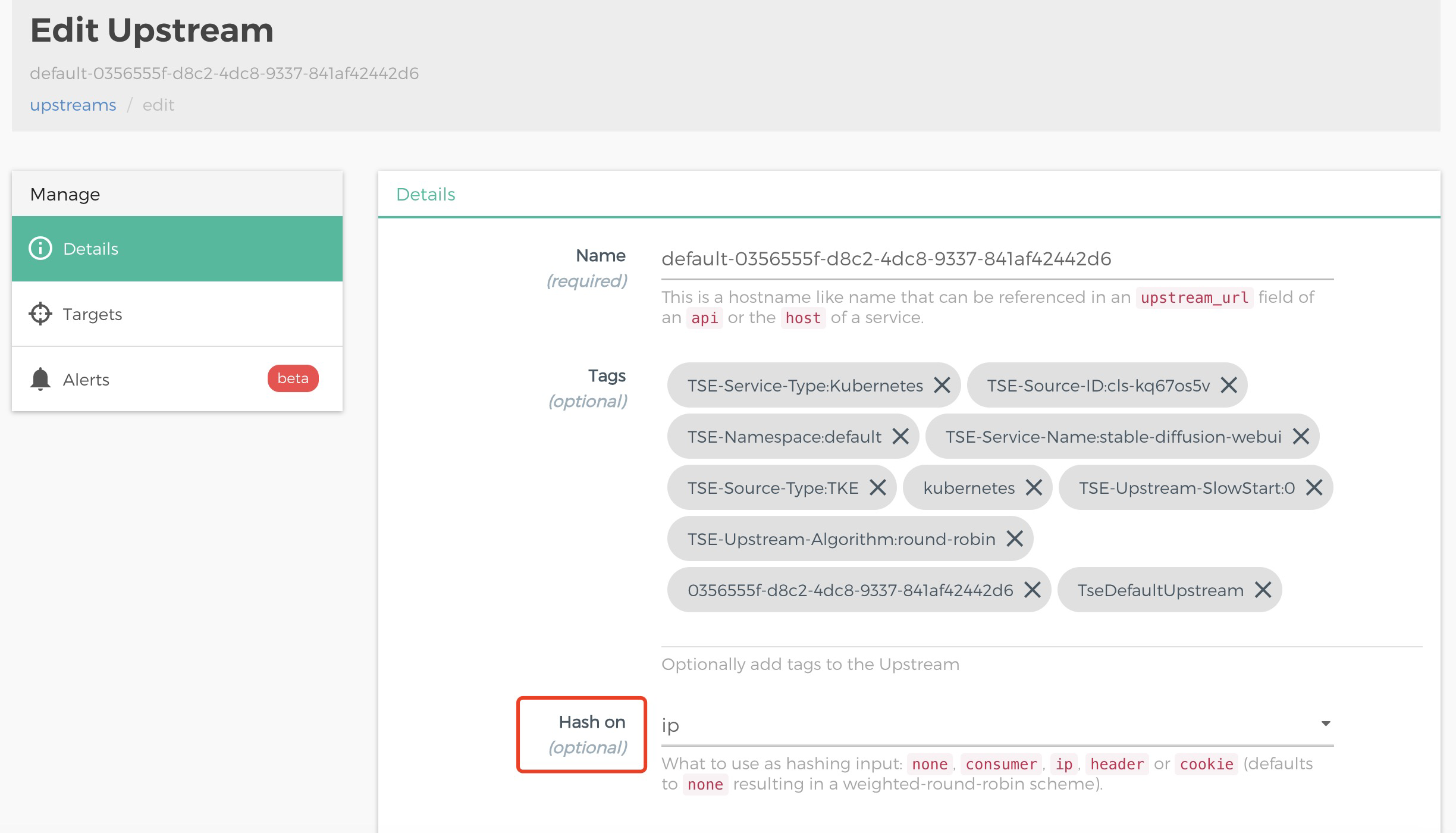
- Stable Diffusion Web UI 出图时会进行多轮请求,将 Deployment 的 Pod 副本数量修改为大于1时,您还需要配置 Session 会话保持,以保证同一 IP 的客户请求落在相同的 Pod 里。选择路由管理 > Konga 控制台,找到 Konga 公网访问地址,在 Konga 控制台里找到 UPSTREAM,单击 DETAILS,如下图所示:
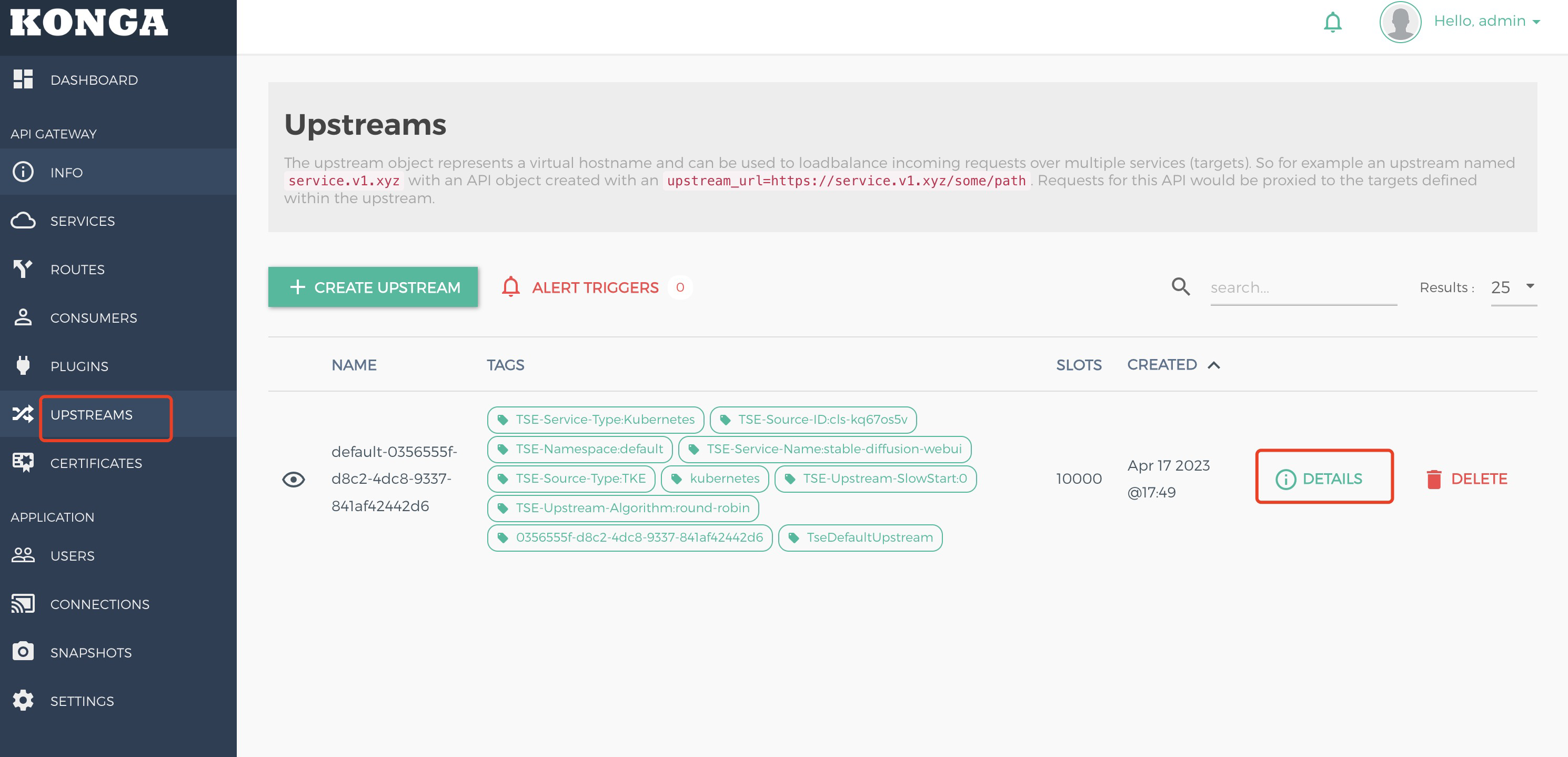
在 HASH ON 下拉框里,选择 IP,完成基于客户端 IP 的会话保持配置。
4、优化 Stable Diffusion 推理性能
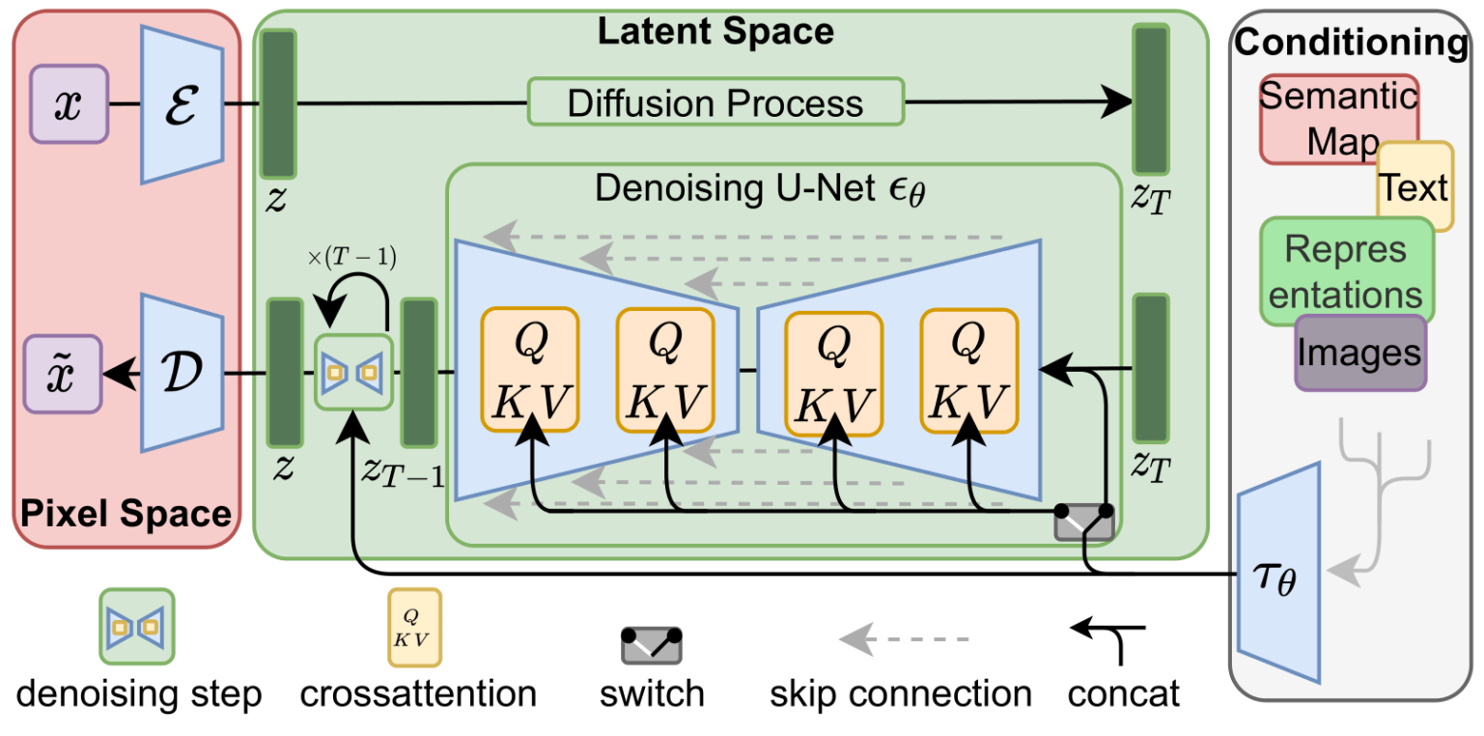
Stable Diffusion 是一个多模型组成的扩散 Pipeline,主要由三个部分组成:变分自编码器 VAE、U-Net 和文本编码器 CLIP。推理耗时主要集中在 UNet 部分,我们选择对这部分进行模型优化,以加速推理速度。
- 下载 A10 GPU 优化的 stable-diffusion-v1.5 UNet 模型文件,以及 sd_v1.5_demo 镜像,该镜像里的 Web UI 修改了模型加载代码,UNet 部分会加载独立优化模型。
- 将 sd_v1.5_demo 镜像服务部署在 TKE 上:按前述步骤进行操作,其中替换镜像为 sd_v1.5_demo,并额外为 UNet 优化模型创建 CFS /data 目录和 PV/PVC。

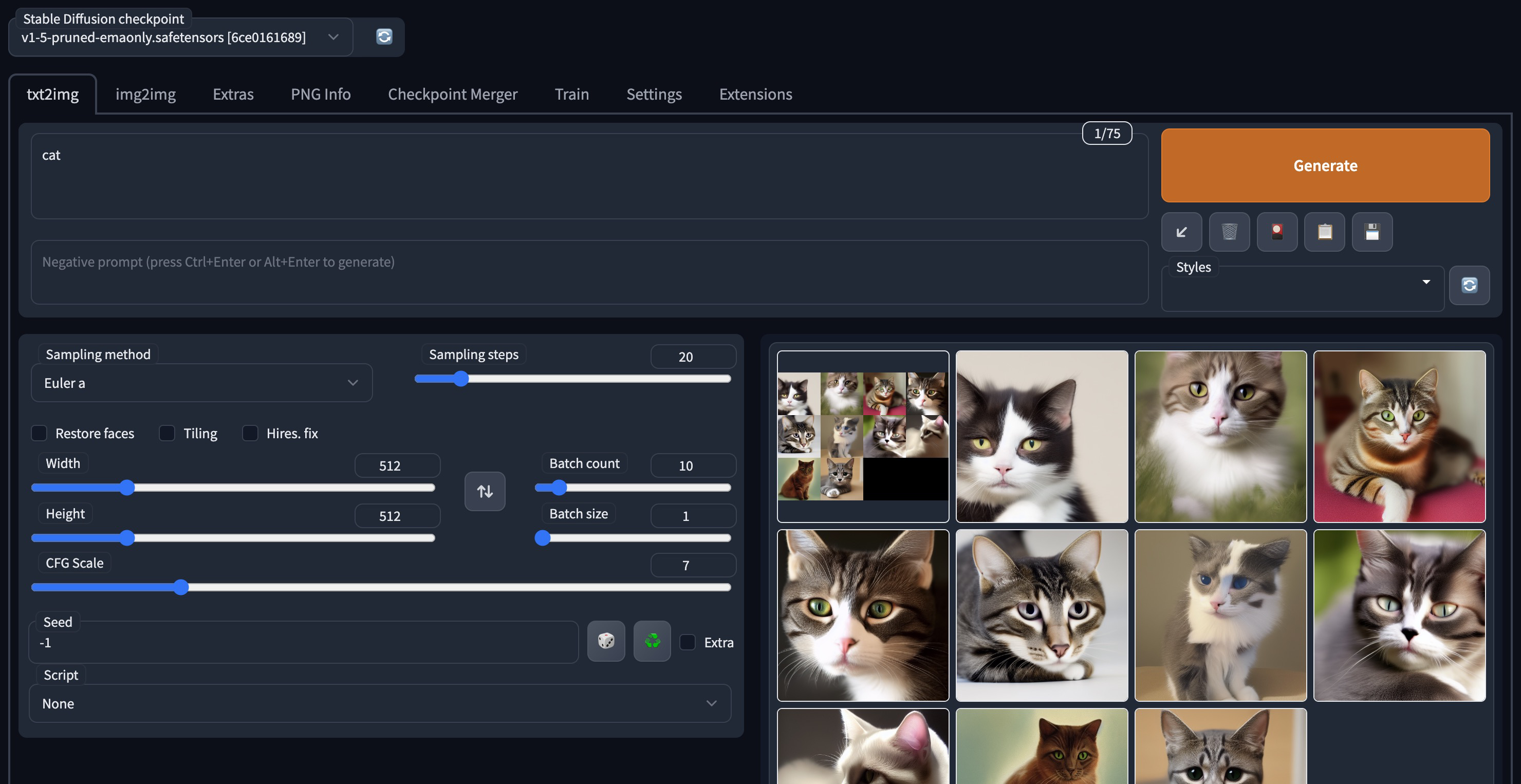
- 在相同的参数配置下,生成10张猫的图片。在优化前,推理耗时为16.14s。在加载 TACO 优化的 UNet 模型后,10张图片仅耗时11.56s,端到端性能提高30%。


- TACO 可以对 Stable Diffusion 系列模型进行优化。如果您希望对其他 Stable Diffusion 微调模型进行推理优化,并部署在上述环境中,可以按照以下步骤操作:
-
4.1 参见 TACO Infer 优化 Stable Diffusion 模型,拉取预置库环境的 sd_taco:v3 镜像。
-
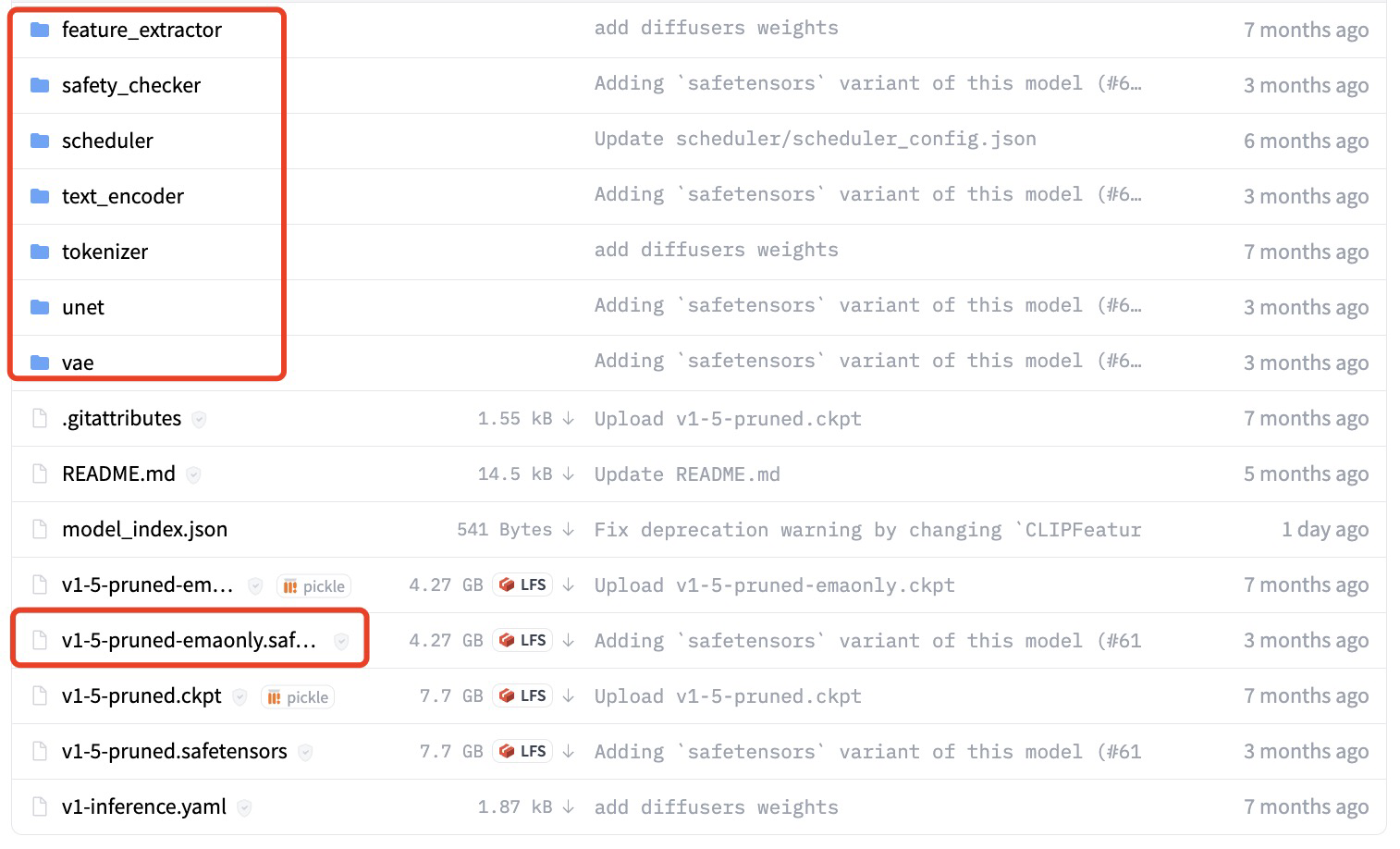
4.2 Stable Diffusion 模型主要有两种存储方式:单文件和 diffusers 目录结构。其中 diffusers 结构按照 Stable Diffusion 的模型结构组织,包含unet、vae、text-encoder 等。在 TACO 优化过程中,会使用 diffusers 结构读取模型。可以在 HuggingFace 上找到这种格式的模型文件进行下载。
-
4.3 如果 HuggingFace 速度较慢,也可以使用官方的转换脚本,将单文件格式(ckpt 或 safetensors)转化成 diffusers 格式使用。脚本见https://github.com/huggingface/diffusers/tree/main/scripts
python convert_original_stable_diffusion_to_diffusers.py --checkpoint_path [single_file_model_name] --dump_path [diffusers_model_directory] --from_safetensors
- 4.4 选择一台 A10 GPU CVM,使用 -v 命令挂载上面的 diffusers 模型目录,交互式启动容器,在容器内部对挂载好的模型进行优化。
docker run -it --gpus=all --network=host -v /[diffusers_model_directory]:/[custom_container_directory] sd_taco:v3 bash
4.5 使用 diffusers 加载模型权重,从中导出 UNet 模型进行优化。
4.6 完成后将优化后的模型放入 CFS 挂载的 /data 目录。UNet 从优化文件中加载,而单文件格式模型(ckpt 或 safetensors)仍然放入 CFS 挂载的 /models/Stable-diffusion 目录,Stable Diffusion 其他部分从原始文件里加载。
4.7 重启 stable-diffusion-webui 界面,选择新模型使用。
总结
该案例展示了Stable Diffusion模型在互联网行业的应用,并详细描述了如何利用腾讯云原生产品进行高可用部署的工程化实践。在生产环境中,推理服务需要考虑服务的可用性、扩展性、多模型文件管理的便利性以及业务架构的灵活性。同时,由于Stable Diffusion推理过程耗时且GPU部署成本较高,提高推理速度和合理设计限流熔断机制至关重要。腾讯云云原生能力能够满足这些需求,实现前后端解耦,提高架构吞吐能力,并通过弹性能力降低资源部署成本。这些实践经验对于当前工作和未来职业发展都具有重要意义。
通过对案例集的深入阅读,我深刻感受到云原生架构及其相关技术所蕴含的巨大潜力与价值。案例集的清晰明了编写风格与丰富的图表截图,不仅我全面掌握了Stable Diffusion模型部署和管理的技巧,更对云原生核心理念和技术架构有了更深入的理解。云原生架构以其全面、高效和可靠的特性,为企业数字化转型提供了重要支撑,助力企业灵活应对业务变化,快速响应市场需求。随着Docker容器、Serverless和微服务等技术的不断进步,云原生架构将为企业创造更大的价值,推动数字化转型迈向新的高度。
《2023腾讯云容器和函数计算技术实践精选集》下载链接:
https://download.csdn.net/download/csdnnews/88942959?spm=1001.2014.3001.5503



开发工具)


激活版)

)
——POSIX信号量使用例程)



)





(七))