1、引言
跨模态大模型是指能够在不同感官模态(如视觉、语言、音频等)之间进行信息转换的大规模语言模型。当前图文跨模态大模型主要有:
-
文生图大模型:如 Stable Diffusion系列、DALL-E系列、Imagen等
-
图文匹配大模型:如CLIP、Chinese CLIP、BridgeTower等
今天主要讨论Stable Diffusion,首先让我们看一下,Stable Diffusion能做什么呢?
-
最简单的形式:给它一个文本提示(Text Prompt) ,它将返回与文本匹配的图像。
-
除此之外,Stable Diffusion还可以用于图像超分、图像修复、样本生成等领域。

Stable Diffusion的发展历程,主要经过如下三个阶段:
-
DDPM:无条件图片生成(不支持文本提示)
-
LDM:有条件图片生成(支持文本等其他形式提示)
-
Stable Diffusion:基于LDM发展而成的强大的文生图大模型
接下来,本文将按照Stable Diffusion的发展历程展开讲解!
2、DDPM
2.1 概要
Denoising Diffusion Probabilistic Models(去噪概率扩散模型,DDPM)在图像生成领域具有里程碑的意义,当前一些主流的文本转图像模型如DALL·E 2、stable-diffusion 和 Imagen 均采用了扩散模型(Diffusion Model)作为图像生成模型,这也引发了对扩散模型的研究热潮。相比传统的GAN来说,扩散模型训练更稳定,而且能够生成更多样的样本。
2.2 基本原理
任务:从随机“向量”到真实图像的生成。和GAN不同的是,DDPM的输入和输出形状是一样的。
动机:DDPM的核心动机,如果我们一点一点地往图像中加噪声,直到把它变成高斯噪声;然后我们把所有加噪的过程逆过来,就可以把高斯分布映射成真实图像的分布。
做法:基于以上动机,作者就设置了如图的加噪声过程(diffusion)和去噪过程(denoising),作者假设加噪过程是个马尔可夫过程,即当前状态只跟上一个状态相关。
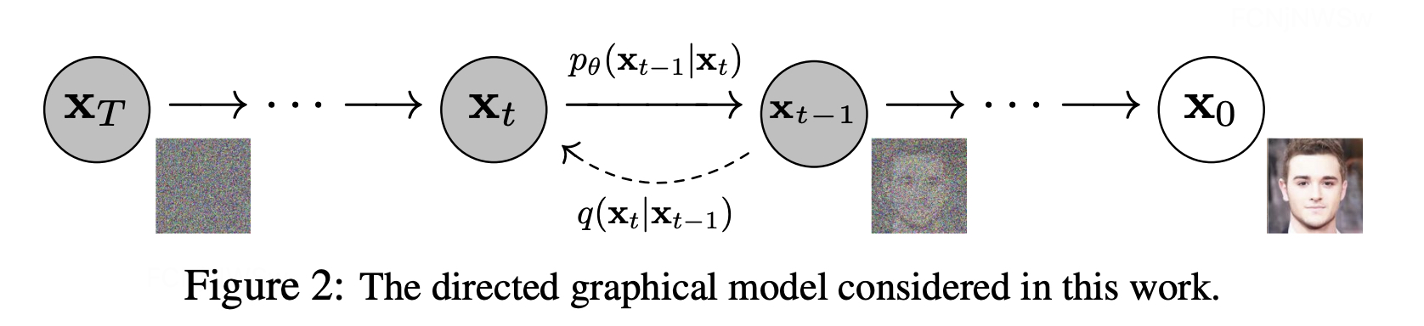
扩散模型包括两个过程:
-
前向过程(扩散,加噪):对原图x0逐渐增加高斯噪音直至数据变成随机噪音的过程。
-
反向过程(去噪):是一个去噪的过程,如果知道反向过程的每一步噪声的真实分布,那么从一个随机噪音N(0, 1)开始,逐渐去噪就能生成一个真实的样本。
简单来讲,图像生成的过程,就是一个去噪的过程;因此扩散模型的关键在于学习图像在前向过程中加入的噪声。
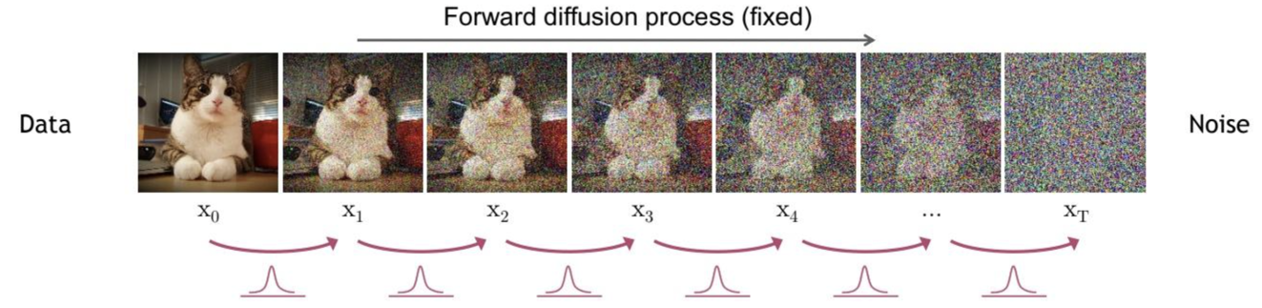
前向过程中,从原图x0到x1,x1到x2,最后到的过程,可以用如下公式表示:
![]()
式中,xt-1表示第t-1步的噪声图,xt表示第t步的噪声图。理论上,已知x0和 t,可以通过一步步推导获得xt,但是实际上,这种方式比较耗费计算资源。因此作者通过一种方式(重参数化技巧),能实现x0到xt的直接计算,这样就能节省大量资源,如下如所示:如果能从x0直接到x4,就不需要从x1到x2到x3再到x4。

2.3 重参数化
扩散过程的一个重要特性是可以直接基于原始数据x0来对任意t步的xt进行采样。在扩散阶段,根据重参数化,可以推导出x0到xt的直接公式:


扩散过程的这个特性很重要。首先,我们可以看到xt其实可以看成是原始数据x0和随机噪音ϵ的线性组合,其中和
为组合系数,它们的平方和等于1,我们也可以称两者分别为
signal_rate和noise_rate。
更近一步地,我们可以基于而不是来定义noise schedule,比如我们直接将设定为一个接近0的值,那么就可以保证最终得到的近似为一个随机噪音。其次,后面的建模和分析过程将使用这个特性。
2.4 网络结构
扩散模型的核心就在于训练噪音预测模型,由于噪音和原始数据是同维度的,所以我们可以选择采用AutoEncoder架构来作为噪音预测模型。DDPM所采用的模型是一个基于residual block和attention block的U-Net模型。如下所示:
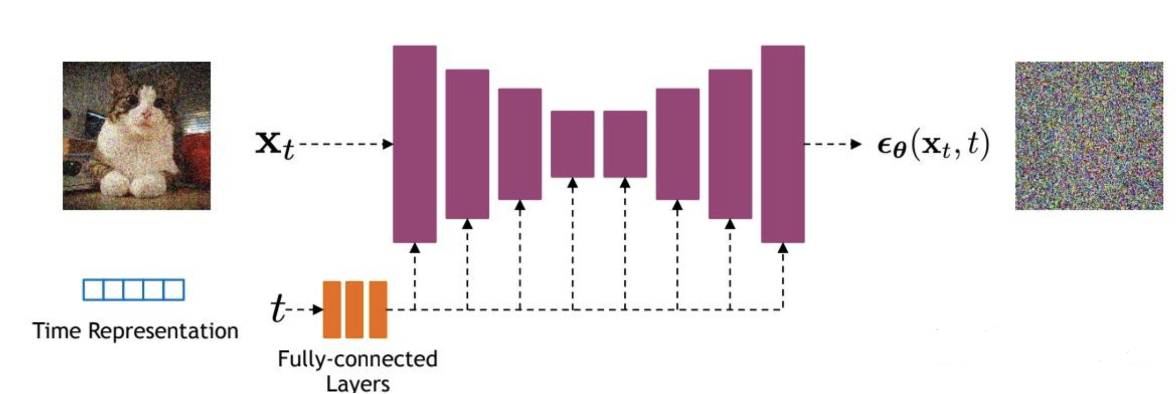
经U-Net改进过后的整体网络结构如下:
-
U-Net属于encoder-decoder架构,其中encoder分成不同的stages,每个stage都包含下采样模块来降低特征的空间大小(H和W),然后decoder和encoder相反,是将encoder压缩的特征逐渐恢复。
-
U-Net在decoder模块中还引入了skip connection,即concat了encoder中间得到的同维度特征,这有利于网络优化。
-
DDPM所采用的U-Net每个stage包含2个residual block,而且部分stage还加入了self-attention模块增加网络的全局建模能力。
-
扩散模型其实需要的是T个噪音预测模型,实际处理时,我们可以增加一个time embedding(类似transformer中的position embedding)来将timestep编码到网络中,从而只需要训练一个共享的U-Net模型。具体地,DDPM在各个residual block都引入了time embedding。
2.5 模型训练
虽然扩散模型背后的推导比较复杂,但是我们最终得到的优化目标非常简单,就是让网络预测的噪音和真实的噪音一致。DDPM的训练过程也非常简单,如下图所示,训练过程具体步骤为:
-
随机选择一个训练样本
-
从1~T随机抽样一个t
-
随机产生高斯噪音,并计算当前所产生的带噪音数据xt
-
输入网络预测噪音
-
计算产生的噪音和预测的噪音的L2损失
-
计算梯度并更新网络

一旦训练完成,其采样过程也非常简单:我们从一个随机高斯噪音开始,并用训练好的的网络预测每一步的(从T到1)噪音,并根据该噪声去噪,就能逐步获得精细的生成图像。
2.6 实现效果
衡量模型生成图像质量的指标:
-
Inception Score(IS):图像质量的期望值(Exp)和图像质量分布的分歧度(KL),越大越好。
-
Fréchet Inception Distance(FID):生成图像和真实图像在特征空间中的分布距离;衡量它们之间的差异,越小越好。
1、在CIFAR10数据集上,DDPM获得了9.46的Inception分数和3.17的最先进的FID分数。

2、在分辨率为256x256 LSUN数据集上,DDPM能生成与ProgressiveGAN同样高质量的图像。

2.7 不足点
虽然DDPM能够生成高质量的图片,但是还存在一些不足:
-
计算量大:由于DDPM整个扩散过程是在像素空间上进行的,所以计算量很高
-
不支持条件控制:DDPM是一个单纯的图像生成模型,不支持文本等提示信息,从而限制了其的发展。
3、LDM
3.1 概要
Latent Diffusion Models(潜在扩散模型,LDM)通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火。除此之外,LDM在无条件图片生成、图片修复、图片超分任务上也进行了实验,都取得了不错的效果。

3.2 主要创新点
-
LDM提出了cross-attention的方法来实现多模态训练,使得条件图片生成任务也可以实现。论文中提到的条件图片生成任务包括:类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。这也为日后Stable Diffusion的开发奠定了基础。
-
DDPM在像素空间上训练模型,需要反复迭代计算,因此训练和推理代价都很高。DLM提出一种在潜在表示空间上进行扩散过程的方法,能够显著减少计算复杂度,同时也能达到十分不错的图片生成效果。
-
相比于其它空间压缩方法,论文提出的方法可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。
3.3 网络结构
Latent Diffusion Models整体框架如图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 E 和一个解码器D。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。

3.4 图片感知压缩
定义:利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后再用解码器恢复到原始像素空间。
原理:通过VAE这类自编码模型对原图片进行处理,忽略掉图片中的高频信息,只保留重要、基础的一些特征;这种方法能够大幅降低训练和采样阶段的计算复杂度。
感知压缩主要利用一个预训练的自编码模型,该模型能够学习到一个在感知上等同于图像空间的潜在表示空间。在感知压缩的过程中,设置下采样因子的大小为: f=H/h=W/w,通过对原图进行f倍的下采样,让扩散模型在潜在空间中进行,从而减小计算量。
论文对比了 f 在分别 {1, 2, 4, 8, 16, 32}下的效果,发现 f 在 {4−16}之间可以比较好的平衡压缩效率与视觉感知效果。作者重点推荐了LDM-4 和 LDM-8。
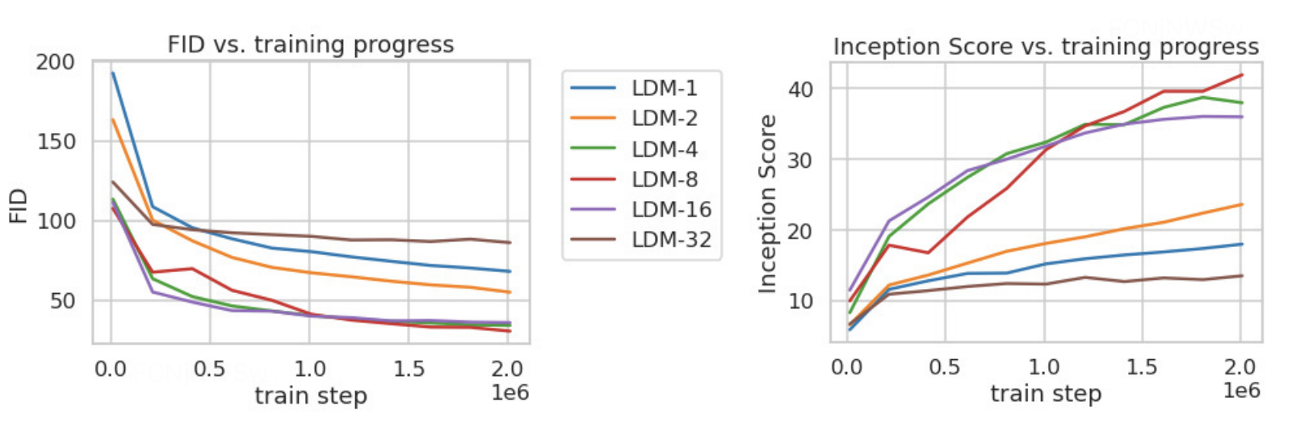

3.5 潜在扩散模型
扩散模型可以解释为一个时序去噪自编码器ϵ_θ (x_t,t),其目标是根据输入x_t和t,取预测噪声。相应的目标函数可以写成如下形式:

其中 t 从 {1,…,T} 中均匀采样获得。
而在潜在扩散模型中,引入了预训练的感知压缩模型,它包括一个编码器ε和一个解码器D。这样在训练时就可以利用编码器得到z_t,从而让模型在潜在表示空间中学习,相应的目标函数可以写成如下形式:
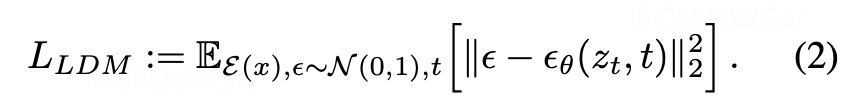
在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet。但是有一个重要的地方是论文为diffusion操作引入了Conditioning Mechanisms,通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
3.6 交叉注意力
本文在扩散过程中引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务得以实现。具体做法是通过训练一个条件时序去噪自编码器ϵ_θ (z_t,t,y),来通过 y来控制图片合成的过程。
为了能够从多个不同的模态预处理 y ,论文引入了一个领域专用编码器τ_θ,它用来将 y 映射为一个中间表示τ_θ (y) ,这样我们就可以很方便的引入各种形态的条件(文本、类别等等)。最终模型就可以通过一个cross-attention层映射将控制信息融入到UNet的中间层,cross-attention层的实现如下:

3.7 实现效果
无条件图像生成:
-
论文从FID和Precision-and-Recall两方面对比LDM的样本生成能力,实验数据集为CelebA-HQ、FFHQ和LSUN-Churches/Bedrooms;其效果超过了GANs和LSGM,并且超过同为扩散模型的DDPM。

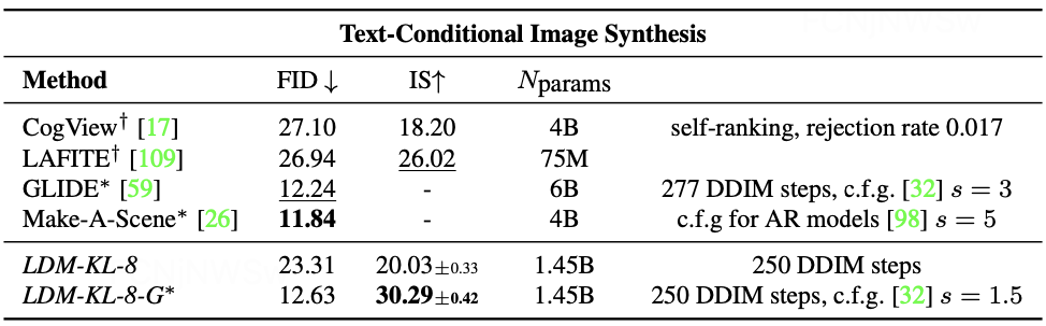
有条件图像生成:
-
采用FID和IS作为衡量图像质量指标,LDM-KL-8-G*在FID和IS两项指标上均获得不错的结果;且在FID相同的情况下,网络参数量显著下降。
4、Stable Diffusion
4.1 概要
Stable diffusion是一种潜在的文本到图像的扩散模型。基于之前的大量工作(如DDPM、LDM的提出),并且在Stability AI的算力支持和LAION的海量数据支持下,Stable diffusion才得以成功。
Stable diffusion在来自LAION- 5B数据库子集的512x512图像上训练潜在扩散模型。与谷歌的Imagen类似,这个模型使用一个冻结的CLIP vitl /14文本编码器来根据文本提示调整模型。
Stable diffusion拥有860M的UNet和123M的文本编码器,该模型相对轻量级,可以运行在具有至少10GB VRAM的GPU上。
4.2 主要改进点
Stable diffusion是在LDM的基础上建立的,同时在LDM的基础上进行了一些改进:
-
数据集:在更大的数据集LAION- 5B上进行训练
-
条件机制:使用更强大的CLIP模型,代替原始的交叉注意力调节机制
除此之外,随着各种图形界面的出现、 微调方法的发布、控制模型的公开,SD进入全新架构SDXL时代,功能更加强大。
4.3 模型训练
SD的训练是采用了32台8卡的A100机器(32 x 8 x A100_40GB GPUs),单卡的训练batch size为2,并采用gradient accumulation,其中gradient accumulation steps=2,那么训练的总batch size就是32x8x2x2=2048。训练优化器采用AdamW,训练采用warmup,在初始10,000步后学习速率升到0.0001,后面保持不变。至于训练时间约150,000小时(A100卡时),如果按照256卡A100来算的话,那么大约需要训练25天左右。
SD提供了不同版本的模型权重可供选择:
-
SD v1.1:在laion2B-en数据集上以256x256大小训练237,000步,上面我们已经说了,laion2B-en数据集中256以上的样本量共1324M;然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024x1024以上,共170M样本。
-
SD v1.2:以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512x512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512x512以下的样本。
-
SD v1.3:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512x512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
-
SD v1.4:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练225,000步数。
-
SD v1.5:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练595,000步数。
其实可以看到SD v1.3、SD v1.4和SD v1.5其实是以SD v1.2为起点在improved_aesthetics_5plus数据集上采用CFG训练过程中的不同checkpoints,目前最常用的版本是SD v1.4和SD v1.5。
4.4 条件控制
-
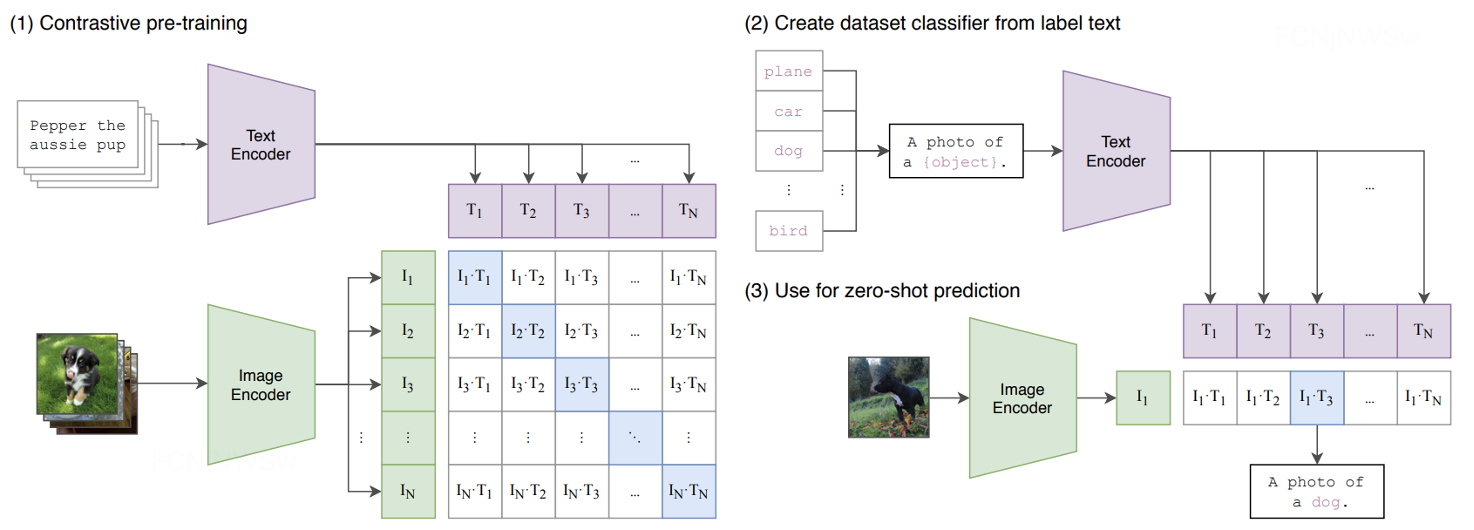
SD采用CLIP text encoder来对输入text提取text embeddings,具体的是采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。
-
值得注意的是,这里的tokenizer最大长度为77(CLIP训练时所采用的设置),当输入text的tokens数量超过77后,将进行截断,如果不足则进行paddings,这样将保证无论输入任何长度的文本(甚至是空文本)都得到77x768大小的特征。 在训练SD的过程中,CLIP text encoder模型是冻结的。在早期的工作中,比如OpenAI的GLIDE和latent diffusion中的LDM均采用一个随机初始化的tranformer模型来提取text的特征,但是最新的工作都是采用预训练好的text model。比如谷歌的Imagen采用纯文本模型T5 encoder来提出文本特征,而SD则采用CLIP text encoder,预训练好的模型往往已经在大规模数据集上进行了训练,它们要比直接采用一个从零训练好的模型要好。
-
下面是SD中使用的条件控制模型CLIP的结构示意图
4.5 与其他模型对比
DALL-E2 :出自OpenAI,其基本原理和SD一样,都是源于最初的扩散概率模型(DDPM),与之不同发是,SD继承了LDM的思想,在潜在空间中进行扩散学习;而DALL-E2是在像素空间中进行扩散学习,所以其计算复杂度较高。
Imagen:由谷歌发布,采用预训练好的文本编码器T5,通过扩散模型,实现文本到低分辨率图像的生成,最后将低分辨率图像进行两次超分,得到高分辨率图像。
5、Conference
- 【扩散模型之LDM】Latent Diffusion Models 论文解读_ldm的损失函数-CSDN博客
- 【扩撒模型之DDPM】Denoising Diffusion Probabilistic Models论文解读
- 最强文生图跨模态大模型:Stable Diffusion_文生图数据集形式-CSDN博客
-
Denoising Diffusion Probabilistic Models
-
High-Resolution Image Synthesis with Latent Diffusion Models
-
https://huggingface.co/CompVis/stable-diffusion
-
GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
-
GitHub - hojonathanho/diffusion: Denoising Diffusion Probabilistic Models
-
DDPM - 搜索结果 - 知乎
-
Latent Diffusion Model - 搜索结果 - 知乎
)









)





)
国际数字物流技术与应用展览会将于7月8日举办)

![[leetcode] 哈希表](http://pic.xiahunao.cn/[leetcode] 哈希表)