ChatGPT、Claude.ai等大模型产品就像“图书馆”一样为我们生成各种各样的内容。但是想更新这个图书馆里的知识却不太方便,经常需要漫长、费时的预训练、蒸馏才能完成。
研究人员提出了一种具有情景记忆控制的大语言模型Larimar,这是一种类似人脑"海马体"的"情景记忆"能力。
Larimar主要设计了一个外部记忆模块,专门储存独立的实时数据,并将这些记忆有效地注入到大语言模型中,使得Larimar无需重新预训练就能在内容生成过程中精准使用新的知识数据。
论文地址:https://arxiv.org/abs/2403.11901

Larimar核心方法
研究人员主要受到了人脑“海马体”神经结构的启发。海马体在人类的多种认知过程中扮演着关键角色,尤其是在记忆形成、组织和检索,以及空间导航方面。
海马体对短期记忆转化为长期记忆至关重要,特别是在形成新的记忆和学习新信息的过程中,帮助将经验和信息从短期记忆库存转移到大脑的其他部分以形成长期记忆。
Larimar采用了互补学习系统理论的观点,其中海马体快速学习系统将样本记录为情景记忆,而新皮层慢速学习系统学习输入分布的摘要统计信息作为语义记忆。
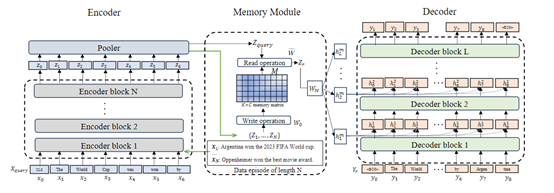
Larimar的目标是将情景记忆模块作为当前一组事实更新或编辑的全局存储,并将这个记忆作为大语言模型解码器的条件。为了高效且准确地更新这个记忆,研究人员利用了类似于Kanerva Machine的分层记忆结构,其中内存的写入和读取被解释为生成模型中的推理。
此外,这种灵活的模块化设计也使得Larimar具备遗忘数据、防泄密等多种特殊记忆控制功能。
Larimar多个核心模块
1)大语言模型编码器:Larimar使用了BERT模型作为基础编码器,其作用是将输入文本映射到潜在语义空间,得到对应的向量表示数据,并作为外部"情景记忆"模块的写入内容。
2)外部情景记忆模块:Larimar的核心模块,设计了一个固定大小(如512x768)的存储矩阵,用于存放编码器输出的潜在向量表示。该记忆模块借鉴了Kanerva的分层记忆架构思路。当有新的知识数据输入到Larimar时,就会被写入到情景记忆模块中,并且需要输出时会进行随机抽取。

3)大语言模型解码器:解码器模块的作用是将情景记忆模块读取的向量进一步解码,生成最终的文本输出,Larimar使用了GPT系列模型作为解码器。解码器通过自注意力机制将记忆模块中的数据与其他信息整合对输出施加影响,使得生成的文本包含了新的数据知识。

4)记忆范围检测器:有时候我们期望生成的输出不受新知识数据影响,执行原本的数据内容生成,就可以通过记忆范围检测器来实现。
这是一个小型序列二分类模型,根据输入判断是否需要利用记忆模块进行条件生成。如果检测器输出"无需记忆",则直接执行无条件解码;反之则会利用新知识数据进行生成。
研究人员表示,Larimar是一种创新技术架构,可以有效解决大语言模型数据更新不及时、消除数据中存在的非法、偏见、错误等数据,同时可以很好保护那些敏感的数据防止外漏。





之React探索)




)
)


)




