前言
基于PaddleNLP的深度学习对文本自动添加标点符号的源码版来了,本篇文章主要讲解如何文本自动添加标点符号的原理和相关训练方法,前一篇文章讲解的是使用paddlepaddle已经训练好的一些模型,在一些简单场景下可以通过这些模型进行预测,但是在复杂场景下,就必须通自行训练。
环境准备
1、建议使用PyCharm进行开发,社区版即可Download PyCharm: Python IDE for Professional Developers by JetBrains
2、获取项目源码并导入到PyCharm中,结构如下
预处理和相关原理讲解
1、数据准备
准备一份数据集,这个数据集质量可能不是很好,中英文标点符号混合了,同时也有很多不合理的文本,例如网页的HTML代码,我们可以简单做一个处理,把英文的标点符号,.?替换成中文的,。?,如果想要更好的数据,可以进一步清理数据,或者自定义数据集。如下:
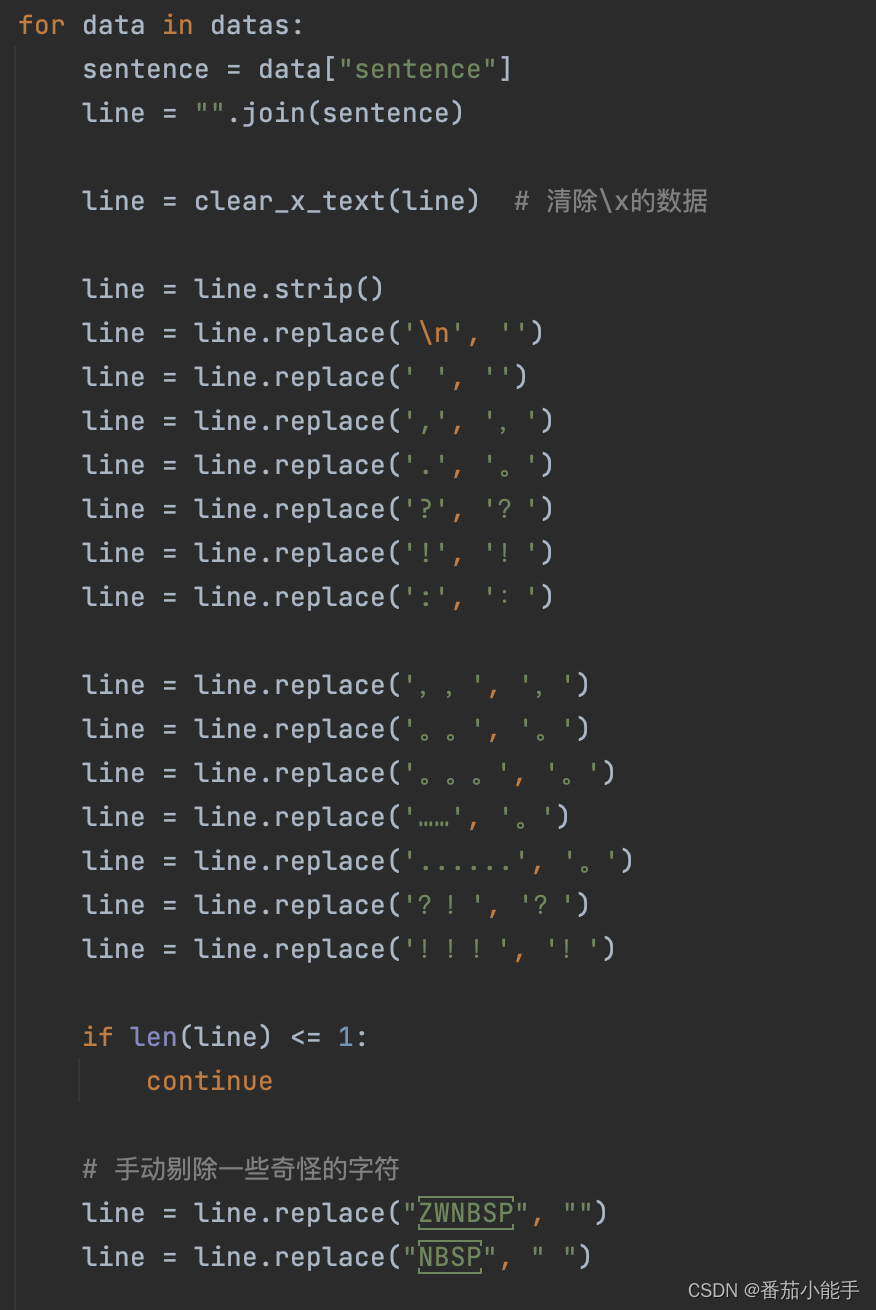
如果存在一些别的特殊字符,也可以手动添加过滤掉。
当然我们自定义的数据中还存在一些不在预训练模型的vocab.txt中字符,我们也可以过滤掉,当然也可能动态添加到vocab.txt中,用来扩充我们的字符集。
这里说明一点:本源码新增两大特色
- 1、支持扩充字符,这个在源码中有体现
- 支持空格字符,训练集中存不存空号都可以,但必须保证没有两个连续的空格
2、原理说明
参考命名实体识别的BIO模式,由于我们标签都是单字,所以采用BO模式,我们可以把数据集处理成如下:
标签文件: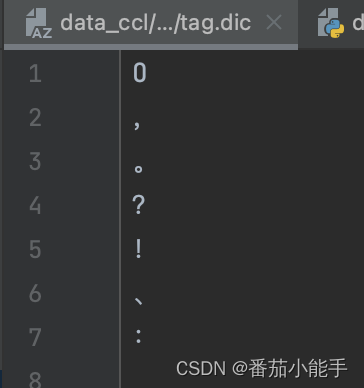
其中符号转换为:
{”O“:0,",-B":1,"。-B":2,"?-B":3,"!-B":4,...
}遍历我们的数据集,将所有的文字标签化:
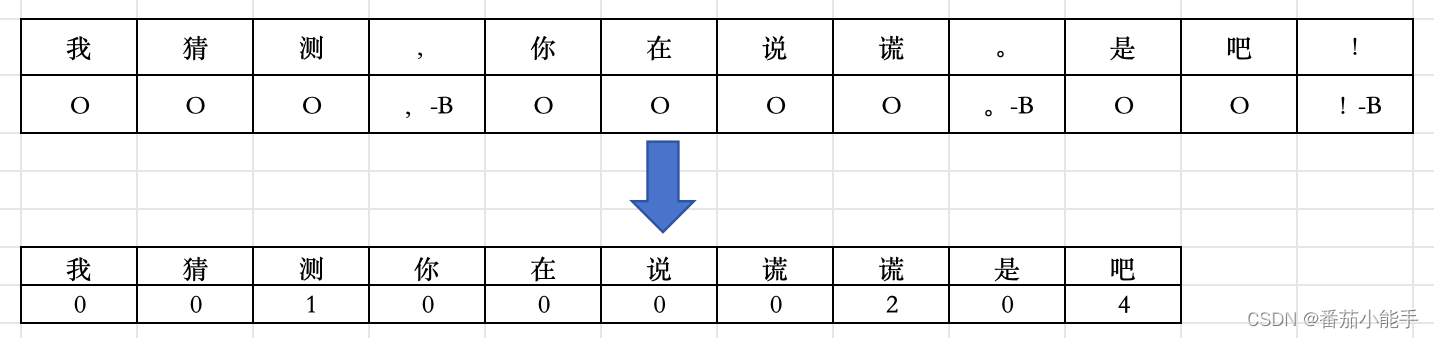
这样处理有个问题,需要首个字符不能为标签中的标点符号。
训练
处理好数据集后,就可以开始进行训练
1、开始训练
其中--add_vocab参数,为新增的字符,训练过程中会将新增的字符加入到库中,导出的模型会自动携带新增的字符
export save_dir=./ernie_ckpt/output/
export data_dir=./data/data/
export pretrained_model=./ernie_ckpt/output/best_model/model_state.pdparams
export add_vocab=./data/vocab_other.txtexport model_name="ernie-3.0-medium-zh"
# ,1,2,3,4,5,6,7
python3 -u -m paddle.distributed.launch --gpus "0,1,2,3,4,5,6,7" run_ernie.py \--device gpu \--model_name $model_name \--pretrained_model $pretrained_model \--save_dir $save_dir \--epochs 300 \--save_epoch 10 \--batch_size 4 \--data_dir $data_dir \--add_vocab $add_vocab
[2022-09-14 17:17:34,309] [ INFO] - Already cached .ppnlp_home/models/ernie-3.0-medium-zh/ernie_3.0_medium_zh.pdparams
W0914 17:17:34.310540 10320 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0914 17:17:34.313140 10320 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-09-14 17:17:37.758967 INFO ] train:train:90 - Train epoch: [1/20], batch: [0/1283], loss: 2.05675, f1_score: 0.02082, learning rate: 0.00001000, eta: 2:18:40
[2023-09-14 17:17:54.295418 INFO ] train:train:90 - Train epoch: [1/20], batch: [100/1283], loss: 0.12979, f1_score: 0.33040, learning rate: 0.00000990, eta: 1:11:06
[2023-09-14 17:18:10.936073 INFO ] train:train:90 - Train epoch: [1/20], batch: [200/1283], loss: 0.13771, f1_score: 0.37442, learning rate: 0.00000980, eta: 1:10:43
[2023-09-14 17:18:27.706051 INFO ] train:train:90 - Train epoch: [1/20], batch: [300/1283], loss: 0.10602, f1_score: 0.47096, learning rate: 0.00000970, eta: 1:10:35
[2023-09-14 17:18:44.545404 INFO ] train:train:90 - Train epoch: [1/20], batch: [400/1283], loss: 0.12836, f1_score: 0.55652, learning rate: 0.00000961, eta: 1:10:27
[2022-09-14 17:19:01.434206 INFO ] train:train:90 - Train epoch: [1/20], batch: [500/1283], loss: 0.11024, f1_score: 0.51312, learning rate: 0.00000951, eta: 1:10:182、导出模型
python3 export_ernie_model.py --model_name ernie-3.0-medium-zh --params_path ./ernie_ckpt/output/best_model/model_state.pdparams --data_dir ./data/data/ --output_path ./inference/
3、预测
import osos.environ["PPNLP_HOME"] = "ppnlp_home"
from deploy.python.predict_ernie import ModelPredictcurrent_path = os.path.dirname(os.path.abspath(__file__))def get_ner_result(model_dir, query_list):modelPredict = ModelPredict(model_dir=model_dir,model_name="ernie-3.0-medium-zh",device="gpu",batch_size=16)results = modelPredict(query_list)print("get predict num={}".format(len(results)))return resultsif __name__ == "__main__":model_dir = "inference/"datalist = ["耶律虎古字海邻六院夷离菫觌烈之孙少颖悟重然诺"]results = get_ner_result(model_dir, datalist)for result in results:print("输出:", str(result))小结
到这一步,标点符号预测到这一步就完成了,总体上讲效果还可以,如果需要更好的效果,可以更换更深更大的神经网络。
源码下载地址:基于PaddleNLP的深度学习对文本自动添加标点符号源码



















