
1、写作动机:
大语言模型有时会显示不一致性和问题行为,例如产生幻觉事实、生成有缺陷的代码或创建令人反感和有毒的内容。与这些模型不同,人类通常利用外部工具来交叉检查和改进他们的初始内容,比如使用搜索引擎进行事实检查,或者使用代码解释器进行调试。作者受到了这一观察的启发写了这一文章。
2、主要贡献:
(1)提出了统一的CRITIC框架,通过集成各种工具和不同任务,并提供一系列新提示,使冻结的LLMs能够通过与外部工具的交互验证和迭代自我修正其输出。
(2)在不同的基础LLMs上进行了跨任务的全面实验,展示了CRITIC所提供的显著性能改进。
(3)强调LLMs在自我验证和自我修正方面的不足,并强调外部工具交互的反馈对LLMs的一致自我改进至关重要。
3、方法:



4、实验:
4.1QA方面:
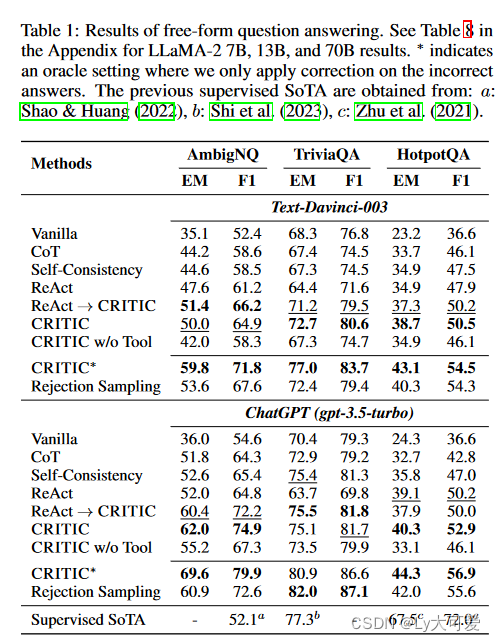
4.2数学程序方面:
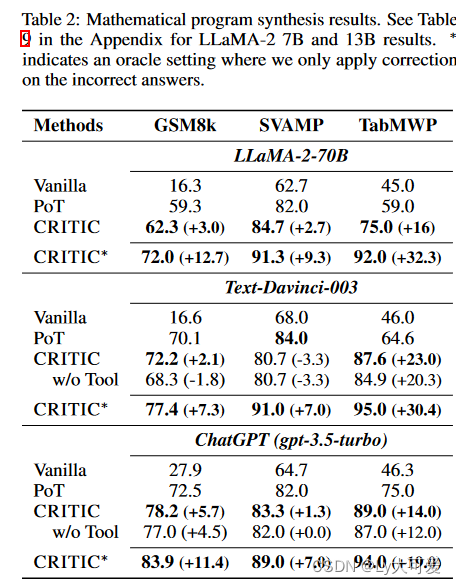
4.3毒性减少方面:
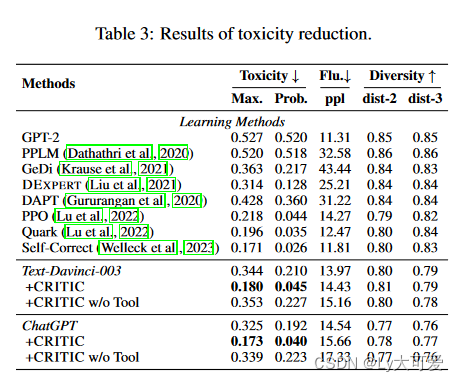



开发平台前端安全配置建议(一))
)


)


)
)







