第九章. 装饰器和闭包
有人对将这个功能命名为“装饰器”的选择提出了一些抱怨。主要的抱怨是该名称与其在 GoF 书中的用法不一致。¹ 名称 decorator 可能更多地归因于其在编译器领域的用法—语法树被遍历并注释。
PEP 318—函数和方法的装饰器
函数装饰器让我们在源代码中“标记”函数以增强其行为。这是强大的东西,但要掌握它需要理解闭包—当函数捕获在其体外定义的变量时,我们就得到了闭包。
Python 中最晦涩的保留关键字是 nonlocal,引入于 Python 3.0。如果你遵循严格的以类为中心的面向对象编程规范,作为 Python 程序员可以过上富有成效的生活而永远不使用它。然而,如果你想要实现自己的函数装饰器,你必须理解闭包,然后 nonlocal 的必要性就显而易见了。
除了在装饰器中的应用外,闭包在使用回调函数的任何类型编程和在适当时以函数式风格编码时也是必不可少的。
本章的最终目标是准确解释函数装饰器的工作原理,从最简单的注册装饰器到更复杂的带参数装饰器。然而,在达到这个目标之前,我们需要涵盖:
-
Python 如何评估装饰器语法
-
Python 如何确定变量是局部的
-
闭包的存在及工作原理
-
nonlocal解决了什么问题
有了这个基础,我们可以进一步探讨装饰器的主题:
-
实现一个行为良好的装饰器
-
标准库中强大的装饰器:
@cache、@lru_cache和@singledispatch -
实现一个带参数的装饰器
本章新内容
Python 3.9 中新增的缓存装饰器 functools.cache 比传统的 functools.lru_cache 更简单,因此我首先介绍它。后者在“使用 lru_cache”中有介绍,包括 Python 3.8 中新增的简化形式。
“单分派泛型函数”进行了扩展,现在使用类型提示,这是自 Python 3.7 以来使用 functools.singledispatch 的首选方式。
“带参数的装饰器”现在包括一个基于类的示例,示例 9-27。
我将第十章,“具有头等函数的设计模式”移到了第 II 部分的末尾,以改善书籍的流畅性。“装饰器增强策略模式”现在在该章节中,以及使用可调用对象的策略设计模式的其他变体。
我们从一个非常温和的装饰器介绍开始,然后继续进行章节开头列出的其余项目。
装饰器 101
装饰器是一个可调用对象,接受另一个函数作为参数(被装饰的函数)。
装饰器可能对被装饰的函数进行一些处理,并返回它或用另一个函数或可调用对象替换它。²
换句话说,假设存在一个名为 decorate 的装饰器,这段代码:
@decorate
def target():print('running target()')
与编写以下内容具有相同的效果:
def target():print('running target()')target = decorate(target)
最终结果是一样的:在这两个片段的末尾,target 名称绑定到 decorate(target) 返回的任何函数上—这可能是最初命名为 target 的函数,也可能是另一个函数。
要确认被装饰的函数是否被替换,请查看示例 9-1 中的控制台会话。
示例 9-1. 装饰器通常会用不同的函数替换一个函数
>>> def deco(func):
... def inner():
... print('running inner()')
... return inner # ①
...
>>> @deco
... def target(): # ②
... print('running target()')
...
>>> target() # ③
running inner() >>> target # ④
<function deco.<locals>.inner at 0x10063b598>
①
deco 返回其 inner 函数对象。
②
target 被 deco 装饰。
③
调用被装饰的 target 实际上运行 inner。
④
检查发现 target 现在是对 inner 的引用。
严格来说,装饰器只是一种语法糖。正如我们刚才看到的,你总是可以像调用任何常规可调用对象一样简单地调用装饰器,传递另一个函数。有时这实际上很方便,特别是在进行 元编程 时——在运行时更改程序行为。
三个关键事实概括了装饰器的要点:
-
装饰器是一个函数或另一个可调用对象。
-
装饰器可能会用不同的函数替换被装饰的函数。
-
装饰器在模块加载时立即执行。
现在让我们专注于第三点。
Python 执行装饰器时
装饰器的一个关键特点是它们在被装饰的函数定义后立即运行。通常是在 导入时间(即 Python 加载模块时)运行。考虑 示例 9-2 中的 registration.py。
示例 9-2. registration.py 模块
registry = [] # ①def register(func): # ②print(f'running register({func})') # ③registry.append(func) # ④return func # ⑤@register # ⑥
def f1():print('running f1()')@register
def f2():print('running f2()')def f3(): # ⑦print('running f3()')def main(): # ⑧print('running main()')print('registry ->', registry)f1()f2()f3()if __name__ == '__main__':main() # ⑨
①
registry 将保存被 @register 装饰的函数的引用。
②
register 接受一个函数作为参数。
③
显示正在被装饰的函数,以供演示。
④
在 registry 中包含 func。
⑤
返回 func:我们必须返回一个函数;在这里我们返回接收到的相同函数。
⑥
f1 和 f2 被 @register 装饰。
⑦
f3 没有被装饰。
⑧
main 显示 registry,然后调用 f1()、f2() 和 f3()。
⑨
只有当 registration.py 作为脚本运行时才会调用 main()。
将 registration.py 作为脚本运行的输出如下:
$ python3 registration.py
running register(<function f1 at 0x100631bf8>)
running register(<function f2 at 0x100631c80>)
running main()
registry -> [<function f1 at 0x100631bf8>, <function f2 at 0x100631c80>]
running f1()
running f2()
running f3()
注意,register 在任何模块中的其他函数之前运行(两次)。当调用 register 时,它接收被装饰的函数对象作为参数,例如 <function f1 at 0x100631bf8>。
模块加载后,registry 列表保存了两个被装饰函数 f1 和 f2 的引用。这些函数以及 f3 只有在被 main 显式调用时才会执行。
如果 registration.py 被导入(而不是作为脚本运行),输出如下:
>>> import registration
running register(<function f1 at 0x10063b1e0>)
running register(<function f2 at 0x10063b268>)
此时,如果检查 registry,你会看到:
>>> registration.registry
[<function f1 at 0x10063b1e0>, <function f2 at 0x10063b268>]
示例 9-2 的主要观点是强调函数装饰器在模块导入时立即执行,但被装饰的函数只有在显式调用时才运行。这突出了 Python 程序员所称的 导入时间 和 运行时 之间的区别。
注册装饰器
考虑到装饰器在实际代码中通常的应用方式,示例 9-2 在两个方面都有些不同寻常:
-
装饰器函数在与被装饰函数相同的模块中定义。真正的装饰器通常在一个模块中定义,并应用于其他模块中的函数。
-
register装饰器返回与传入的相同函数。实际上,大多数装饰器定义一个内部函数并返回它。
即使 示例 9-2 中的 register 装饰器返回未更改的装饰函数,这种技术也不是无用的。许多 Python 框架中使用类似的装饰器将函数添加到某个中央注册表中,例如将 URL 模式映射到生成 HTTP 响应的函数的注册表。这些注册装饰器可能会或可能不会更改被装饰的函数。
我们将在 “装饰器增强的策略模式”(第十章)中看到一个注册装饰器的应用。
大多数装饰器确实会改变被装饰的函数。它们通常通过定义内部函数并返回它来替换被装饰的函数来实现。几乎总是依赖闭包才能正确运行使用内部函数的代码。要理解闭包,我们需要退一步,回顾一下 Python 中变量作用域的工作原理。
变量作用域规则
在示例 9-3 中,我们定义并测试了一个函数,该函数读取两个变量:一个局部变量a—定义为函数参数—和一个在函数中任何地方都未定义的变量b。
示例 9-3. 读取局部变量和全局变量的函数
>>> def f1(a):
... print(a)
... print(b)
...
>>> f1(3)
3
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<stdin>", line 3, in f1
NameError: global name 'b' is not defined
我们得到的错误并不令人惊讶。继续从示例 9-3 中,如果我们为全局b赋值然后调用f1,它可以工作:
>>> b = 6
>>> f1(3)
3
6
现在,让我们看一个可能会让你惊讶的例子。
查看示例 9-4 中的f2函数。它的前两行与示例 9-3 中的f1相同,然后对b进行赋值。但在赋值之前的第二个print失败了。
示例 9-4. 变量b是局部的,因为它在函数体中被赋值
>>> b = 6
>>> def f2(a):
... print(a)
... print(b)
... b = 9
...
>>> f2(3)
3
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<stdin>", line 3, in f2
UnboundLocalError: local variable 'b' referenced before assignment
请注意,输出以3开头,这证明了print(a)语句已执行。但第二个print(b)从未运行。当我第一次看到这个时,我感到惊讶,认为应该打印6,因为有一个全局变量b,并且在print(b)之后对局部b进行了赋值。
但事实是,当 Python 编译函数体时,它决定将b视为局部变量,因为它是在函数内部赋值的。生成的字节码反映了这个决定,并将尝试从局部作用域获取b。稍后,当调用f2(3)时,f2的函数体获取并打印局部变量a的值,但在尝试获取局部变量b的值时,它发现b是未绑定的。
这不是一个错误,而是一个设计选择:Python 不要求您声明变量,但假设在函数体中分配的变量是局部的。这比 JavaScript 的行为要好得多,后者也不需要变量声明,但如果您忘记声明变量是局部的(使用var),您可能会在不知情的情况下覆盖全局变量。
如果我们希望解释器将b视为全局变量,并且仍然在函数内部为其赋新值,我们使用global声明:
>>> b = 6
>>> def f3(a):
... global b
... print(a)
... print(b)
... b = 9
...
>>> f3(3)
3
6
>>> b
9
在前面的示例中,我们可以看到两个作用域的运作:
模块全局作用域
由分配给任何类或函数块之外的值的名称组成。
f3 函数的局部作用域
由分配给参数的值或直接在函数体中分配的名称组成。
另一个变量可能来自的作用域是非局部,对于闭包是至关重要的;我们稍后会看到它。
在更深入地了解 Python 中变量作用域工作原理之后,我们可以在下一节“闭包”中讨论闭包。如果您对示例 9-3 和 9-4 中的函数之间的字节码差异感兴趣,请参阅以下侧边栏。
闭包
在博客圈中,有时会混淆闭包和匿名函数。许多人会因为这两个特性的平行历史而混淆它们:在函数内部定义函数并不那么常见或方便,直到有了匿名函数。而只有在有嵌套函数时闭包才重要。因此,很多人会同时学习这两个概念。
实际上,闭包是一个函数—我们称之为f—具有扩展作用域,包含在f的函数体中引用的不是全局变量或f的局部变量的变量。这些变量必须来自包含f的外部函数的局部作用域。
函数是匿名的与否并不重要;重要的是它可以访问在其函数体之外定义的非全局变量。
这是一个难以理解的概念,最好通过一个例子来解释。
考虑一个avg函数来计算不断增长的数值序列的平均值;例如,商品的整个历史上的平均收盘价。每天都会添加一个新的价格,并且平均值是根据到目前为止的所有价格计算的。
从一张干净的画布开始,这就是如何使用avg:
>>> avg(10)
10.0
>>> avg(11)
10.5
>>> avg(12)
11.0
avg是从哪里来的,它在哪里保留了先前值的历史记录?
起步时,示例 9-7 是基于类的实现。
示例 9-7. average_oo.py:用于计算移动平均值的类
class Averager():def __init__(self):self.series = []def __call__(self, new_value):self.series.append(new_value)total = sum(self.series)return total / len(self.series)
Averager类创建可调用的实例:
>>> avg = Averager()
>>> avg(10)
10.0
>>> avg(11)
10.5
>>> avg(12)
11.0
现在,示例 9-8 是一个功能实现,使用高阶函数make_averager。
示例 9-8. average.py:用于计算移动平均值的高阶函数
def make_averager():series = []def averager(new_value):series.append(new_value)total = sum(series)return total / len(series)return averager
当调用时,make_averager返回一个averager函数对象。每次调用averager时,它都会将传递的参数附加到序列中,并计算当前平均值,如示例 9-9 所示。
示例 9-9. 测试示例 9-8
>>> avg = make_averager()
>>> avg(10)
10.0
>>> avg(11)
10.5
>>> avg(15)
12.0
注意示例的相似之处:我们调用Averager()或make_averager()来获取一个可调用对象avg,它将更新历史序列并计算当前平均值。在示例 9-7 中,avg是Averager的一个实例,在示例 9-8 中,它是内部函数averager。无论哪种方式,我们只需调用avg(n)来将n包含在序列中并获得更新后的平均值。
很明显,Averager类的avg保留历史记录的地方:self.series实例属性。但第二个示例中的avg函数从哪里找到series呢?
请注意,series是make_averager的局部变量,因为赋值series = []发生在该函数的主体中。但当调用avg(10)时,make_averager已经返回,并且它的局部作用域早已消失。
在averager中,series是一个自由变量。这是一个技术术语,意味着一个在局部作用域中未绑定的变量。参见图 9-1。
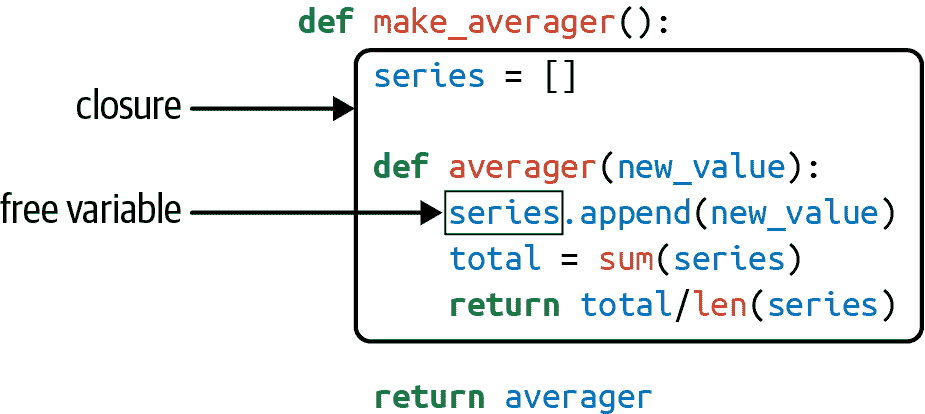
图 9-1. averager的闭包将该函数的作用域扩展到包括自由变量series的绑定。
检查返回的averager对象显示了 Python 如何在__code__属性中保存局部和自由变量的名称,该属性表示函数的编译体。示例 9-10 展示了这些属性。
示例 9-10. 检查由示例 9-8 创建的函数
>>> avg.__code__.co_varnames
('new_value', 'total')
>>> avg.__code__.co_freevars
('series',)
series的值保存在返回的函数avg的__closure__属性中。avg.__closure__中的每个项目对应于avg.__code__.co_freevars中的一个名称。这些项目是cells,它们有一个名为cell_contents的属性,其中可以找到实际值。示例 9-11 展示了这些属性。
示例 9-11. 从示例 9-9 继续
>>> avg.__code__.co_freevars
('series',)
>>> avg.__closure__
(<cell at 0x107a44f78: list object at 0x107a91a48>,)
>>> avg.__closure__[0].cell_contents
[10, 11, 12]
总结一下:闭包是一个函数,保留在函数定义时存在的自由变量的绑定,以便在函数被调用时使用,而定义作用域不再可用时可以使用它们。
请注意,函数可能需要处理非全局外部变量的唯一情况是当它嵌套在另一个函数中并且这些变量是外部函数的局部作用域的一部分时。
非局部声明
我们先前的make_averager实现效率不高。在示例 9-8 中,我们将所有值存储在历史序列中,并且每次调用averager时都计算它们的sum。更好的实现方式是只存储总和和到目前为止的项目数,并从这两个数字计算平均值。
示例 9-12 是一个有问题的实现,只是为了说明一个观点。你能看出它在哪里出错了吗?
示例 9-12. 一个破损的高阶函数,用于计算不保留所有历史记录的运行平均值
def make_averager():count = 0total = 0def averager(new_value):count += 1total += new_valuereturn total / countreturn averager
如果尝试 示例 9-12,你会得到以下结果:
>>> avg = make_averager()
>>> avg(10)
Traceback (most recent call last):...
UnboundLocalError: local variable 'count' referenced before assignment
>>>
问题在于语句 count += 1 实际上意味着与 count = count + 1 相同,当 count 是一个数字或任何不可变类型时。因此,我们实际上是在 averager 的主体中对 count 赋值,这使其成为一个局部变量。同样的问题也影响到 total 变量。
我们在 示例 9-8 中没有这个问题,因为我们从未给 series 赋值;我们只调用了 series.append 并在其上调用了 sum 和 len。所以我们利用了列表是可变的这一事实。
但对于像数字、字符串、元组等不可变类型,你只能读取,而不能更新。如果尝试重新绑定它们,比如 count = count + 1,那么实际上是隐式创建了一个局部变量 count。它不再是一个自由变量,因此不会保存在闭包中。
为了解决这个问题,Python 3 中引入了 nonlocal 关键字。它允许你将一个变量声明为自由变量,即使它在函数内部被赋值。如果向 nonlocal 变量赋予新值,闭包中存储的绑定将会改变。我们最新的 make_averager 的正确实现看起来像 示例 9-13。
示例 9-13. 计算不保留所有历史记录的运行平均值(使用 nonlocal 修复)
def make_averager():count = 0total = 0def averager(new_value):nonlocal count, totalcount += 1total += new_valuereturn total / countreturn averager
在学习了 nonlocal 的使用之后,让我们总结一下 Python 的变量查找工作原理。
变量查找逻辑
当定义一个函数时,Python 字节码编译器根据以下规则确定如何获取其中出现的变量 x:³
-
如果有
global x声明,x来自并被赋值给模块的x全局变量。⁴ -
如果有
nonlocal x声明,x来自并被赋值给最近的周围函数的x局部变量,其中x被定义。 -
如果
x是参数或在函数体中被赋值,则x是局部变量。 -
如果引用了
x但未被赋值且不是参数:-
x将在周围函数体的本地作用域(非本地作用域)中查找。 -
如果在周围作用域中找不到,将从模块全局作用域中读取。
-
如果在全局作用域中找不到,将从
__builtins__.__dict__中读取。
-
现在我们已经介绍了 Python 闭包,我们可以有效地使用嵌套函数实现装饰器。
实现一个简单的装饰器
示例 9-14 是一个装饰器,用于记录装饰函数的每次调用并显示经过的时间、传递的参数以及调用的结果。
示例 9-14. clockdeco0.py: 显示函数运行时间的简单装饰器
import timedef clock(func):def clocked(*args): # ①t0 = time.perf_counter()result = func(*args) # ②elapsed = time.perf_counter() - t0name = func.__name__arg_str = ', '.join(repr(arg) for arg in args)print(f'[{elapsed:0.8f}s] {name}({arg_str}) -> {result!r}')return resultreturn clocked # ③
①
定义内部函数 clocked 来接受任意数量的位置参数。
②
这行代码之所以有效,是因为 clocked 的闭包包含了 func 自由变量。
③
返回内部函数以替换装饰的函数。
示例 9-15 演示了 clock 装饰器的使用。
示例 9-15. 使用 clock 装饰器
import time
from clockdeco0 import clock@clock
def snooze(seconds):time.sleep(seconds)@clock
def factorial(n):return 1 if n < 2 else n*factorial(n-1)if __name__ == '__main__':print('*' * 40, 'Calling snooze(.123)')snooze(.123)print('*' * 40, 'Calling factorial(6)')print('6! =', factorial(6))
运行 示例 9-15 的输出如下所示:
$ python3 clockdeco_demo.py
**************************************** Calling snooze(.123)
[0.12363791s] snooze(0.123) -> None
**************************************** Calling factorial(6)
[0.00000095s] factorial(1) -> 1
[0.00002408s] factorial(2) -> 2
[0.00003934s] factorial(3) -> 6
[0.00005221s] factorial(4) -> 24
[0.00006390s] factorial(5) -> 120
[0.00008297s] factorial(6) -> 720
6! = 720
工作原理
记住这段代码:
@clock
def factorial(n):return 1 if n < 2 else n*factorial(n-1)
实际上是这样的:
def factorial(n):return 1 if n < 2 else n*factorial(n-1)factorial = clock(factorial)
因此,在这两个示例中,clock将factorial函数作为其func参数(参见示例 9-14)。然后创建并返回clocked函数,Python 解释器将其分配给factorial(在第一个示例中,在幕后)。实际上,如果导入clockdeco_demo模块并检查factorial的__name__,您会得到以下结果:
>>> import clockdeco_demo
>>> clockdeco_demo.factorial.__name__
'clocked'
>>>
所以factorial现在实际上持有对clocked函数的引用。从现在开始,每次调用factorial(n),都会执行clocked(n)。实质上,clocked执行以下操作:
-
记录初始时间
t0。 -
调用原始
factorial函数,保存结果。 -
计算经过的时间。
-
格式化并显示收集的数据。
-
返回第 2 步保存的结果。
这是装饰器的典型行为:它用新函数替换装饰函数,新函数接受相同的参数并(通常)返回装饰函数应该返回的内容,同时还进行一些额外处理。
提示
在 Gamma 等人的设计模式中,装饰器模式的简短描述以“动态地为对象附加额外的责任”开始。函数装饰器符合这一描述。但在实现层面上,Python 装饰器与原始设计模式作品中描述的经典装饰器几乎没有相似之处。“讲台”有更多相关内容。
示例 9-14 中实现的clock装饰器存在一些缺陷:它不支持关键字参数,并且掩盖了装饰函数的__name__和__doc__。示例 9-16 使用functools.wraps装饰器从func复制相关属性到clocked。此外,在这个新版本中,关键字参数被正确处理。
示例 9-16. clockdeco.py:改进的时钟装饰器
import time
import functoolsdef clock(func):@functools.wraps(func)def clocked(*args, **kwargs):t0 = time.perf_counter()result = func(*args, **kwargs)elapsed = time.perf_counter() - t0name = func.__name__arg_lst = [repr(arg) for arg in args]arg_lst.extend(f'{k}={v!r}' for k, v in kwargs.items())arg_str = ', '.join(arg_lst)print(f'[{elapsed:0.8f}s] {name}({arg_str}) -> {result!r}')return resultreturn clocked
functools.wraps只是标准库中可用的装饰器之一。在下一节中,我们将介绍functools提供的最令人印象深刻的装饰器:cache。
标准库中的装饰器
Python 有三个内置函数专门用于装饰方法:property、classmethod和staticmethod。我们将在“使用属性进行属性验证”中讨论property,并在“classmethod 与 staticmethod”中讨论其他内容。
在示例 9-16 中,我们看到另一个重要的装饰器:functools.wraps,一个用于构建行为良好的装饰器的辅助工具。标准库中一些最有趣的装饰器是cache、lru_cache和singledispatch,它们都来自functools模块。我们将在下一节中介绍它们。
使用functools.cache进行记忆化
functools.cache装饰器实现了记忆化:⁵一种通过保存先前调用昂贵函数的结果来优化的技术,避免对先前使用的参数进行重复计算。
提示
functools.cache在 Python 3.9 中添加。如果需要在 Python 3.8 中运行这些示例,请将@cache替换为@lru_cache。对于 Python 的早期版本,您必须调用装饰器,写成@lru_cache(),如“使用 lru_cache”中所述。
一个很好的演示是将@cache应用于痛苦缓慢的递归函数,以生成斐波那契数列中的第n个数字,如示例 9-17 所示。
示例 9-17. 计算斐波那契数列中第 n 个数字的非常昂贵的递归方式
from clockdeco import clock@clock
def fibonacci(n):if n < 2:return nreturn fibonacci(n - 2) + fibonacci(n - 1)if __name__ == '__main__':print(fibonacci(6))
运行fibo_demo.py的结果如下。除了最后一行外,所有输出都是由clock装饰器生成的:
$ python3 fibo_demo.py
[0.00000042s] fibonacci(0) -> 0
[0.00000049s] fibonacci(1) -> 1
[0.00006115s] fibonacci(2) -> 1
[0.00000031s] fibonacci(1) -> 1
[0.00000035s] fibonacci(0) -> 0
[0.00000030s] fibonacci(1) -> 1
[0.00001084s] fibonacci(2) -> 1
[0.00002074s] fibonacci(3) -> 2
[0.00009189s] fibonacci(4) -> 3
[0.00000029s] fibonacci(1) -> 1
[0.00000027s] fibonacci(0) -> 0
[0.00000029s] fibonacci(1) -> 1
[0.00000959s] fibonacci(2) -> 1
[0.00001905s] fibonacci(3) -> 2
[0.00000026s] fibonacci(0) -> 0
[0.00000029s] fibonacci(1) -> 1
[0.00000997s] fibonacci(2) -> 1
[0.00000028s] fibonacci(1) -> 1
[0.00000030s] fibonacci(0) -> 0
[0.00000031s] fibonacci(1) -> 1
[0.00001019s] fibonacci(2) -> 1
[0.00001967s] fibonacci(3) -> 2
[0.00003876s] fibonacci(4) -> 3
[0.00006670s] fibonacci(5) -> 5
[0.00016852s] fibonacci(6) -> 8
8
浪费是显而易见的:fibonacci(1)被调用了八次,fibonacci(2)被调用了五次,等等。但只需添加两行代码来使用cache,性能就得到了很大改善。参见示例 9-18。
示例 9-18. 使用缓存实现更快的方法
import functoolsfrom clockdeco import clock@functools.cache # ①
@clock # ②
def fibonacci(n):if n < 2:return nreturn fibonacci(n - 2) + fibonacci(n - 1)if __name__ == '__main__':print(fibonacci(6))
①
这行代码适用于 Python 3.9 或更高版本。有关支持较早 Python 版本的替代方法,请参阅“使用 lru_cache”。
②
这是堆叠装饰器的一个示例:@cache应用于@clock返回的函数。
堆叠装饰器
要理解堆叠装饰器的意义,回想一下@是将装饰器函数应用于其下方的函数的语法糖。如果有多个装饰器,它们的行为类似于嵌套函数调用。这个:
@alpha
@beta
def my_fn():...
与此相同:
my_fn = alpha(beta(my_fn))
换句话说,首先应用beta装饰器,然后将其返回的函数传递给alpha。
在示例 9-18 中使用cache,fibonacci函数仅对每个n值调用一次:
$ python3 fibo_demo_lru.py
[0.00000043s] fibonacci(0) -> 0
[0.00000054s] fibonacci(1) -> 1
[0.00006179s] fibonacci(2) -> 1
[0.00000070s] fibonacci(3) -> 2
[0.00007366s] fibonacci(4) -> 3
[0.00000057s] fibonacci(5) -> 5
[0.00008479s] fibonacci(6) -> 8
8
在另一个测试中,计算fibonacci(30)时,示例 9-18 在 0.00017 秒内完成了所需的 31 次调用(总时间),而未缓存的示例 9-17 在 Intel Core i7 笔记本上花费了 12.09 秒,因为它调用了fibonacci(1)832,040 次,总共 2,692,537 次调用。
被装饰函数接受的所有参数必须是可散列的,因为底层的lru_cache使用dict来存储结果,键是由调用中使用的位置和关键字参数生成的。
除了使愚蠢的递归算法可行外,@cache在需要从远程 API 获取信息的应用程序中表现出色。
警告
如果缓存条目数量非常大,functools.cache可能会消耗所有可用内存。我认为它更适合用于短暂的命令本。在长时间运行的进程中,我建议使用适当的maxsize参数使用functools.lru_cache,如下一节所述。
使用 lru_cache
functools.cache装饰器实际上是围绕旧的functools.lru_cache函数的简单包装器,后者更灵活,与 Python 3.8 及更早版本兼容。
@lru_cache的主要优势在于其内存使用受maxsize参数限制,其默认值相当保守,为 128,这意味着缓存最多同时保留 128 个条目。
LRU 的首字母缩写代表最近最少使用,意味着长时间未被读取的旧条目将被丢弃,以腾出空间给新条目。
自 Python 3.8 以来,lru_cache可以以两种方式应用。这是最简单的使用方法:
@lru_cache
def costly_function(a, b):...
另一种方式——自 Python 3.2 起可用——是将其作为函数调用,使用():
@lru_cache()
def costly_function(a, b):...
在这两种情况下,将使用默认参数。这些是:
maxsize=128
设置要存储的条目的最大数量。缓存满后,最近最少使用的条目将被丢弃以为新条目腾出空间。为了获得最佳性能,maxsize应为 2 的幂。如果传递maxsize=None,LRU 逻辑将被禁用,因此缓存工作速度更快,但条目永远不会被丢弃,这可能会消耗过多内存。这就是@functools.cache的作用。
typed=False
确定不同参数类型的结果是否分开存储。例如,在默认设置中,被视为相等的浮点数和整数参数仅存储一次,因此对f(1)和f(1.0)的调用将只有一个条目。如果typed=True,这些参数将产生不同的条目,可能存储不同的结果。
这是使用非默认参数调用@lru_cache的示例:
@lru_cache(maxsize=2**20, typed=True)
def costly_function(a, b):...
现在让我们研究另一个强大的装饰器:functools.singledispatch。
单分发通用函数
想象我们正在创建一个用于调试 Web 应用程序的工具。我们希望为不同类型的 Python 对象生成 HTML 显示。
我们可以从这样的函数开始:
import htmldef htmlize(obj):content = html.escape(repr(obj))return f'<pre>{content}</pre>'
这将适用于任何 Python 类型,但现在我们想扩展它以生成一些类型的自定义显示。一些示例:
str
用'<br/>\n'替换嵌入的换行符,并使用<p>标签代替<pre>。
int
以十进制和十六进制形式显示数字(对 bool 有特殊情况)。
list
输出一个 HTML 列表,根据其类型格式化每个项目。
float 和 Decimal
通常输出值,但也以分数形式呈现(为什么不呢?)。
我们想要的行为在 Example 9-19 中展示。
Example 9-19. htmlize() 生成针对不同对象类型定制的 HTML
>>> htmlize({1, 2, 3}) # ①
'<pre>{1, 2, 3}</pre>' >>> htmlize(abs)
'<pre><built-in function abs></pre>' >>> htmlize('Heimlich & Co.\n- a game') # ②
'<p>Heimlich & Co.<br/>\n- a game</p>' >>> htmlize(42) # ③
'<pre>42 (0x2a)</pre>' >>> print(htmlize(['alpha', 66, {3, 2, 1}])) # ④
<ul> <li><p>alpha</p></li> <li><pre>66 (0x42)</pre></li> <li><pre>{1, 2, 3}</pre></li> </ul> >>> htmlize(True) # ⑤
'<pre>True</pre>' >>> htmlize(fractions.Fraction(2, 3)) # ⑥
'<pre>2/3</pre>' >>> htmlize(2/3) # ⑦
'<pre>0.6666666666666666 (2/3)</pre>' >>> htmlize(decimal.Decimal('0.02380952'))
'<pre>0.02380952 (1/42)</pre>'
①
原始函数为 object 注册,因此它作为一个通用函数来处理与其他实现不匹配的参数类型。
②
str 对象也会进行 HTML 转义,但会被包裹在 <p></p> 中,并在每个 '\n' 前插入 <br/> 换行符。
③
int 以十进制和十六进制的形式显示,在 <pre></pre> 中。
④
每个列表项根据其类型进行格式化,并将整个序列呈现为 HTML 列表。
⑤
尽管 bool 是 int 的子类型,但它得到了特殊处理。
⑥
以分数形式展示 Fraction。
⑦
以近似分数等价形式展示 float 和 Decimal。
函数 singledispatch
因为在 Python 中我们没有 Java 风格的方法重载,所以我们不能简单地为我们想要以不同方式处理的每种数据类型创建 htmlize 的变体。在 Python 中的一个可能的解决方案是将 htmlize 转变为一个分发函数,使用一系列的 if/elif/… 或 match/case/… 调用专门函数,如 htmlize_str,htmlize_int 等。这种方法对我们模块的用户来说是不可扩展的,而且很笨重:随着时间的推移,htmlize 分发器会变得太大,它与专门函数之间的耦合会非常紧密。
functools.singledispatch 装饰器允许不同模块为整体解决方案做出贡献,并让您轻松为属于第三方包的类型提供专门函数,而这些包您无法编辑。如果您用 @singledispatch 装饰一个普通函数,它将成为一个通用函数的入口点:一组函数以不同方式执行相同操作,取决于第一个参数的类型。这就是所谓的单分派。如果使用更多参数来选择特定函数,我们将有多分派。Example 9-20 展示了如何实现。
警告
functools.singledispatch 自 Python 3.4 起存在,但自 Python 3.7 起才支持类型提示。Example 9-20 中的最后两个函数展示了在 Python 3.4 以来所有版本中都有效的语法。
Example 9-20. @singledispatch 创建一个自定义的 @htmlize.register 来将几个函数捆绑成一个通用函数
from functools import singledispatch
from collections import abc
import fractions
import decimal
import html
import numbers@singledispatch # ①
def htmlize(obj: object) -> str:content = html.escape(repr(obj))return f'<pre>{content}</pre>'@htmlize.register # ②
def _(text: str) -> str: # ③content = html.escape(text).replace('\n', '<br/>\n')return f'<p>{content}</p>'@htmlize.register # ④
def _(seq: abc.Sequence) -> str:inner = '</li>\n<li>'.join(htmlize(item) for item in seq)return '<ul>\n<li>' + inner + '</li>\n</ul>'@htmlize.register # ⑤
def _(n: numbers.Integral) -> str:return f'<pre>{n} (0x{n:x})</pre>'@htmlize.register # ⑥
def _(n: bool) -> str:return f'<pre>{n}</pre>'@htmlize.register(fractions.Fraction) # ⑦
def _(x) -> str:frac = fractions.Fraction(x)return f'<pre>{frac.numerator}/{frac.denominator}</pre>'@htmlize.register(decimal.Decimal) # ⑧
@htmlize.register(float)
def _(x) -> str:frac = fractions.Fraction(x).limit_denominator()return f'<pre>{x} ({frac.numerator}/{frac.denominator})</pre>'
①
@singledispatch 标记了处理 object 类型的基本函数。
②
每个专门函数都使用 @«base».register 进行装饰。
③
运行时给定的第一个参数的类型决定了何时使用这个特定的函数定义。专门函数的名称并不重要;_ 是一个很好的选择,可以让这一点清晰明了。⁶
④
为了让每个额外的类型得到特殊处理,需要注册一个新的函数,并在第一个参数中使用匹配的类型提示。
⑤
numbers ABCs 对于与 singledispatch 一起使用很有用。⁷
⑥
bool是numbers.Integral的子类型,但singledispatch逻辑寻找具有最具体匹配类型的实现,而不考虑它们在代码中出现的顺序。
⑦
如果您不想或无法向装饰的函数添加类型提示,可以将类型传递给@«base».register装饰器。这种语法适用于 Python 3.4 或更高版本。
⑧
@«base».register装饰器返回未装饰的函数,因此可以堆叠它们以在同一实现上注册两个或更多类型。⁸
在可能的情况下,注册专门的函数以处理抽象类(ABCs)如numbers.Integral和abc.MutableSequence,而不是具体实现如int和list。这样可以使您的代码支持更多兼容类型的变化。例如,Python 扩展可以提供numbers.Integral的子类作为int类型的替代方案。
提示
使用 ABCs 或typing.Protocol与@singledispatch允许您的代码支持现有或未来的类,这些类是这些 ABCs 的实际或虚拟子类,或者实现了这些协议。ABCs 的使用和虚拟子类的概念是第十三章的主题。
singledispatch机制的一个显著特点是,您可以在系统中的任何模块中注册专门的函数。如果以后添加了一个具有新用户定义类型的模块,您可以轻松提供一个新的自定义函数来处理该类型。您可以为您没有编写且无法更改的类编写自定义函数。
singledispatch是标准库中经过深思熟虑的添加,它提供的功能比我在这里描述的要多。PEP 443—单分派通用函数是一个很好的参考,但它没有提到后来添加的类型提示的使用。functools模块文档已经改进,并在其singledispatch条目中提供了更多最新的覆盖范例。
注意
@singledispatch并非旨在将 Java 风格的方法重载引入 Python。一个具有许多重载方法变体的单个类比具有一长串if/elif/elif/elif块的单个函数更好。但这两种解决方案都有缺陷,因为它们在单个代码单元(类或函数)中集中了太多责任。@singledispatch的优势在于支持模块化扩展:每个模块可以为其支持的每种类型注册一个专门的函数。在实际用例中,您不会像示例 9-20 中那样将所有通用函数的实现放在同一个模块中。
我们已经看到一些接受参数的装饰器,例如@lru_cache()和htmlize.register(float),由@singledispatch在示例 9-20 中创建。下一节将展示如何构建接受参数的装饰器。
参数化装饰器
在源代码中解析装饰器时,Python 将装饰的函数作为第一个参数传递给装饰器函数。那么如何使装饰器接受其他参数呢?答案是:创建一个接受这些参数并返回装饰器的装饰器工厂,然后将其应用于要装饰的函数。令人困惑?当然。让我们从基于我们看到的最简单的装饰器register的示例开始:示例 9-21。
示例 9-21. 来自示例 9-2 的简化 registration.py 模块,这里为方便起见重复显示
registry = []def register(func):print(f'running register({func})')registry.append(func)return func@register
def f1():print('running f1()')print('running main()')
print('registry ->', registry)
f1()
一个参数化注册装饰器
为了方便启用或禁用register执行的函数注册,我们将使其接受一个可选的active参数,如果为False,则跳过注册被装饰的函数。示例 9-22 展示了如何。从概念上讲,新的register函数不是一个装饰器,而是一个装饰器工厂。当调用时,它返回将应用于目标函数的实际装饰器。
示例 9-22. 要接受参数,新的register装饰器必须被调用为一个函数
registry = set() # ①def register(active=True): # ②def decorate(func): # ③print('running register'f'(active={active})->decorate({func})')if active: # ④registry.add(func)else:registry.discard(func) # ⑤return func # ⑥return decorate # ⑦@register(active=False) # ⑧
def f1():print('running f1()')@register() # ⑨
def f2():print('running f2()')def f3():print('running f3()')
①
registry现在是一个set,因此添加和移除函数更快。
②
register接受一个可选的关键字参数。
③
decorate内部函数是实际的装饰器;注意它如何将一个函数作为参数。
④
仅在active参数(从闭包中检索)为True时注册func。
⑤
如果not active并且func in registry,则移除它。
⑥
因为decorate是一个装饰器,所以它必须返回一个函数。
⑦
register是我们的装饰器工厂,因此它返回decorate。
⑧
必须将@register工厂作为一个函数调用,带上所需的参数。
⑨
如果没有传递参数,则必须仍然调用register作为一个函数—@register()—即,返回实际装饰器decorate。
主要点是register()返回decorate,然后应用于被装饰的函数。
示例 9-22 中的代码位于registration_param.py模块中。如果我们导入它,我们会得到这个:
>>> import registration_param
running register(active=False)->decorate(<function f1 at 0x10063c1e0>)
running register(active=True)->decorate(<function f2 at 0x10063c268>)
>>> registration_param.registry
[<function f2 at 0x10063c268>]
注意只有f2函数出现在registry中;f1没有出现,因为active=False被传递给register装饰器工厂,所以应用于f1的decorate没有将其添加到registry中。
如果我们不使用@语法,而是将register作为一个常规函数使用,装饰一个函数f所需的语法将是register()(f)来将f添加到registry中,或者register(active=False)(f)来不添加它(或移除它)。查看示例 9-23 了解如何向registry添加和移除函数的演示。
示例 9-23. 使用示例 9-22 中列出的 registration_param 模块
>>> from registration_param import *
running register(active=False)->decorate(<function f1 at 0x10073c1e0>) running register(active=True)->decorate(<function f2 at 0x10073c268>) >>> registry # ①
{<function f2 at 0x10073c268>} >>> register()(f3) # ②
running register(active=True)->decorate(<function f3 at 0x10073c158>) <function f3 at 0x10073c158> >>> registry # ③
{<function f3 at 0x10073c158>, <function f2 at 0x10073c268>} >>> register(active=False)(f2) # ④
running register(active=False)->decorate(<function f2 at 0x10073c268>) <function f2 at 0x10073c268> >>> registry # ⑤
{<function f3 at 0x10073c158>}
①
当模块被导入时,f2在registry中。
②
register()表达式返回decorate,然后应用于f3。
③
前一行将f3添加到registry中。
④
这个调用从registry中移除了f2。
⑤
确认只有f3保留在registry中。
参数化装饰器的工作方式相当复杂,我们刚刚讨论的比大多数都要简单。参数化装饰器通常会替换被装饰的函数,它们的构建需要另一层嵌套。现在我们将探讨这样一个函数金字塔的架构。
带参数的时钟装饰器
在本节中,我们将重新访问clock装饰器,添加一个功能:用户可以传递一个格式字符串来控制时钟函数报告的输出。参见示例 9-24。
注意
为简单起见,示例 9-24 基于初始clock实现示例 9-14,而不是使用@functools.wraps改进的实现示例 9-16,后者添加了另一个函数层。
示例 9-24. 模块 clockdeco_param.py:带参数时钟装饰器
import timeDEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}'def clock(fmt=DEFAULT_FMT): # ①def decorate(func): # ②def clocked(*_args): # ③t0 = time.perf_counter()_result = func(*_args) # ④elapsed = time.perf_counter() - t0name = func.__name__args = ', '.join(repr(arg) for arg in _args) # ⑤result = repr(_result) # ⑥print(fmt.format(**locals())) # ⑦return _result # ⑧return clocked # ⑨return decorate # ⑩if __name__ == '__main__':@clock() ⑪def snooze(seconds):time.sleep(seconds)for i in range(3):snooze(.123)
①
clock是我们的带参数装饰器工厂。
②
decorate是实际的装饰器。
③
clocked包装了被装饰的函数。
④
_result是被装饰函数的实际结果。
⑤
_args保存了clocked的实际参数,而args是用于显示的str。
⑥
result是_result的str表示,用于显示。
⑦
在这里使用**locals()允许引用clocked的任何局部变量在fmt中。¹⁰
⑧
clocked将替换被装饰的函数,因此它应该返回该函数返回的任何内容。
⑨
decorate返回clocked。
⑩
clock返回decorate。
⑪
在这个自测中,clock()被无参数调用,因此应用的装饰器将使用默认格式str。
如果你在 shell 中运行示例 9-24,你会得到这个结果:
$ python3 clockdeco_param.py
[0.12412500s] snooze(0.123) -> None
[0.12411904s] snooze(0.123) -> None
[0.12410498s] snooze(0.123) -> None
为了练习新功能,让我们看一下示例 9-25 和 9-26,它们是使用clockdeco_param的另外两个模块以及它们生成的输出。
示例 9-25. clockdeco_param_demo1.py
import time
from clockdeco_param import clock@clock('{name}: {elapsed}s')
def snooze(seconds):time.sleep(seconds)for i in range(3):snooze(.123)
示例 9-25 的输出:
$ python3 clockdeco_param_demo1.py
snooze: 0.12414693832397461s
snooze: 0.1241159439086914s
snooze: 0.12412118911743164s
示例 9-26. clockdeco_param_demo2.py
import time
from clockdeco_param import clock@clock('{name}({args}) dt={elapsed:0.3f}s')
def snooze(seconds):time.sleep(seconds)for i in range(3):snooze(.123)
示例 9-26 的输出:
$ python3 clockdeco_param_demo2.py
snooze(0.123) dt=0.124s
snooze(0.123) dt=0.124s
snooze(0.123) dt=0.124s
注意
第一版的技术审阅员 Lennart Regebro 认为装饰器最好编写为实现__call__的类,而不是像本章示例中的函数那样。我同意这种方法对于复杂的装饰器更好,但为了解释这种语言特性的基本思想,函数更容易理解。参见“进一步阅读”,特别是 Graham Dumpleton 的博客和wrapt模块,用于构建装饰器的工业级技术。
下一节展示了 Regebro 和 Dumpleton 推荐风格的示例。
基于类的时钟装饰器
最后一个例子,示例 9-27 列出了一个作为类实现的带参数clock装饰器的实现,其中使用了__call__。对比示例 9-24 和示例 9-27。你更喜欢哪一个?
示例 9-27. 模块 clockdeco_cls.py:作为类实现的带参数时钟装饰器
import timeDEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}'class clock: # ①def __init__(self, fmt=DEFAULT_FMT): # ②self.fmt = fmtdef __call__(self, func): # ③def clocked(*_args):t0 = time.perf_counter()_result = func(*_args) # ④elapsed = time.perf_counter() - t0name = func.__name__args = ', '.join(repr(arg) for arg in _args)result = repr(_result)print(self.fmt.format(**locals()))return _resultreturn clocked
①
与clock外部函数不同,clock类是我们的带参数装饰器工厂。我用小写字母c命名它,以明确表明这个实现是示例 9-24 中的一个可替换项。
②
在clock(my_format)中传入的参数被分配给了这里的fmt参数。类构造函数返回一个clock的实例,其中my_format存储在self.fmt中。
③
__call__使clock实例可调用。当调用时,实例将用clocked替换被装饰的函数。
④
clocked包装了被装饰的函数。
我们的函数装饰器探索到此结束。我们将在第二十四章中看到类装饰器。
章节总结
我们在本章涵盖了一些困难的领域。我尽力使旅程尽可能顺利,但我们确实进入了元编程的领域。
我们从一个没有内部函数的简单@register装饰器开始,最后完成了一个涉及两个嵌套函数级别的参数化@clock()。
虽然注册装饰器在本质上很简单,但在 Python 框架中有真正的应用。我们将在第十章中将注册思想应用于策略设计模式的一个实现。
理解装饰器实际工作原理需要涵盖导入时间和运行时之间的差异,然后深入研究变量作用域、闭包和新的nonlocal声明。掌握闭包和nonlocal不仅有助于构建装饰器,还有助于为 GUI 或异步 I/O 编写事件导向的程序,并在有意义时采用函数式风格。
参数化装饰器几乎总是涉及至少两个嵌套函数,如果您想使用@functools.wraps来生成提供更好支持更高级技术的装饰器,则可能涉及更多嵌套函数。其中一种技术是堆叠装饰器,我们在示例 9-18 中看到了。对于更复杂的装饰器,基于类的实现可能更易于阅读和维护。
作为标准库中参数化装饰器的示例,我们访问了functools模块中强大的@cache和@singledispatch。
进一步阅读
Brett Slatkin 的Effective Python第 2 版(Addison-Wesley)的第 26 条建议了函数装饰器的最佳实践,并建议始终使用functools.wraps——我们在示例 9-16 中看到的。¹¹
Graham Dumpleton 在他的一系列深入的博客文章中介绍了实现行为良好的装饰器的技术,从“你实现的 Python 装饰器是错误的”开始。他在这方面的深厚专业知识也很好地包含在他编写的wrapt模块中,该模块简化了装饰器和动态函数包装器的实现,支持内省,并在进一步装饰、应用于方法以及用作属性描述符时表现正确。第 III 部分的第二十三章是关于描述符的。
《Python Cookbook》第 3 版(O’Reilly)的第九章“元编程”,作者是 David Beazley 和 Brian K. Jones,包含了从基本装饰器到非常复杂的装饰器的几个示例,其中包括一个可以作为常规装饰器或装饰器工厂调用的示例,例如,@clock或@clock()。这在该食谱书中是“食谱 9.6. 定义一个带有可选参数的装饰器”。
Michele Simionato 编写了一个旨在“简化普通程序员对装饰器的使用,并通过展示各种非平凡示例来普及装饰器”的软件包。它在 PyPI 上作为decorator 软件包提供。
当装饰器在 Python 中仍然是一个新功能时创建的,Python 装饰器库维基页面有数十个示例。由于该页面多年前开始,一些显示的技术已经过时,但该页面仍然是一个极好的灵感来源。
“Python 中的闭包”是 Fredrik Lundh 的一篇简短博客文章,解释了闭包的术语。
PEP 3104—访问外部作用域中的名称 描述了引入 nonlocal 声明以允许重新绑定既不是本地的也不是全局的名称。它还包括了如何在其他动态语言(Perl、Ruby、JavaScript 等)中解决这个问题的优秀概述,以及 Python 可用的设计选项的利弊。
在更理论层面上,PEP 227—静态嵌套作用域 记录了在 Python 2.1 中引入词法作用域作为一个选项,并在 Python 2.2 中作为标准的过程,解释了在 Python 中实现闭包的原因和设计选择。
PEP 443 提供了单分派通用函数的理由和详细描述。Guido van Rossum 在 2005 年 3 月的一篇博客文章 “Python 中的五分钟多方法” 通过使用装饰器实现了通用函数(又称多方法)。他的代码支持多分派(即基于多个位置参数的分派)。Guido 的多方法代码很有趣,但这只是一个教学示例。要了解现代、适用于生产的多分派通用函数的实现,请查看 Martijn Faassen 的 Reg—作者是面向模型驱动和 REST 专业的 Morepath web 框架的作者。
¹ 这是 1995 年的设计模式一书,由所谓的四人帮(Gamma 等,Addison-Wesley)撰写。
² 如果你在前一句中将“函数”替换为“类”,你就得到了类装饰器的简要描述。类装饰器在 第二十四章 中有介绍。
³ 感谢技术审阅者 Leonardo Rochael 提出这个总结。
⁴ Python 没有程序全局作用域,只有模块全局作用域。
⁵ 为了澄清,这不是一个打字错误:memoization 是一个与“memorization”模糊相关的计算机科学术语,但并不相同。
⁶ 不幸的是,当 Mypy 0.770 看到多个同名函数时会报错。
⁷ 尽管在 “数值塔的崩塌” 中有警告,number ABCs 并没有被弃用,你可以在 Python 3 代码中找到它们。
⁸ 也许有一天你也能用单个无参数的 @htmlize.register 和使用 Union 类型提示来表达这个,但当我尝试时,Python 报错,提示 Union 不是一个类。因此,尽管 @singledispatch 支持 PEP 484 的语法,但语义还没有实现。
⁹ 例如,NumPy 实现了几种面向机器的整数和浮点数类型。
¹⁰ 技术审阅者 Miroslav Šedivý 指出:“这也意味着代码检查工具会抱怨未使用的变量,因为它们倾向于忽略对 locals() 的使用。” 是的,这是静态检查工具如何阻止我和无数程序员最初被 Python 吸引的动态特性的又一个例子。为了让代码检查工具满意,我可以在调用中两次拼写每个本地变量:fmt.format(elapsed=elapsed, name=name, args=args, result=result)。我宁愿不这样做。如果你使用静态检查工具,非常重要的是要知道何时忽略它们。
¹¹ 我想尽可能简化代码,所以我并没有在所有示例中遵循 Slatkin 的优秀建议。
第十章:具有一等函数的设计模式
符合模式并不是好坏的衡量标准。
拉尔夫·约翰逊,设计模式经典著作的合著者¹
在软件工程中,设计模式是解决常见设计问题的通用配方。你不需要了解设计模式来阅读本章。我将解释示例中使用的模式。
编程中设计模式的使用被设计模式:可复用面向对象软件的元素(Addison-Wesley)一书所推广,作者是 Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides,也被称为“四人组”。这本书是一个包含 23 种模式的目录,其中有用 C++代码示例的类排列,但也被认为在其他面向对象语言中也很有用。
尽管设计模式是与语言无关的,但这并不意味着每种模式都适用于每种语言。例如,第十七章将展示在 Python 中模拟Iterator模式的配方是没有意义的,因为该模式已嵌入在语言中,并以生成器的形式准备好使用,不需要类来工作,并且比经典配方需要更少的代码。
设计模式的作者在介绍中承认,实现语言决定了哪些模式是相关的:
编程语言的选择很重要,因为它影响一个人的观点。我们的模式假设具有 Smalltalk/C++级别的语言特性,这种选择决定了什么可以轻松实现,什么不能。如果我们假设过程式语言,我们可能会包括称为“继承”、“封装”和“多态性”的设计模式。同样,一些我们的模式直接受到不太常见的面向对象语言的支持。例如,CLOS 具有多方法,这减少了像 Visitor 这样的模式的需求²
在他 1996 年的演讲中,“动态语言中的设计模式”,Peter Norvig 指出原始设计模式书中的 23 种模式中有 16 种在动态语言中变得“不可见或更简单”(幻灯片 9)。他谈到的是 Lisp 和 Dylan 语言,但许多相关的动态特性也存在于 Python 中。特别是在具有一等函数的语言环境中,Norvig 建议重新思考被称为 Strategy、Command、Template Method 和 Visitor 的经典模式。
本章的目标是展示如何——在某些情况下——函数可以像类一样完成工作,代码更易读且更简洁。我们将使用函数作为对象重构 Strategy 的实现,消除大量样板代码。我们还将讨论简化 Command 模式的类似方法。
本章的新内容
我将这一章移到第三部分的末尾,这样我就可以在“装饰增强的 Strategy 模式”中应用注册装饰器,并在示例中使用类型提示。本章中使用的大多数类型提示并不复杂,它们确实有助于可读性。
案例研究:重构 Strategy
Strategy 是一个很好的设计模式示例,在 Python 中,如果你利用函数作为一等对象,它可能会更简单。在接下来的部分中,我们使用设计模式中描述的“经典”结构来描述和实现 Strategy。如果你熟悉经典模式,可以直接跳到“面向函数的 Strategy”,我们将使用函数重构代码,显著减少行数。
经典 Strategy
图 10-1 中的 UML 类图描述了展示 Strategy 模式的类排列。
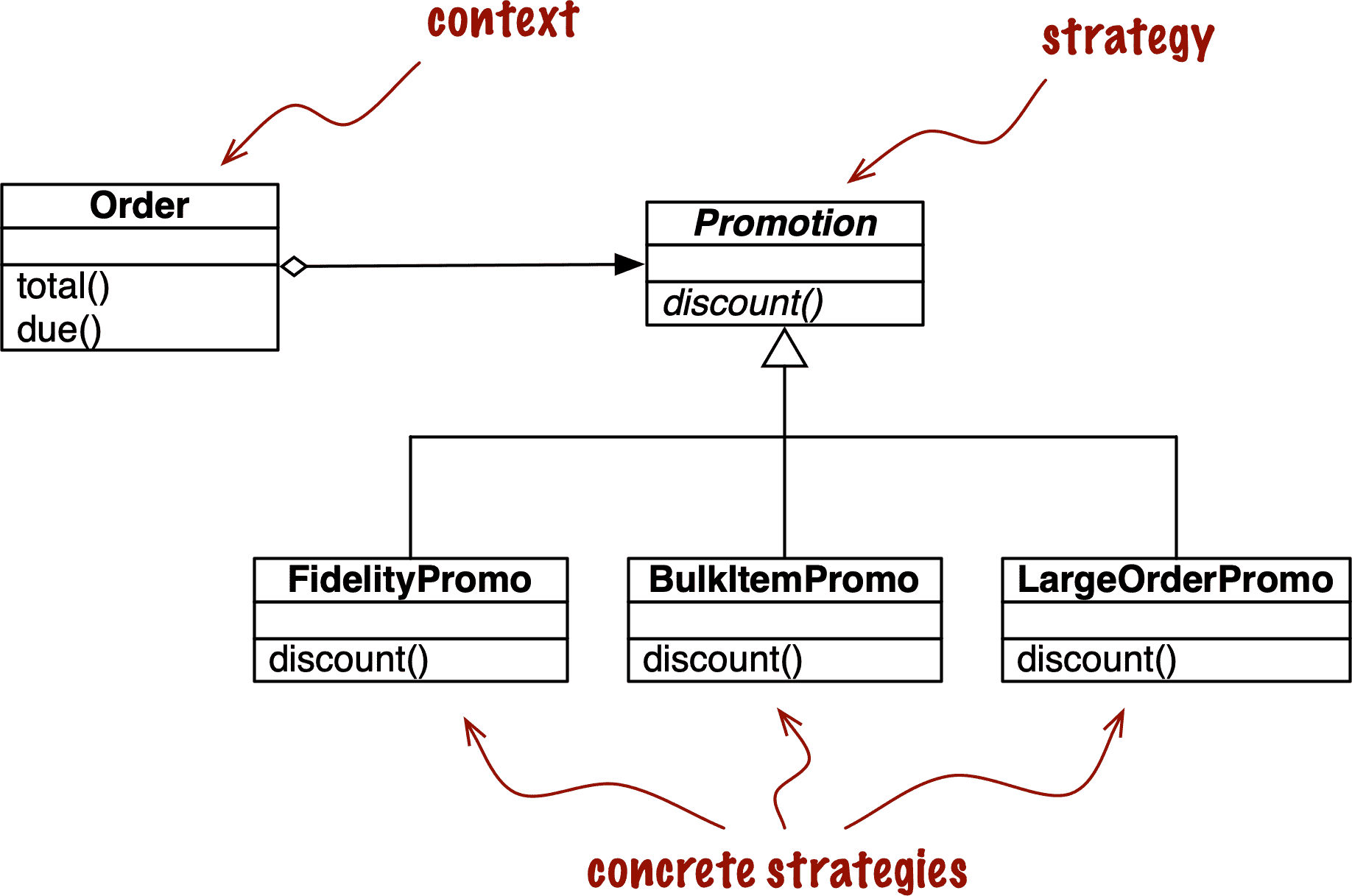
图 10-1. 使用策略设计模式实现订单折扣处理的 UML 类图。
设计模式 中对策略模式的总结如下:
定义一组算法家族,封装每个算法,并使它们可以互换。策略让算法独立于使用它的客户端变化。
在电子商务领域中应用策略的一个明显例子是根据客户属性或订购商品的检查计算订单折扣。
考虑一个在线商店,具有以下折扣规则:
-
拥有 1,000 或更多忠诚积分的顾客每个订单可以获得全局 5% 的折扣。
-
每个订单中有 20 个或更多单位的行项目都会获得 10% 的折扣。
-
至少有 10 个不同商品的订单可以获得 7% 的全局折扣。
为简洁起见,假设订单只能应用一个折扣。
策略模式的 UML 类图在 图 10-1 中描述。参与者有:
上下文
通过将一些计算委托给实现替代算法的可互换组件来提供服务。在电子商务示例中,上下文是一个 Order,它被配置为根据几种算法之一应用促销折扣。
策略
实现不同算法的组件之间的公共接口。在我们的例子中,这个角色由一个名为 Promotion 的抽象类扮演。
具体策略
Strategy 的具体子类之一。FidelityPromo、BulkPromo 和 LargeOrderPromo 是实现的三个具体策略。
示例 10-1 中的代码遵循 图 10-1 中的蓝图。如 设计模式 中所述,具体策略由上下文类的客户端选择。在我们的例子中,在实例化订单之前,系统会以某种方式选择促销折扣策略并将其传递给 Order 构造函数。策略的选择超出了模式的范围。
示例 10-1. 实现具有可插入折扣策略的 Order 类
from abc import ABC, abstractmethod
from collections.abc import Sequence
from decimal import Decimal
from typing import NamedTuple, Optionalclass Customer(NamedTuple):name: strfidelity: intclass LineItem(NamedTuple):product: strquantity: intprice: Decimaldef total(self) -> Decimal:return self.price * self.quantityclass Order(NamedTuple): # the Contextcustomer: Customercart: Sequence[LineItem]promotion: Optional['Promotion'] = Nonedef total(self) -> Decimal:totals = (item.total() for item in self.cart)return sum(totals, start=Decimal(0))def due(self) -> Decimal:if self.promotion is None:discount = Decimal(0)else:discount = self.promotion.discount(self)return self.total() - discountdef __repr__(self):return f'<Order total: {self.total():.2f} due: {self.due():.2f}>'class Promotion(ABC): # the Strategy: an abstract base class@abstractmethoddef discount(self, order: Order) -> Decimal:"""Return discount as a positive dollar amount"""class FidelityPromo(Promotion): # first Concrete Strategy"""5% discount for customers with 1000 or more fidelity points"""def discount(self, order: Order) -> Decimal:rate = Decimal('0.05')if order.customer.fidelity >= 1000:return order.total() * ratereturn Decimal(0)class BulkItemPromo(Promotion): # second Concrete Strategy"""10% discount for each LineItem with 20 or more units"""def discount(self, order: Order) -> Decimal:discount = Decimal(0)for item in order.cart:if item.quantity >= 20:discount += item.total() * Decimal('0.1')return discountclass LargeOrderPromo(Promotion): # third Concrete Strategy"""7% discount for orders with 10 or more distinct items"""def discount(self, order: Order) -> Decimal:distinct_items = {item.product for item in order.cart}if len(distinct_items) >= 10:return order.total() * Decimal('0.07')return Decimal(0)
请注意,在 示例 10-1 中,我将 Promotion 编码为抽象基类(ABC),以使用 @abstractmethod 装饰器并使模式更加明确。
示例 10-2 展示了用于演示和验证实现前述规则的模块操作的 doctests。
示例 10-2. 应用不同促销策略的 Order 类的示例用法
>>> joe = Customer('John Doe', 0) # ①>>> ann = Customer('Ann Smith', 1100) >>> cart = (LineItem('banana', 4, Decimal('.5')), # ②... LineItem('apple', 10, Decimal('1.5')), ... LineItem('watermelon', 5, Decimal(5))) >>> Order(joe, cart, FidelityPromo()) # ③<Order total: 42.00 due: 42.00> >>> Order(ann, cart, FidelityPromo()) # ④<Order total: 42.00 due: 39.90> >>> banana_cart = (LineItem('banana', 30, Decimal('.5')), # ⑤... LineItem('apple', 10, Decimal('1.5'))) >>> Order(joe, banana_cart, BulkItemPromo()) # ⑥<Order total: 30.00 due: 28.50> >>> long_cart = tuple(LineItem(str(sku), 1, Decimal(1)) # ⑦... for sku in range(10)) >>> Order(joe, long_cart, LargeOrderPromo()) # ⑧<Order total: 10.00 due: 9.30> >>> Order(joe, cart, LargeOrderPromo()) <Order total: 42.00 due: 42.00>
①
两位顾客:joe 没有忠诚积分,ann 有 1,100 积分。
②
一个购物车有三个行项目。
③
FidelityPromo 促销不给 joe 任何折扣。
④
ann 因为拥有至少 1,000 积分,所以可以获得 5% 的折扣。
⑤
banana_cart 有 30 个单位的 "banana" 产品和 10 个苹果。
⑥
由于 BulkItemPromo,joe 在香蕉上获得 $1.50 的折扣。
⑦
long_cart 有 10 个不同的商品,每个商品价格为 $1.00。
⑧
joe 因为 LargerOrderPromo 而获得整个订单 7% 的折扣。
示例 10-1 可以完美地运行,但是在 Python 中可以使用函数作为对象来实现相同的功能,代码更少。下一节将展示如何实现。
面向函数的策略
示例 10-1 中的每个具体策略都是一个只有一个方法discount的类。此外,策略实例没有状态(没有实例属性)。你可以说它们看起来很像普通函数,你说得对。示例 10-3 是示例 10-1 的重构,用简单函数替换具体策略并移除Promo抽象类。在Order类中只需要做出小的调整。³
示例 10-3。Order类中实现的折扣策略作为函数
from collections.abc import Sequence
from dataclasses import dataclass
from decimal import Decimal
from typing import Optional, Callable, NamedTupleclass Customer(NamedTuple):name: strfidelity: intclass LineItem(NamedTuple):product: strquantity: intprice: Decimaldef total(self):return self.price * self.quantity@dataclass(frozen=True)
class Order: # the Contextcustomer: Customercart: Sequence[LineItem]promotion: Optional[Callable[['Order'], Decimal]] = None # ①def total(self) -> Decimal:totals = (item.total() for item in self.cart)return sum(totals, start=Decimal(0))def due(self) -> Decimal:if self.promotion is None:discount = Decimal(0)else:discount = self.promotion(self) # ②return self.total() - discountdef __repr__(self):return f'<Order total: {self.total():.2f} due: {self.due():.2f}>'# ③def fidelity_promo(order: Order) -> Decimal: # ④"""5% discount for customers with 1000 or more fidelity points"""if order.customer.fidelity >= 1000:return order.total() * Decimal('0.05')return Decimal(0)def bulk_item_promo(order: Order) -> Decimal:"""10% discount for each LineItem with 20 or more units"""discount = Decimal(0)for item in order.cart:if item.quantity >= 20:discount += item.total() * Decimal('0.1')return discountdef large_order_promo(order: Order) -> Decimal:"""7% discount for orders with 10 or more distinct items"""distinct_items = {item.product for item in order.cart}if len(distinct_items) >= 10:return order.total() * Decimal('0.07')return Decimal(0)
①
这个类型提示说:promotion可能是None,也可能是一个接受Order参数并返回Decimal的可调用对象。
②
要计算折扣,请调用self.promotion可调用对象,并传递self作为参数。请查看下面的提示原因。
③
没有抽象类。
④
每个策略都是一个函数。
为什么是 self.promotion(self)?
在Order类中,promotion不是一个方法。它是一个可调用的实例属性。因此,表达式的第一部分self.promotion检索到了可调用对象。要调用它,我们必须提供一个Order实例,而在这种情况下是self。这就是为什么在表达式中self出现两次的原因。
“方法是描述符”将解释将方法自动绑定到实例的机制。这不适用于promotion,因为它不是一个方法。
示例 10-3 中的代码比示例 10-1 要短。使用新的Order也更简单,如示例 10-4 中的 doctests 所示。
示例 10-4。Order类使用函数作为促销的示例用法
>>> joe = Customer('John Doe', 0) # ①>>> ann = Customer('Ann Smith', 1100) >>> cart = [LineItem('banana', 4, Decimal('.5')), ... LineItem('apple', 10, Decimal('1.5')), ... LineItem('watermelon', 5, Decimal(5))] >>> Order(joe, cart, fidelity_promo) # ②<Order total: 42.00 due: 42.00> >>> Order(ann, cart, fidelity_promo) <Order total: 42.00 due: 39.90> >>> banana_cart = [LineItem('banana', 30, Decimal('.5')), ... LineItem('apple', 10, Decimal('1.5'))] >>> Order(joe, banana_cart, bulk_item_promo) # ③<Order total: 30.00 due: 28.50> >>> long_cart = [LineItem(str(item_code), 1, Decimal(1)) ... for item_code in range(10)] >>> Order(joe, long_cart, large_order_promo) <Order total: 10.00 due: 9.30> >>> Order(joe, cart, large_order_promo) <Order total: 42.00 due: 42.00>
①
与示例 10-1 相同的测试固定装置。
②
要将折扣策略应用于Order,只需将促销函数作为参数传递。
③
这里和下一个测试中使用了不同的促销函数。
注意示例 10-4 中的标注——每个新订单不需要实例化一个新的促销对象:这些函数已经准备好使用。
有趣的是,在设计模式中,作者建议:“策略对象通常是很好的享元。”⁴ 该作品的另一部分中对享元模式的定义是:“享元是一个可以在多个上下文中同时使用的共享对象。”⁵ 建议共享以减少在每个新上下文中重复应用相同策略时创建新具体策略对象的成本——在我们的例子中,每个新的Order实例。因此,为了克服策略模式的一个缺点——运行时成本——作者建议应用另一种模式。同时,您的代码行数和维护成本正在积累。
一个更棘手的用例,具有内部状态的复杂具体策略可能需要将策略和享元设计模式的所有部分结合起来。但通常具体策略没有内部状态;它们只处理来自上下文的数据。如果是这种情况,那么请务必使用普通的函数,而不是编写实现单方法接口的单方法类的单方法类。函数比用户定义类的实例更轻量级,而且不需要享元,因为每个策略函数在 Python 进程加载模块时只创建一次。一个普通函数也是“一个可以同时在多个上下文中使用的共享对象”。
现在我们已经使用函数实现了策略模式,其他可能性也出现了。假设您想创建一个“元策略”,为给定的Order选择最佳可用折扣。在接下来的几节中,我们研究了使用各种方法利用函数和模块作为对象实现此要求的额外重构。
选择最佳策略:简单方法
在示例 10-4 中的测试中给定相同的顾客和购物车,我们现在在示例 10-5 中添加了三个额外的测试。
示例 10-5。best_promo函数应用所有折扣并返回最大值
>>> Order(joe, long_cart, best_promo) # ①<Order total: 10.00 due: 9.30>>>> Order(joe, banana_cart, best_promo) # ②<Order total: 30.00 due: 28.50>>>> Order(ann, cart, best_promo) # ③<Order total: 42.00 due: 39.90>
①
best_promo为顾客joe选择了larger_order_promo。
②
这里joe因为订购了大量香蕉而从bulk_item_promo获得了折扣。
③
使用一个简单的购物车结账,best_promo为忠实顾客ann提供了fidelity_promo的折扣。
best_promo的实现非常简单。参见示例 10-6。
示例 10-6。best_promo在函数列表上迭代找到最大折扣
promos = [fidelity_promo, bulk_item_promo, large_order_promo] # ①def best_promo(order: Order) -> Decimal: # ②"""Compute the best discount available"""return max(promo(order) for promo in promos) # ③
①
promos:作为函数实现的策略列表。
②
best_promo接受Order的实例作为参数,其他*_promo函数也是如此。
③
使用生成器表达式,我们将promos中的每个函数应用于order,并返回计算出的最大折扣。
示例 10-6 很简单:promos是一个函数列表。一旦您习惯于函数是一等对象的概念,自然而然地会发现构建包含函数的数据结构通常是有意义的。
尽管示例 10-6 有效且易于阅读,但存在一些重复代码可能导致微妙的错误:要添加新的促销策略,我们需要编写该函数并记得将其添加到promos列表中,否则新的促销将在显式传递给Order时起作用,但不会被best_promotion考虑。
继续阅读解决此问题的几种解决方案。
在模块中查找策略
Python 中的模块也是头等对象,标准库提供了几个函数来处理它们。Python 文档中对内置的globals描述如下:
globals()
返回表示当前全局符号表的字典。这始终是当前模块的字典(在函数或方法内部,这是定义它的模块,而不是调用它的模块)。
示例 10-7 是一种有些巧妙的使用globals来帮助best_promo自动找到其他可用的*_promo函数的方法。
示例 10-7。promos列表是通过检查模块全局命名空间构建的
from decimal import Decimal
from strategy import Order
from strategy import (fidelity_promo, bulk_item_promo, large_order_promo # ①
)promos = promo for name, promo in globals().items() ![2 if name.endswith('_promo') and # ③name != 'best_promo' # ④
]def best_promo(order: Order) -> Decimal: # ⑤"""Compute the best discount available"""return max(promo(order) for promo in promos)
①
导入促销函数,以便它们在全局命名空间中可用。⁶
②
遍历 globals() 返回的 dict 中的每个项目。
③
仅选择名称以 _promo 结尾的值,并…
④
…过滤掉 best_promo 本身,以避免在调用 best_promo 时出现无限递归。
⑤
best_promo 没有变化。
收集可用促销的另一种方法是创建一个模块,并将所有策略函数放在那里,除了 best_promo。
在 示例 10-8 中,唯一的显著变化是策略函数列表是通过内省一个名为 promotions 的单独模块构建的。请注意,示例 10-8 依赖于导入 promotions 模块以及提供高级内省函数的 inspect。
示例 10-8. promos 列表通过检查新的 promotions 模块进行内省构建
from decimal import Decimal
import inspectfrom strategy import Order
import promotionspromos = [func for _, func in inspect.getmembers(promotions, inspect.isfunction)]def best_promo(order: Order) -> Decimal:"""Compute the best discount available"""return max(promo(order) for promo in promos)
函数 inspect.getmembers 返回对象的属性—在本例中是 promotions 模块—可选择通过谓词(布尔函数)进行过滤。我们使用 inspect.isfunction 仅从模块中获取函数。
示例 10-8 不受函数名称的影响;重要的是 promotions 模块只包含计算订单折扣的函数。当然,这是代码的一个隐含假设。如果有人在 promotions 模块中创建一个具有不同签名的函数,那么在尝试将其应用于订单时,best_promo 将会出错。
我们可以添加更严格的测试来过滤函数,例如检查它们的参数。示例 10-8 的重点不是提供一个完整的解决方案,而是强调模块内省的一个可能用法。
一个更明确的动态收集促销折扣函数的替代方法是使用一个简单的装饰器。接下来就是这个。
装饰器增强策略模式
回想一下我们对 示例 10-6 的主要问题是在函数定义中重复函数名称,然后在 promos 列表中重复使用这些名称,供 best_promo 函数确定适用的最高折扣。重复是有问题的,因为有人可能会添加一个新的促销策略函数,并忘记手动将其添加到 promos 列表中——在这种情况下,best_promo 将悄悄地忽略新策略,在系统中引入一个微妙的错误。示例 10-9 使用了 “注册装饰器” 中介绍的技术解决了这个问题。
示例 10-9. promos 列表由 Promotion 装饰器填充
Promotion = Callable[[Order], Decimal]promos: list[Promotion] = [] # ①def promotion(promo: Promotion) -> Promotion: # ②promos.append(promo)return promodef best_promo(order: Order) -> Decimal:"""Compute the best discount available"""return max(promo(order) for promo in promos) # ③@promotion # ④
def fidelity(order: Order) -> Decimal:"""5% discount for customers with 1000 or more fidelity points"""if order.customer.fidelity >= 1000:return order.total() * Decimal('0.05')return Decimal(0)@promotion
def bulk_item(order: Order) -> Decimal:"""10% discount for each LineItem with 20 or more units"""discount = Decimal(0)for item in order.cart:if item.quantity >= 20:discount += item.total() * Decimal('0.1')return discount@promotion
def large_order(order: Order) -> Decimal:"""7% discount for orders with 10 or more distinct items"""distinct_items = {item.product for item in order.cart}if len(distinct_items) >= 10:return order.total() * Decimal('0.07')return Decimal(0)
①
promos 列表是一个模块全局变量,并且初始为空。
②
Promotion 是一个注册装饰器:它返回未更改的 promo 函数,并将其附加到 promos 列表中。
③
best_promo 不需要更改,因为它依赖于 promos 列表。
④
任何被 @promotion 装饰的函数都将被添加到 promos 中。
这种解决方案比之前提出的其他解决方案有几个优点:
-
促销策略函数不必使用特殊名称—不需要
_promo后缀。 -
@promotion装饰器突出了被装饰函数的目的,并且使得暂时禁用促销变得容易:只需注释掉装饰器。 -
促销折扣策略可以在系统中的任何其他模块中定义,只要对它们应用
@promotion装饰器。
在下一节中,我们将讨论命令——另一个设计模式,有时通过单方法类实现,而普通函数也可以胜任。
命令模式
命令是另一个设计模式,可以通过将函数作为参数传递来简化。图 10-2 显示了命令模式中类的排列。
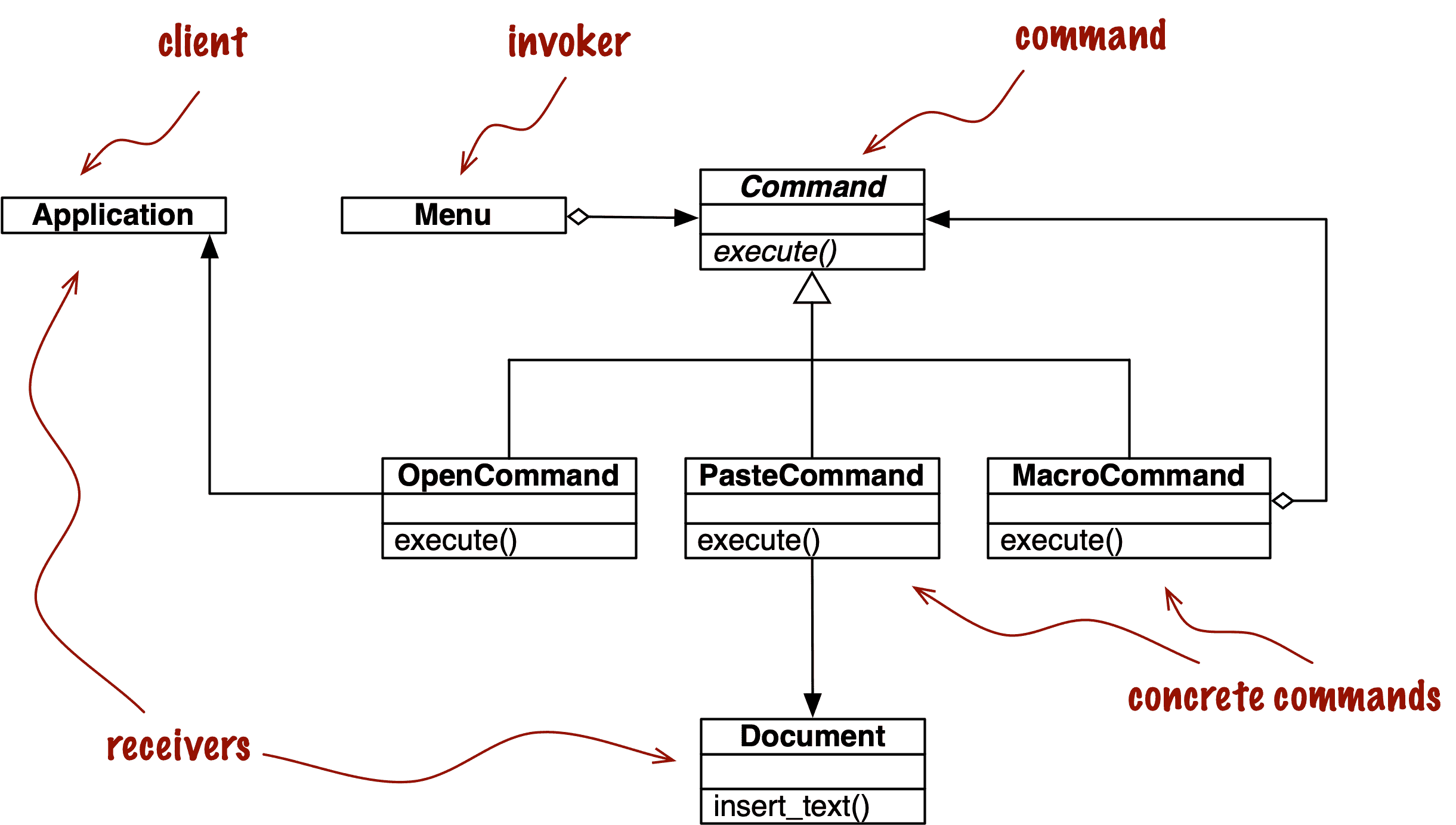
图 10-2。使用命令设计模式实现的菜单驱动文本编辑器的 UML 类图。每个命令可能有不同的接收者:实现动作的对象。对于PasteCommand,接收者是文档。对于OpenCommand,接收者是应用程序。
命令的目标是将调用操作的对象(调用者)与实现它的提供对象(接收者)解耦。在《设计模式》中的示例中,每个调用者是图形应用程序中的菜单项,而接收者是正在编辑的文档或应用程序本身。
思路是在两者之间放置一个Command对象,实现一个具有单个方法execute的接口,该方法调用接收者中的某个方法执行所需的操作。这样,调用者不需要知道接收者的接口,不同的接收者可以通过不同的Command子类进行适配。调用者配置具体命令并调用其execute方法来操作它。请注意,在图 10-2 中,MacroCommand可以存储一系列命令;其execute()方法调用存储的每个命令中的相同方法。
引用自《设计模式》,“命令是回调的面向对象替代品。”问题是:我们是否需要回调的面向对象替代品?有时是,但并非总是。
我们可以简单地给调用者一个函数,而不是给一个Command实例。调用者可以直接调用command(),而不是调用command.execute()。MacroCommand可以用实现__call__的类来实现。MacroCommand的实例将是可调用对象,每个对象都保存着未来调用的函数列表,就像在示例 10-10 中实现的那样。
示例 10-10。每个MacroCommand实例都有一个内部命令列表
class MacroCommand:"""A command that executes a list of commands"""def __init__(self, commands):self.commands = list(commands) # ①def __call__(self):for command in self.commands: # ②command()
①
从commands参数构建列表确保它是可迭代的,并在每个MacroCommand实例中保留命令引用的本地副本。
②
当调用MacroCommand的实例时,self.commands中的每个命令按顺序调用。
命令模式的更高级用法——支持撤销,例如——可能需要更多于简单回调函数的内容。即使如此,Python 提供了几种值得考虑的替代方案:
-
像示例 10-10 中的
MacroCommand一样的可调用实例可以保持必要的任何状态,并提供除__call__之外的额外方法。 -
闭包可以用来在函数调用之间保存内部状态。
这里我们重新思考了使用一等函数的命令模式。在高层次上,这里的方法与我们应用于策略模式的方法类似:用可调用对象替换实现单方法接口的参与者类的实例。毕竟,每个 Python 可调用对象都实现了单方法接口,而该方法被命名为__call__。
章节总结
正如 Peter Norvig 在经典《设计模式》书籍出现几年后指出的,“23 个模式中有 16 个模式在 Lisp 或 Dylan 中的某些用法上比在 C++ 中具有质量上更简单的实现”(Norvig 的 “动态语言中的设计模式”演示文稿第 9 页)。Python 共享 Lisp 和 Dylan 语言的一些动态特性,特别是一流函数,这是我们在本书的这部分关注的重点。
从本章开头引用的同一次演讲中,在反思《设计模式:可复用面向对象软件的元素》20 周年时,Ralph Johnson 表示该书的一个失败之处是:“过分强调模式作为设计过程中的终点而不是步骤。”⁷ 在本章中,我们以策略模式作为起点:一个我们可以使用一流函数简化的工作解决方案。
在许多情况下,函数或可调用对象提供了在 Python 中实现回调的更自然的方式,而不是模仿 Gamma、Helm、Johnson 和 Vlissides 在《设计模式》中描述的策略或命令模式。本章中策略的重构和命令的讨论是更一般洞察的例子:有时你可能会遇到一个设计模式或一个需要组件实现一个具有单一方法的接口的 API,而该方法具有一个泛泛的名称,如“execute”、“run”或“do_it”。在 Python 中,这种模式或 API 通常可以使用函数作为一流对象来实现,减少样板代码。
进一步阅读
在《Python Cookbook,第三版》中,“配方 8.21 实现访问者模式”展示了一个优雅的访问者模式实现,其中一个 NodeVisitor 类处理方法作为一流对象。
在设计模式的一般主题上,Python 程序员的阅读选择并不像其他语言社区那样广泛。
Learning Python Design Patterns,作者是 Gennadiy Zlobin(Packt),是我见过的唯一一本完全致力于 Python 中模式的书。但 Zlobin 的作品相当简短(100 页),涵盖了原始 23 个设计模式中的 8 个。
Expert Python Programming,作者是 Tarek Ziadé(Packt),是市场上最好的中级 Python 书籍之一,其最后一章“有用的设计模式”从 Python 视角呈现了几个经典模式。
Alex Martelli 关于 Python 设计模式的几次演讲。有他的一个 EuroPython 2011 演讲视频 和一个 他个人网站上的幻灯片集。多年来我发现了不同长度的幻灯片和视频,所以值得彻底搜索他的名字和“Python 设计模式”这几个词。一位出版商告诉我 Martelli 正在撰写一本关于这个主题的书。当它出版时,我一定会买。
在 Java 上下文中有许多关于设计模式的书籍,但其中我最喜欢的是Head First Design Patterns,第二版,作者是埃里克·弗里曼和伊丽莎白·罗布森(O’Reilly)。它解释了 23 个经典模式中的 16 个。如果你喜欢Head First系列的古怪风格,并需要对这个主题有一个介绍,你会喜欢这部作品。它以 Java 为中心,但第二版已经更新,以反映 Java 中添加了一流函数,使得一些示例更接近我们在 Python 中编写的代码。
从动态语言的角度,具有鸭子类型和一流函数的视角重新审视模式,《Design Patterns in Ruby》作者是 Russ Olsen(Addison-Wesley)提供了许多见解,这些见解也适用于 Python。尽管它们在语法上有许多差异,在语义层面上,Python 和 Ruby 更接近于彼此,而不是 Java 或 C++。
在“动态语言中的设计模式”(幻灯片)中,彼得·诺维格展示了头等函数(和其他动态特性)如何使原始设计模式中的一些模式变得更简单或不再必要。
原著设计模式书的介绍由 Gamma 等人撰写,其价值超过了书中的 23 种模式目录,其中包括从非常重要到很少有用的配方。广为引用的设计原则,“针对接口编程,而不是实现”和“优先使用对象组合而非类继承”,都来自该介绍部分。
将模式应用于设计最初源自建筑师克里斯托弗·亚历山大等人,在书籍模式语言(牛津大学出版社)中展示。亚历山大的想法是创建一个标准词汇,使团队在设计建筑时能够共享共同的设计决策。M. J. 多米努斯撰写了“‘设计模式’并非如此”,一个引人入胜的幻灯片和附录文本,论证了亚历山大原始模式的愿景更加深刻,更加人性化,也适用于软件工程。
¹ 来自拉尔夫·约翰逊在 IME/CCSL,圣保罗大学,2014 年 11 月 15 日展示的“设计模式中一些故障的根本原因分析”演讲中的幻灯片。
² 引自设计模式第 4 页。
³ 由于 Mypy 中的一个错误,我不得不使用@dataclass重新实现Order。您可以忽略这个细节,因为这个类与NamedTuple一样工作,就像示例 10-1 中一样。如果Order是一个NamedTuple,当检查promotion的类型提示时,Mypy 0.910 会崩溃。我尝试在特定行添加# type ignore,但 Mypy 仍然崩溃。如果使用@dataclass构建Order,Mypy 会正确处理相同的类型提示。截至 2021 年 7 月 19 日,问题#9397尚未解决。希望在您阅读此文时已经修复。
⁴ 请参阅设计模式第 323 页。
⁵ 同上,第 196 页。
⁶ flake8 和 VS Code 都抱怨这些名称被导入但未被使用。根据定义,静态分析工具无法理解 Python 的动态特性。如果我们听从这些工具的每一个建议,我们很快就会用 Python 语法编写冗长且令人沮丧的类似 Java 的代码。
⁷ “设计模式中一些故障的根本原因分析”,由约翰逊在 IME-USP 于 2014 年 11 月 15 日展示。


)








)




子数组最大累加和,子矩阵最大累加和)


