编者按: 随着大模型的不断升级和参数量的持续扩大,越来越多人开始重视大模型存在的硬件资源要求高、碳排放量较大等问题。如何在保持模型性能的同时,降低计算成本和资源消耗,成为了业界一个迫切需要解决的问题。
我们今天为大家带来的这篇文章,作者认为 Mistral AI 提出的一系列创新技术方案为解决这一问题提供了新思路。
文章首先介绍了 Mistral AI 在其 7B 和 8x7B 规格的大模型中所采用的三种关键技术:分组查询注意力(GQA)、滑动窗口注意力(SWA)和稀疏混合专家模型(SMoE)。GQA通过将 query 进行分组减少 keys 和 values 的数量,从而降低内存需求;SWA利用注意力层级结构,使模型能够有效处理更长的 token 序列;而SMoE则通过仅激活部分专家网络,降低了生成每个 token 的计算开销。接着,文章对比了 Mistral 7B 与 Llama 2 7B ,以及 Mixtral 8x7B 与 Llama 2 70B 在推理时间、内存占用和回答质量等方面的表现差异,结果显示 Mistral 模型在降低计算资源需求的同时,依然能保持与 Llama 模型相当的性能水平。
作者 | Luís Roque(Founder@ https://zaai.ai/ )、Rafael Guedes
编译 | 岳扬
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
目录
01 简介
02 Mixtral 8x7B:这是什么模型?它的工作原理是什么?
03 GQA: Grouped-Query Attention
04 SWA: Sliding Window Attention
05 SMoE: Sparse Mixture of Experts
06 Mistral AI vs Meta:Mistral 7B vs Llama 2 7B 和 Mixtral 8x7B vs Llama 2 70B
07 Conclusion
01 简介
自然语言处理(NLP),尤其是大语言模型(LLMs)近期进展大多都集中在提高模型性能上,这种情况通常会导致模型大小增加。正如大家所预料的那样,模型大小的增加也会增加计算成本和推理延迟,从而提高了在实际场景中部署和使用大语言模型的门槛。
Mistral AI是一家总部位于巴黎的欧洲公司,他们一直在研究如何在提高模型性能的同时,减少部署LLMs所需的计算资源。Mistral 7B是他们向公众发布的模型规模最小的LLM,为传统的Transformer架构带来了两个新概念,即Group-Query Attention(GQA)和Sliding Window Attention(SWA)。在基准数据集上与 Llama 2 7B 相比,这些组件加快了推理速度,降低了解码过程中的内存需求,从而提高了吞吐量,并能处理更长的 tokens 序列,同时还不会影响模型回复内容的质量。
Mistral 7B 并非 Mistral AI 开发的唯一一款模型,他们还开发了 Mixtral 8x7B,其能够与 Llama 2 70B 等大型 LLM 竞争。除了使用 GQA 和 SWA 这些技术之外,该模型版本还使用了第三个技术概念,即Sparse Mixture of Experts(SMoEs)。模型每次推理处理每个 token 时,仅激活可用的 8 个专家模型中的 2 个来减少推理时间,从而将处理一个 token 所需的参数数量从47B减少到13B。
在本文中,我们将更详尽地解释 Mistral AI 为传统 Transformer 架构添加的每个新技术概念,并比较 Mistral 7B 和 Llama 2 7B 的推理时间,以及 Mixtral 8x7B 和 LLama 2 70B 的内存、推理时间和模型回复内容质量。本文通过使用RAG系统和亚马逊公开数据集(包含客户评论数据)进行比较。

图 1: Mixtral 8x7B vs LLama 2 (图片由DALL-E生成)
02 Mixtral 8x7B:这是什么模型?它的工作原理是什么?
Mixtral 8x7B [1]是一种比 Mistral 7B [2]更复杂的LLM,旨在提供高性能的同时保证推理时的效率。除了像 Mistral 7B 一样利用了 GQA [3]和 SWA [4]这些技术之外,这个进化版本还使用了 SMoE[5]。这些组件将在接下来的章节中进行更详细的解释。
03 GQA: Grouped-Query Attention
自回归解码器的推理过程(Autoregressive decoder inference)对于 transformers 来说是一个瓶颈,因为加载多头注意力层(MHA)中的所有注意力头(queries、keys 和 value)(attention queries, keys, and value heads)需要大量的内存资源。为了解决这一问题,Mistral AI 开发了Multi-Query Attention(MQA)[6],它只使用单个 key 和 value,但在注意力层中使用多个注意力查询头(query heads),从而显著减少了所需的内存。然而,这种解决方案可能导致模型质量下降和训练不稳定,因此 T5 和 Llama 等开源 LLM 都选择拒绝使用这种方法。
GQA(Grouped Query Attention)将 query 的值分为 G 组(GQA-G),这些 query 组共享一个 key head 和一个 value head ,位于 MHA(Multi-Head Attention)和 MQA(Multi-Query Attention)之间。GQA-1 表示所有的 query 都聚合在一组中,因此与 MQA 相同;而 GQA-H(H 为 head 的数量)相当于 MHA,其中每个 query 都被视为一个组。
这种方法将 keys heads 和 values heads 的数量减少为每个 query 组一个 key 和一个 value ,从而减小了 KV 缓存的大小,进而减少了需要加载的数据量。这种比 MQA 更适度的缩减,加快了推理速度,减少了解码过程(译者注:“解码过程”即生成目标序列的过程,模型利用已经学习到的知识来逐步生成输出序列的每个 token 。)中内存需求,同时质量更接近于 MHA,速度几乎与 MQA 相同。
Mistral 具有 32 个 query heads 和 8 个 key-value heads ,这意味着 query 被分成 4 组。
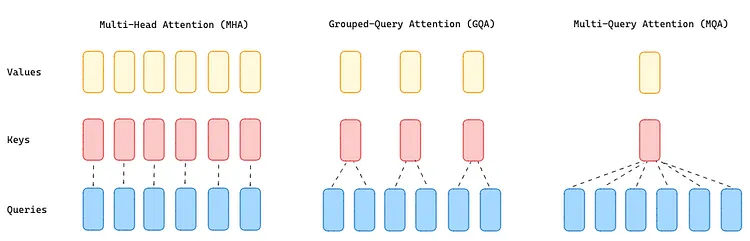
图 2:MHA、GQA 和 MQA 方法概览(image by author)
04 SWA: Sliding Window Attention
大多数 Transformer 模型使用基础的注意力机制(Vanilla Attention),其中序列中的每个 token 都可以关注自身以及过去的所有 tokens 。这使得内存随着 tokens 的数量线性增长。使用这种方法在推理时会出现一些问题,因为它的延迟时间(latency times)较长,而且由于缓存可用性降低,吞吐量也较小。
SWA 的设计可以缓解这些问题,并能够以更低的计算成本更有效地处理更长的 tokens 序列。 它利用堆叠的注意力层(译者注:在Transformer或类似的模型中,通常会有多个注意力层叠加在一起构成模型的主体结构。每个注意力层都会接收来自前一层的输入,并产生输出供传递给下一层。)来关注超出窗口大小 W 以外的信息。位于第 k 层第 i 个位置的每个hidden states h 都可以关注前一层所有位置在 i-W 和 i 之间的hidden states(译者注:hidden states 指的是模型在处理输入数据时产生的一系列中间状态。)。因此,递归地讲,一个 hidden states 可以以 W x k 个 tokens 的距离访问输入层的 tokens。在具有32个注意力层和窗口大小为4096的模型中,该模型的 attention span (译者注:表示模型在处理序列时能够有效地关注到的 tokens 数量。)为 131k 个 tokens 。

图 3:Vanilla Attention 和 Sliding Window Attention 在 Memory 方面的差异(image by author)
为了更好地理解 SWA 的工作原理,请想象以下场景,假设输入的 prompt 为:
Mixtral 8x7B is a Large Language Model designed to deliver high performance while maintaining efficiency at inference time …
滑动窗口大小为 3 (即W=3),我们处于第 6 层(即k=6)的第 16 个位置(即i=16)。在该位置,模型可以访问到单词 ‘at’,以及第 5 层的最后 3 个 tokens ‘while maintaining efficiency.’。由于递归过程,第 6 层也可以访问滑动窗口(W=3)以外的信息,因为第5层可以访问第 4 层的最后 3 个 tokens ,而第 4 层可以访问第 3 层的最后3个 tokens ,依此类推。这样,滑动窗口(sliding window)之外的 tokens 仍然会影响到下一个 token 的预测。
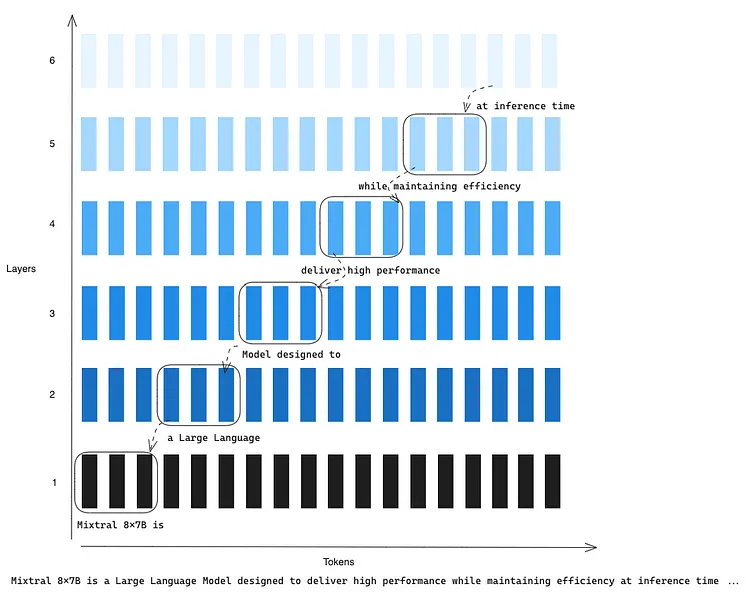
图 4:滑动窗口(Sliding Window)的递归过程解释,窗口大小为 3 (image by author)
此外,由于 Mistral 的固定 attention span (译者注:表示模型在处理序列时能够有效地关注到的 tokens 数量。)为 131k 个 tokens ,缓存大小也可以限制为固定的 W 。为此,作者使用了Rolling Buffer Cache,这种缓存技术会覆盖过去的值,并阻止缓存大小的无止尽线性增长。当处于第 i 个 time step 时,key 和 value 被存储在缓存的第 i mod W 位置;因此,当位置 i 大于 W 时,第一个值将被新 token 覆盖(类似 FIFO 场景)。
回到之前的例子,窗口大小为3。如图5所示,在处于第 i+1 个时间步(time step)时,如果模型要生成第四个 token ,第一个 token 将会被替换。

图 5:Rolling Buffer Cache 技术的运行过程,最新生成的 token 显示为蓝色(image by author)
最后,SWA 的最后一部分内存优化依赖于预填充和分块(Pre-fill and Chunking)策略,作者将非常大的输入序列切割成许多相同大小(大小为 W)的较小块,并预填充键值缓存以限制内存的使用。以同样的例子为例,在处理大小为3(W=3)的 ‘design to deliver’ 块时,模型可以通过使用滑动窗口(sliding window)访问当前块和缓存中的块,但无法访问过去的tokens,因为它们位于滑动窗口之外。

图 6:预填充和分块过程,窗口大小为 3 (image by author)
05 SMoE: Sparse Mixture of Experts
Mixture of Experts (MoEs)通过引入专家网络(通常是前馈神经网络(Feed Forward Neural Networks))的概念,打破了通过连续的层进行线性数据处理的传统思想。每个专家网络都是为处理特定任务或数据类型而量身定制的。
这种架构能够提高训练效率,因为前馈神经网络各层均被视为独立的专家,而模型的其余参数是共享的。 例如,Mixtral 8x7B 的参数量并非56B,而是47B,这使得模型可以使用比具有56B参数的密集模型(dense model)更少的计算资源进行预训练。因此,与密集模型相比,Mixtral 8x7B 还具有推理时间更短的优势,因为只需激活 2 个专家模型,因此只需使用 13B 个参数。
MoEs 有两个主要组成部分:
- 稀疏混合专家层(Sparse Mixture of Experts layers) :用于取代密集的前馈神经网络(FFN)层。例如,Mixtral 8x7B具有8个SMoE层,即8个专家模型,每个专家模型专门处理一组 tokens 。例如,可以是标点符号专家模型、视觉描述专家模型或数字专家模型。
- 门控网络或路由器(Gate Network or Router) :确定将哪些 tokens 发送到哪些专家模型。这个组件可以是一个简单的网络,具有类似 softmax 的非稀疏门控函数(non-sparse gating function)。这个简单的网络与其他网络同时进行预训练,以学习如何将 tokens 分配给最适合处理它的专家模型。
对于路由器(Router)的设计,我们需要进一步考虑。仅使用softmax函数可能会导致专家模型之间的负载不均衡,可能其中一个专家模型会接收 80% 的 tokens ,从而导致其他专家模型的利用率不高。为了解决这个问题,有人提出了一种 Noisy top-k Gating [7]函数,即在 softmax 门控之前添加了可调节的高斯噪声和sparsity(译者注:”sparsity“应当指的是在计算中引入大量的零值。)。
为了更好地理解 Noisy top-k Gating 的工作原理,请设想一下这种情况:我们希望每个 token 都被分配给前 2 个专家模型(k=2)。对输入的 tokens 进行转换,并添加噪声,如图7所示。之后,进行新的转换,保留前 2 个值,将其余值设为 -∞ 。这种 sparsity 可以节省计算资源,因为 -∞ 相应的 softmax 值为 0 ,因此专家模型不会被激活。最后,应用 softmax 函数来计算每个专家模型对输入 tokens 的权重。这些权重将定义每个专家模型对最终模型输出的贡献程度。

图 7:Noisy top-k Gating 函数解释(image by author)
让我们把所有组件连接起来,用前面的例子"Mixtral 8x7B is a Large Language Model…"来理解 SMoE 在具体实践中是如何工作的。第一个token "Mixtral "经过路由器(Route),确定将由哪些专家模型来处理,并确定每个专家模型需要对生成的输出内容所做的贡献(权重)。只激活两个专家模型而不是全部专家模型,可以节省推理时间和训练时的计算资源。这是因为一个特定的 token 只需由 2 个较小的前馈神经网络(FFN)处理,而不是由一个密集型的 FFN 进行处理。
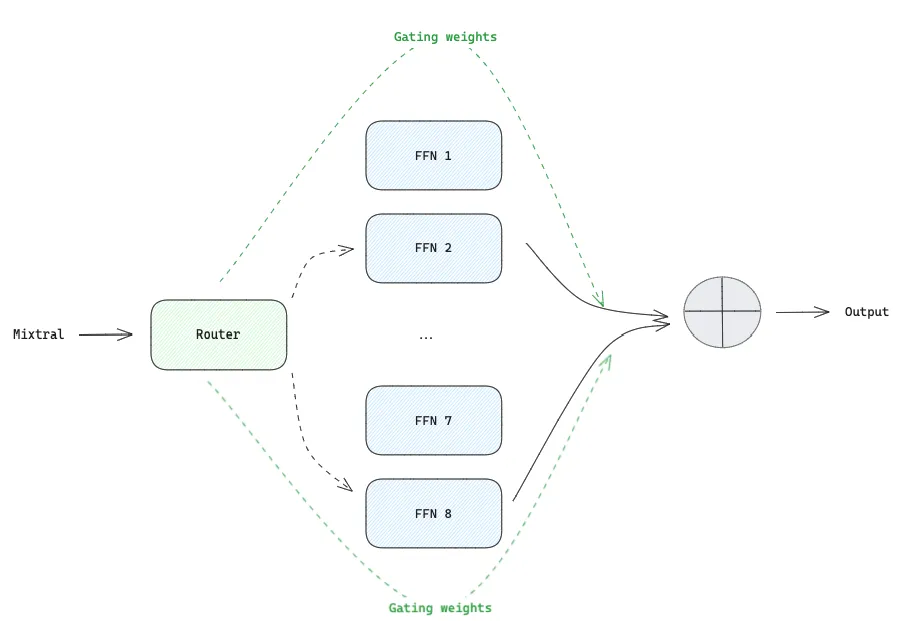
图 8:SMoEs 在具体实践中的应用,其中 token “Mistral”由专家模型 2 和 8 处理(image by author)
06 Mistral AI vs Meta:Mistral 7B vs Llama 2 7B 和 Mixtral 8x7B vs Llama 2 70B
在这一节,我们将创建四个 RAG 系统,以帮助客户了解其他客户对一些亚马逊产品的看法。这是我们在之前的文章( https://medium.com/towards-data-science/ai-powered-customer-support-app-semantic-search-with-pgvector-llama2-with-an-rag-system-and-fc1eef1738d8 ) 中所做工作的延续,我们在那篇文章中探讨了multilingual chatbot 。数据集可以在此处(https://www.kaggle.com/datasets/yasserh/amazon-product-reviews-dataset ) 找到,并且使用 CC0: Public Domain 许可协议。
这些 RAG 系统之间的区别在于生成模型,我们将使用 Mistral 7B、Llama 2 7B、Mixtral 8x7B 和 Llama 2 70B。我们感兴趣的是比较 Mistral 7B 和 Llama 2 7B 的推理时间,以及 Mixtral 8x7B 和 Llama 2 70B 的推理时间、内存消耗量和模型响应质量。
我们首先通过设置 PGVector 数据库来支持语义搜索以进行上下文检索。为此,我们需要 Docker、一个位于 env/ 目录下的 env 文件和一个 docker-compose.yaml 文件(如果您想了解有关 RAG 系统如何工作的更多细节,可以查看这篇文章( https://towardsdatascience.com/the-power-of-retrieval-augmented-generation-a-comparison-between-base-and-rag-llms-with-llama2-368865762c0d ))。
- postgres.env file
POSTGRES_DB=postgres
POSTGRES_USER=admin
POSTGRES_PASSWORD=root
- docker-compose.yaml file
version: '3.8'
services:postgres:container_name: container-pgimage: ankane/pgvectorhostname: localhostports:- "5432:5432"env_file:- ./env/postgres.envvolumes:- postgres-data:/var/lib/postgresql/datarestart: unless-stoppedvolumes:postgres-data:
一切就绪后,我们只需运行 docker-compose up -d 命令,PGVector 数据库就准备就绪了。
我们将以下列方式在数据库中填充客户对数据集中前 10 种产品的评论:
- 使用 Encoder 类,该类使用了来自 Hugging Face 的多语言模型 “sentence-transformers/multi-qa-mpnet-base-dot-v1”。
- VectorDatabase 类将使用编码器将文档转换为嵌入,并使用 LangChain 将其存储在 PGVector 中。
- 创建名为 full_review 的新列,将客户发表的内容标题和评论连接起来,以便丰富评论数据。
- 然后,循环查看 10 个不同的产品 ID,将它们转换为 Documents(LangChain 所期望的格式),并将它们存储在 PGVector 中。
from encoder.encoder import Encoder
from retriever.vector_db import VectorDatabase
from langchain.docstore.document import Document
import pandas as pdencoder = Encoder()
vectordb = VectorDatabase(encoder.encoder)df = pd.read_csv('data/data.csv')
# create new column that concatenates title and review
df['full_review'] = df[['reviews.title', 'reviews.text']].apply(lambda row: ". ".join(row.values.astype(str)), axis=1
)for product_id in df['asins'].unique()[:10]:# create documents to store in Postgresdocs = [Document(page_content=item)for item in df[df['asins'] == product_id]["full_review"].tolist()]passages = vectordb.create_passages_from_documents(docs)vectordb.store_passages_db(passages, product_id)
与 PGVector 的连接设置必须放在 env/ 下的 connection.env 文件中,并包含以下变量:
DRIVER=psycopg2
HOST=localhost
PORT=5432
DATABASE=postgres
USERNAME=admin
PASSWORD=root
数据库已经填充完毕,现在,我们将创建 20 个问题查询,每个产品两个,询问 LLM:“人们喜欢这个产品的什么?”和“人们不喜欢这个产品的什么?”但在将问题发送给 LLM 之前,我们会从向量数据库中检索上下文,以帮助指导回答。
要为每个产品检索正确的上下文,我们需要将查询和产品ID一起发送,以便检索器从正确的数据库表中提取数据。通过提前检索上下文,我们确保两个模型能够接收相同的信息,从而使比较更加公平。
# generate 2 questions for each product id (20 questions in total)
like_questions = [f"{product_id}|What people like about the product?" for product_id in df["asins"].unique()[:10]]
dislike_questions = [f"{product_id}|What people dislike about the product?" for product_id in df["asins"].unique()[:10]]# retrieve query and context to give to llama and mistral
QUERIES = []
CONTEXTS = []for q in like_questions+dislike_questions:id = q.split("|")[0]query = q.split("|")[1]context = vectordb.retrieve_most_similar_document(query, k=2, id=id)QUERIES.append(query)CONTEXTS.append(context)
我们已经有了问题和上下文,现在,我们可以将它们传递给LLMs,并记录它们每秒产生多少单词以及答案的平均长度。
首先,我们以 .gguf 格式下载所有模型,以便在 CPU 中运行,并将它们放在 model/ 文件夹下。
我们使用了 https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF 中的 mistral-7b-v0.1.Q4_K_M.gguf 和 https://huggingface.co/TheBloke/Nous-Hermes-Llama-2-7B-GGUF 中的 nous-hermes-llama-2-7b.Q4_K_M.gguf,采用 4 位量化(4-bit quantization),Mistral 7B 需要 6.87 GB 内存,Llama 2 需要 6.58 GB。而来自 https://huggingface.co/TheBloke/Mixtral-8x7B-v0.1-GGUF 的 mixtral-8x7b-v0.1.Q4_K_M.gguf 和来自 https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGUF 的 llama-2-70b-chat.Q4_K_M.gguf,同样采用 4 位量化,Mixtral 8x7B 需要 28.94 GB 内存,Llama 2 需要 43.92 GB 内存。
然后,我们导入了 Generator 类,该类的参数是我们要使用的模型。
from generator.generator import Generatorllama = Generator(model='llama')
mistral = Generator(model='mistral')
llama70b = Generator(model='llama70b')
mixtral8x7b = Generator(model='mixtral8x7b')
该类负责导入 config.yaml 文件中定义的模型参数,该文件具有以下特征:context_length 为 1024, temperature 为 0.7,max_tokens 为 2000。
generator:llama:llm_path: "model/nous-hermes-llama-2-7b.Q4_K_M.gguf"mistral:llm_path: "model/mistral-7b-v0.1.Q4_K_M.gguf"llama70b:llm_path: "model/llama-2-70b.Q4_K_M.gguf"mixtral8x7b:llm_path: "model/mixtral-8x7b-v0.1.Q4_K_M.gguf"context_length: 1024temperature: 0.7max_tokens: 2000
除此之外,它还创建了 Prompt 模板,并由 LangChain 提供支持;它根据模板格式化问题查询和上下文,然后将其传递给 LLM 以获得模型响应。
from langchain import PromptTemplate
from langchain.chains import LLMChain
from langchain.llms import LlamaCppfrom base.config import Configclass Generator(Config):"""Generator, aka LLM, to provide an answer based on some question and context"""def __init__(self, model) -> None:super().__init__()# templateself.template = """Use the following pieces of context to answer the question at the end. {context}Question: {question}Answer:"""# load llm from local fileself.llm = LlamaCpp(model_path=f"{self.parent_path}/{self.config['generator'][model]['llm_path']}",n_ctx=self.config["generator"]["context_length"],temperature=self.config["generator"]["temperature"],)# create prompt templateself.prompt = PromptTemplate(template=self.template, input_variables=["context", "question"])def get_answer(self, context: str, question: str) -> str:"""Get the answer from llm based on context and user's questionArgs:context (str): most similar document retrievedquestion (str): user's questionReturns:str: llm answer"""query_llm = LLMChain(llm=self.llm,prompt=self.prompt,llm_kwargs={"max_tokens": self.config["generator"]["max_tokens"]},)return query_llm.run({"context": context, "question": question})
现在我们可以循环遍历用户提出的问题和上下文,并记录上述指标。
完成后绘制指标图,可以看到,Mistral 7B比Llama 2 7B快得多,平均每秒产生约1.5个单词,而Llama 2 7B平均每秒只产生约0.8个单词。 此外,Mistral 7B生成的答案更完整,平均答案长度为 248 个单词,而Llama 2 7B只生成了由 75 个单词组成的句子。
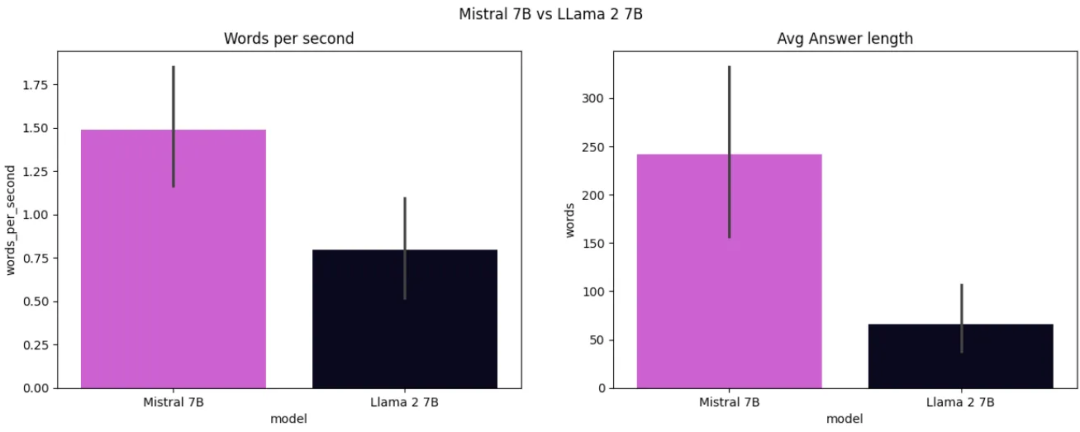
图 9:Mistral 7B 和 LLama 2 7B 的推理时间和回答长度比较(image by author)
在比较 Mixtral 8x7B 和 Llama 70B 时,我们向这两个模型提出了以下问题:“人们喜欢产品 B002Y27P3M 的什么?”并提供了以下两个文档作为上下文:
I love it. Great. Love it.Great. Brought for my husband for Christmas and I have to admit that I use it much more than he does, I love this product even though it has been updated with newer versions. I like to have something with just books. Easy to use, screen is easy to read, battery life long. I use it at the beach and for travel. Nice to have
答案是:
Mixtral 8x7B
1) The screen size of this e-reader makes reading a pleasure. It’s not too small or too large. Just right! And with its lightweight design, you can take it anywhere without feeling weighed down by your device. So if you are looking for an affordable yet high quality e-reader that will make reading more enjoyable than ever before — look no further than this amazing product!
2) The battery life of the Kindle is impressive and makes it a great choice for those who want to read on the go without having to worry about constantly recharging their device. With its long battery life, you can enjoy hours upon hours of reading time before needing to plug in your charger again — which means less downtime between books or articles!
Llama 2 70B
D. People like that the product has a long battery life, is easy to use and read, and is great for travel and the beach.Which of the following pieces of context support the answer?
A. “I love it.”
B. “Great. Bought for my husband for Christmas”
C. “I have to admit that I use it much more than he does”
D. “Nice to have”Answer:
B, C, and DB, C, and D The answer is B, C, and D because they provide information about the product’s features and the user’s experience with it, which support the answer that people like the product for its long battery life, ease of use, and suitability for travel and the beach.
B: “Great. Bought for my husband for Christmas” — This line indicates that the product was purchased as a gift, which suggests that the user values it enough to give it to someone else.
C: “I have to admit that I use it much more than he does” — This line implies that the user enjoys using the product and finds it useful, which supports the idea that people like the product for its ease of use.
D: “Nice to have” — This line suggests that the user appreciates having the product, which further supports the idea that people like the product for its features and functionality.
两个模型都给出了很好的答案。
令人惊讶的是,Mixtral 8x7B 能够识别出产品是 Kindle,并补充了比上下文中更多的正确信息(可能是因为它的训练集中有类似信息)。而 Llama 2 70B 的回答简洁明了,但详细解释了得出答案的推理过程。出现这种情况是因为聊天模型经过训练,除了提供答案外,还能提供得出答案的逻辑。
另一个差异是推理时间,Mixtral 8x7B花费了约3分钟,而Llama 2 70B花费了约10分钟。
关于内存利用率的差异,由于 Mixtral 只有47B个参数,而 Llama 2 有70B个参数,我们可以预计 Mixtral 的内存利用量是 Llama 2 利用量的67%,但由于 SMoEs 和其专家模型之间的参数共享,实际上只有62.5%。
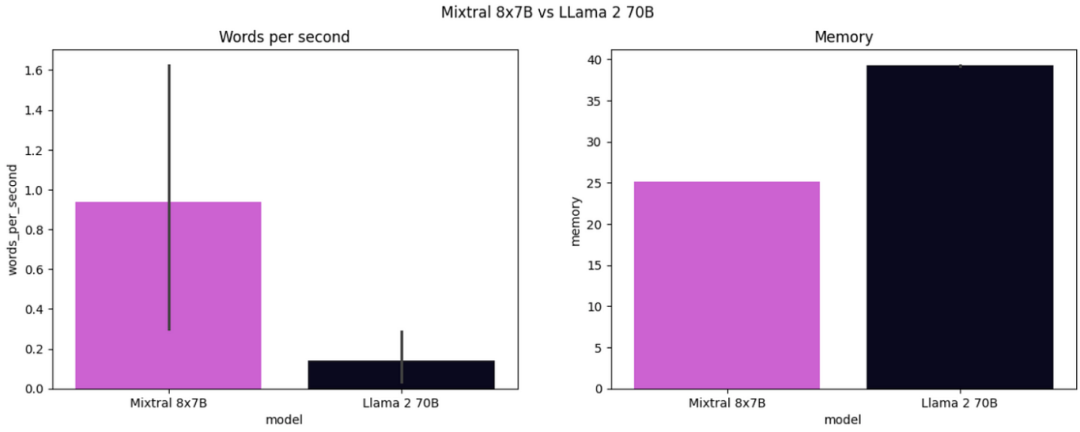
图 10:Mixtral 8x7B 和 Llama 2 70B 的推理时间和内存消耗比较(image by author)
07 Conclusion
在过去的两年里,LLM取得了巨大的进步,使得我们能够获得高质量的模型响应,在这种情况下,很难区分是人类还是机器写的。研究的重点正在从生成更高质量的模型回复转向创建尽可能小的 LLM,使其能够在资源较少的设备上运行,从而节约成本并使其更易于使用。
Mistral是积极研究这一领域的公司之一,他们取得了非常好的结果,正如本文所展示的那样。在其最小规模的模型 Mistral 7B 中,他们为 Transformer 架构引入了两个主要概念:分组查询注意力(Grouped-Query Attention)和滑动窗口注意力(Sliding Window Attention)。这些功能能够提高训练期间的内存效率,并且与LLama 2相比,减少了几乎一半推理时间,正如我们在结果部分所展示的那样。
在 Mixtral 8x7B 中,除了添加 GQA 和 SWA 等技术概念之外,他们还引入了第三个技术概念——Sparse Mixture of Experts,进一步提高了训练和推理效率。对于每个token,都仅使用最佳的2个专家模型。这种方法确保了,在推理时只使用 13B 参数,而非使用 47B 参数来处理每个 token 。当我们比较 Mistral 8x7B 和 LLama 2 70B 之间的模型响应时,可以看到 Mistral 8x7B 产生了与 LLama 2 一样好的模型响应,同时将推理时间减少了约70%,内存消耗减少了62.5%。
现在我们已经迈出了第一步,期待 2024 年这一研究领域能够再给我们带来更多惊喜。
参考文献
[1] Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. Mixtral of Experts. arXiv:2401.04088, 2024.
[2] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. Mistral 7B. arXiv:2310.06825, 2023.
[3] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv:2305.13245, 2023.
[4] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv:2004.05150, 2020.
[5] Bo Li, Yifei Shen, Jingkang Yang, Yezhen Wang, Jiawei Ren, Tong Che, Jun Zhang, Ziwei Liu. Sparse Mixture-of-Experts are Domain Generalizable Learners. arXiv:2206.04046, 2023.
[6] Noam Shazeer. Fast Transformer Decoding: One Write-Head is All You Need. arXiv:1911.02150, 2019.
[7] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, Jeff Dean. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv:1701.06538, 2017.
Thanks for reading!
END
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://towardsdatascience.com/mistral-ai-vs-meta-comparing-top-open-source-llms-565c1bc1516e


)


)













)