目录
前言
一、整数在内存中的存储
二、大小端字节序和字节序判断
2.1.练习一
2.2 练习二
2.3 练习三
2.4 练习四
2.5 练习五
2.6 练习六
三、浮点数在内存中的存储
3.1 浮点数存的过程
3.2 浮点数取的过程
总结
前言
数据在内存中根据数据类型有不同的存储方式,今天我们就来了解一下,我们常见的数据类型在内存中的存储方式。
一、整数在内存中的存储
在之前讲操作符时我们讲了整形在内存中以二进制存放:C语言操作符详解
二、大小端字节序和字节序判断
当我们知道了整形在内存中如何存储时,我们来看下面一段代码:
#include<stdio.h>int main()
{int a = 0x11223344;return 0;
}
我们发现为什么是44 33 22 11这种顺序存储的,这时我们就要引入大小端字节序的概念了。
2.1.练习一
设计一个小程序来判断当前机器的字节序
#include<stdio.h>int check_sys()
{int i = 1;return (*(char*)&i);
}
int main()
{int ret = check_sys();if (ret == 1){printf("小端\n");}else{printf("大端\n");}return 0;
}这里1在内存中存储为00000000000000000000000000000001,可以换为16进制00 00 00 01,如果是小端存储则在内存中字节序为01 00 00 00 ,所以强制类型转换为char访问一个字节就是01,如果是大端存储就是00 00 00 01,返回的就是00。

2.2 练习二
#include<stdio.h>int main()
{char a = -1;signed char b = -1;unsigned char c = -1;printf("a=%d,b=%d,c=%d", a, b, c);return 0;
}其中char类型的-1在内存中表示为11111111,所以通过%d打印后要进行整型提升变为11111111111111111111111111111111,打印出来还是-1,signed char与char类型一样。
unsigend char由于是无符号的,所以最高位不为符号位。在内存中存储图解:
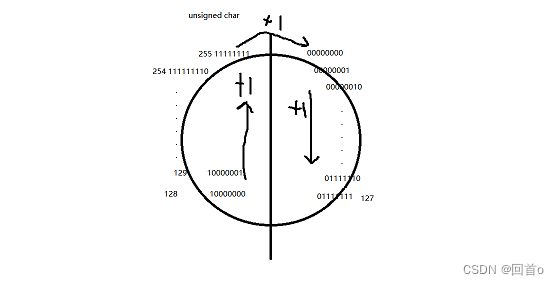
所以unsigend char类型范围为0~255。
在unsigend char中-1为11111111,与255一样,所以c输出为255。

2.3 练习三
#include <stdio.h>
int main()
{char a = -128;printf("%u\n",a);return 0;
}在char类型中,数据是有符号的所以最高位为符号位,在内存中存储图解:
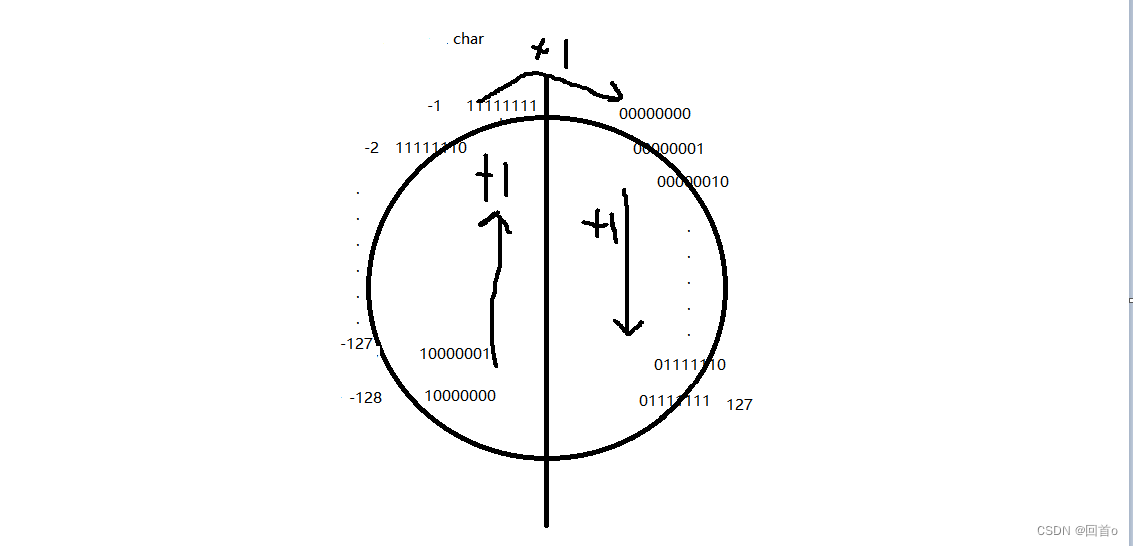
其中127+1后10000000为 -128,所以char整型范围为-128~127。
%u为通过无符号的整型打印,-128为10000000通过整型提升为1111111111111111111111110000000,由于无符号打印,所以最高位不是符号位,所以为正数,正数原反补码相同。

#include <stdio.h>
int main()
{char a = 128;printf("%u\n",a);return 0;
}128在char中存放也是10000000,所以结果通过与上面一样:

2.4 练习四
#include<stdio.h>int main()
{char a[1000];int i;for (i = 0; i < 1000; i++) {a[i] = -1 - i;}printf("%d", strlen(a));return 0;
}分析上面代码我们知道,循环-1,-2,-3,-4.....strlen遇到'\0'停止。但是数组为char类型,char类型范围为-128~127,所以到根据char类型数据存储-128时再减1就变成了127了

直到到0也就是’\0‘的ASCII值停止。结果为|-128|+127=255

2.5 练习五
#include <stdio.h>
unsigned char i = 0;
int main()
{for(i = 0;i<=255;i++){printf("hello world\n");}return 0;
}根据前面我们可知unsigned char范围为0~255,所以当i为255时,加1又变成0了,所以会无限循环代码。
同理,下面这段代码,当i=0时,减1又变成了255,所以i永远不会小于0,所以无限循环。
#include<stdio.h>int main()
{unsigned int i;for (i = 9; i >= 0; i--){printf("%u\n", i);}return 0;
}2.6 练习六
#include <stdio.h>
int main()
{int a[4] = { 1, 2, 3, 4 };int *ptr1 = (int *)(&a + 1);int *ptr2 = (int *)((int)a + 1);printf("%x,%x", ptr1[-1], *ptr2);return 0;
}下面是对代码的分析:
int main()
{int a[4] = { 1, 2, 3, 4 };//01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00 在内存中的存储int* ptr1 = (int*)(&a + 1);//&a为数组的地址,+1跳过整个数组int* ptr2 = (int*)((int)a + 1);//a为数组首地址,强制类型转换为整型,整型加1,直接加1printf("%#x,%#x", ptr1[-1], *ptr2);//ptr[-1]==*(ptr-1) ptr类型为int* ptr为数组尾地址,-1,为元素4的地址//*ptr ptr为01 后面 00的地址,ptr为int*,解引用访问四个字节 00 00 00 02,因为小端存储所以为0x2000000return 0;
}三、浮点数在内存中的存储
在了解浮点数在内存中的存储之前,我们先来看看下面一段代码:
#include <stdio.h>
int main()
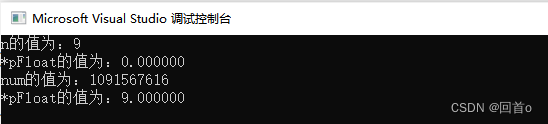
{int n = 9;float *pFloat = (float *)&n;printf("n的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);*pFloat = 9.0;printf("num的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);return 0;
}大家觉得输出结果是什么呢?
为什么会出现这样的结果呢?那让我们来了解一下浮点数在内存中的存储。
V =(−1)^S * M ∗ 2^E
• (−1)S 表⽰符号位,当S=0,V为正数;当S=1,V为负数
• M表⽰有效数字,M是⼤于等于1,⼩于2的
• 2^E表⽰指数位比如说
十进制的5.0 二进制表示为101.0 相当于1.01×2^2,此时S=0,M=1.01,E=2。
十进制的-5.0,写成⼆进制是 -101.0 ,相当于 -1.01×2^2 。那么,S=1,M=1.01,E=2。
十进制的0.5,写成二进制就是0.1 相当于1.0×2^-1,那么S=1,M=1,E=-1。


3.1 浮点数存的过程
3.2 浮点数取的过程
0 01111110 000000000000000000000002.E全为0
0 00000000 001000000000000000000003.E全为1
这时,如果有效数字M全为0,表示±无穷⼤(正负取决于符号位s);
0 11111111 00010000000000000000000了解完浮点数在内存中的存储后,我们来看看刚才的题:
#include <stdio.h>
int main()
{int n = 9;float *pFloat = (float *)&n;printf("n的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);*pFloat = 9.0;printf("num的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);return 0;
}9在内存中的存储为00000000 00000000 00000000 00001001
如果以浮点数进行存储则为0 00000000 000 0000 0000 0000 0000 1001
由于指数E全为0,所以符合E为全0的情况。因此,浮点数V就写成:
0 10000010 001 0000 0000 0000 0000 0000总结
上述文章讲了整型,浮点型在内存中的存储,和大小端的概念,希望对你有所帮助。
![使用ChatGPT高效完成简历制作[中篇]-有爱AI实战教程(五)](http://pic.xiahunao.cn/使用ChatGPT高效完成简历制作[中篇]-有爱AI实战教程(五))








)



-java+ selenium自动化测试-日历时间控件-上篇(详解教程))





