一、引言

7 月 26 日,Stability AI 发布了 SDXL 1.0,号称目前为止,最厉害的开放式图像生成大模型。

它到底有没有网上说的那么炸裂?真的已经实现了像 midjourney 一样 靠嘴出图 的功能吗?相对于之前的版本,增加了哪些新特性?
今天体验了一把,一起来看看!
二、新特性
1、清晰的文字生成
大家都知道,目前的绘画工具,对于文字生成的支持,还不是特别成熟。虽然有一些工具已经可以生成文字了,但生成的总是不太能令人满意。而 SDXL 1.0 在文字生成方面,又向前迈了一步。
比如通过短短一句提示词:a cute cat holds a paper with text "cool",professional photography,就可以生成一只拿着一张写着 “cool” 字样的小猫。

2、更好的理解人体结构
以前的 Stable Diffusino 模型,在生成正确的人体结构方面,存在着明显的问题。比如经常生成多余或者残缺的四肢,以及极度畸形的脸等等。SDXL 1.0 在一定程度上解决了这个问题。
我们都知道,AI 不擅长画手,比如之前为了生成一个正常的手,会加很多的负向提示词、Embedding 或者使用 OpenPose 等插件,而在 SDXL 1.0 中,这些通通都不需要了,或者更确切地说,就算不用这些,生成的人物也比之前的版本也要好很多。
3、自由度大幅提升

在 SDXL 1.0 之前,如果想生成不同风格的图像,必须通过改变大模型或者下载相应的 LoRA 模型来实现,而在 SDXL 1.0 中,可以通过提示词在十余种风格间做无缝切换,包括动漫、摄影、数字插画等等。
4、更短的提示词
在提示词方面,咒语变得更短、更简单了,同时增强了对自然语言的理解,大大降低了我们写提示词的门槛。
- 之前的提示词,是由一个个单词、词语、逗号等符号组成的词条化的描述,而在 SDXL 1.0 中,可以直接使用自然语言(比如一整个句子)来描述了。
- 之前的提示词,在描述的时候,除了要写生成主体、场景、环境光线等提示词之外,还需要添加例如 masterpiece、best quality、highres 等画质提示词以及大量的负面提示词。而在 SDXL 1.0 中,这些质量提示词以及负面提示词,都不需要再写了。
- 对一些概念的理解以及对环境氛围的还原更加到位了。对于概念的理解,官网给出了个例子:比如对于这两个概念 “The Red Square”(一个著名的景点)和 “red square”(一个形状),SDXL 1.0 已经可以区分他俩了。

5、支持更大尺寸和精度的照片
有 Stable Diffusion 出图经验的朋友都知道,之前如果直接生成 1024 x 1024 或更高分辨率的大图,有可能会出现多人多头、肢体错位等的现象,需要使用高清修复或者 Tiled Diffusion 等其他方法才能达到。
而现在,可以直接出 1024 x 1024 或更高分辨率的大图了也不会有问题了。
6、色彩的鲜艳度和准确度
SDXL1.0 在色彩的鲜艳度和准确度上做了很大改进,相对于之前版本,在对比度、光线和阴影上较之前版本更加真实了。


三、如何体验 SDXL 1.0
1、Liblib AI
如果仅仅是为了体验,推荐一个最简单快捷的在线方式:Liblib AI。
Liblib AI 在线出图,一天可以免费出图 300 张,基本满足大部分同学需求。
ps: Liblib AI 在线体验的缺点是,插件少,而且高峰期出图可能会卡。简单体验还是可以,要想深度体验,还是需要使用云部署 Stable Diffusion 或者本地部署 Stable Diffusion 的方式。
Liblib AI 体验步骤很简单,跟着操作,5 分钟搞定!
- 在 Liblib AI 中,点 “在线 Stable Diffusion”。

- 模型选择带 “SDXL” 的模型,然后输入简单的提示词。
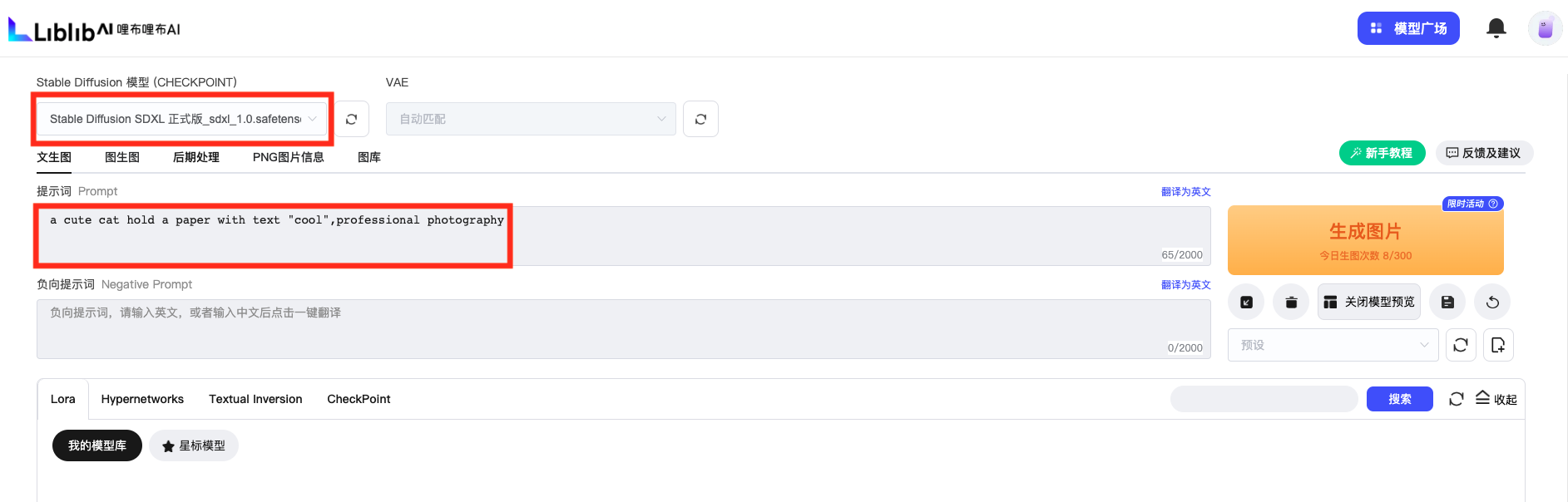
- 参数设置。
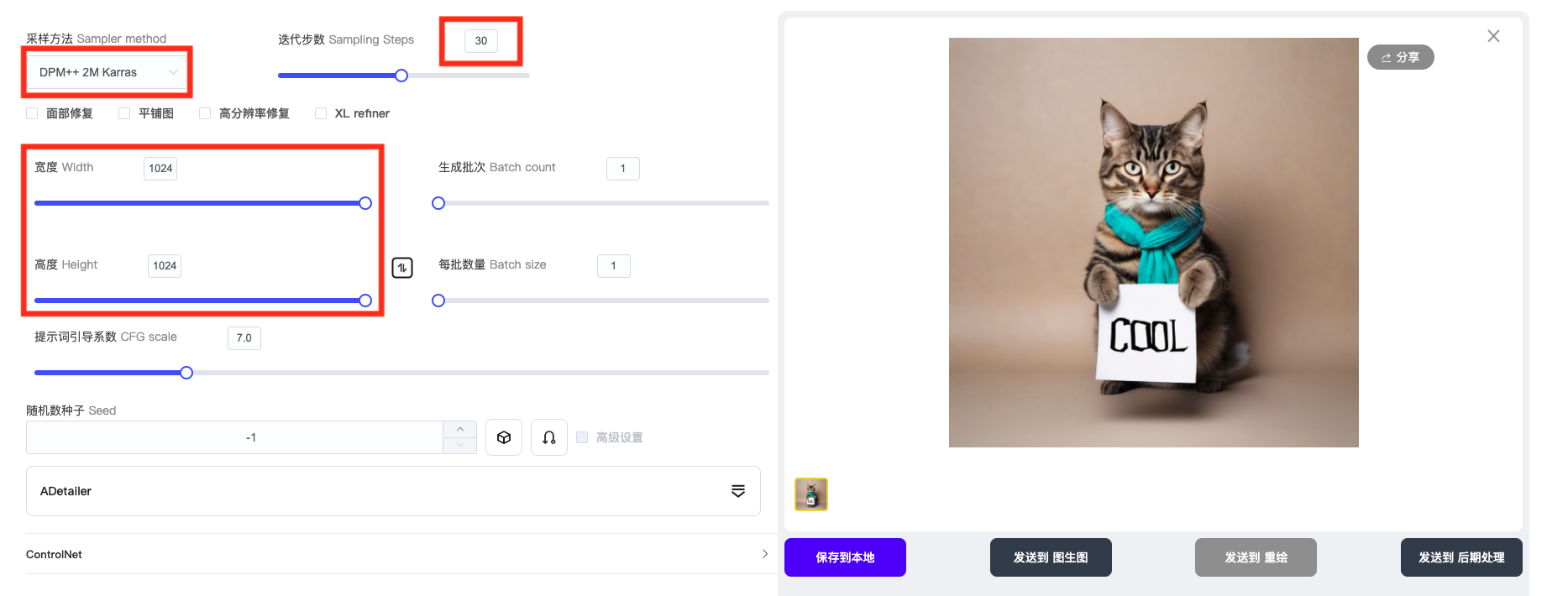
如果不知道哪个参数出图好,可以直接抄图上的。
采样方法:DPM++ 2M Karras(或其他)
采样步数:30
之前很多时候,我们一般会将采样步数设置成 20,但在 SDXL 中,如果将采样步数设置为 20,会让人感觉图片精细度不够。因此可以将采样步数适当调大一些。
分辨率:1024 x 1024 或其他分辨率。太低可能会影响出图质量。
其他参数:可以默认即可。
- 点“生成图片”。
一张使用 SDXL 1.0 生成的图片就出来了,是不是很简单!
2、本地部署
温馨提醒:需要先将本地的 Stable Diffusion WebUI 更新到 1.5.1。
如果之前本地没有部署过 Stable Diffusion WebUI,
Mac 电脑可以参考这篇:Mac 本地部署 Stable Diffusion(超详细,含踩坑点)
Windows 电脑:直接使用秋叶大佬的一键部署安装就可以了。
如果本地已经安装部署过 Stable Diffusion WebUI 了,直接下载下面的两个 SDXL 1.0 的模型,放在 SDW 的根目录/models/Stable-diffusion 目录下即可。
SDXL 1.0 base model 下载
SDXL 1.0 refiner model 下载

这里大家可以发现 SDXL 1.0 有两个模型,一个 base model,一个 refiner model。在使用的时候,先通过 base model 生图,再选择 “发送到图生图”,用 refiner model 进行优化。
第二步使用 refiner model 进行优化的过程,其实相当于通过图生图进行低幅度的重绘来提高图片的画质(这里的重绘幅度不宜设置太高,比如 0.2、0.3 就 ok,也可以根据自己需求)。
当然也可以不进行第二步,只使用 base model 进行图像的生成。
出图方式及具体的参数设置,参照上面 Liblib AI 的方式,这里就不再赘述了。
3、官方提供的方式
Stability AI 官方也提供了几种体验方式:

四、目前的问题
说了半天,SDXL 1.0 多么强大,难道就真的无懈可击了吗?当然不是!
1、一些旧模型、LoRA 模型以及 ControlNet 目前还不支持
比如大部分旧版的模型、LoRA 模型以及 ControlNet 等,用在 SDXL 1.0 上大部分都会失效,因为目前还不支持,需要重新更新才能适配 SDXL 1.0。
另外,SDXL 1.0 只是一个基础大模型,就好比之前的 SD 1.4、SD 1.5,而我们在日常绘画时,往往不会使用这些官方提供的基础模型,而是使用经过这些基础模型进行训练、微调、融合之后的特定模型。
比如我们想画二次元风格的图片,会选择 Cetus-Mix、Counterfeit、AbyssOrangeMix 等二次元风格的大模型,而不会使用官方的基础大模型。


如果我们想画写实风格的图片,会选择 Deliberate、LOFI、Realistic Vision 等大模型,也不会使用官方的基础大模型。

在 SDXL 问世之后,也会涌现出有很多基于 SDXL 训练、微调、融合而成的大模型。目前在 Liblib 等平台上,已经有基于 SDXL 训练的模型了,大家可以试用。而我们日后的绘图,大概率会使用这些基于基础大模型训练、微调、融合而成模型,而不是目前官方提供的 SDXL 的模型。
也就是说,SDXL 1.0 目前只是一个过渡期产品,感兴趣的尝尝鲜、提前了解一些知识还是可以的,但大规模的用于生产,可能还需要一些时间。
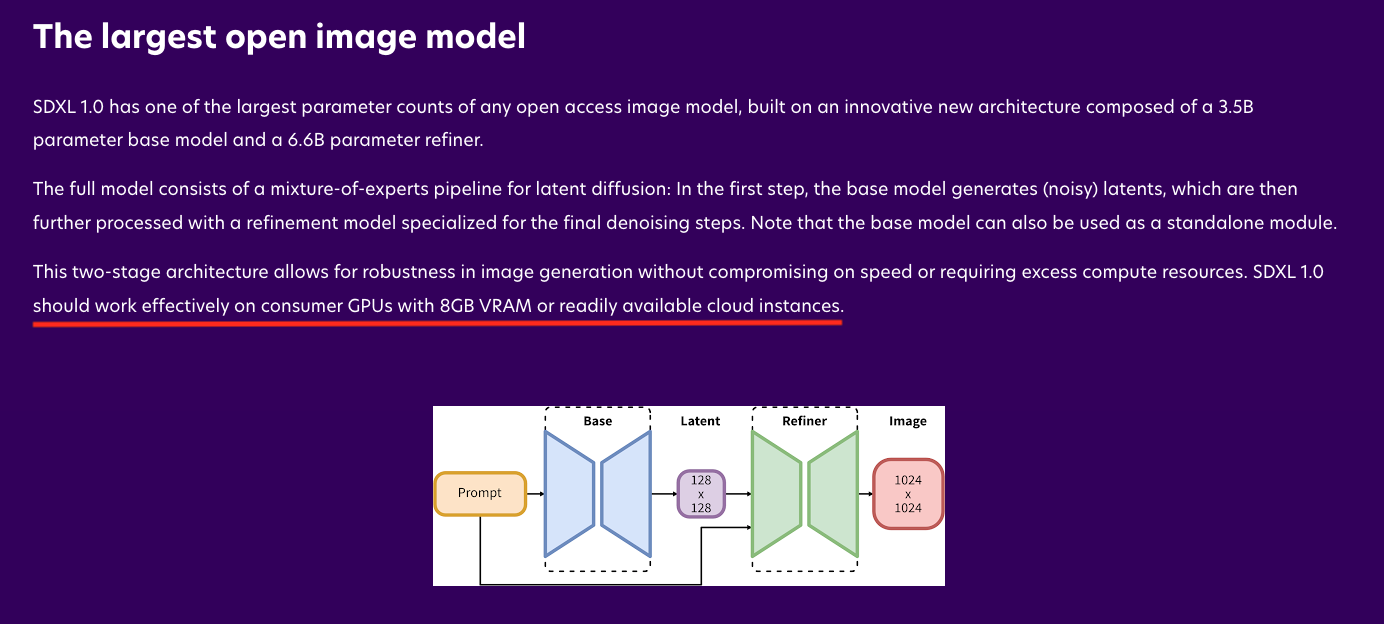
2、太耗显存
相对于之前的 Stable Diffusion 版本,明显更耗显存了。官方推荐在 8G 以上的显存显卡上或者云平台上运行。
五、总结
SDXL 1.0 给我们带来最大的好处就是,基本可以实现 靠嘴出图了,使出图方式更加简单。
新手小白可以在完全不了解复杂的提示词结构、LoRA、Embedding、扩展插件等知识的情况下,也可以使用自然语言轻松出图了,大大降低了使用门槛。
后面肯定还会涌现出一批基于 SDXL 1.0 训练的大模型,到时候肯定会更加惊艳,一起期待一下吧!







 过程记录)






--- 网络协议)



)
