前言
今天开始 DIM 层的开发,说开发好像有点不配,还只是学习阶段,离开发还有很长的路要走。
一个人想象自己不懂得的事很容易浪漫。 --《沉默的大多数》王小波
1、DIM 层开发
DIM层设计要点:
- DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
- DIM层的数据存储格式为orc列式存储+snappy压缩。
- DIM层表名的命名规范为dim_表名_全量表或者拉链表标识(full/zip)
我们在前面 ODS 层的开发时数据压缩用的是 gz ,为的是最大的压缩存储。但是这里,我们的 DIM 、DWD、DWS 层是之后用的最频繁的三层,所以我们必须保证它的读取和解压缩更快,所以我们选用 orc + snappy 压缩。
维度表我们大致可以分为两类:每日全量快照表和拉链表
DIM 层就是创建维度表的过程,所以我们需要先回顾一下维度建模的知识:
1.1、维度建模回顾

前面我们学习数据仓库构建流程的时候说 DWD 和 DIM 层是业务驱动的,因为我们的事实表(存在 DWD 层)取决于业务系统中业务过程,而我们的维度表(存在 DIM 层)取决于业务系统中的环境,它俩都和我们的指标没啥关系。
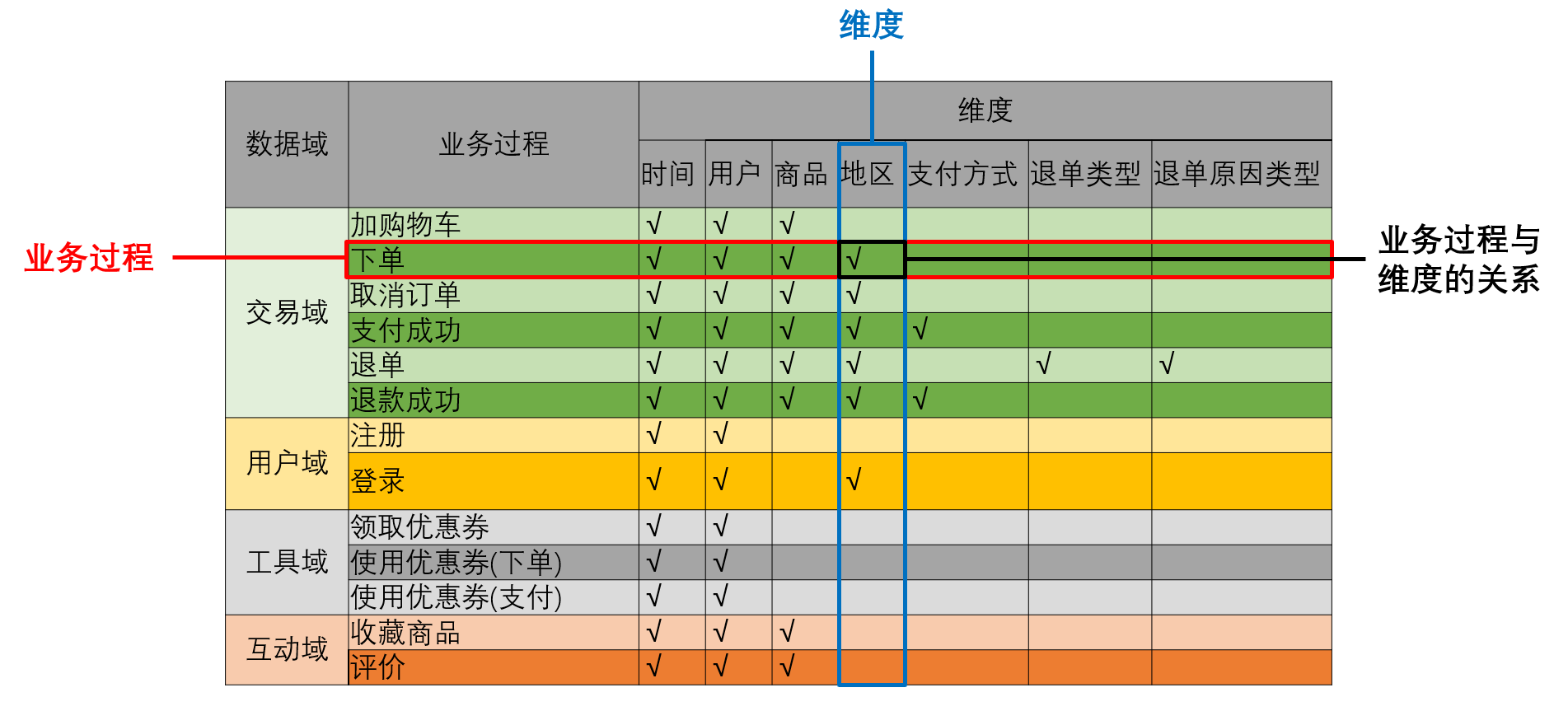
在设计维度模型之前我们需要构建业务总线矩阵,矩阵的行是一个个业务过程(具体说就是每行代表一个业务事实表),矩阵的列是一个个的维度(代表一个维度表),行列的交点表示业务过程与维度存在关联关系。
按照事务型事实表的设计流程我们就可以得到业务总线矩阵,因为我们的维度模型是以事实表为核心,而事实表主要就是事务型事实表。
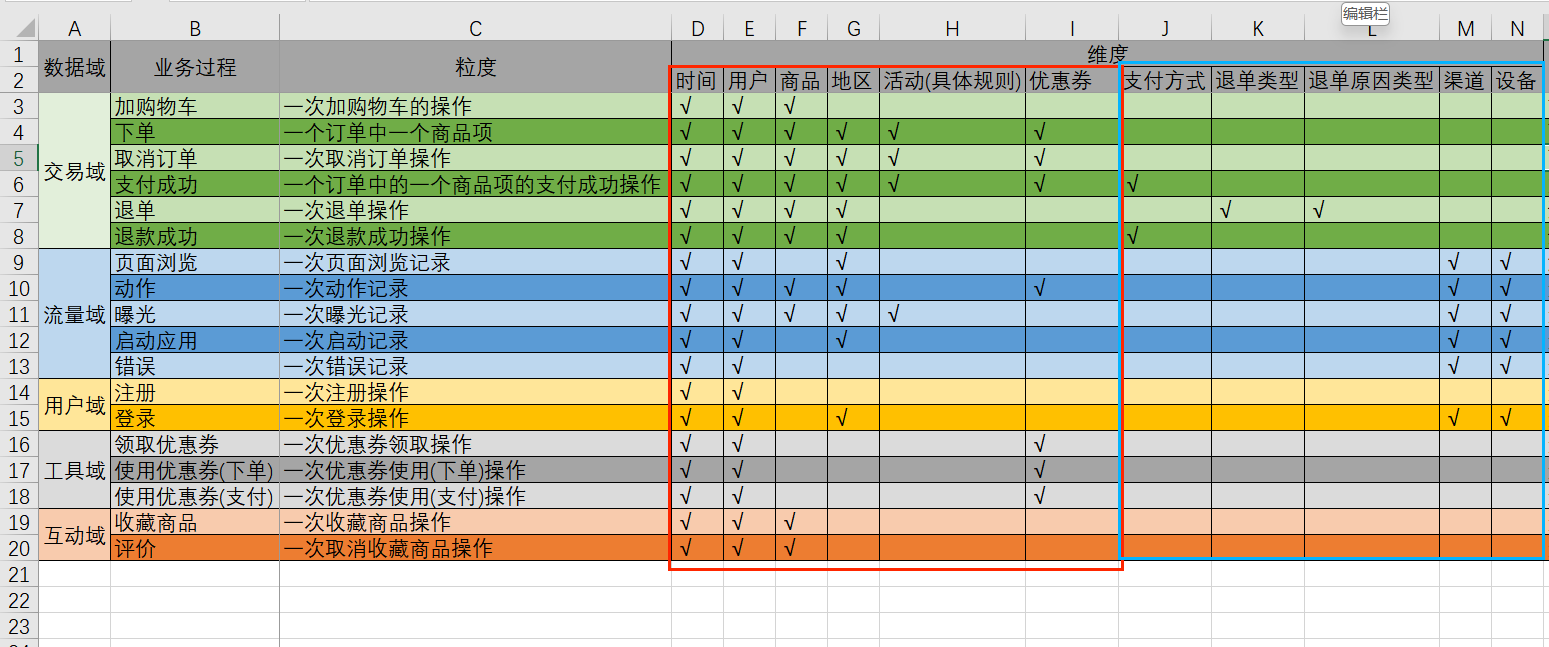
这里只对红色框起来的部分维度进行建表,而蓝色框的维度我们会做一个维度退化。回顾一下维度退化的定义:
如果某些维度表的维度属性很少(比如支付方式表没有必要去单独创建一个维度表,因为它就一个支付方式字段),则可不创建该维度表,而把该表的维度属性直接增加到与之相关的事实表中,这个操作称为维度退化。
也就是说,我们直接把支付方式这个维度属性作为一个字段加到支付成功和退款成功这两个事实表当中,把退单类型作为一个字段做到退款成功这个事实表当中...
还有渠道、设备这两个维度属性也要做维度退化,尽管它俩和多张事实表有关系,但是与这两个维度属性相关联的业务过程基本都是日志当中的业务过程。
CREATE EXTERNAL TABLE ods_log_inc
(`common` STRUCT<ar :STRING,ba :STRING,ch :STRING,is_new :STRING,md :STRING,mid :STRING,os :STRING,uid :STRING,vc:STRING> COMMENT '公共信息',`page` STRUCT<during_time :STRING,item :STRING,item_type :STRING,last_page_id :STRING,page_id:STRING,source_type :STRING> COMMENT '页面信息',`actions` ARRAY<STRUCT<action_id:STRING,item:STRING,item_type:STRING,ts:BIGINT>> COMMENT '动作信息',`displays` ARRAY<STRUCT<display_type :STRING,item :STRING,item_type :STRING,`order` :STRING,pos_id:STRING>> COMMENT '曝光信息',`start` STRUCT<entry :STRING,loading_time :BIGINT,open_ad_id :BIGINT,open_ad_ms :BIGINT,open_ad_skip_ms:BIGINT> COMMENT '启动信息',`err` STRUCT<error_code:BIGINT,msg:STRING> COMMENT '错误信息',`ts` BIGINT COMMENT '时间戳'
) COMMENT '活动信息表'PARTITIONED BY (`dt` STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'LOCATION '/warehouse/gmall/ods/ods_log_inc/';我们在创建日志表的时候已经把业务过程和维度属性给放到一起了,没有必要再把维度属性 "渠道"、"设备" 再拆出来单独建个维度表。
1.2、维度表设计步骤
具体建模步骤看前面的博客:数据仓库(五)【数据仓库建模】
1.2.1、确认维度
也就确认创建哪些维度表,哪些维度属性不需要创建单独的维度表而是做维度退化,我们上面都分析清楚了。
1.2.2、确定主维表和相关维表
主维表和相关维表指的都是和维度相关的业务系统当中的表,然后通常情况下粒度最细的是主维表(比如商品这个维度,我们要去业务系统中找到和它相关的表,发现有购物车表、订单表、商品信息表、退单表... ),如果我们以订单表作为主维表,那一个订单中可能有多个订单,那就导致粒度太大,我们无法确定商品的多个属性。所以我们尽可能选择粒度最细的,比如商品信息表,从商品信息表中我们可以得到更多和商品这个维度相关的属性。
1.2.3、确定维度属性
确定维度属性也就是确定维度表字段。维度属性可直接从主维表或相关维表中选择,也可通过进一步加工得到。
1.3、商品维度表设计
1.3.1、确认维度
我们在上面回顾维度建模的时候已经确定维度了 ,准确说应该是给事实表确定维度,我对这一步的理解是先清楚事实表需要这个维度我们才需要继续创建这张维度表。
1.3.2、确定主维表和相关维表
我们需要去业务系统寻找和商品相关的每张表:
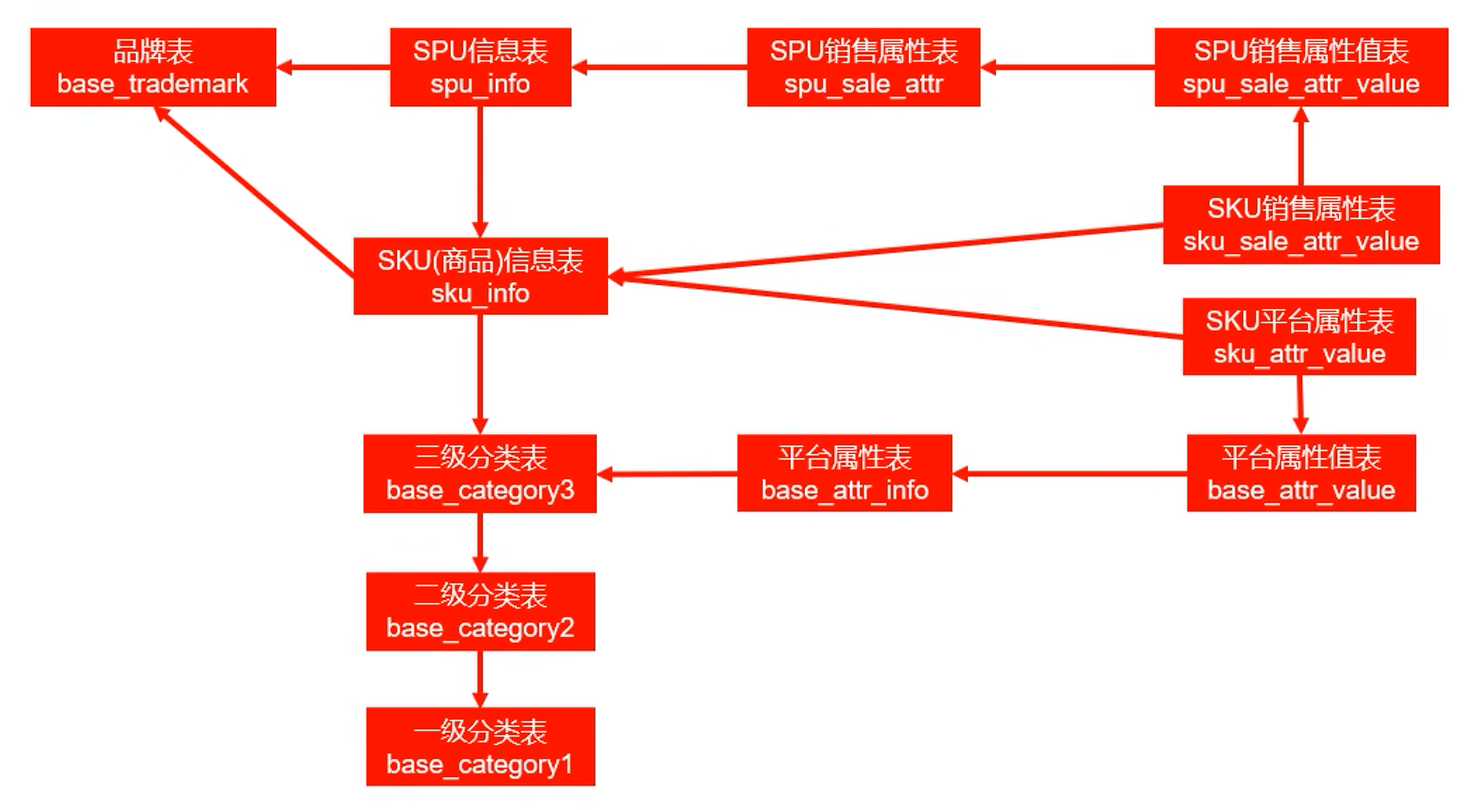
我们的 base_attr_info 存储的是平台属性名:品牌、分类、内存、材质、CPU型号等都是平台属性名,而 base_attr_value 存储的三星、6.4寸、8G内存、玻璃材质、骁龙888 等都是平台属性值。
一个平台属性值可能对应多个商品,同样一个商品也有很多个平台属性值,它们是多对多的关系,平台属性和商品信息的关系存储在 sku_attr_value 这个中间表中。

上面都是我们和平台属性有关的表,我们现在需要知道从应该这些表中获取哪些和商品相关的信息。其实我们主要希望得到的就是每个商品对应的平台属性名(attr_id 和 value_name)和平台属性值(value_id 和 value_name),而我们需要的这些字段都正好被存在了 sku_attr_value 这张中间表,这张表并没有按照三范式去设计,所以我们都不需要去通过 attr_id 和 value_id 去关联另外两张表去获取平台属性名和平台属性值。所以我们之前在做数据采集的时候其实也并没有对这两张表(base_attr_value 和 base_attr_info )进行同步。

和平台属性一样,一个商品属性值可能对应多个商品,同样一个商品也有很多个销售属性值,它们同样是多对多的关系,商品属性和商品信息的关系存储在 sku_sale_attr_value 这个中间表中。而且它同样对 spu_sale_attr 和 spu_sale_attr_value 中的销售属性和销售属性值的字段进行了冗余,我们采集的时候也没有进行同步,而且在设计维度表的时候直接参 sku_sale_attr_value 这个中间表即可。
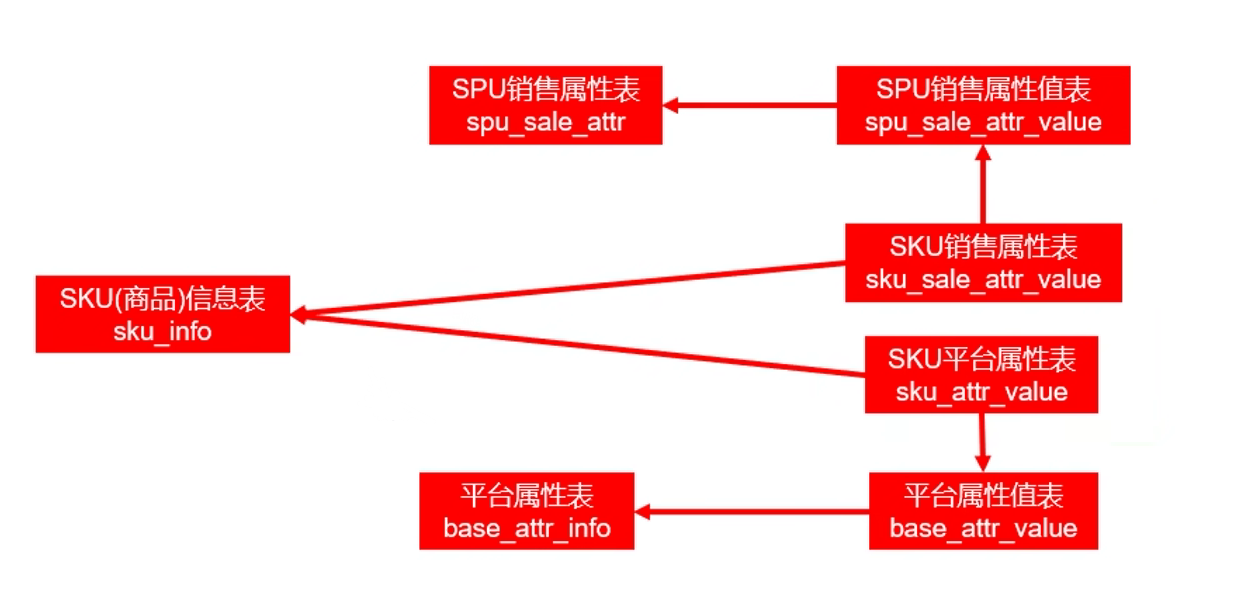
这样,我们的主维表和相关维表就确定好了,sku_info 是最细粒度的表,所以 sku_info 就是主维表,其它和商品相关的表都是相关维表。
1.3.3、确定商品维度的属性
确定商品维度属性就是确定商品维度表的字段,商品主维表(sku_info)具有最细粒度的属性,所以主维表的字段我们可以直接作为商品维度表的维度属性,而其它的相关维表只需要取出它的 id 作为维度属性即可。
1.4、商品维度表的实现
1.4.1、建表语句
DROP TABLE IF EXISTS dim_sku_full;
CREATE EXTERNAL TABLE dim_sku_full
(`id` STRING COMMENT 'sku_id',`price` DECIMAL(16, 2) COMMENT '商品价格',`sku_name` STRING COMMENT '商品名称',`sku_desc` STRING COMMENT '商品描述',`weight` DECIMAL(16, 2) COMMENT '重量',`is_sale` BOOLEAN COMMENT '是否在售',`spu_id` STRING COMMENT 'spu编号',`spu_name` STRING COMMENT 'spu名称',`category3_id` STRING COMMENT '三级分类id',`category3_name` STRING COMMENT '三级分类名称',`category2_id` STRING COMMENT '二级分类id',`category2_name` STRING COMMENT '二级分类名称',`category1_id` STRING COMMENT '一级分类id',`category1_name` STRING COMMENT '一级分类名称',`tm_id` STRING COMMENT '品牌id',`tm_name` STRING COMMENT '品牌名称',`sku_attr_values` ARRAY<STRUCT<attr_id :STRING,value_id :STRING,attr_name :STRING,value_name:STRING>> COMMENT '平台属性',`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id :STRING,sale_attr_value_id :STRING,sale_attr_name :STRING,sale_attr_value_name:STRING>> COMMENT '销售属性',`create_time` STRING COMMENT '创建时间'
) COMMENT '商品维度表'PARTITIONED BY (`dt` STRING)STORED AS ORCLOCATION '/warehouse/gmall/dim/dim_sku_full/'TBLPROPERTIES ('orc.compress' = 'snappy');可以看到,大部分的维度属性是来自于我们的主维表:

剩下的字段来自我们的其它维表,比如 SKU 相关的平台属性和销售属性:
`sku_attr_values` ARRAY<STRUCT<attr_id :STRING,value_id :STRING,attr_name :STRING,value_name:STRING>> COMMENT '平台属性',`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id :STRING,sale_attr_value_id :STRING,sale_attr_name :STRING,sale_attr_value_name:STRING>> COMMENT '销售属性'其中,sku_attr_values 存的是平台属性名和平台属性值;sku_sale_attr_values 存的是销售属性名和销售属性值。这是我们前面维度表设计中提到的一个设计要点——多值属性,对于多值属性通常有两种存储方案:1. 多个属性值放到一个字段,这也是我们这里用到的。2. 将多值属性放到多个字段,这里我们没有用,因为我们不能确定多值属性的属性个数,所以就无法怎么去设计这个结构体。
至于这张全量表的分区,我们选择用日期进行分区,每天把前一天的数据都得导入到一个日期目录下。
这里我们选择 store as orc 来指定存储格式为 orc ,使用 tblproperties 来指定压缩格式为 snappy。
4.1.2、装载语句
这张表的装载我们不能再用简单的 load 语句了,因为我们现在不再是通过文件映射到表格了。我们得通过 insert + select 来进行装载,select 的当然就是我们的 ODS 层的原始数据表了,而且 insert 时需要指定分区。
这就需要我们从 ODS 层中和我们商品相关的所有表(主维表和相关维表)中获取了,而且是拿到这些表当天分区的数据,然后写入到当天的维度表中。
-- 数据装载
-- 2020-06-14
-- sku_info 中的数据
selectid,spu_id,price,sku_name,sku_desc,weight,tm_id,category3_id,is_sale,create_time
from ods_sku_info_full
where dt='2020-06-14';-- spu_info 中的数据
selectid,spu_name
from ods_spu_info_full
where dt='2020-06-14';-- base_category3 中的数据,通过category2_id和base_category2产生关联
selectid,name,category2_id
from ods_base_category3_full
where dt='2020-06-14';-- base_category2 中的数据,通过category1_id和base_category1产生关联
selectid,name,category1_id
from ods_base_category2_full
where dt='2020-06-14';selectid,name
from ods_base_category1_full
where dt='2020-06-14';selectid,tm_name
from ods_base_trademark_full
where dt='2020-06-14';selectsku_id,
collect_set(named_struct("attr_id",attr_id,"value_id",value_id,"attr_name",attr_name,"value_name",value_name))
from ods_sku_attr_value_full
where dt='2020-06-14'
group by sku_id;selectsku_id,
collect_set(named_struct('sale_attr_id',sale_attr_id,'sale_attr_value_id',sale_attr_value_id,'sale_attr_name',sale_attr_name,'sale_attr_value_name',sale_attr_value_name)) sale_attrsfrom ods_sku_sale_attr_value_fullwhere dt='2020-06-14'group by sku_id;对于平台属性名和平台属性值,我们要把同一个 sku_id 的平台属性名和平台属性值放到同一个结构体数组中:

selectsku_id,collect_set(named_struct("attr_id",attr_id,"value_id",value_id,"attr_name",attr_name,"value_name",value_name))
from ods_sku_attr_value_full
where dt='2020-06-14'
group by sku_id;销售属性名和销售属性值也是一样;最后我们一共从这 8 张和商品信息相关的表中来获取我们需要的字段,但是我们总不能就这么 join 吧,那可读性太差了!我们学习一种新的语法(CTE:common table expression):
with
sku as
(selectid,price,sku_name,sku_desc,weight,is_sale,spu_id,category3_id,tm_id,create_timefrom ods_sku_info_fullwhere dt='2020-06-14'
),
spu as
(selectid,spu_namefrom ods_spu_info_fullwhere dt='2020-06-14'
),
c3 as
(selectid,name,category2_idfrom ods_base_category3_fullwhere dt='2020-06-14'
),
c2 as
(selectid,name,category1_idfrom ods_base_category2_fullwhere dt='2020-06-14'
),
c1 as
(selectid,namefrom ods_base_category1_fullwhere dt='2020-06-14'
),
tm as
(selectid,tm_namefrom ods_base_trademark_fullwhere dt='2020-06-14'
),
attr as
(selectsku_id,collect_set(named_struct('attr_id',attr_id,'value_id',value_id,'attr_name',attr_name,'value_name',value_name)) attrsfrom ods_sku_attr_value_fullwhere dt='2020-06-14'group by sku_id
),
sale_attr as
(selectsku_id,collect_set(named_struct('sale_attr_id',sale_attr_id,'sale_attr_value_id',sale_attr_value_id,'sale_attr_name',sale_attr_name,'sale_attr_value_name',sale_attr_value_name)) sale_attrsfrom ods_sku_sale_attr_value_fullwhere dt='2020-06-14'group by sku_id
)
insert overwrite table dim_sku_full partition(dt='2020-06-14')
selectsku.id,sku.price,sku.sku_name,sku.sku_desc,sku.weight,sku.is_sale,sku.spu_id,spu.spu_name,sku.category3_id,c3.name,c3.category2_id,c2.name,c2.category1_id,c1.name,sku.tm_id,tm.tm_name,attr.attrs,sale_attr.sale_attrs,sku.create_time
from sku
left join spu on sku.spu_id=spu.id
left join c3 on sku.category3_id=c3.id
left join c2 on c3.category2_id=c2.id
left join c1 on c2.category1_id=c1.id
left join tm on sku.tm_id=tm.id
left join attr on sku.id=attr.sku_id
left join sale_attr on sku.id=sale_attr.sku_id;可以看到,我们在 join 这 8 张表的时候,先从我们的主维表(sku)去查询然后再和其它维表去 left join 来保证结果中包含所有的 sku 信息。而且我们可以看到每张表都能直接的(通过和 sku 表中的字段)或者间接的(比如 1级category和2级category产生关联,2级category再和3级category产生关联,最后3级category直接和sku通过公共字段产生关联)和我们的主维表产生关联。
而且我们这里用的是 insert overwrite,为的是保持任务的幂等性,比如说,我们用 insert overwrite 执行这个任务多少次它的结果都是一样的,也就不用担心执行过程失败重新执行时数据重复的问题;但是如果我们用 insert into 的话,我们这个分区的数据就可能会发生重复。
1.5、优惠券维度表
剩下的明天完成




 方法、运用JSONP)






)

:Iterator、Generator、类的用法、类的继承)


-机器学习-深度学习-大语言模型LLM(chatgtp))


)