前言
HTTP/1.1 是目前广泛应用的网络协议之一,虽然已经存在多年,但我们仍然可以通过优化来提升其性能和效率。本文将从优化思路的角度出发,探讨如何在 HTTP/1.1 协议下实现优化,包括避免发送重复 HTTP 请求、减少 HTTP 请求次数、减少 HTTP 响应的数据大小等方面。通过深入了解如何利用强制缓存、协商缓存、合并请求、延迟发送请求等技术手段,以及压缩资源的方式来提高网络传输效率,我们可以更好地利用 HTTP/1.1 协议,提升网页加载速度和用户体验。
我们可以从下面这三种优化思路来优化 HTTP/1.1 协议:
-
尽量避免发送 HTTP 请求;
-
在需要发送 HTTP 请求时,考虑如何减少请求次数;
-
减少服务器的 HTTP 响应的数据大小;
避免发送重复 HTTP 请求
对于一些具有重复性的 HTTP 请求,比如每次请求得到的数据都一样的,我们可以把这对「请求-响应」的数据都缓存在本地,那么下次就直接读取本地的数据,不必在通过网络获取服务器的响应了。HTTP 缓存有两种实现方式,分别是强制缓存和协商缓存。注意二者是一起使用的,不是单选一个
缓存是如何做到的呢?
客户端会把第一次请求以及响应的数据保存在本地磁盘上,其中将请求的 URL 作为 key,而响应作为 value,两者形成映射关系。
这样当后续发起相同的请求时,就可以先在本地磁盘上通过 key 查到对应的 value,也就是响应,如果找到了,就直接从本地读取该响应。毋庸置疑,读取本地磁盘的速度肯定比网络请求快得多
强制缓存
强缓存指的是只要浏览器判断缓存没有过期,则直接使用浏览器的本地缓存,决定是否使用缓存的主动性在于浏览器这边
强缓存是利用下面这两个 HTTP 响应头部(Response Header)字段实现的,它们都用来表示资源在客户端缓存的有效期:
-
Cache-Control, 是一个相对时间; -
Expires,是一个绝对时间;
如果 HTTP 响应头部同时有 Cache-Control 和 Expires 字段的话,Cache-Control 的优先级高于 Expires 。
Cache-control 选项更多一些,设置更加精细,所以建议使用 Cache-Control 来实现强缓存。具体的实现流程如下:
-
当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在 Response 头部加上 Cache-Control,Cache-Control 中设置了过期时间大小;
-
浏览器再次请求访问服务器中的该资源时,会先通过请求资源的时间与 Cache-Control 中设置的过期时间大小,来计算出该资源是否过期,如果没有,则使用该缓存,否则重新请求服务器;
-
服务器再次收到请求后,会再次更新 Response 头部的 Cache-Control。
协商缓存
当我们在浏览器使用开发者工具的时候,你可能会看到过某些请求的响应码是
304,这个是告诉浏览器可以使用本地缓存的资源,通常这种通过服务端告知客户端是否可以使用缓存的方式被称为协商缓存。
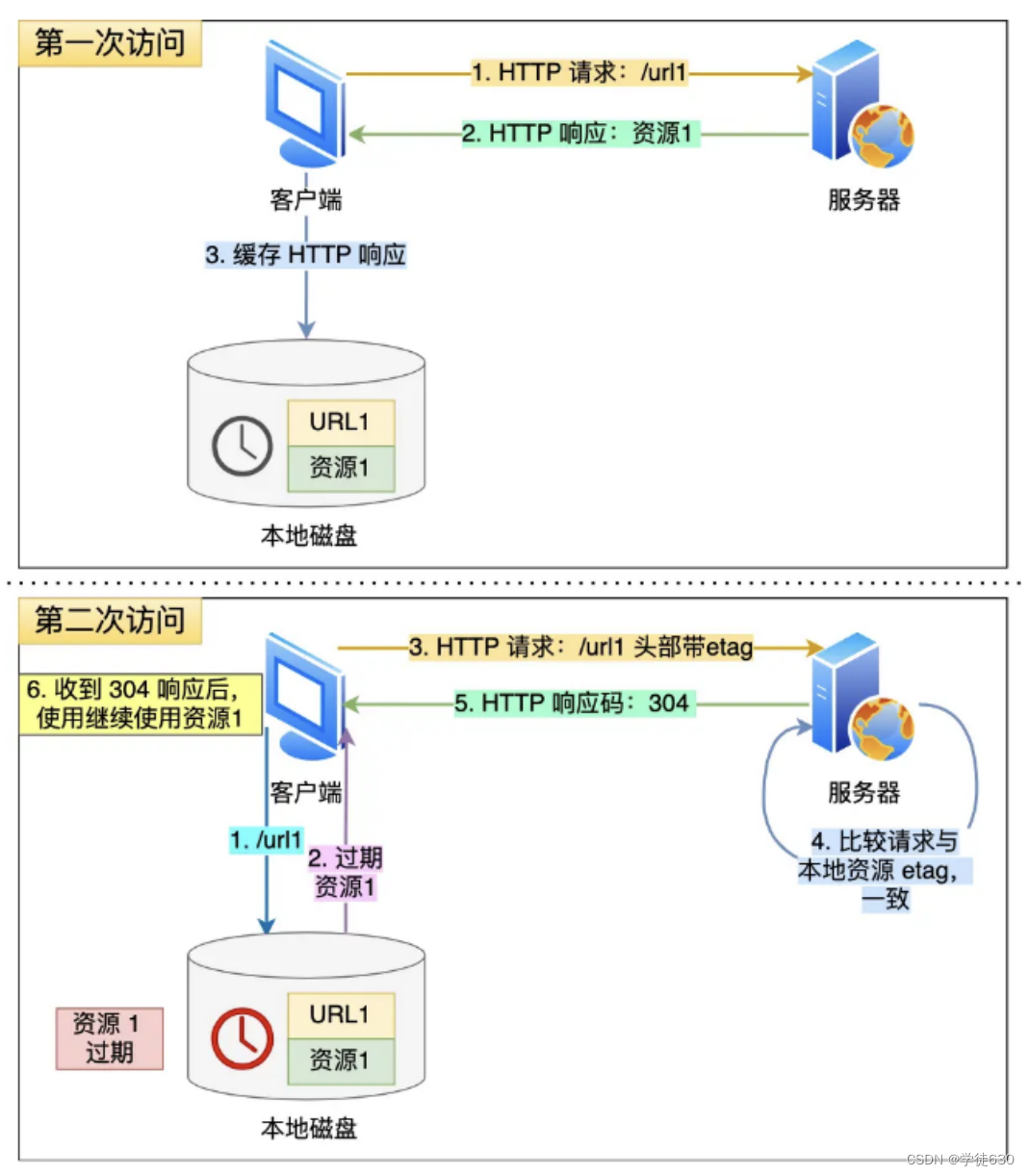
上图就是一个协商缓存的过程,所以协商缓存就是与服务端协商之后,通过协商结果来判断是否使用本地缓存。
注意,协商缓存这两个字段都需要配合强制缓存中 Cache-Control 字段来使用,只有在未能命中强制缓存的时候,才能发起带有协商缓存字段的请求。
为什么这样子做?
如果客户端从第一次请求得到的响应头部中发现该响应过期了,客户端重新发送请求,假设服务器上的资源并没有变更,还是老样子,那么你觉得还要在服务器的响应带上这个资源吗?很显然不带的话,可以提高 HTTP 协议的性能,那具体如何做到呢?
只需要客户端在重新发送请求时,在请求的
Etag头部带上第一次请求的响应头部中的摘要,这个摘要是唯一标识响应的资源,当服务器收到请求后,会将本地资源的摘要与请求中的摘要做个比较。
如果不同,那么说明客户端的缓存已经没有价值,服务器在响应中带上最新的资源。
如果相同,说明客户端的缓存还是可以继续使用的,那么服务器仅返回不含有包体的
304 Not Modified响应,告诉客户端仍然有效,这样就可以减少响应资源在网络中传输的延时
减少 HTTP 请求次数
减少 HTTP 请求次数自然也就提升了 HTTP 性能,可以从这 3 个方面入手:
-
减少重定向请求次数;
-
合并请求;
-
延迟发送请求;
减少重定向请求次数
服务器上的一个资源可能由于迁移、维护等原因从 url1 移至 url2 后,而客户端不知情,它还是继续请求 url1,这时服务器不能粗暴地返回错误,而是通过 302 响应码和 Location 头部,告诉客户端该资源已经迁移至 url2 了,于是客户端需要再发送 url2 请求以获得服务器的资源。那么,如果重定向请求越多,那么客户端就要多次发起 HTTP 请求,每一次的 HTTP 请求都得经过网络,这无疑会越降低网络性能。
另外,服务端这一方往往不只有一台服务器,比如源服务器上一级是代理服务器,然后代理服务器才与客户端通信,这时客户端重定向就会导致客户端与代理服务器之间需要 2 次消息传递,如下图:
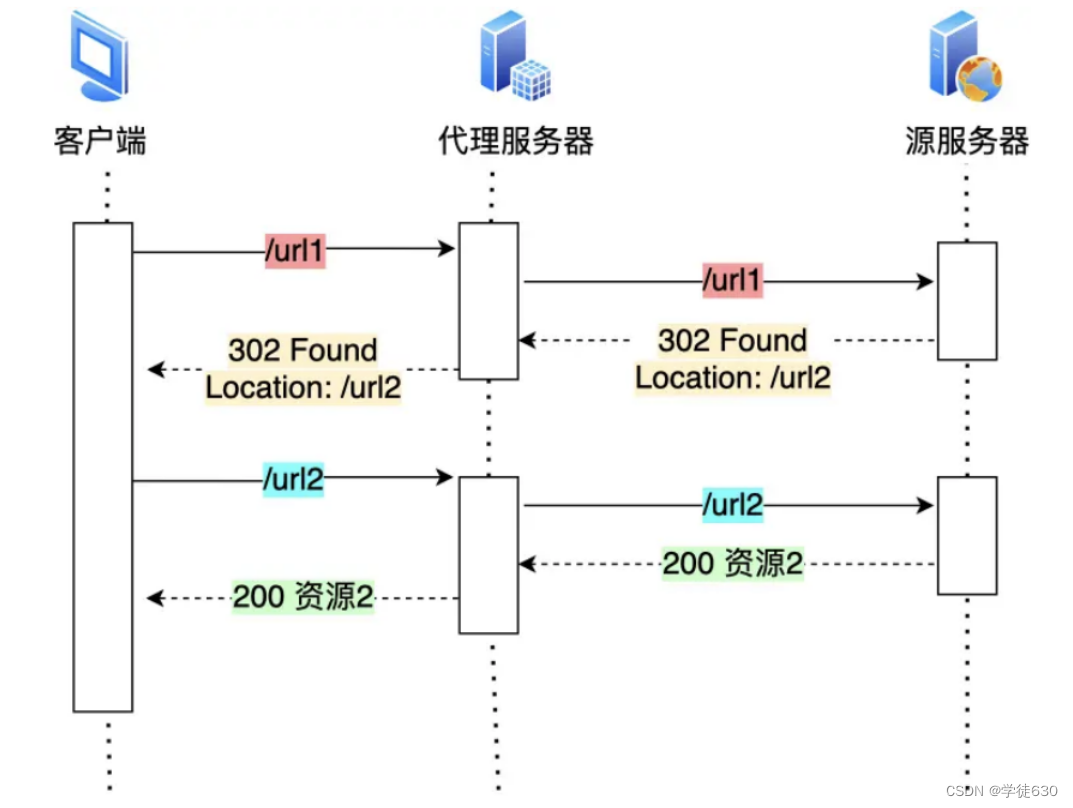
如果重定向的工作交由代理服务器完成,就能减少 HTTP 请求次数了

而且当代理服务器知晓了重定向规则后,可以进一步减少消息传递次数

合并请求
由于 HTTP/1.1 是请求响应模型,如果第一个发送的请求,未收到对应的响应,那么后续的请求就不会发送(PS:HTTP/1.1 管道模式是默认不使用的,所以讨论 HTTP/1.1 的队头阻塞问题,是不考虑管道模式的),于是为了防止单个请求的阻塞,所以一般浏览器会同时发起 5-6 个请求,每一个请求都是不同的 TCP 连接,那么如果合并了请求,也就会减少 TCP 连接的数量,因而省去了 TCP 握手和慢启动过程耗费的时间。
对于前端开发而言,对于小图标展示有个比较熟悉的优化思想,就是采用精灵图来减少请求次数
对于这些小图片,我们可以考虑使用
CSS Image Sprites技术把它们合成一个大图片,这样浏览器就可以用一次请求获得一个大图片,然后再根据 CSS 数据把大图片切割成多张小图片。这种方式就是通过将多个小图片合并成一个大图片来减少 HTTP 请求的次数,以减少 HTTP 请求的次数,从而减少网络的开销。除了将小图片合并成大图片的方式,还有服务端使用
webpack等打包工具将 js、css 等资源合并打包成大文件,也是能达到类似的效果。另外,还可以将图片的二进制数据用
base64编码后,以 URL 的形式嵌入到 HTML 文件,跟随 HTML 文件一并发送.

但是这样的合并请求会带来新的问题,当大资源中的某一个小资源发生变化后,客户端必须重新下载整个完整的大资源文件,这显然带来了额外的网络消耗
延迟发送请求
其实这个就是懒加载的一种思路。一般 HTML 里会含有很多 HTTP 的 URL,当前不需要的资源,我们没必要也获取过来,于是可以通过「按需获取」的方式,来减少第一时间的 HTTP 请求次数。
减少 HTTP 响应的数据大小?
我们可以考虑对响应的资源进行压缩,这样就可以减少响应的数据大小,从而提高网络传输的效率。
压缩的方式一般分为 2 种,分别是:
-
无损压缩;
-
有损压缩;
无损压缩
无损压缩是指资源经过压缩后,信息不被破坏,还能完全恢复到压缩前的原样,适合用在文本文件、程序可执行文件、程序源代码。
gzip 就是比较常见的无损压缩。客户端支持的压缩算法,会在 HTTP 请求中通过头部中的 Accept-Encoding 字段告诉服务器:
Accept-Encoding: gzip, deflate, br服务器收到后,会从中选择一个服务器支持的或者合适的压缩算法,然后使用此压缩算法对响应资源进行压缩,最后通过响应头部中的 Content-Encoding 字段告诉客户端该资源使用的压缩算法。
Content-Encoding: gzipgzip 的压缩效率相比 Google 推出的 Brotli 算法还是差点意思,也就是上文中的 br,所以如果可以,服务器应该选择压缩效率更高的 br 压缩算法。
有损压缩
与无损压缩相对的就是有损压缩,经过此方法压缩,解压的数据会与原始数据不同但是非常接近。
有损压缩主要将次要的数据舍弃,牺牲一些质量来减少数据量、提高压缩比,这种方法经常用于压缩多媒体数据,比如音频、视频、图片。
可以通过 HTTP 请求头部中的 Accept 字段里的「 q 质量因子」,告诉服务器期望的资源质量。
Accept: audio/*; q=0.2, audio/basic关于图片的压缩,目前压缩比较高的是 Google 推出的 WebP 格式,相同图片质量下,WebP 格式的图片大小都比 Png 格式的图片小,所以对于大量图片的网站,可以考虑使用 WebP 格式的图片,这将大幅度提升网络传输的性能。



)
)




的概念,并说明在Python中如何使用)





)



