机器学习概论—正则化
在开发机器学习模型的过程中,大家一定遇到过模型在训练集上表现不错,但验证精度或测试精度过低的情况。这种情况在机器学习领域通常被称为过度拟合,这也是机器学习从业者最不希望在他的模型中出现的情况。
在本文中,我们将学习一种称为正则化的方法,它可以帮助我们解决过度拟合的问题。但在此之前,让我们先了解一下什么是欠拟合和过拟合。
什么是过拟合和欠拟合
机器学习在训练时有一个从欠拟合到过拟合的过程:
过度拟合是机器学习模型受限于训练集并且无法在未见过的数据上表现良好时发生的一种现象。此时我们的模型也会学习训练数据中的噪声。当我们的模型记住训练数据而不是学习其中的模式时,就会出现这种情况。
另一方面,**欠拟合是指我们的模型甚至无法学习数据集中可用的基本模式。**在欠拟合的情况下,模型即使在训练数据上也无法表现良好,因此我们不能期望它在验证数据上表现良好。当我们增加模型的复杂性或向特征集中添加更多特征时,就会出现这种情况
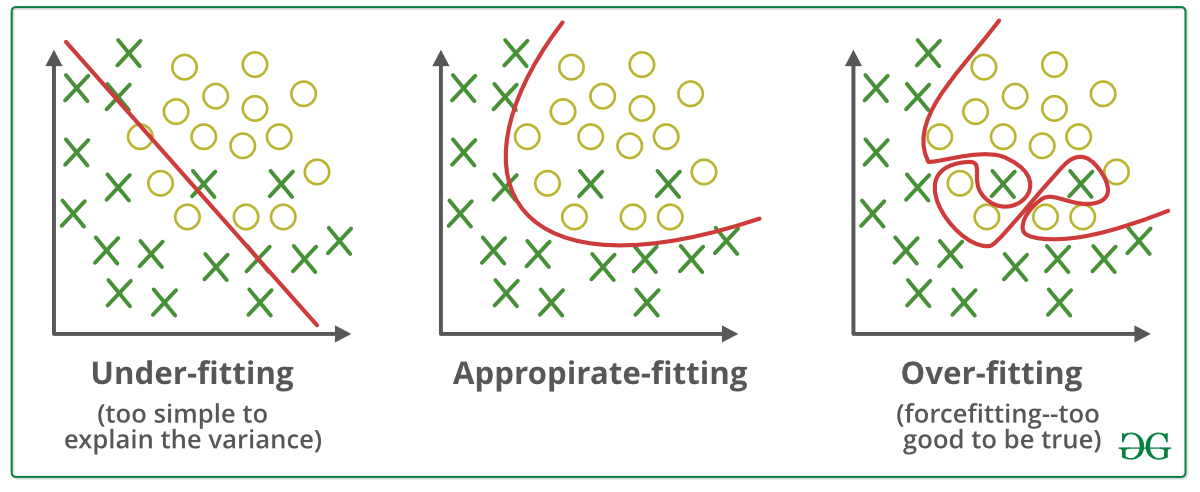
什么是偏差和方差
偏差是指当我们尝试将统计模型拟合到现实世界的数据时出现的错误,而该统计模型并不完全适合某些数学模型。如果我们使用过于简单的模型来拟合数据,那么我们更有可能面临高偏差的情况,这是指模型无法学习手头数据中的模式并因此表现不佳的情况。
方差意味着当我们尝试使用模型之前未见过的数据进行预测时出现的误差值。当模


)







)






)

