Redis是一个在内存中存储数据的中间件,用于作为数据库,用于作为数据缓存,在分布式系统中能够发挥重要作用。
Redis的特性
1.In-memory data structures:
MySQL使用表的方式存储数据,这意味着数据通常存储在硬盘上,并且在需要时加载到内存中进行处理。而Redis则是将数据存储在内存中,这使得Redis能够提供非常高的读写性能,适用于对性能要求较高的场景。
2.Programmability:
Redis具有丰富的命令集,可以通过交互式命令行或脚本语言(如Lua)进行操作。这使得开发人员可以方便地进行数据操作和逻辑处理,而不需要编写复杂的SQL语句。
3.Extensibility:
Redis提供了一组API,可以通过编写C、C++、Rust等语言的扩展来扩展其功能。这意味着开发人员可以根据自己的需求添加自定义功能或优化现有功能。
4.Persistence:
尽管Redis主要将数据存储在内存中以提供高性能,但它也提供了持久化的机制,可以将数据定期写入硬盘中,以防止数据丢失。这可以通过快照(snapshot)持久化和日志(append-only log)持久化两种方式来实现。
5.Clustering:
Redis支持集群部署,可以通过将多个Redis节点组成一个集群来扩展数据存储和处理能力。集群中的不同节点负责存储和处理不同的数据片段,并通过内部通信协议进行数据同步和负载均衡。
6. High availability:
为了实现高可用性,Redis支持主从复制(master-slave replication)机制。在主从复制中,一个主节点负责处理客户端请求,并将数据复制到一个或多个从节点,从节点则用作主节点的备份。当主节点发生故障时,可以通过将一个从节点提升为新的主节点来实现故障转移,从而保证系统的可用性。
Redis快的原因:
1.Redis将数据存储在内存中,这使得它比基于硬盘的数据库快得多。通过将数据保留在内存中,Redis避免了从硬盘读取数据所带来的延迟。
2.Redis的核心功能主要围绕着对内存中数据结构的简单和高效操作展开。相比于复杂的关系型数据库,Redis提供了一组简单而强大的命令,可以直接操作数据结构,例如字符串、哈希表、列表、集合和有序集合等。
3.从网络的角度来看,Redis采用了I0多路复用的模型(如epol),它使用单个线程来管理多个套接字连接。这种设计使得Redis能够高效地处理并发连接请求,提高了网络通信的性能。
4.Redis采用单线程模型,这减少了不必要的线程间竞争开销。由于Redis的核心任务是操作内存中的数据结构,它并不消耗大量的CPU资源。多线程适用于CPU密集型任务,而Redis的单线程模型更适合处理高并发的读写操作。
Redis主要的应用场景
1.实时数据的存储
这里的Redis被当作数据库使用。
大多数情况下,考虑到数据存储都是优先选择存储量大的。
但在某些情况下,需要考虑数据存储的速度。
eg:做搜索引擎开发时,比如商业搜索,对性能的要求是很高的,所以搜索系统当中是没有使用到MySQL这样的数据库。所以我们会把所有检索的数据存放到内存当中,就是用的是类似Redis这样的内存数据库。
2.缓存与会话存储
大多数情况下,每一个系统都有热点数据与冷点数据,我们可以将热点数据存放在速度较快的Redis当中,将大量的冷点数据存放在存储量更大的MySQL当中。
会话存储:
cookie => 实现用户身份信息的保存,需要session的配合。
cookie只是在浏览器这边存储了一个用户的身份标识---sessionId
session在服务器这里真正的存储了用户数据。
问题小场景
现在出现了一点小问题:
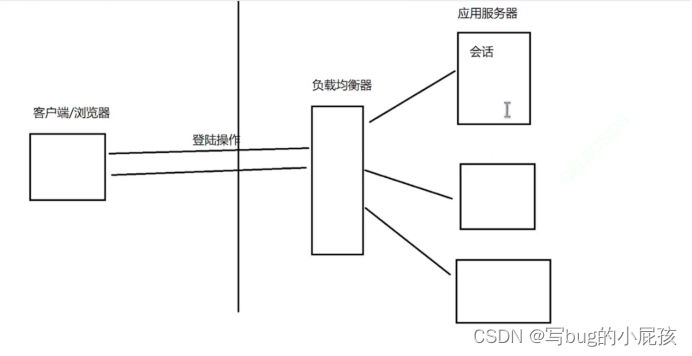
如上,如果每次客户端发送了请求,都会需要经过负载均衡器,那都需要登录一次,显然这个是个问题。
解决方式:
1).想办法让负载均衡器,把同一个用户的请求都输送到同一个应用服务器上(不能够轮询,而是需要通过userId之类的方式来分配机器)
2).把会话数据单独拿出来,放到一组独立的机器上存储(Redis)
PS:这里有个好处,应用服务器重启了,会话数据是不会丢失的。
3.消息队列(服务器)
PS:此处说的消息队列不是Linux进程间通信的消息队列
基于此,可以实现一个网络版本的 生产者/消费者 模型。 对于分布式系统中的服务器与服务器之间,也会用到该模型。
该模型的优势:解耦合,削峰填谷
PS:对比1,2两点,第一点中,Redis存放的是全量数据,这里的数据是不可以随便丢的。
第二点中,Redis存放的是部分数据,全量数据都是以MySQL为主的,哪怕Redis的数据没了,还可以从MySQL当中加载回去。
Redis不能做的事情:
存储大规模数据!!!





)




——选择角色界面--解析赋值服务器返回的信息1)



)




](http://pic.xiahunao.cn/JAVA虚拟机实战篇之GC调优[1](GC调优基知、方法、工具和常见GC模式))