Tesseract OCR
- Tesseract
- 概述
- 常见OCR识别平台
- 下载安装
- 配置
- 命令使用
- 语法
- 测试验证
- Tesseract的使用
- 安装python库
- 基本使用
- 可能的异常
- 更换语言字体库识别
- Tesseract的训练
Tesseract
概述
Tesseract是一个开源文本识别 (OCR)引擎,是目前公认最优秀、最精确的开源OCR系统,用于识别图片中的文字并将其转换为可编辑的文本。
Tesseract能够将印刷体文字图像转换成可编辑文本,它支持多种语言,并且在许多平台上都可使用,包括Windows、Mac OS和Linux。Tesseract可以处理各种图像文件格式,如JPEG、PNG、TIFF等。
Tesseract的主要功能是识别图像中的文字,并将其转换成机器可读的文本内容。它采用了一系列图像处理、特征提取和机器学习技术来实现文字识别的过程。Tesseract算法的基础是使用训练好的模型来识别字符,并通过上下文和语言模型来提高识别准确性。
GitHub地址:https://github.com/tesseract-ocr/tesseract
常见OCR识别平台
微软Azure图像识别:https://azure.microsoft.com/zh-cn/services/cognitive-services/computer-vision有道智云文字识别:https://ai.youdao.com阿里云图文识别:https://www.aliyun.com/product/cdi腾讯OCR文字识别:https://cloud.tencent.com/product/ocr
下载安装
安装说明
https://tesseract-ocr.github.io/tessdoc/Installation.html
官方不提供最新版windows平台安装包,只有相对略老的3.02.02版本
https://sourceforge.net/projects/tesseract-ocr-alt/files/
直接下载
https://sourceforge.net/projects/tesseract-ocr-alt/files/tesseract-ocr-setup-3.02.02.exe/download
德国曼海姆大学发行的3.05版本下载地址
http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-3.05.00dev.exe
新版都是三方维护和管理的安装包
UB Mannheim提供的: https://github.com/UB-Mannheim/tesseract/wiki
https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w32-setup-5.3.0.20221222.exehttps://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-5.3.0.20221222.exe
安装后得到如下目录
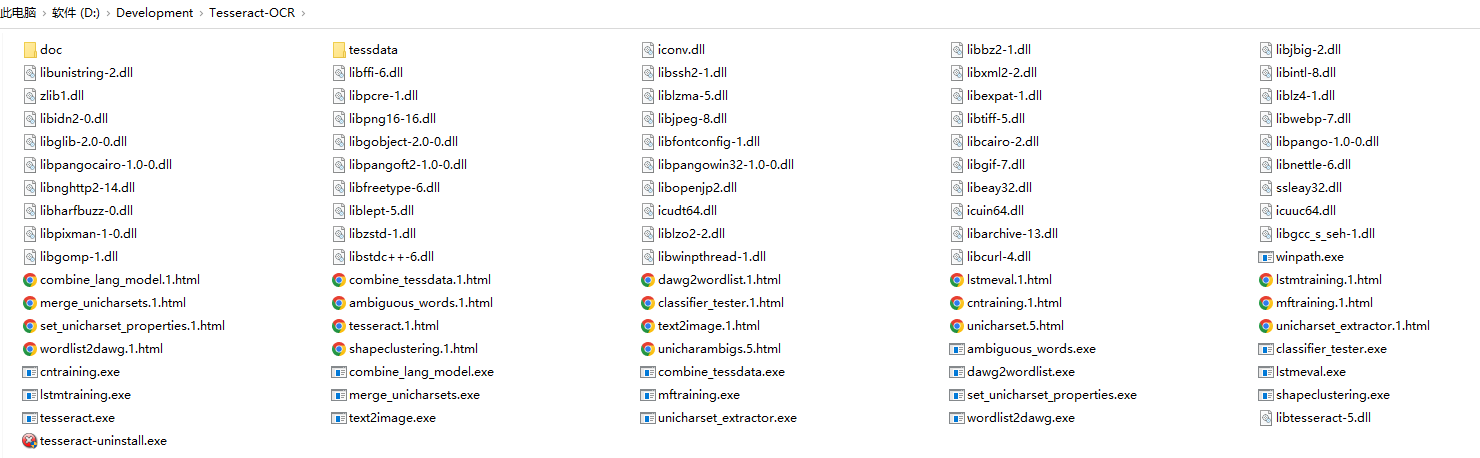
配置
1.配置语言字体库
在安装目录下,默认有个 tessdata目录,该目录中存放的是语言字库文件
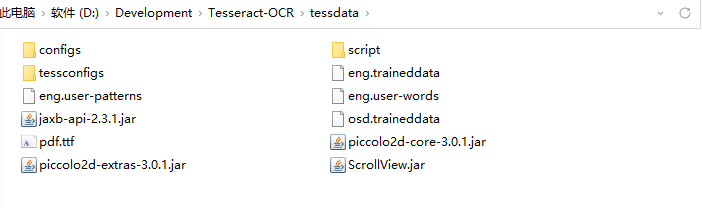
访问:https://github.com/tesseract-ocr/tessdata项目,下载需要的语言字库文件,例如中文字库:chi_sim.traineddata下载后放到该目录即可。
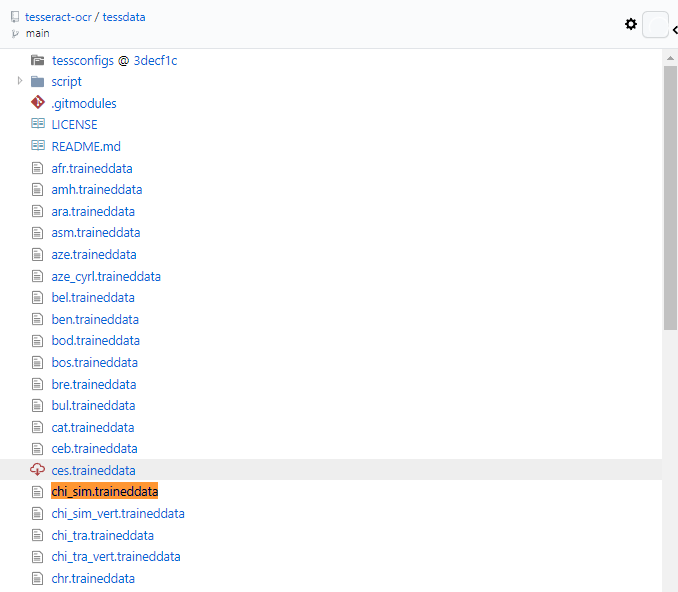
或者访问:https://tesseract-ocr.github.io/tessdoc/Data-Files寻找合适的版本下载
2.配置环境变量
添加PATH环境变量,可方便的执行tesseract命令
D:\Development\Tesseract-OCR
添加TESSDATA_PREFIX变量名,将语言字库文件夹添加到变量中
D:\Development\Tesseract-OCR\tessdata
命令使用
打开命令行窗口,输入tesseract -v命令进行验证。
C:\Users\Admin>tesseract -v
tesseract v5.3.0.20221222leptonica-1.78.0libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0Found AVX2Found AVXFound FMAFound SSE4.1Found libarchive 3.5.0 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5 libzstd/1.4.5Found libcurl/7.77.0-DEV Schannel zlib/1.2.11 zstd/1.4.5 libidn2/2.0.4 nghttp2/1.31.0
显示帮助
C:\Users\Admin>tesseract --help
Usage:tesseract --help | --help-extra | --versiontesseract --list-langstesseract imagename outputbase [options...] [configfile...]OCR options:-l LANG[+LANG] Specify language(s) used for OCR.
NOTE: These options must occur before any configfile.Single options:--help Show this help message.--help-extra Show extra help for advanced users.--version Show version information.--list-langs List available languages for tesseract engine.
显示当前训练语言列表
C:\Users\Admin>tesseract --list-langs
List of available languages in "D:\Development\Tesseract-OCR/tessdata/" (3):
chi_sim
eng
osd
语法
英文: tesseract imagename outputbase [-l lang] [--psm pagesegmode]中文:命令程序 被识别图片 输出文件 -l 语言 --psm 识别级别
-l eng:代表使用英语识别-psm 7:表示用单行文本识别
pagesegmode可选值:
0 =定向和脚本检测(OSD)
1 =带OSD的自动页面分割
2 =自动页面分割,但没有OSD或OCR
3 =全自动页面分割,但没有OSD(默认)
4 =假设一列可变大小的文本
5 =假设一个统一的垂直对齐文本块
6 =假设一个统一的文本块
7 =将图像作为单个文本行处理
8 =把图像当作一个单词
9 =把图像当作一个圆圈中的一个词来对待
10 =将图像作为单个字符处理
测试验证
tesseract.exe D:\dev\test.png D:\dev\out -l eng --psm 7
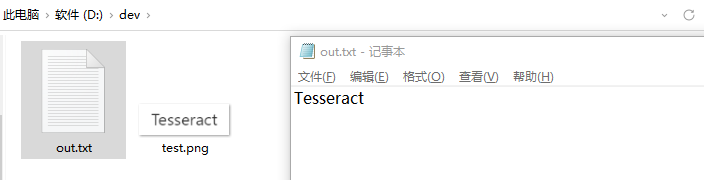
tesseract.exe D:\dev\test2.png D:\dev\out -l chi_sim --psm 7
Tesseract的使用
安装python库
# PIL用于打开图片文件
pip/pip3 install pillow# pytesseract模块用于从图片中解析数据
pip/pip3 install pytesseract
基本使用
# 导入模块
import pytesseract
# 导入图片库,需要安装库: pip install Pillow
from PIL import Image# 创建图片对象,使用pillow库加载图片
image = Image.open("E:\\dev\\test.png")# 识别图片
text = pytesseract.image_to_string(image, config="--psm 7")
print(text)
可能的异常
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
方案一:
# 导入模块
import pytesseract
# 导入图片库,需要安装库: pip install Pillow
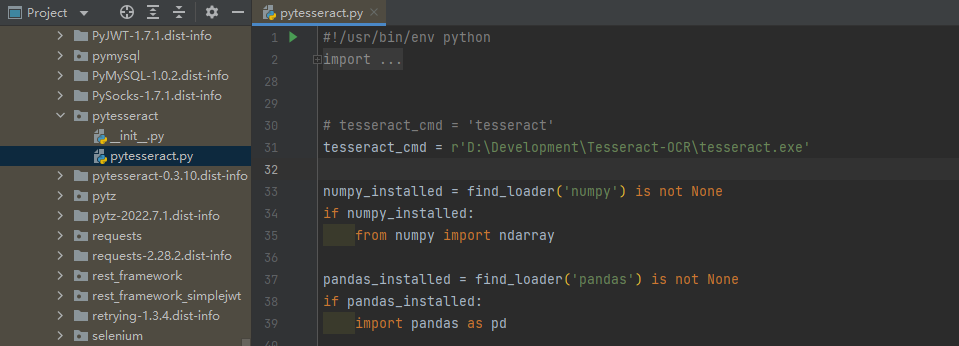
from PIL import Image# 指定tesseract目录,该目录是安装tesseract-OCR的目录:
pytesseract.pytesseract.tesseract_cmd = r'D:\Development\Tesseract-OCR\tesseract.exe'# 创建图片对象,使用pillow库加载图片
image = Image.open("E:\\dev\\test.png")
# 识别图片
text = pytesseract.image_to_string(image, config="--psm 7")
print(text)
方案二:
在pytesseract库下的pytesseract.py文件中找到tesseract_cmd = ‘tesseract’,修改成
tesseract_cmd = r'D:\Development\Tesseract-OCR\tesseract.exe'
D:\Development\Python\env\py\Scripts\python.exe D:/WorkSpace/Python/demo/apps/zd_admin/test/test.py
TesseractProcess finished with exit code 0
更换语言字体库识别
# 导入模块
import pytesseract
# 导入图片库,需要安装库: pip install Pillow
from PIL import Image# 指定tesseract目录,该目录是安装tesseract-OCR的目录:
pytesseract.pytesseract.tesseract_cmd = r'D:\Development\Tesseract-OCR\tesseract.exe'# 创建图片对象,使用pillow库加载图片
image = Image.open("E:\\dev\\test2.png")# 使用tesseract识别图像的文字,chi_sim中文简体:
text = pytesseract.image_to_string(image, lang='chi_sim', config='--psm 6')
print(text)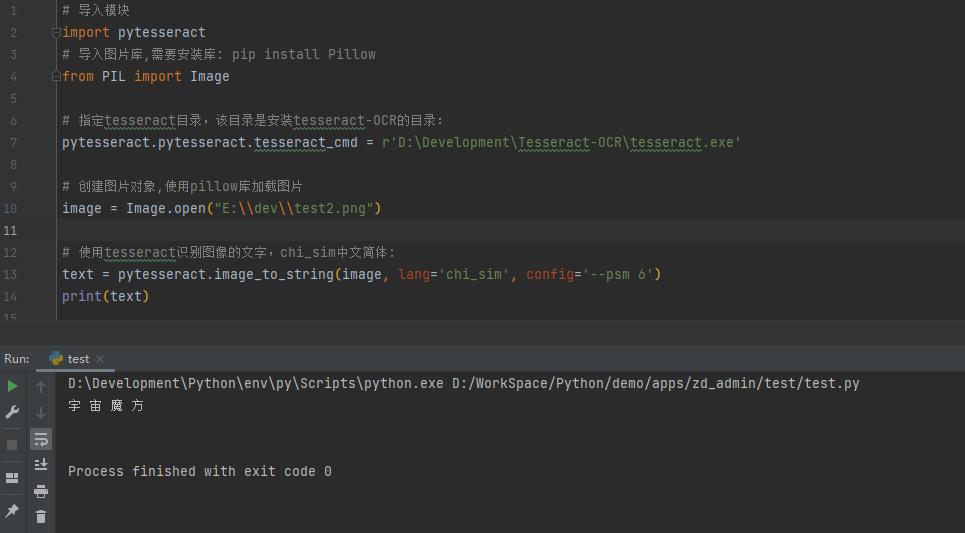
Tesseract的训练
Tesseract的识别是有点不够准确,因此可以进行Tesseract的训练提高tesseract识别字符准确率。
Tesseract是支持多种语言的识别,需要下载并安装相应语言的训练数据文件,这些文件可以在Tesseract的GitHub页面的
essdata目录中找到。
Tesseract的训练可以使用
jTessBoxEditor训练工具来训练样本



时非法字符输入导致的死循环的原因及解决方法)
学习总结)

元素组成)







)
)



)