【问题】
今天有A问我一个问题,我明明创建了一个物化视图,源表是有数据的,为什么查询物化视图就没有数据?
创建物化视图的SQL示意如下:
CREATE MATERIALIZED VIEW schema1.test_mvon cluster clusterNameTO schema1.test_dtl(`field_a` UInt64,`field_b` UInt32,`field_f` Int8)
AS
SELECT t1.field_a,t2.field_b,t3.field_f
FROM schema1.table1 AS t1LEFT JOIN(SELECT field_a,field_bFROM schema1.table4 t4) AS t2 ON t1.field_a = toUInt64(t2.field_a)LEFT JOIN schema1.table3 AS t3 ON t2.field_b = t3.field_e
WHERE (t1.create_type = 1)
A的意思是
SELECT t1.field_a,t2.field_b,t3.field_f FROM schema1.table1 AS t1LEFT JOIN(SELECT field_a,field_bFROM schema1.table4 t4) AS t2 ON t1.field_a = toUInt64(t2.field_a)LEFT JOIN schema1.table3 AS t3 ON t2.field_b = t3.field_e WHERE (t1.create_type = 1)
是有数据的,但是直接查
select * from schema1.test_mv是没数据的
由于我很久没有用物化视图,也是愣了一下,自己动手做了些实验才搞懂。
其实,如果熟悉clickhouse物化视图的特性,就知道创建的物化视图并不会把创建之前的数据给加载进来,只会把创建物化视图后的数据加载进来,所以一开始查不到数据是正常的。
借这个机会,我也边做实验边复习了一下物化视图的相关知识。
物化视图的机制是什么
一个物化视图的实现是这样的:当向SELECT中指定的表插入数据时,检测到有物化视图跟它关联,会针对这批写入的数据进行物化操作。即插入数据的一部分被这个SELECT查询转换,结果插入到视图中。
物化视图其实是数据库中的预计算逻辑+显式缓存,典型的空间换时间思路。
物化视图可以计算聚合,重组表主索引和排序顺序,可以很好地跨大量节点和处理大型数据集。
因此,ClickHouse 中的物化视图更像是插入触发器。 如果视图查询中有一些聚合,则它仅应用于一批新插入的数据。 对源表现有数据的任何更改(如更新、删除、删除分区等)都不会更改物化视图。
为什么需要物化视图
想像一个场景:有一个大的用户日志表,需要每个小时统计一些用户行为指标(例如登录时长)
如果每个小时都从这个大表里面去读,则由于数据量太大,效率很慢,而且对这个表的压力会很大(尤其是各种指标需求都需要访问这个表)。
有一个方法:如果对 用户日志表 进行预聚合,把结果保存到一个新表 xx_mv,并随着 用户日志表 增量实时更新,每次去查询xx_mv 就可以了。
这就是物化视图的其中一个作用。
为何物化视图比表查询快
一般来说物化视图会快一些。
因为物化视图相当于物理表,已经将符合条件的数据存入物理的物化视图表中,查询已经和原来的基表没有关系,因此一般来说物化视图的数据量会远小于原来的基表。
而直接查询或者使用一般的视图还是要在原来的基表中查询。
物化视图在复杂的SQL查询的时候效果就很明显了,可以把一个查询出来的数据存到物理空间里,还可以创建索引、排序等等。
下面我们用具体的实验例子来看看这些特性。
物化视图的几个有趣的特性
物化视图与表一样可以指定表引擎、分区键、主键和表设置参数
例如:
CREATE MATERIALIZED VIEW test_mv
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(ctime) ORDER BY (userid)
AS SELECT
xxx
FROM table WHERE ctime >= toDateTime('2024-01-01 00:00:00')
GROUP BY userid
物化视图并不会把创建之前的数据给加载进来
准备表table1,table2,talbe4,里面灌入相关数据,然后执行:
SELECT t1.field_a, t1.field_b, t3.field_f FROM schema1.table1 AS t1 LEFT JOIN ( SELECT field_a, field_b FROM schema1.table4 t4 ) AS t2 ON t1.field_a = toUInt64(t2.field_a) LEFT JOIN schema1.table3 AS t3 ON t2.field_b = t3.field_e WHERE (t1.create_type = 1)
返回数据是500+
此时还没创建物化视图
然后创建物化视图:
CREATE MATERIALIZED VIEW schema1.test_mvon cluster clusterNameTO schema1.test_dtl(`field_a` UInt64,`field_b` UInt32,`field_f` Int8)
AS
SELECT t1.field_a,t2.field_b,t3.field_f
FROM schema1.table1 AS t1LEFT JOIN(SELECT field_a,field_bFROM schema1.table4 t4) AS t2 ON t1.field_a = toUInt64(t2.field_a)LEFT JOIN schema1.table3 AS t3 ON t2.field_b = t3.field_e
WHERE (t1.create_type = 1)
其中schema1.test_dtl是新表的实体表,里面数据是空的。
查询创建好的物化视图和物化视图表:
select * from schema1.test_mv
select * from schema1.test_dtl
均返回空,表明物化视图并不会把创建之前的数据给加载进来
然后往table1中插入数据:
insert into schema.table1(field_a,create_type) values(1,1),(2,1);
然后查询
物化视图和物化视图表:
select * from schema1.test_mv
select * from schema1.test_dtl
均返回相同的两条数据,表明当向SELECT中指定的表插入数据时,检测到有物化视图跟它关联,会针对这批写入的数据进行物化操作
这里就有一个问题:为什么有了物化视图,还需要加个物化视图表?
其实就是问要不要创建物化视图时进行 [TO[db.]name] 配置
如果创建物化视图时不带TO [db].[table],且必须指定ENGINE用于存储数据的表引擎,和建表类似,这种方法ClickHouse会创建一个隐藏的目标表(私有表)来保存视图数据,可以通过SHOW TABLES查看(inner_id开头的表);删除视图,私有表会消失;
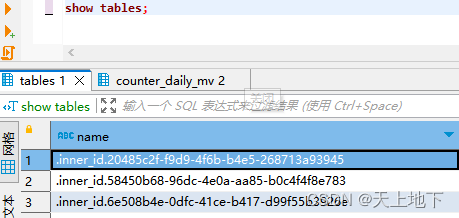
如果使用TO [db].[table]创建物化视图,[db].[table]必须是一张已经存在的表,用来保存视图数据,此时创建物化视图相当于在表上面附加了一个物化视图。
需要注意,间接创建不能使用POPULATE关键字。
配置的好处:可以明确指定物化视图的存储位置,避免与其他表或视图产生名称冲突或者误删误操作。
另外,如果物化视图表本身是有数据的,那么在创建物化视图后,该物化视图就会含有该物化视图表的数据。
不指定POPULATE时如何初始化
clickhouse有POPULATE关键字的,但是不建议使用POPULATE,因为在创建视图期间插入基础表中的数据不会被插入物化视图,会造成数据的丢失。
如果指定POPULATE,则在创建视图时将现有表数据插入到视图中,就像创建一个CREATE TABLE ... AS SELECT ...一样。
那么在不用POPULATE的前提下,怎么进行物化视图的初始化?其实很简单:在 MV 建好之后将数据手动insert into test_mv select * from 来导入数据到 MV
对源表现有数据的任何更改(如更新、删除、删除分区等)都不会更改物化视图
还是使用上面创建好的test_mv,由于前面我们执行
insert into schema.table1(field_a,create_type) values(1,1),(2,1);
所以目前test_mv里面有两条数据。
我们修改table1中的数据:
alter table schema.table1_replica(本地表) on cluster clusterName
update create_type=2 where field_a=1
按照前面的创建物化视图的sql,我们知道只会把schema.table1里面create_type=1的数据纳入物化视图,因此,我们去查现有的test_mv:
select * from schema1.test_mv
仍然是原先是两条数据。
因此可以证明,对源表现有数据的修改,不会更改物化视图。
同理,物化视图不支持同步删除,若源表的数据不存在(删除了)则物化视图的数据仍然保留
在创建 MV 表时如用到了多表联查,只有当第一个查询的表有数据插入时,这个 MV 才会被触发
还是使用上面创建好的test_mv,目前有两条数据
(field_a,field_b,create_type) ==>(1,0,1),(2,0,1);
我们插入table4的数据:
insert into cs_data.table4(field_a,field_b) values(1,99999) ,(2,8888);
然后查询test_mv,发现数据没变,仍然是:
(field_a,field_b,create_type) ==>(1,0,1),(2,0,1);
而不是(field_a,field_b,create_type) ==>(1,99999,1),(2,888,1);
表明在创建 MV 表时如用到了多表联查,只有当第一个查询的表有数据插入时,这个 MV 才会被触发
无缝更改ClickHouse物化视图SELECT逻辑的方法
无缝更改ClickHouse物化视图SELECT逻辑的方法-CSDN博客
物化视图的缺点
1.空间换时间,因此占空间。
2.使用难度较大,需要合理设计表结构对历史数据做聚合分析
3.仅支持插入触发,不支持历史数据的更新
4.它的本质是一个流式数据的使用场景,是累加式的技术,所以要用历史数据做去重、去更新的场景,就不适合
因此,如果一张表加了好多物化视图,在写这张表的时候,就会消耗很多机器的资源,比如数据带宽占满、存储一下子增加了很多。
物化视图适合的场景
1.解决表索引问题,我们可以用物化视图创建另外一种物理序,来满足某些条件下的查询问题。
2.可以借助 MergeTree 家族引擎(SummingMergeTree、Aggregatingmergetree等),得到一个实时的预聚合,满足快速查询。




:数值和序列)






)
)





![中间件 | Redis - [基本信息]](http://pic.xiahunao.cn/中间件 | Redis - [基本信息])
