1. 文件路径
/etc/kubeedge/config
edgecore.yaml是该目录下唯一的文件
附上链接:edgecore.yaml
2. 文件生成方式
2.1 方式一
使用keadm安装部署的方式,执行完keadm join --cloudcore-ipport=cloudcore监听的IP地址:端口(默认为10002) --token=获取到的token字符串后自动生成。
![[图片]](https://img-blog.csdnimg.cn/direct/5e1555a622f248068d7477b08aa0e0c2.png)
执行后,edgecore节点会自行使用systemctl进行管理,并加入开机启动项,同时启动edgecore节点,此时edgecore节点的运行状态不一定正常。
若edgecore状态不正常,修改并检查配置文件edgecore.yaml。
然后重启
systemctl restart edgecore
2.2 方式二
如果使用二进制安装,需要先获取初始的最小化edgecore配置文件:(/etc/kubeedge/config路径),或者
–defaultconfig创建完整配置文件。
edgecore --minconfig > edgecore.yaml
启动edgecore服务
nohup ./edgecore --config edgecore.yaml 2>&1 > edgecore.log &
nohup : no hang up(不挂起),用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。
2>&1 : 将标准错误 2 重定向到标准输出 &1 ,标准输出 &1 再被重定向输入到 edgecore.log 文件中。
0 – stdin (standard input,标准输入)
1 – stdout (standard output,标准输出)
2 – stderr (standard error,标准错误输出)
在命令的末尾加个&符号后,程序可以在后台运行。
3. 总体层次概述
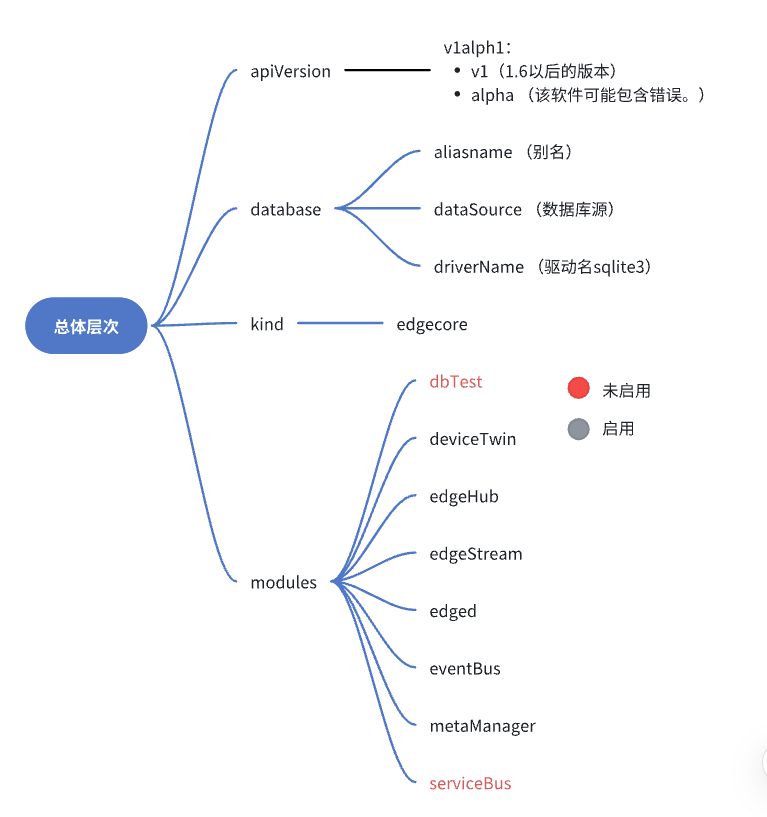
4. modules 组件概述
| 组件名 | 意义 |
|---|---|
| dbTest | 测试数据库性能 |
| deviceTwin | 设备的动态属性 |
| edgeHub | 通信接口,WebSocket 客户端,用于云边消息同步 |
| edgeStream | 支持ApiServer向Kubelet发起的containerLog、exec和metrics请求。云边隧道基于WebSocket建造,支持双向传输和流式传输 |
| edged | 管理边缘的容器化应用程序,一个运行在 edge 节点的 agent 程序 |
| eventBus | 使用MQTT处理内部边缘通信。 |
| metaManager | 管理边缘节点上的元数据。 |
| serviceBus | HTTP 客户端与 HTTP 服务器使用 REST 进行交互,为云端组件提供 HTTP 客户端功能,使其请求到达运行在边缘端的 HTTP 服务器 |
![[图片]](https://img-blog.csdnimg.cn/direct/9adc1810a1334116bac2cd329bf4a6b0.png)
5. edged解析
5.1 edged启动原理
EdgeD是管理节点生命周期的边缘节点模块,(轻量化的 kubelet),它可以帮助用户在边缘节点上部署容器化的工作负载或应用程序。这些工作负载可以执行任何操作,从简单的远程遥测数据操作到分析或ML推理等等。使用kubectl云端的命令行界面,用户可以发出命令来启动工作负载。
通过容器运行时接口Container Runtime Interface(CRI)支持几种符合OCI的运行时runtimes。请参阅KubeEdge运行时配置,以获取有关如何配置边缘以利用其他运行时的更多信息。
edged内部模块如图所示:
当edged启动时,首先初始化并启动各个模块,最后进行pod的sync。
各组件说明:edged
![[图片]](https://img-blog.csdnimg.cn/direct/c80b52bc45ba448a8e325ae9f26af042.png)
当edged启动时,首先初始化并启动各个模块,最后进行pod的sync。下面以一个pod的创建来看一下edged中各个模块是如何协作完成pod的生命周期管理的。
当edged接收到pod的insert消息时,将pod所有信息加入podmanager、probemanager,podAdditionQueue加入node-namespace/node-name信息。
启动一个goroutine,创建下发到此节点的pod。
![[图片]](https://img-blog.csdnimg.cn/direct/3a553ffdc327466982d547df2319bd26.png)
此时我们根据pod的定义成功创建pod,之后还要对pod的状态进行管理。
启动一个goroutine执行syncLoopIteration()函数:
①当liveness探针的结果更新,若内容是“failure”,根据container的restart policy执行相应的操作,比如:never->do nothing;onfailed->判断container的status,若completed->do nothing,否则将加podAdditionQueue,等待被再次创建;always->加入podAddtionQueue,等待被再次创建。
②当收到PLEG的event,更新podmanager中podstatus(containerruntime中获取当前sataus,probemanager更新ready状态),更新statusmanager中的缓存podstatus。若event是containerdied,则根据restart policy执行相应操作。
另外,statusmanager中会定时(10s)将podstatus上传至metamanager
![[图片]](https://img-blog.csdnimg.cn/direct/78b56ab23ca9455384892c01e91aed89.png)
…
Edged 的注册和启动过程代码在 edge/pkg/edged/edged.go 中。
edged.go源码
5.2 edged配置项解析
kubeedge官网解释:https://kubeedge.io/zh/docs/architecture/edge/edged
edged:cgroupDriver: cgroupfs #cri的cgroup驱动程序配置为cgroupfscgroupRoot: "" #默认为空,使用底层containter runtime的cgroup root,一般是 /sys/fs/cgroup/cgroupsPerQOS: true #对应 pod 容器的 QOS 级别clusterDNS: "" #集群dns(默认dns)clusterDomain: "" #集群域(默认域)cniBinDir: /opt/cni/bin #放可执行的原生CNI插件。cniCacheDirs: /var/lib/cni/cache #存储运行容器的网络配置信息cniConfDir: /etc/cni/net.d #CNI的配置文件,在不同CNI插件中表现为NetworkConfig结构体的差异。concurrentConsumers: 5 #并发devicePluginEnabled: false #设备插件是否启用dockerAddress: unix:///var/run/docker.sock #Docker守护进程通信edgedMemoryCapacity: 7852396000 #边缘内存容量enable: trueenableMetrics: true #一个集群范围内的资源数据集和工具,只是显示数据,并不提供数据存储服务gpuPluginEnabled: false #gpu插件hostnameOverride: edgezh1-virtual-machine #覆盖名imageGCHighThreshold: 80 #垃圾回收高阈值imageGCLowThreshold: 40 #垃圾回收低阈值imagePullProgressDeadline: 60maximumDeadContainersPerPod: 1networkPluginMTU: 1500nodeIP: 192.168.2.101nodeStatusUpdateFrequency: 10podSandboxImage: kubeedge/pause:3.1registerNode: trueregisterNodeNamespace: defaultremoteImageEndpoint: unix:///var/run/dockershim.sockremoteRuntimeEndpoint: unix:///var/run/dockershim.sockruntimeRequestTimeout: 2runtimeType: docker
5.2.1 cgroup
cgroup是什么?
Cgroup (Control Group)是对一组进程的资源使用(CPU、内存、磁盘 I/O 和网络等)进行限制、审计和隔离。
![[图片]](https://img-blog.csdnimg.cn/direct/42e06a2d88ec4e0d9b6552fe71659e1b.png)
cgroups(Control Groups) 是 linux 内核提供的一种机制。(对多组,暂时场景不是多组,所以不深入探究)。
cgroupfs:
类似于procfs和sysfs,是一种虚拟文件系统。并且cgroupfs是可以挂载的,默认情况下挂载在/sys/fs/cgroup目录。
![[图片]](https://img-blog.csdnimg.cn/direct/df3e587fe83347f9818b63b041715f74.png)
![[图片]](https://img-blog.csdnimg.cn/direct/8e554a97ce3e4517baebcbb4b55f41f8.png)
三个核心功能:
分组:根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内。
限制:可以限制、记录任务组所使用的物理资源。
调度:内核附加在程序上的一系列钩子(hook),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
cgroup如何分组?
可以先看这个目录层次,或者到云端设备上查看。
内容较多,资源切分方面可根据下图的指引结合理解。

- cgroup.clone_ children, cpuset 的 subsystem 会读取这个配置文件,如果这个值是 1 (默认是 0),子 cgroup 才会继承父 cgroup 的 cpuset 的配置。
- cgroup.procs 是树中当前节点 cgroup 中的进程组 ID,现在的位置是在根节点,这个文件中会有现在系统中所有进程组的 ID。
- notify_on_release 和 release agent 会一起使用。 notify_on_release 标识当这个 cgroup 最后一个进程退出的时候是否执行了 release_agent; release_agent 则是一个路径,通常用作进程退出之后自动清理掉不再使用的 cgroup。
- tasks 标识该 cgroup 下面的进程 ID,如果把一个进程 ID 写到 tasks 文件中,便会将相应的进程加入到这个 cgroup 中。
cgroupsPerQOS配置项中提到QoS级别是什么?

cgroup如何限制?
https://zhuanlan.zhihu.com/p/636467664
对cgroup的基本操作:https://zhuanlan.zhihu.com/p/651405353
以一个关联cpu和memory的一个控制组my_group为例子,
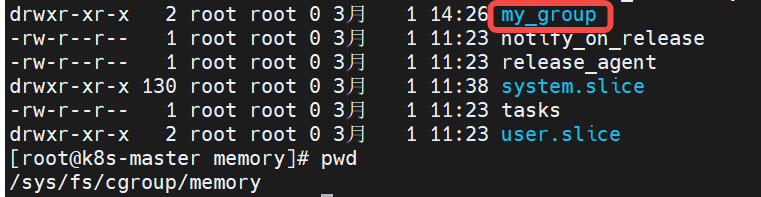
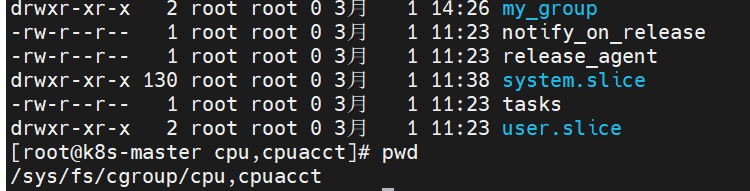
Container级别:
路径:
- Guaranteed container:默认 /sys/fs/cgroup/{controller}/kubepods/{pod_id}/{container_id}/;
- Burstable container:默认 /sys/fs/cgroup/{controller}/kubepods/burstable/{pod_id}/{container_id}/;
- BestEffort container:默认 /sys/fs/cgroup/{controller}/kubepods/besteffort/{pod_id}/{container_id}/。
一个资源申请(容器)的例子:
apiVersion: v1
kind: Pod
spec:containers:
name: busybox
image: busybox
resources:limits:cpu: 500m memory: "400Mi" requests:cpu: 250mmemory: "300Mi"
command: ["md5sum"]
args: ["/dev/urandom"]
在Kubernetes中,资源请求和限制通常使用以下单位来表示:
CPU:以"millicores"为单位,即千分之一的CPU核心。例如,1000m表示一个核心。
内存:以字节为单位(B),可以使用K、Ki、M、Mi、G、Gi等后缀来表示。例如,1Gi表示1GB。
requests 经过转换之后会写入 cpu.share, 表示这个 cgroup 最少可以使用的 CPU;
limits 经过转换之后会写入 cpu.cfs_quota_us, 表示这个 cgroup 最多可以使用的 CPU;
resources.requests.cpu:指定容器所需的CPU资源数量;
resources.requests.memory:指定容器所需的内存资源数量;
resources.limits.cpu:指定容器的CPU资源限制;
resources.limits.memory:指定容器的内存资源限制。
Pod 级别:
Pod 配置在 QoS cgroup 配置的下一级,
- Guaranteed Pod:默认 /sys/fs/cgroup/{controller}/kubepods/{pod_id}/;
- Burstable Pod:默认 /sys/fs/cgroup/{controller}/kubepods/burstable/{pod_id}/;
- BestEffort Pod:默认 /sys/fs/cgroup/{controller}/kubepods/besteffort/{pod_id}/。
kubelet 计算 pod requets/limits 的过程
一个Pod的容器的request和limits是通过在Pod的容器定义中设置资源请求和限制来确定的。
在Pod的容器定义中,可以为每个容器定义资源请求和限制。资源请求是指容器在运行时对某一资源(如CPU或内存)的需求量。资源限制是指容器在运行时对某一资源的最大使用量。
在计算一个Pod的所有容器的资源请求和限制时,Kubernetes将遵循以下规则:
如果一个容器没有设置资源请求和限制,Kubernetes将默认使用集群级别的资源限制。
如果一个Pod中的容器设置了资源请求,但没有设置资源限制,Kubernetes将使用资源请求作为容器的限制值。
如果一个Pod中的容器同时设置了资源请求和限制,Kubernetes将使用设置的资源请求和限制值。
总结起来,一个Pod的所有容器的资源请求和限制是根据容器定义中设置的值来计算的,如果没有设置则会采用默认值。这些资源请求和限制对于Kubernetes调度和资源管理非常重要,可以确保在容器运行时有足够的资源可用,并保证不会过度使用资源。
cgroup如何调度?
调度算法根据各 node 当前可供分配的资源量(Allocatable),为容器选择合适的 node; 注意,k8s 的调度只看 requests,不看 limits。
5.2.2 cni
kubelet创建/删除pod时,会调用CRI,然后CRI会调用CNI来进行pod网络的构建/删除。
cni标准规范也是一套标准的容器网络接口规范。
cniBinDir: /opt/cni/bin #放可执行的原生CNI插件。
cniCacheDirs: /var/lib/cni/cache #存储运行容器的网络配置信息
cniConfDir: /etc/cni/net.d #CNI的配置文件,在不同CNI插件中表现为NetworkConfig结构体的差异。
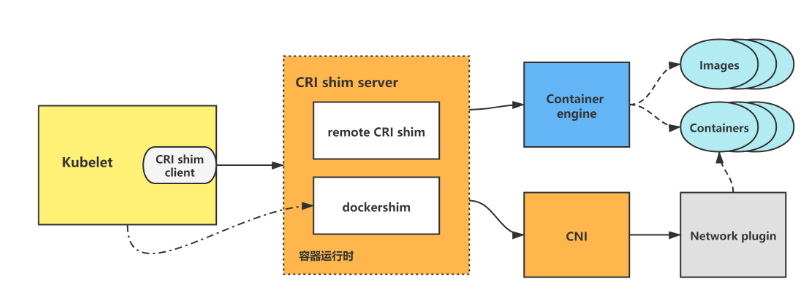
在这个示意图中,我们看到有一个容器运行时 (Container Runtime) 和多个不同的网络插件 (Network Plugins),它们可以是 Calico、Flannel、Weave 等等。CNI 提供了一个统一的接口,使得容器运行时可以与任何支持 CNI 规范的网络插件进行通信。
当一个容器启动时,容器运行时会调用 CNI 接口,并将容器的网络配置传递给网络插件。网络插件会根据配置信息来创建和管理容器的网络,同时也负责处理容器之间的通信。CNI 还定义了一些标准的网络配置参数,用于指定容器的 IP 地址、网关、子网等。
5.2.3 GC
垃圾回收机制(Garbage collection)的设计和实现
与镜像回收有关的主要有以下俩参数:
imageGCHighThreshold:表示一个 pod 最多可以保存多少个已经停止的容器,默认为1;
imageGCLowThreshold:一个 node 上最多可以保留多少个已经停止的容器,默认为 -1,表示没有限制;
镜像回收的过程如下:
当用于存储镜像的磁盘使用率达到百分之–image-gc-high-threshold时将触发镜像回收,删除最近最久未使用(LRU,Least Recently Used)的镜像直到磁盘使用率降为百分之–image-gc-low-threshold或无镜像可删为止。
查看当前磁盘使用率 :df -lh
储存docker的镜像信息:/var/lib/docker
官网说明:
- The image garbage collector is an edged routine which wakes up every 5 secs, and collects information about disk usage based on the policy used.
镜像垃圾收集器是一个边缘例程,每5秒唤醒一次,并根据所使用的策略收集磁盘使用信息。 - The policy for garbage collecting images takes two factors into consideration, HighThresholdPercent and LowThresholdPercent .
图像垃圾收集策略需要考虑两个因素:HighThresholdPercent和LowThresholdPercent。 - Disk usage above the high threshold will trigger garbage collection, which attempts to delete unused images until the low threshold is met.
磁盘使用率高于高阈值将触发垃圾收集,垃圾收集将尝试删除未使用的映像,直到达到低阈值。 - Least recently used images are deleted first.
首先删除最近最少使用的图像。
5.2.4 taints
- effect: NoSchedule key: node-role.kubernetes.io/edgevolumeStatsAggPeriod: 60000000000
每个污点的组成如下:
key=value:effect
每个污点有一个 key 和 value 作为污点的标签,其中 value 可以为空,effect 描述污点的作用。
当前 taint effect 支持如下三个选项:
NoSchedule :表示k8s将不会将Pod调度到具有该污点的Node上
PreferNoSchedule :表示k8s将尽量避免将Pod调度到具有该污点的Node上
NoExecute :表示k8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod驱逐出去
6. edgestream解析
Stream是KubeEdge中提供云边隧道的模块,目前支持ApiServer向Kubelet发起containerLog、exec和metrics请求。云边隧道基于WebSocket建造,支持双向传输和流式传输。
参考自:
edgestream启动原理
主要功能是启动创建websocket
- 读取本地的证书配置
- 连接cloud 端的 tunnel server(也就是下面提到的server端)
edgeStream: handshakeTimeout: 30 #握手超时时间(second) default 30readDeadline: 15 #读取证书的截止时间:15s内server: 1.94.44.163:30004tlsTunnelCAFile: /etc/kubeedge/ca/rootCA.crttlsTunnelCertFile: /etc/kubeedge/certs/server.crttlsTunnelPrivateKeyFile: /etc/kubeedge/certs/server.key writeDeadline: 15 #写证书的截止时间:15s内
7. edgeHub解析
官网解释
EdgeHub是Azure IoT Edge的核心组件之一,是一个轻量级的消息路由器,用于在边缘设备上与云平台进行通信。它起到了以下几个作用:
-
消息路由:EdgeHub允许边缘设备与云平台之间进行双向的消息传递。它可以接收来自云平台的消息,并将其路由到边缘设备上运行的模块,也可以将来自边缘设备的消息发送到云平台。这种消息路由的能力使得边缘设备能够与云平台进行实时的通信和数据交换。
-
模块通信:在边缘设备上运行的模块之间可能需要相互通信,例如将传感器数据从一个模块传递给另一个模块进行处理。EdgeHub提供了一个统一的消息传递机制,使得模块之间可以通过发送和接收消息进行通信。这种模块之间的通信能力使得边缘设备上的各个模块可以协同工作,共同完成复杂的任务。
-
安全性:EdgeHub提供了对消息传输的安全保护。它使用TLS来加密消息,以确保消息在传输过程中的机密性和完整性。此外,EdgeHub还支持设备身份验证和授权,只有经过身份验证的设备才能与边缘设备进行通信,从而增加了系统的安全性。
总的来说,EdgeHub在边缘端起到了消息路由、模块通信和安全性保护等重要作用,使得边缘设备能够与云平台进行可靠的通信,并提供了模块之间的协同工作能力。
edgeHub: #通信接口,WebSocket 客户端,用于云边消息同步enable: trueheartbeat: 15 #根据心跳时间向云端发送心跳 15s发一次httpServer: https://1.94.44.163:30002 #httpclient:用于与EdgeCore与CloudCore通信所需证书的申请projectID: e632aba927ea4ac2b575ec1603d56f10quic: #quic client:负责与CloudCore的日常通信(资源下发、状态上传等)enable: falsehandshakeTimeout: 30 #握手超时时间:30s(默认30)readDeadline: 15 #读取证书的截止时间:15s内server: 1.94.44.163:30001writeDeadline: 15rotateCertificates: true #证书轮转tlsCaFile: /etc/kubeedge/ca/rootCA.crttlsCertFile: /etc/kubeedge/certs/server.crttlsPrivateKeyFile: /etc/kubeedge/certs/server.keytoken: 111900b80a0a2a87b0910b2590963e5dadbfa56f977810909b7eabdf0cc1668c.eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3MDY1NjMzNDF9.QSRQsMmL_YZQFEfLC0r0Rr6_HgNBKmBPvs50VLfHGnUwebsocket: #websocket:负责与CloudCore的日常通信(资源下发、状态上传等)enable: truehandshakeTimeout: 30readDeadline: 15server: 1.94.44.163:30000writeDeadline: 15
8. MetaManager解析
官网解释
MetaManager在edge端的作用是对边缘设备进行管理和控制。它能够对边缘设备的资源进行监控和调度,管理边缘计算节点和资源的分配,以及实现边缘设备的远程配置和更新。通过MetaManager,用户可以实现对边缘设备的集中管理,提升边缘计算的效率和可靠性。
metaManager: #它管理边缘节点上的元数据。contextSendGroup: hubcontextSendModule: websocket #上下文发送的模块,客户端和服务端之间建立tcp连接的通信enable: truemetaServer:enable: falseserver: 127.0.0.1:10550podStatusSyncInterval: 60 #定期发送MetaSync操作消息的同步间隔,同步pod状态,60s(默认)。remoteQueryTimeout: 60 #发送请求超时时间,60s(默认)
9. DeviceTwin解析
官网解释
在Edge设备上,Device Twin是Azure IoT Hub提供的一个关键功能。它允许开发人员在设备端和云端之间同步设备的状态和属性。
具体而言,Device Twin在Edge端的作用包括:
-
设备状态管理:Device Twin允许设备端将其当前状态(如温度、湿度、电池电量等)报告给云端,并将其保存为设备的状态属性。这样,云端可以随时了解设备的最新状态。
-
远程配置:设备端可以使用Device Twin获取来自云端的配置信息,并根据配置信息调整自己的行为。这样,设备可以动态地适应不同的环境和需求。
-
双向通信:Device Twin允许设备端和云端之间进行双向通信。设备可以向云端发送命令、请求或报告设备状态,云端可以向设备端发送配置信息、命令或其他指令。
-
设备拓扑管理:Device Twin允许设备端创建和管理设备拓扑。设备可以将自己作为父设备或子设备与其他设备进行关联,并在Device Twin中管理这些关联关系。
总的来说,Device Twin在Edge端提供了一种可靠的、双向的设备与云端之间的通信机制,使得设备可以灵活地与云端进行交互,并根据云端的配置和指令适应不同的场景和需求。在Edge设备上,Device Twin是Azure IoT Hub提供的一个关键功能。它允许开发人员在设备端和云端之间同步设备的状态和属性。
10. EventBus解析
EventBus在边缘端起到了以下作用:
-
事件发布与订阅:EventBus允许在边缘端组件之间进行松散耦合的通信,组件可以发布事件,并且其他组件可以订阅这些事件。这种事件驱动的机制能够提高边缘端的可扩展性和灵活性。
-
实时数据传递:边缘端的设备和传感器通常会产生大量的实时数据。EventBus可以用于在边缘端不同组件之间实时传递数据,实现实时数据的处理和分发。这种实时的数据传递能够帮助边缘端系统实时响应和处理数据。
-
解耦和管理:EventBus可以解耦边缘端的不同组件,使它们之间的通信更加灵活和可扩展。通过订阅事件的方式,组件之间不需要直接耦合在一起,降低了代码的依赖性和复杂性。同时,EventBus还可以管理事件的发布和订阅,确保事件的交付和处理。
-
系统集成:边缘端的系统往往由多个组件和服务组成,这些组件和服务可能来自不同的厂商或者遵循不同的通信协议。EventBus可以作为一个中间件,帮助不同的组件和服务进行集成和协同工作。通过发布和订阅事件的方式,不同的组件可以通过EventBus进行通信和协作。
总之,EventBus在边缘端起到了解耦和管理组件之间通信、实时数据传递、系统集成等作用,提高了边缘端系统的可扩展性、灵活性和实时性。
eventBus: #使用MQTT处理内部边缘通信。enable: trueeventBusTLS:enable: falsetlsMqttCAFile: /etc/kubeedge/ca/rootCA.crttlsMqttCertFile: /etc/kubeedge/certs/server.crttlsMqttPrivateKeyFile: /etc/kubeedge/certs/server.keymqttMode: 2 #启用内部 mqtt 代理(mqttMode=2)。mqttQOS: 0mqttRetain: falsemqttServerExternal: tcp://127.0.0.1:1883mqttServerInternal: tcp://127.0.0.1:1884mqttSessionQueueSize: 100
(mqttMode=0):bothMqttMode:启用内部和外部代理(mqttMode=1):externalMqttMode:仅启用外部代理
11. ServiceBus解析
在边缘端,ServiceBus起多个作用:
ServiceBus在边缘端起到了连接边缘设备和云端的桥梁作用,提供可靠的消息传递、数据集成、高可用性和离线操作等功能。这使得边缘设备可以更好地与云端进行交互,并实现更强大的功能和应用场景。
serviceBus: enable: falseport: 9060server: 127.0.0.1timeout: 60




SpringCloud系列——openfeign的高级特性实战内容介绍)







)






