我们历尽千辛万苦,总算要部署模型了。这个系列也写到62篇,不要着急,后面还有很多。
这周偷懒了,一天放出太多的文章,大家可能有些吃不消,从下周开始,本系列将正常更新。
这套大厂AI课,非常经典,我已经通过这套课程,考过了腾讯云的人工智能TCA认证。
模型的部署要考虑很多问题,面临很多挑战。
比如语言,我们都是用R语言或者PYTHON来开发,但是部署时,很多时候需要转换成C或者JAVA。
我们还要考虑可移植性、可扩展性,还有算力的分配,等等。
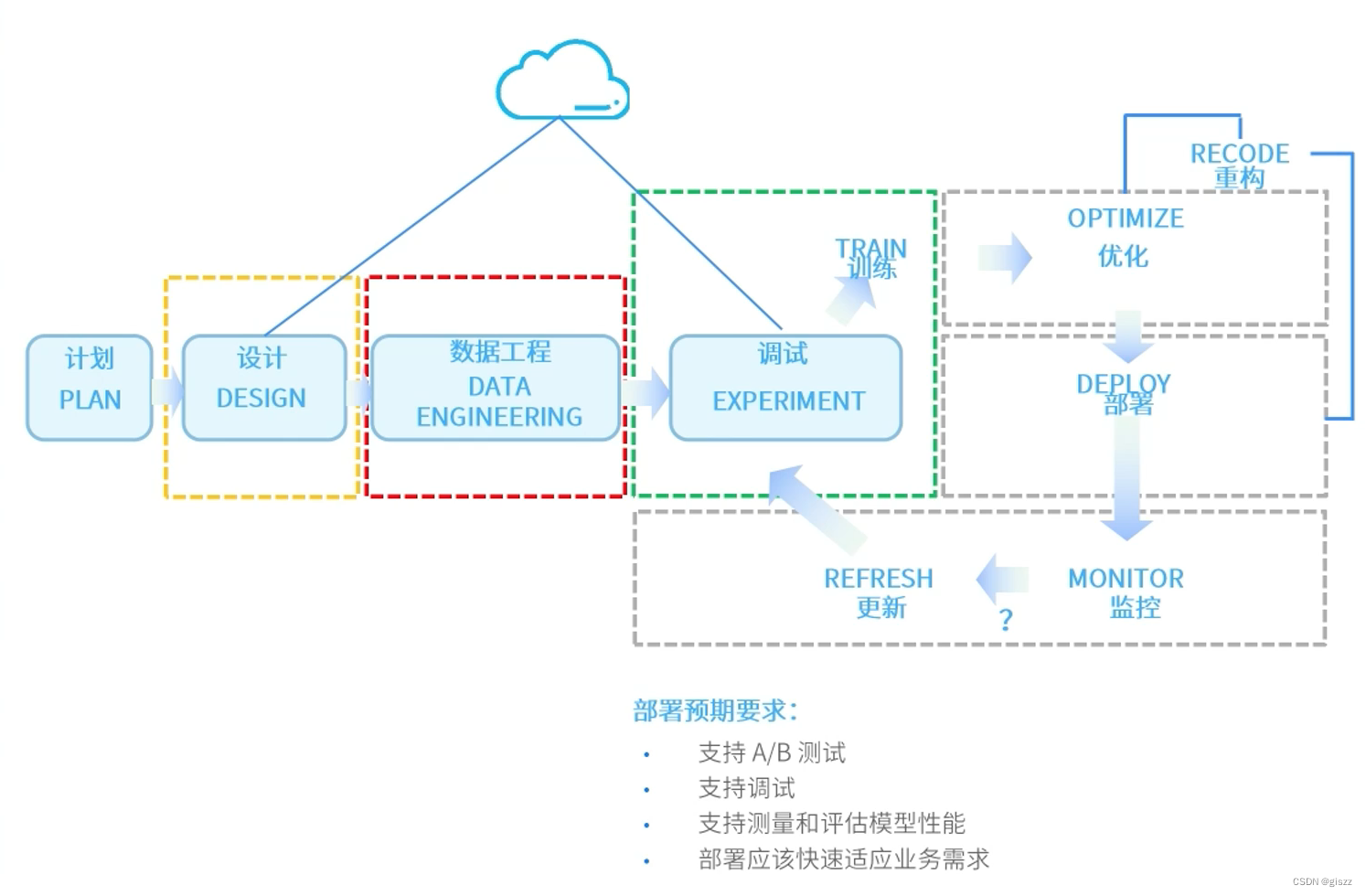
我们还需要需要模型引擎、工具库、数据转换器、模型库等。
需要支持常用编程脚本语言,及相关的工具库,docker,spark等。
模型部署是机器学习项目从开发到生产的关键步骤之一。在部署过程中,需要考虑代码的转换、算力的分配、部署工具的选择以及其他工程步骤。下面将详细阐述这些方面。
一、代码转换
在模型部署之前,通常需要将训练代码转换为推理代码。训练代码关注于模型的训练和优化,而推理代码则关注于使用训练好的模型进行预测。这个转换过程需要考虑以下几个方面:
- 模型格式转换:不同的深度学习框架(如TensorFlow、PyTorch等)可能使用不同的模型格式。在部署时,可能需要将模型转换为与部署环境兼容的格式,如TensorFlow Lite、ONNX等。这些格式通常针对移动设备或特定硬件进行了优化,以提高推理速度。
- 代码优化:推理代码需要尽可能高效,以减少预测时的延迟。这包括去除训练代码中的不必要部分(如反向传播、优化器等),以及使用针对推理的优化技术(如量化、剪枝等)。
- 输入/输出处理:推理代码需要能够处理来自实际应用的输入数据,并将其转换为模型可以接受的格式。同样,模型的输出也需要转换为应用可以理解的格式。这可能需要编写额外的数据预处理和后处理代码。
二、算力分配
算力分配是模型部署中的另一个重要问题。根据模型的大小和复杂性,以及预期的推理速度,需要选择合适的硬件来部署模型。这包括:
- CPU vs GPU vs TPU:中央处理器(CPU)适用于大多数简单的模型和小规模推理任务。然而,对于大规模的深度学习模型,图形处理器(GPU)或张量处理器(TPU)可能更合适,因为它们提供了更高的并行处理能力。
- 云端 vs 边缘计算:对于需要实时响应的应用(如自动驾驶、智能语音助手等),将模型部署在靠近用户的边缘设备上可能更有优势。这样可以减少数据传输延迟,提高响应速度。然而,对于不需要实时响应的应用(如批量数据分析、图像识别等),将模型部署在云端可能更经济高效。
- 弹性伸缩:在实际应用中,模型的推理请求量可能会随时间变化。因此,部署方案需要能够弹性地扩展或缩减算力资源,以满足不同时间段的需求。这可以通过使用云计算平台的自动扩展功能或容器编排工具来实现。
三、部署工具
选择合适的部署工具可以大大简化模型部署的过程。以下是一些常用的部署工具及其特点:
- Docker:Docker是一种容器化技术,它允许开发者将应用及其所有依赖项打包到一个可移植的容器中,然后将其部署到任何Docker环境中。使用Docker可以确保模型在不同环境中的一致性和可重复性。此外,Docker还提供了强大的容器编排和扩展功能,适用于大规模部署场景。
- Kubernetes:Kubernetes是一个开源的容器编排平台,它提供了自动扩展、自动故障恢复、自动日志收集等高级功能。使用Kubernetes可以轻松地管理和维护大规模的容器集群,适用于需要高可用性和弹性伸缩的部署场景。
- 模型服务框架:除了容器化技术外,还有一些专门用于模型部署的框架,如TensorFlow Serving、Clipper等。这些框架提供了针对机器学习模型的优化功能,如批量处理、模型版本管理、动态加载等。它们通常与特定的深度学习框架紧密集成,可以方便地部署和管理使用该框架训练的模型。
四、其他工程步骤
除了上述三个方面外,模型部署还涉及其他一些重要的工程步骤:
- 性能测试与调优:在部署之前,需要对模型进行性能测试以评估其推理速度和准确性。根据测试结果,可能需要对模型或推理代码进行优化以提高性能。这可能包括调整模型的参数、优化算法选择、减少不必要的计算等。
- 安全性与隐私保护:对于涉及敏感数据的应用(如人脸识别、语音识别等),需要确保模型部署过程中的安全性和隐私保护。这包括使用加密技术保护数据传输、对敏感数据进行脱敏处理、限制对模型的访问权限等。此外,还需要定期更新和修补安全漏洞以防止潜在的安全风险。
- 监控与日志收集:部署后需要设置监控机制以实时跟踪模型的性能和稳定性。这包括收集模型的推理请求量、响应时间、错误率等指标,并设置相应的警报阈值以便及时发现问题。同时,还需要收集详细的日志信息以便进行故障排查和性能优化。这可以通过使用专门的监控和日志收集工具来实现。
- 版本管理与回滚:随着项目的进展和需求的变更,可能需要更新或替换已部署的模型。因此,需要建立完善的版本管理机制以跟踪不同版本的模型和推理代码。同时,还需要实现回滚功能以便在出现问题时能够迅速恢复到之前的稳定版本。这可以通过使用版本控制工具(如Git)和持续集成/持续部署(CI/CD)流程来实现。
- 文档编写与维护:为了方便其他开发者了解和使用已部署的模型,需要编写详细的文档说明模型的输入输出格式、使用方法、性能指标等信息。同时,还需要定期更新文档以反映模型的最新变化和最佳实践。这有助于提高项目的可维护性和团队协作效率。
综上所述,模型部署是一个涉及多个方面的复杂过程,需要综合考虑代码转换、算力分配、部署工具选择以及其他工程步骤等多个因素。通过合理规划和实施这些步骤,可以确保模型在生产环境中的高效运行和稳定性。
![[python] dict类型变量写在文件中](http://pic.xiahunao.cn/[python] dict类型变量写在文件中)



)


过拟合与欠拟合)

)
解决)








