
一、引言
在当今竞争激烈的汽车行业中,售后服务的质量已成为品牌成功的关键因素之一。作为一位经验丰富的项目经理,我曾参与构建一个全面的汽车售后服务网络,旨在为客户提供无缝的维修、保养和配件更换服务。这个项目的核心目标是通过高效的服务流程和客户关怀,提升客户满意度并增强品牌忠诚度。信息抽取技术的应用,使得我们能够从大量数据中提取有价值的客户洞察,从而优化服务流程和响应策略。通过这种方式,我们不仅维护了品牌形象,而且建立了一个强大的客户关系网络,为汽车制造商在市场中的长期成功奠定了基础。
二、用户案例
在项目初期,我们面临了一个重大挑战:如何高效地处理和分析客户的反馈信息,以便快速响应他们的需求和解决问题。客户反馈通常包含大量的非结构化数据,如电子邮件、社交媒体帖子和客服记录。这些数据中蕴含着丰富的信息,但需要先进的技术来进行有效的提取和分析。信息抽取技术正好满足了这一需求,它使我们能够自动从文本中识别出关键参数、属性、实体和事件,从而加快了我们对客户反馈的处理速度。
例如,在分析客户对某款新车的反馈时,我们使用参数抽取技术识别出了客户的里程数、车辆使用时间和维修频率等数据。这些数据帮助我们发现了一个潜在的质量问题:车辆在特定里程数后出现故障的概率显著增加。通过进一步的属性抽取,我们发现这一问题与车辆的特定部件材质有关。有了这些详细信息,我们能够及时通知生产线进行调整,并为客户提供免费的维修或更换服务。 在项目进行中,我们还面临着如何快速识别并处理客户的紧急维修请求的问题。信息抽取技术再次发挥了关键作用。
通过实体抽取,我们能够迅速识别出客户提到的车辆型号、故障描述和地理位置。这使得我们的服务团队能够立即响应,并且根据客户的具体情况,为他们安排最近的服务中心或派遣移动维修团队。此外,关系抽取技术帮助我们理解了客户与服务流程之间的相互作用,使我们能够优化服务流程,减少客户等待时间。 项目后期,我们利用事件抽取技术来分析客户在维修过程中的体验。我们从中识别出了客户在维修过程中的关键时间点,如预约时间、到店时间和维修完成时间。通过这些信息,我们能够评估服务流程的效率,并发现可能导致客户不满的瓶颈。例如,我们发现某些服务中心在周末的预约过于集中,导致客户等待时间过长。
基于这些发现,我们调整了预约系统,平衡了各个服务中心的预约分布,从而显著提升了客户的整体满意度。 通过这些具体的应用实例,我们可以看到信息抽取技术在汽车制造和售后服务领域的巨大潜力。它不仅提高了我们的工作效率,还帮助我们更好地理解和满足客户的需求,最终实现了项目的长期目标。
三、技术原理
在汽车制造领域,信息抽取技术的应用正成为提升生产效率和质量控制的关键。深度学习技术,特别是自然语言处理(NLP)的进步,使得从复杂的生产数据中自动提取信息成为可能。通过预训练语言模型,如BERT、GPT和XLNet,我们可以捕获语言的深层结构和语义,为后续的信息处理打下坚实基础。这些模型在大规模文本数据上经过训练,能够理解复杂的语言模式,为汽车制造过程中的信息处理提供了强大的支持。 针对特定的制造任务,预训练模型需要进行微调,以适应特定的信息抽取需求。例如,在生产线上,实体识别(NER)可以帮助识别关键的组件和设备信息;关系抽取(RE)可以揭示组件之间的相互关系及其与生产流程的关联;事件抽取(EE)则能够从日志和报告中提取生产事件,如故障、维护和质量检查。这些任务的微调通常涉及在特定领域的标注数据上进行训练,使得模型能够更准确地识别和理解与汽车制造相关的特定术语和概念。 序列标注技术在实体识别等任务中发挥着重要作用。

通过条件随机场(CRF)或双向长短时记忆网络(BiLSTM),模型能够对文本序列进行精确标注,识别出诸如部件编号、生产批次和质量标准等关键信息。这些技术能够捕捉文本中的长距离依赖关系,确保即使在复杂的句子结构中也能准确识别出相关信息。 对于更复杂的任务,如生产流程的优化和故障诊断,序列到序列(Seq2Seq)模型,尤其是基于注意力机制的Transformer模型,被用来处理输入序列并生成输出序列。这些模型能够理解生产数据的上下文信息,并生成有助于决策的输出,如优化建议或故障原因分析。 整个信息抽取过程通常通过端到端训练进行,这意味着从输入到输出的整个过程都在一个统一的训练框架下进行优化。这样的训练方式有助于提高模型的整体性能,确保在实际应用中能够快速准确地提取所需信息。
在模型训练过程中,通过准确率、召回率、F1分数等指标对模型性能进行评估,并根据评估结果进行调整。这可能包括调整学习率、优化网络结构或增加训练数据,以提高信息抽取的准确性和可靠性。 在汽车制造项目中,信息抽取技术的应用不仅提高了生产效率,还有助于质量控制和故障预防。通过自动分析生产数据,我们能够及时发现潜在的质量问题,优化生产流程,减少浪费,确保每一台出厂的汽车都符合最高标准。此外,这些技术还能够帮助项目经理更好地理解生产过程中的各种动态,从而做出更明智的决策,推动项目顺利进行。
四、技术实现
在处理项目的技术原理部分时,由于涉及到的自然语言处理(NLP)技术较为复杂,为了确保项目的顺利进行,我选择使用了一个现成的NLP平台。这个平台提供了一整套的NLP工具和服务,帮助我在不需要深入了解底层技术细节的情况下,快速实现数据的标注、模型训练和预测。 首先,我进行了数据收集,收集了与项目相关的数据样本,这些样本覆盖了各种可能的情况。接着,我对这些数据进行了清洗,确保数据质量。在数据清洗的基础上,我使用平台提供的在线标注工具对数据进行了标注,这个过程包括了实体、关系等的标记,确保了标注的一致性和质量。 在样本标注完成后,我根据标注的数据提取了文本特征,如词性标注、命名实体识别(NER)和依存句法分析等,并使用这些数据训练了模型。在模型训练过程中,我通过调整模型参数来优化性能,并进行了多次迭代。 为了确保模型的性能,我选择了合适的评估指标,如精确度、召回率和F1分数等,对模型进行了评估。通过交叉验证等方法,我确保了模型具有良好的泛化能力,并根据评估结果对模型进行了调整。 最后,我将训练好的模型部署到了生产环境中,以便对新的文本数据进行信息抽取。模型能够自动执行信息抽取任务,并输出结构化的结果。所有这些步骤都可以通过平台的Web界面完成,我无需编写任何代码。 此外,我还可以通过Python代码调用接口,实现训练和预测的结果。这为我在项目中提供了极大的便利,让我能够专注于项目管理和业务逻辑,而不是深入研究技术细节。通过这种方式,我有效地利用了NLP技术,提升了项目的效率和效果。
信息抽取代码实现
在构建汽车售后服务网络的过程中,我利用了平台的信息抽取功能来优化服务流程和提升客户满意度。以下是我使用该功能的伪代码示例:
# 设置请求参数headers = {'secret-id': '你的密钥','secret-key': '你的密钥'}data = {'text': '提供汽车维修、保养、配件更换等售后服务的相关文本内容。','sch': '汽车维修,保养,配件更换','modelID': '选择或创建的模型ID'}# 发送POST请求response = post('https://nlp.stonedt.com/api/extract', headers=headers, json=data)# 解析返回的JSON数据if response.status_code == 200:result = response.json()# 输出抽取结果print("抽取的保养信息:")for movie in result['result'][0]['实体']:print(f"名称:{movie['text']}, 起始位置:{movie['start']}, 结束位置:{movie['end']}, 准确率:{movie['probability']}")print("\n抽取的维修信息:")for director in result['result'][0]['关系']:print(f"名称:{director['text']}, 起始位置:{director['start']}, 结束位置:{director['end']}, 准确率:{director['probability']}")# ... 其他抽取结果的输出else:print("请求失败,状态码:", response.status_code)在这个伪代码中,我们通过设置请求头和请求参数,向平台的API发送了一个POST请求。请求的目的是抽取文本中关于汽车维修、保养、配件更换的相关信息。平台返回的JSON数据包含了抽取结果的详细信息,包括文本内容、起始和结束位置以及准确率。我们通过解析这些数据,可以将非结构化的文本信息转换为结构化的输出,进而用于优化我们的服务流程和响应策略。
通过这种方式,信息抽取技术帮助我们在处理大量客户反馈和维修记录时,快速定位到关键信息,提高了服务效率,并确保了客户问题能够得到及时和准确的解决。这不仅提升了客户满意度,也为品牌忠诚度的建立提供了坚实的基础。
数据库表设计
-- 创建维修记录表
CREATE TABLE MaintenanceRecords (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '维修记录唯一标识',vehicle_id INT NOT NULL COMMENT '车辆唯一标识',customer_id INT NOT NULL COMMENT '客户唯一标识',service_center_id INT NOT NULL COMMENT '服务中心唯一标识',maintenance_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '维修日期',mileage INT COMMENT '维修时里程数',issue_description TEXT COMMENT '问题描述',maintenance_type ENUM('Repair', 'Checkup', 'PartsReplacement') COMMENT '维修类型',status ENUM('Pending', 'InProgress', 'Completed', 'Cancelled') COMMENT '维修状态',estimated_cost DECIMAL(10, 2) COMMENT '预计成本',actual_cost DECIMAL(10, 2) COMMENT '实际成本',technician_id INT COMMENT '维修技师唯一标识',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间') COMMENT '维修记录表';-- 创建客户表
CREATE TABLE Customers (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '客户唯一标识',name VARCHAR(255) NOT NULL COMMENT '客户姓名',email VARCHAR(255) COMMENT '客户邮箱',phone_number VARCHAR(20) COMMENT '客户电话号码',address TEXT COMMENT '客户地址',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间') COMMENT '客户表';-- 创建服务中心表
CREATE TABLE ServiceCenters (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '服务中心唯一标识',name VARCHAR(255) NOT NULL COMMENT '服务中心名称',address TEXT COMMENT '服务中心地址',phone_number VARCHAR(20) COMMENT '服务中心电话号码',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间') COMMENT '服务中心表';-- 创建维修技师表
CREATE TABLE Technicians (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '维修技师唯一标识',name VARCHAR(255) NOT NULL COMMENT '技师姓名',phone_number VARCHAR(20) COMMENT '技师电话号码',service_center_id INT COMMENT '所属服务中心唯一标识',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间',FOREIGN KEY (service_center_id) REFERENCES ServiceCenters(id) ON DELETE SET NULL ON UPDATE CASCADE COMMENT '技师所属服务中心外键') COMMENT '维修技师表';五、项目总结
在本项目中,我们成功构建了一个高效的汽车售后服务网络,通过信息抽取技术的应用,我们实现了以下具体效益和效果:
- 显著提升了客户反馈处理的效率。通过自动化的文本分析,我们能够在短时间内从大量非结构化数据中提取关键信息,从而快速响应客户需求,减少了客户等待时间。例如,质量问题的及时发现和处理,避免了潜在的大规模召回,节约了成本并维护了品牌形象。
- 优化了服务流程,提高了服务质量。信息抽取技术帮助我们理解客户与服务流程的相互作用,我们据此调整了预约系统,平衡了服务中心的预约分布,显著提升了客户满意度。此外,通过对维修过程中关键时间点的分析,我们发现了服务流程中的瓶颈,并采取了相应措施进行优化。
- 强化了客户关系管理。通过分析客户反馈和维修记录,我们能够更好地理解客户需求,为他们提供个性化的服务,增强了客户的忠诚度。同时,这些数据为市场分析提供了宝贵信息,帮助我们更好地定位市场策略,提升品牌竞争力。
- 提升了生产效率和质量控制。在生产过程中,信息抽取技术的应用使我们能够自动分析生产数据,及时发现潜在的质量问题,优化生产流程,减少浪费。这不仅确保了出厂汽车的质量,也为项目经理提供了实时的生产监控,使得项目决策更为高效。
- 技术实现的便捷性。我们采用了现成的NLP平台,使得整个信息抽取过程无需深入了解底层技术细节,就可以快速实现。这大大减轻了技术团队的负担,使得团队能够专注于项目管理和业务逻辑,加速了项目的推进。
- 综上所述,信息抽取技术在本项目中的应用不仅提高了工作效率,优化了服务和生产流程,还加强了客户关系管理,为公司的长期发展奠定了坚实基础。
六、开源项目(本地部署,永久免费)
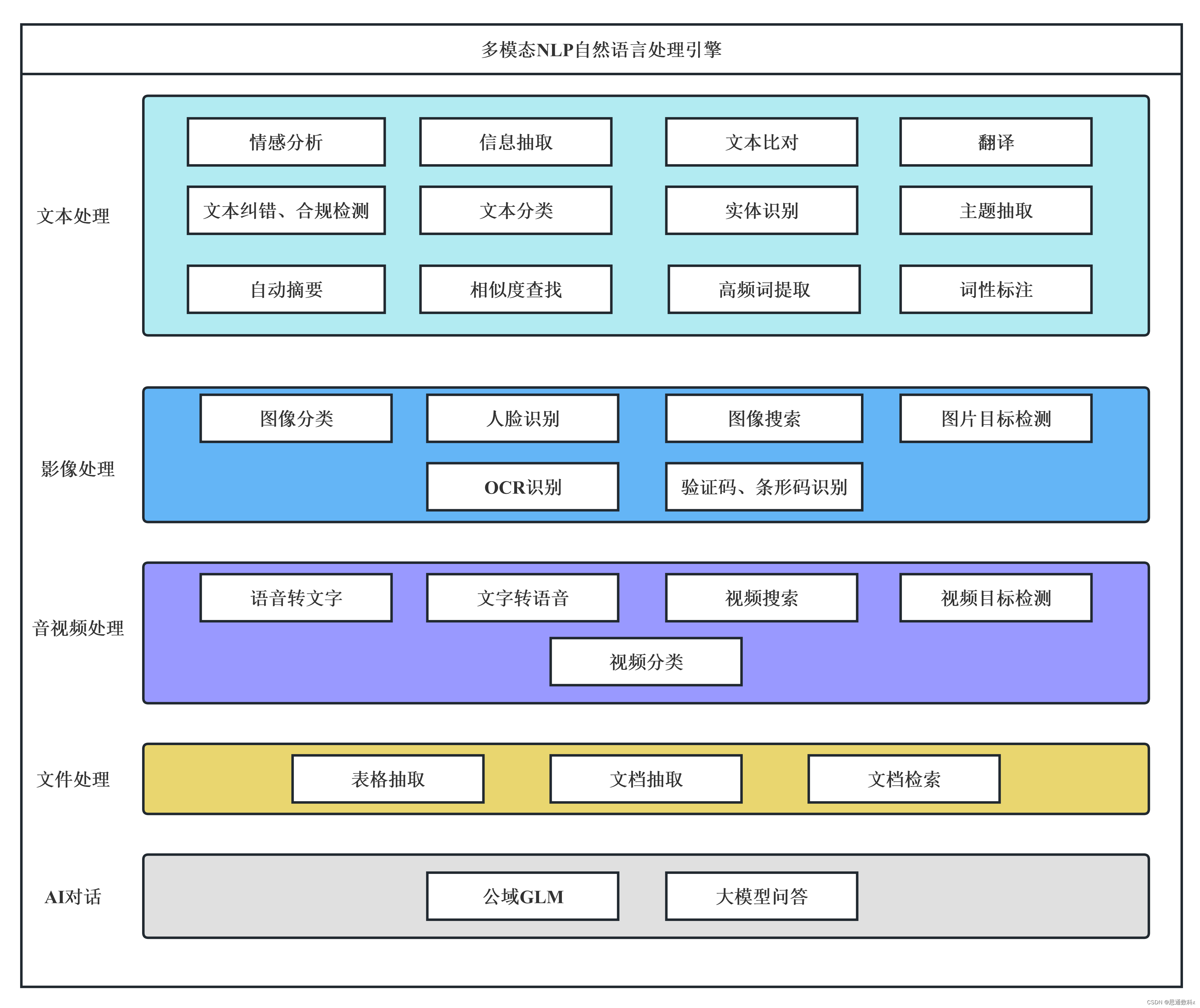
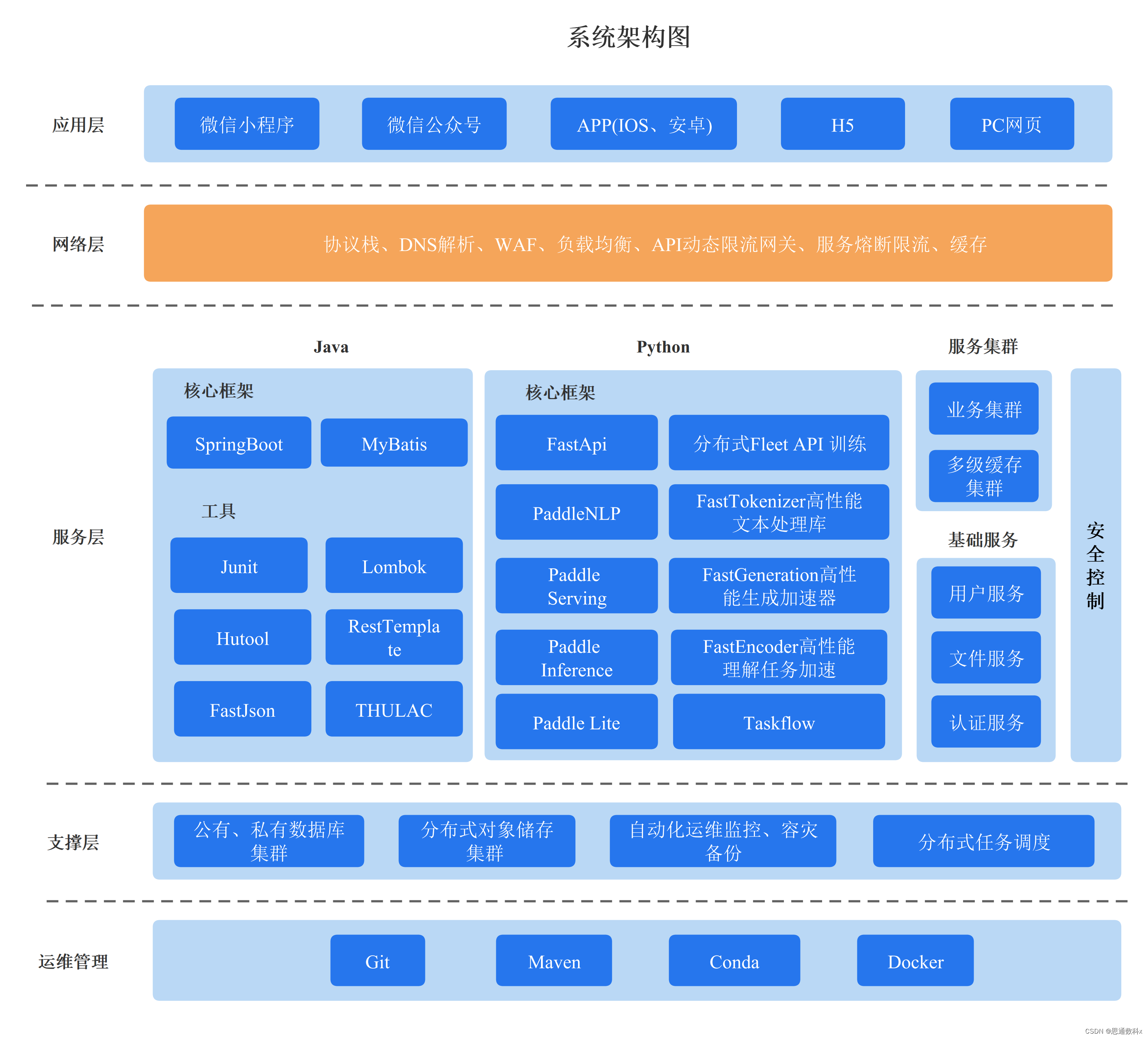
思通数科的多模态AI能力引擎平台是一个企业级解决方案,它结合了自然语言处理、图像识别和语音识别技术,帮助客户自动化处理和分析文本、音视频和图像数据。该平台支持本地化部署,提供自动结构化数据、文档比对、内容审核等功能,旨在提高效率、降低成本,并支持企业构建详细的内容画像。用户可以通过在线接口体验产品,或通过提供的教程视频和文档进行本地部署。
思通数科多模态AI能力引擎平台![]() https://nlp.stonedt.com多模态AI能力引擎平台: 免费的自然语言处理、情感分析、实体识别、图像识别与分类、OCR识别、语音识别接口,功能强大,欢迎体验。
https://nlp.stonedt.com多模态AI能力引擎平台: 免费的自然语言处理、情感分析、实体识别、图像识别与分类、OCR识别、语音识别接口,功能强大,欢迎体验。![]() https://gitee.com/stonedtx/free-nlp-api
https://gitee.com/stonedtx/free-nlp-api



)
(九))
)

)


和 Temporal Join)

状态模式)






