(本内容部分来自知乎网等网络)
Redis 缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解。如果对数据 的一致性要求很高,那么就不能使用缓存。
另外的一些典型问题就是,缓存穿透、缓存雪崩和缓存击穿。目前,业界也都有比较流行的解决方案。
1. 缓存穿透(数据不存在)
缓存穿透是指查询请求中的数据在缓存系统和后端数据库中都不存在的情况。
正常情况下,如果数据不在缓存中,会去数据库查询并把结果放入缓存以备后续使用。但如果恶意或者大量请求都是针对不存在的数据,那么这些请求将会绕过缓存直接打到数据库,导致数据库承受不必要的压力。
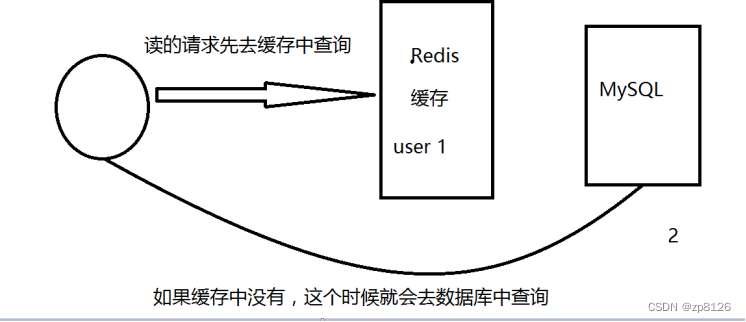
解决方案
- 布隆过滤器(Bloom Filter):可以在查询缓存之前先通过布隆过滤器判断该 key 是否可能存在,如果布隆过滤器认为不存在,则直接返回空,避免对数据库进行查询。
- 空值缓存:即使从数据库查不到数据,也把一个特殊值(比如
NULL或FLAG)作为结果缓存起来,设置较短的过期时间,这样短期内连续针对同样不存在的数据的请求也能被缓存拦截。
布隆过滤器
布隆过滤器: 是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则 丢弃,从而避免了对底层存储系统的查询压力;
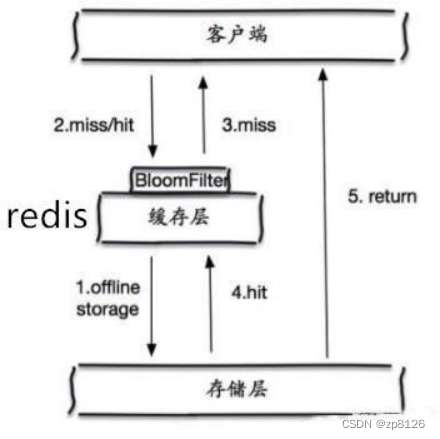
什么是布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
什么是布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
实现原理
HashMap 的问题
讲述布隆过滤器的原理之前,我们先思考一下,通常你判断某个元素是否存在用的是什么?应该蛮多人回答 HashMap 吧,确实可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高。但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多例如上亿的时候,那 HashMap 占据的内存大小就变得很可观了。
还比如说你的数据集存储在远程服务器上,本地服务接受输入,而数据集非常大不可能一次性读进内存构建 HashMap 的时候,也会存在问题。
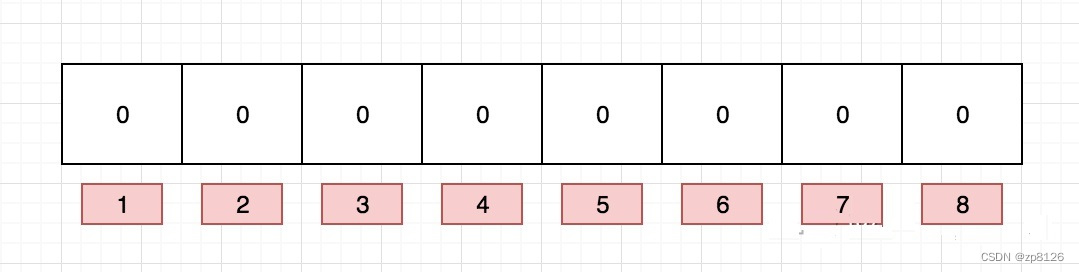
布隆过滤器数据结构
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
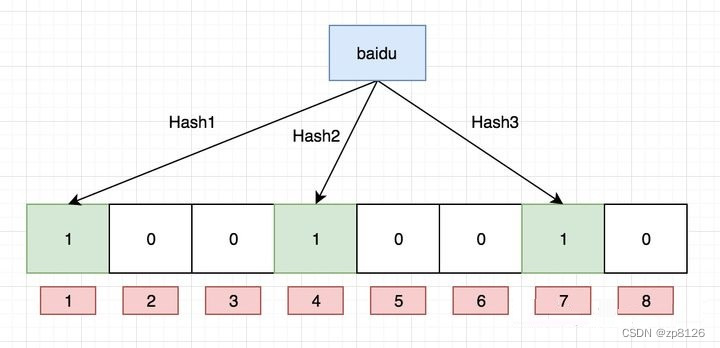
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
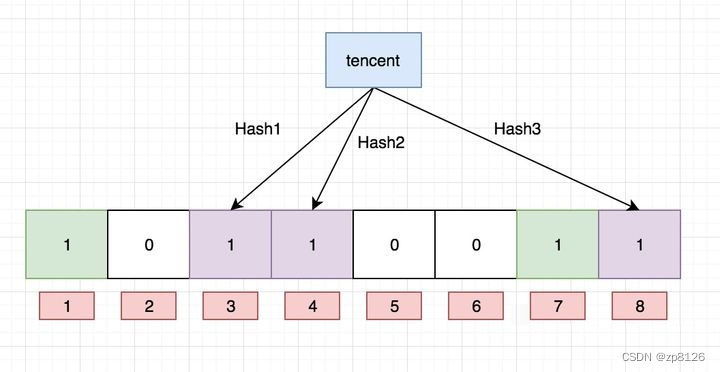
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
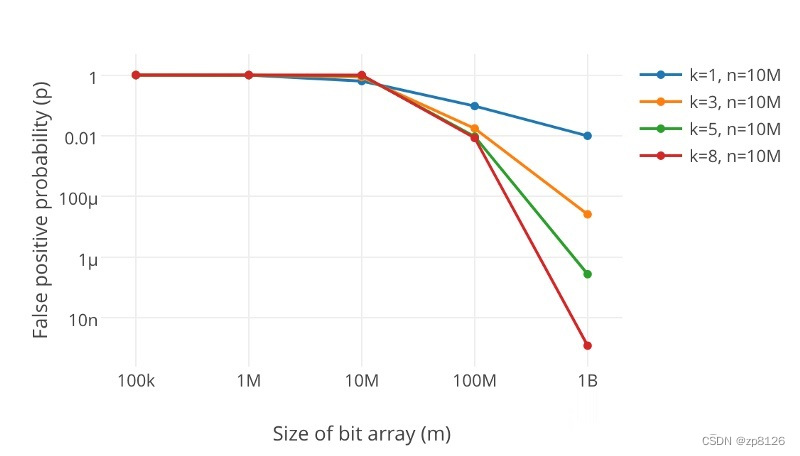
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数 据将会从缓存中获取,保护了后端数据源;
但是这种方法会存在两个问题:
1、如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
2、即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
2. 缓存击穿(缓存过期)
定义: 缓存击穿通常指的是某个热点数据过期失效后,短时间内有大量的并发请求同时来访问这个刚刚过期的数据,从而所有请求都会穿透缓存直接到达数据库,造成数据库瞬间压力过大。
解决方法:
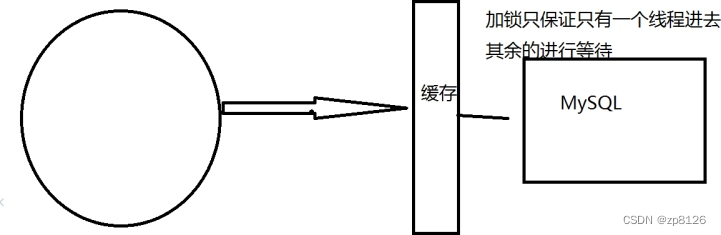
- 互斥锁(Mutex Lock):对于热点数据,在缓存失效时采用加锁策略,使得只有一个线程能持有锁去数据库加载数据,其他线程等待锁释放后获取更新后的缓存数据。
- 永不过期:在业务允许的情况下,可以考虑让热点数据永不超时,而是通过定时任务或后台异步刷新的方式更新缓存。
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中 对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导使数据库瞬间压力过大。
设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题。
加互斥锁
分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
3. 缓存雪崩
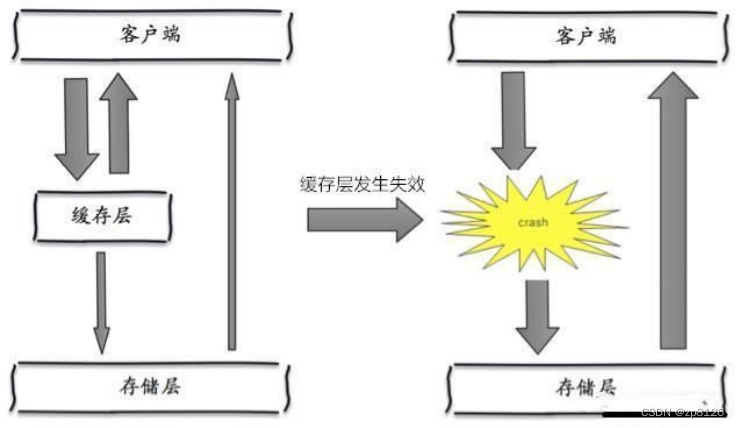
定义: 缓存雪崩是指缓存集群在某一时刻大面积地发生缓存失效,例如由于网络抖动、缓存服务器宕机、或者大量缓存同时达到预设过期时间等导致。此时,原本由缓存承载的大量请求全部涌入数据库,可能会压垮数据库。
缓存雪崩,是指在某一个时间段,缓存集中过期失效。Redis 宕机!
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
解决方法:
- 分散失效时间:为缓存设置随机的过期时间,防止大量缓存在同一时刻失效。
- 多级缓存:使用主从、集群等方式部署缓存,增强缓存系统的可用性。
- 熔断降级与限流:当数据库压力过大时,可以通过熔断机制暂时停止向数据库发送请求,并启动降级策略;同时也可以使用限流措施控制请求流量,保护数据库不受冲击。
- 提前预热:在缓存失效前提前刷新缓存,尤其对于那些即将过期的热点数据。
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
综上所述,要应对这三种情况,需要结合具体的业务场景,合理设计缓存策略,以及利用额外的技术手段来保证系统的稳定性和高可用性。
 E. XOR Tree(启发式合并+贪心))




)

)


——数组(1))






V2 用户关注)

