一、根页面万年不动
在之前的文章里,为了方便理解,都是先画存储用户记录的叶子节点,然后再画出存储目录项记录的内节点。
但实际上 B+ 树的行成过程是这样的:
-
每当为某个表创建一个 B+ 树索引,都会为这个索引创建一个根节点页面。最开始表里没数据,所以根节点中既没有用户记录,也没有目录项记录。
-
当往表里插入用户记录时,先把用户记录存储到这个根节点上。
-
当根节点页空间用完,继续插入记录,此时会将根节点中所有记录复制到一个新页(比如页 a),然后对这个新页进行页分裂,得到另一个新页(页 b)。这时候新插入的记录就根据键值大小分配到页 a 和 页 b 中。于是,根节点页就升级成了存储目录项记录的页,就需要把页a 和 页b 对应的目录项记录插入到根节点中。
另外,当一个B+树索引的根节点创建后,它的页号就不会再变。
所以只要我们对某个表建立一个索引,那么它的根节点的页号就会被记录到某个地方,后续只要 innodb引擎需要用这个索引,就会从那个固定的地方取出根节点的页号,从而访问这个索引。
二、内节点中目录项记录的唯一性
在B+树索引的内节点中,目录项记录的内容是索引列+页号。但是对于二级索引来说,不太严谨。
因为二级索引的索引列可能存在相同的值,比如某张表里有这4条记录,其中c1列是主键 :

现在为c2列建立索引:

如果这时候继续插入一条记录,3个列分别为9、1、'c',就会遇到问题:
- 新记录中 c2的值也是1,那么这个新记录到底应该放在页 4,还是放到页 5?
所以,为了能让新插入的记录可以找到自己应该到哪个页中,就需要保证B+树同一层内节点的目录项记录是唯一的。
那么,实际上二级索引的内节点的目录项记录应该由 3 个部分组成:
- 索引列的值
- 主键值
- 页号
所以实际上给c2建立的索引应该是这样:
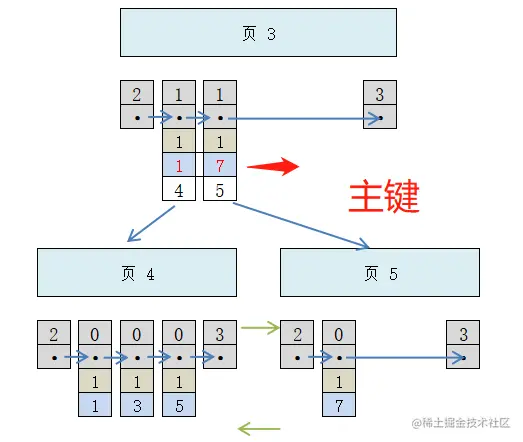
现在,当插入新记录9、1、'c'时:
- 可以先把新记录的 c2 列的值和页 3 中各目录项记录的 c2 列的值进行比较。
- 如果 c2 列的值相同,就接着比较主键值。
所以,对于二级索引来说,给 c2 列建索引,其实就相当于用c2、c1建立了一个联合索引。先按照二级索引的值进行排序,在二级索引列值相同的情况下,再按照主键值进行排序。
三、一个页面至少容纳 2 条记录
在之前的文章里提到过,B+ 树其实只需要很少的层级就可以轻松存储数亿条记录,查询速度还很快。
这是因为 B+ 树本质上就是一个大的多层级目录。每经过一个目录时都会过滤许多无效的子目录,直到最后访问到存储真正数据的目录。
那么现在不妨设想一下:还是同样的数据量,如果一个大的目录只存放一个子目录,又是什么样子?
- 目录层级非常多
- 最后那个存放真正数据的目录中只能存放一条记录
如果是这样的话,这种B+ 树结构就没什么意义了,不能形成一个有效的索引。于是,设计 innoDB的大佬为了避免 B+树的层级增长得过高,要求所有数据页都至少可以存放2条记录。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!

及其常见组件)





)












