PDF解析是极其复杂的问题。不可能靠一个工具解决全部问题,尤其是五花八门,格式不统一的PDF文件。除非有钞能力。如果没有那就看看可以分为哪些问题。
提取文本内容,提取表格内容,提取图片。我认为这些应该是分开做的事情。python有一些组件,是有专长的。
问题分解以后,最重要的一个事情是,版面分析。怎么确定边界,就是哪一块是什么内容?是正文,还是表格,还是图片?
文本、图片及形状涵盖了常见的PDF元素,本文介绍利用
PyMuPDF提取这些页面元素,及其基本数据结构。本文会提供可运行的代码!
一、技术选型 PyMuPDF
PyMuPDF的Textpage对象提供的extractDICT()和extractRAWDICT()用以获取页面中的所有文本和图片(内容、位置、属性),基本数据结构如下:

看到这里,有分类,有位置信息。
二、代码演示
2.1 安装
pip install PyMuPDF2.2 demo代码
import fitz # PyMuPDFdef extract_text_blocks(pdf_path):# 打开 PDF 文件pdf_document = fitz.open(pdf_path)# 存储文本块和行块信息text_blocks = []line_blocks = []# 遍历 PDF 中的每一页for page_number in range(len(pdf_document)):page = pdf_document.load_page(page_number)# 获取文本块和行块信息blocks = page.get_text("dict")["blocks"]for b in blocks:for l in b["lines"]:line_blocks.append({"line": l["spans"],"bbox": l["bbox"],"height": l["bbox"][3] - l["bbox"][1] # 计算行块的高度})text_blocks.append({"block": b["lines"],"bbox": b["bbox"]})# 关闭 PDF 文件pdf_document.close()return text_blocks, line_blocks# 示例用法
pdf_path = "D:\\angus\\py\\困难pdf节选西藏奇正2022.pdf"
text_blocks, line_blocks = extract_text_blocks(pdf_path)# 打印提取的文本块信息
for index, block in enumerate(text_blocks):print(f"Text Block {index + 1}:")for line_index, line in enumerate(block["block"]):print(f" Line {line_index + 1}: '{line['spans']}' at position {block['bbox']}")# 打印提取的行块信息
for index, line in enumerate(line_blocks):print(f"Line {index + 1}: '{line['line']}' at position {line['bbox']}, height={line['height']}")
三、效果展示
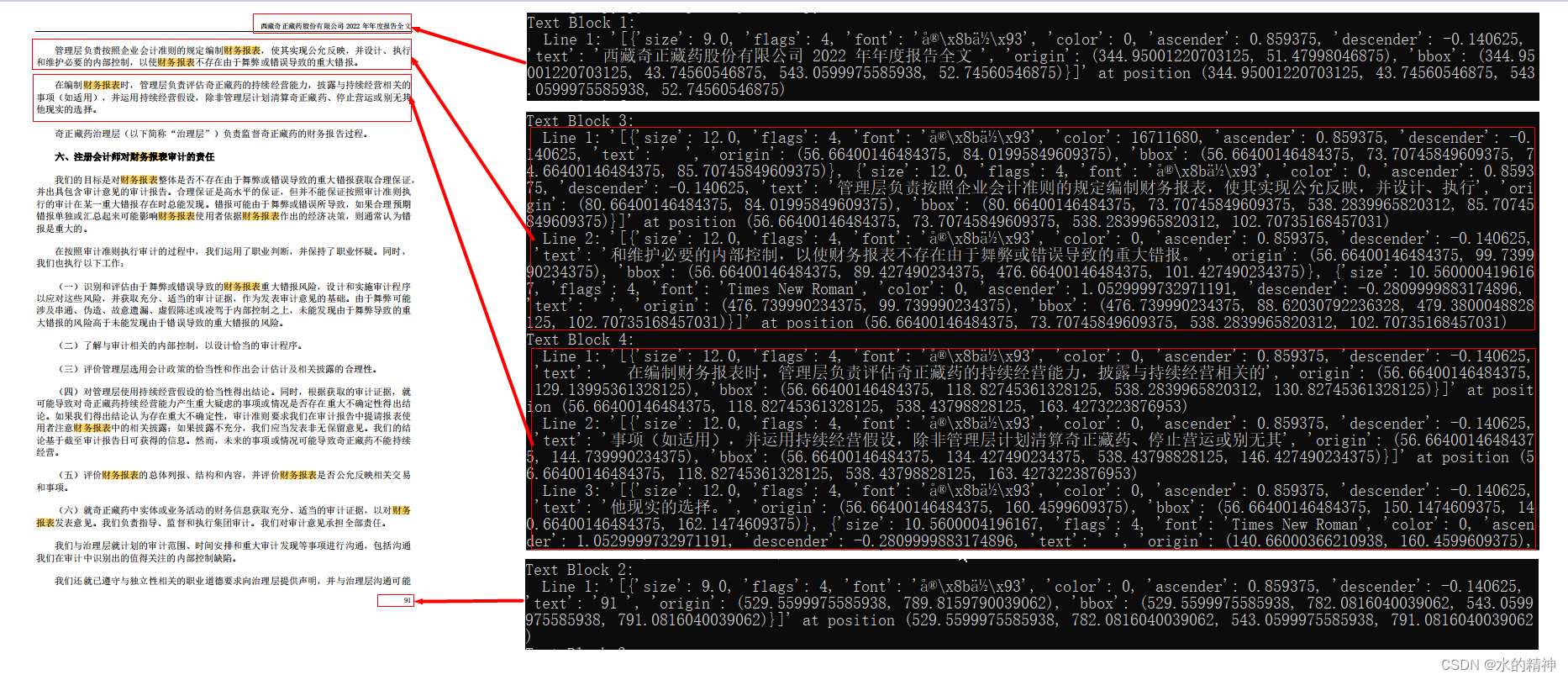
3.1 原文PDF内容

3.2 解析后得到的结果

3.3 分析原文和结果
对比输出的结果和原文。我们可以发现,我们拿到了行的数据,也拿到了段落的数据。上述的代码中已经给我们分好了块!这样解可以区分段落了。
3.4 获取更多信息,包括位置

来看一个文本块:
size: 文本的大小。flags: 文本的标志。font: 字体名称。color: 字体颜色。ascender: 文本的上升高度。descender: 文本的下降高度。text: 文本内容。origin: 文本的起始位置坐标。bbox: 文本的边界框坐标,即左下角和右上角的坐标。
通过这些信息,我们可以获取到每个文本块的具体内容、大小、位置和格式等信息。这些信息对于分析和处理 PDF 文件中的文本内容非常有用。例如,你可以根据文本的大小、位置和格式来识别标题、正文和其他内容,并进行相应的处理和分析。当然,就以这个文档为例,我们可以看到的是,因为文档本身字体大小都一样,所以很难根据字体和大小获取到标题。
四、错误问题
但是也发现了问题
4.1 段落有被分开了
原文

错误的问题如下

4.2 将表格错当成了文本内容
原文表格内容如下

解析得到的内容如下
表格的一行为一个块内容,

这里调试了一版,可以去掉表格。
逻辑是:判断相邻的block,表格的特征是,当个block内的 lines的 bbox的第四位是相同的。且相邻的block的lines一定是相同的,且lines不为空。逻辑本身没有问题,就怕PDF有问题,识别出来的表格的同一行的bbox中的第四位不一样,这样会错误判断!
import fitz # PyMuPDFdef is_table_block(b1, b2):# 检查连续相邻的文本块是否具有相同的行数,并且其 bbox 的高度也相同if len(b1["lines"]) == len(b2["lines"]) and b1["bbox"][3] - b1["bbox"][1] == b2["bbox"][3] - b2["bbox"][1]:return Truereturn Falsedef extract_text_blocks(pdf_path):# 打开 PDF 文件pdf_document = fitz.open(pdf_path)# 存储文本块信息text_blocks = []line_blocks = []# 遍历 PDF 中的每一页for page_number in range(len(pdf_document)):page = pdf_document.load_page(page_number)# 获取文本块和行块信息blocks = page.get_text("dict")["blocks"]for i in range(len(blocks)):if i < len(blocks) - 1 and is_table_block(blocks[i], blocks[i+1]): # 如果是表格,则跳过continuefor l in blocks[i]["lines"]:line_blocks.append({"line": l["spans"],"bbox": l["bbox"],"height": l["bbox"][3] - l["bbox"][1] # 计算行块的高度})text_blocks.append({"block": blocks[i]["lines"],"bbox": blocks[i]["bbox"]})# 关闭 PDF 文件pdf_document.close()return text_blocks, line_blocks# 示例用法
pdf_path = "D:\\angus\\py\\困难pdf节选西藏奇正2022.pdf"
text_blocks, line_blocks = extract_text_blocks(pdf_path)# 打印提取的文本块信息
# 用于检查两个文本块中的行是否相同
def check_lines_same(block1, block2):num_lines_block1 = len(block1["block"])num_lines_block2 = len(block2["block"])return num_lines_block1 == num_lines_block2for index, block in enumerate(text_blocks):# 获取当前文本块中行的个数num_lines = len(block["block"])# 如果当前文本块是表格,则继续检查下一个文本块是否是表格if num_lines > 1 and index < len(text_blocks) - 1: # 需要多于一行,并且不是最后一个文本块next_block = text_blocks[index + 1]if check_lines_same(block, next_block):# 如果下一个文本块也是表格,则跳过,不进行打印输出continue# 如果当前文本块不是表格,则打印输出print(f"Text Block {index + 1}:")for line_index, line in enumerate(block["block"]):print(f" Line {line_index + 1}: '{line['spans']}' at position {block['bbox']}")# 打印提取的行块信息
# for index, line in enumerate(line_blocks):
# print(f"Line {index + 1}: '{line['line']}' at position {line['bbox']}, height={line['height']}")
4.3 解析丢失整行数据
测试了另外一个法律法规文件。
发现文件丢失了。原文件内容如下:

解析后的:
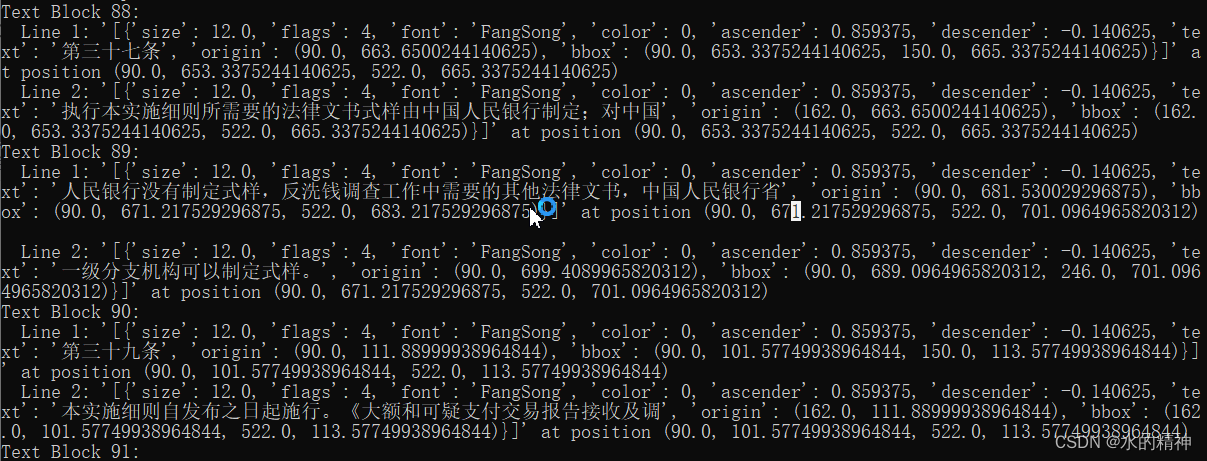
还没找到bug的原因。


)



: Flutter的版本管理终极指南)











)
