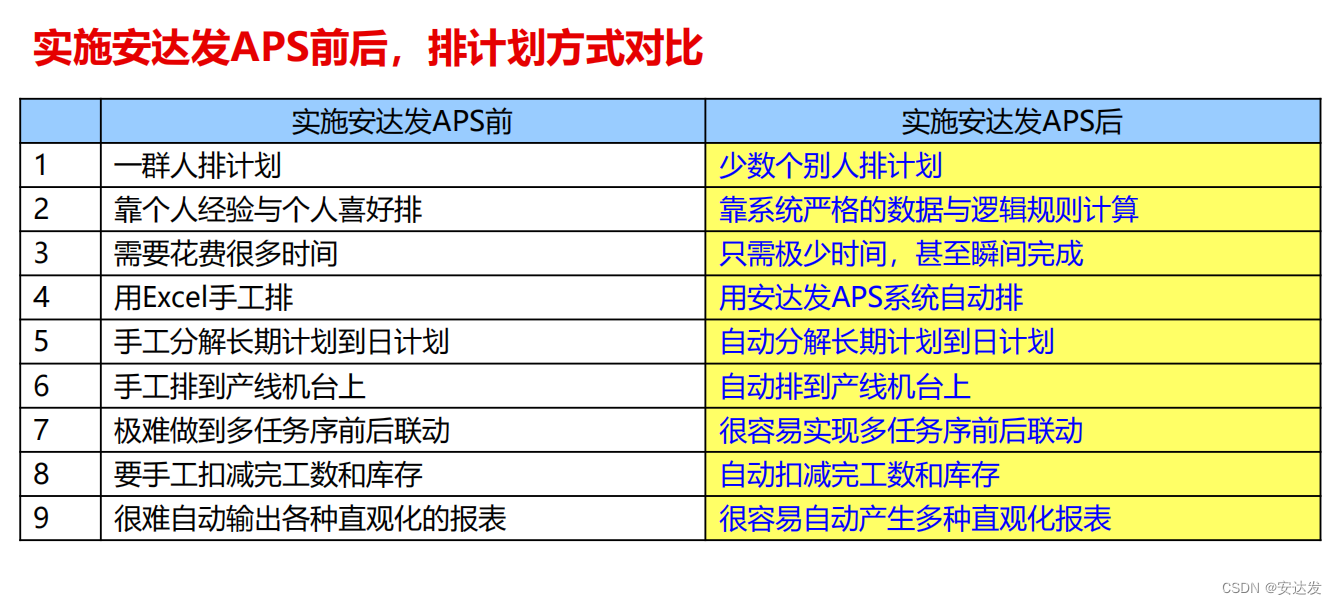
长期以来,医院信息化运维中存在着科室复杂、应用场景多、终端运维工作量大、软件系统兼容需求强等诸多痛点,且对技术设备的稳定性、连续性要求极高,在日常运维中,需要应对和解决这些问题来保障业务稳定、健康运行。
1、数据孤岛
在信息化建设中,医院基本完成核心业务系统的建设,且配置一定规模的网络、服务器、动环等系统。因此也会出现各厂商独立监控、数据割裂,形成运维孤岛。
2、问题发现被动、滞后
传统人工巡检的方式,存在问题发现被动、滞后,难以保障业务的稳定运行。且人工摸排时间长、效率低,运维工作效果不显著。
3、告警不准确
部分医院有动环、基础设施监控等管理系统, 医院业务系统复杂,易产生告警冗余,难以在告警风暴中判断故障根因。
4、对资源和性能数据掌握不足
对服务器CPU、内存等计算资源,磁盘空间、磁盘I/O等存储资源的缺乏监控管理,对系统应用节点和数据的各项性能参数配置等数据把控不足,不能提前发现隐患问题。
近5年,LinkSLA智能运维管家在医疗领域服务满意度95%以上,通过建立主动监控和御防,MOC在线值守的线上+线下的大运维服务,帮助医院实现高效、稳定的业务环境。下面通过一组小案例看LinkSLA智能运维管家在医院运维实践中的价值。
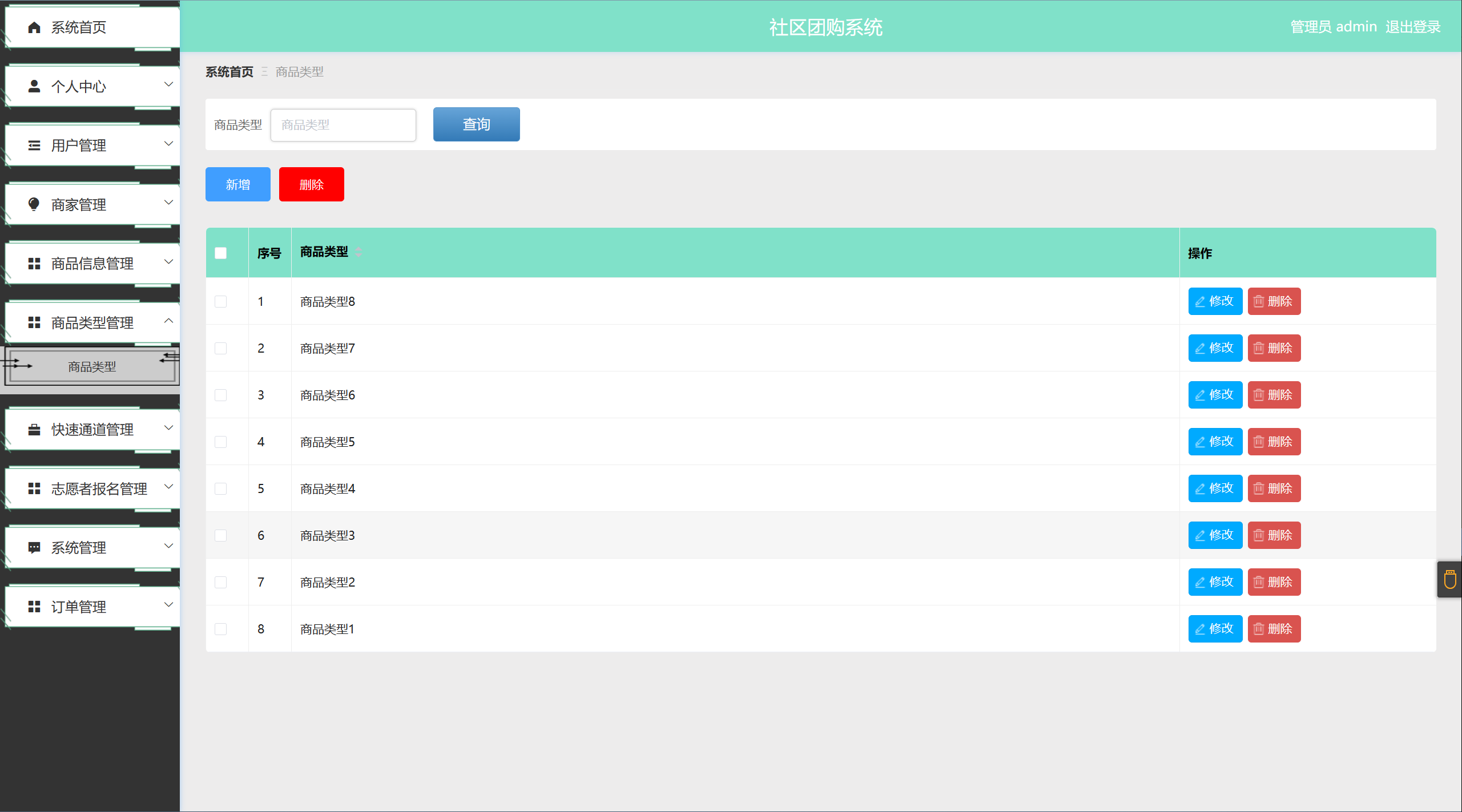
一、告警问题
11月14日9点,平台接到安徽某三甲医院HuaweiOceanStor9000设备告警,告警提示3点异常:
-
文件系统服务状态异常;
-
Node-01存储节点异常;
-
协议共享服务异常;
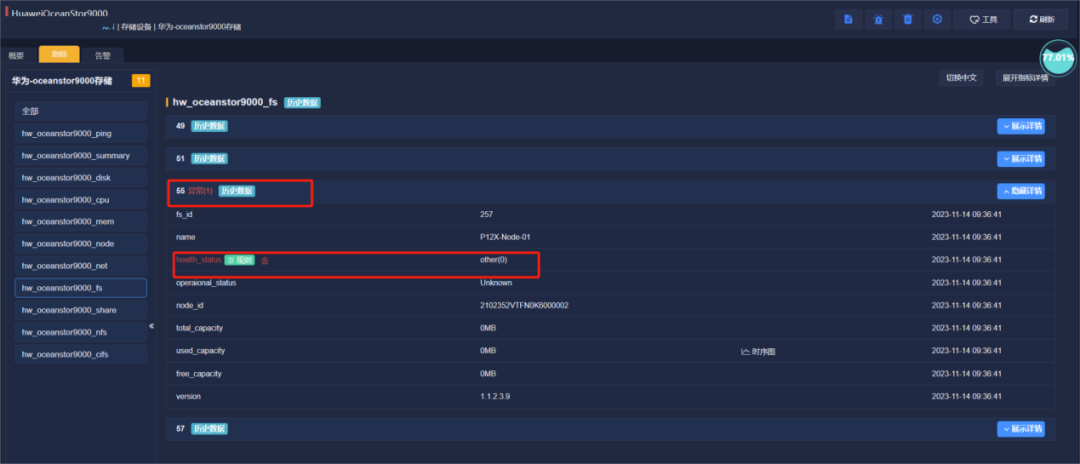
(告警列表)
奇怪的是,告警仅持续5分钟,随后文件系统、存储节点和协议共享服务状态又全部恢复正常。期间无任何技术性调整,告警自动解除,是产生误报吗?设备问题需要再确认一下吗?答案是肯定的,对平台告警准确率深信不疑的moc工程师不错过任何隐患问题,坚持再次检查设备的健康状况。
二、问题的排查过程
moc工程师沟通现场工程师,建议查看设备运行状态,并查看运行日志,检查是否有硬件故障发生。
次日,厂家检查设备发现Node1没有备用节点,手动添加节点Node2,这一操作导致存储节点Node4健康状态和磁盘状态异常,平台收到告警建议进行整改,存储节点Node4恢复正常,厂家将检测日志带回做进一步分析。

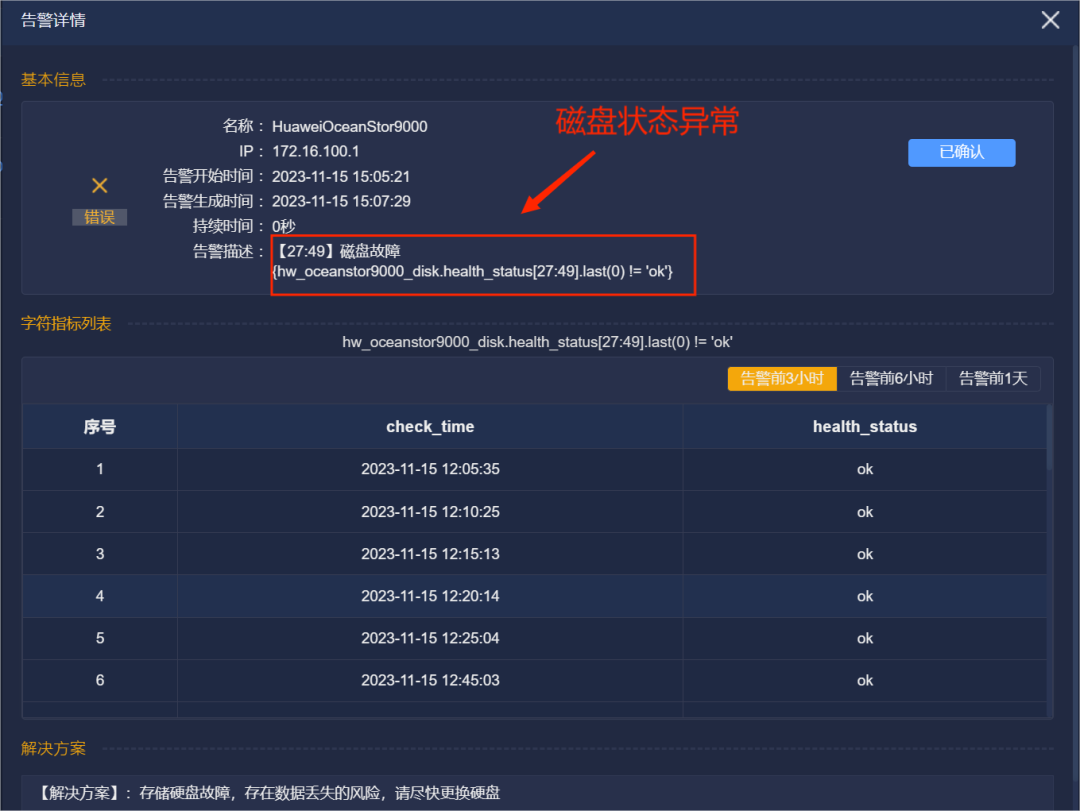
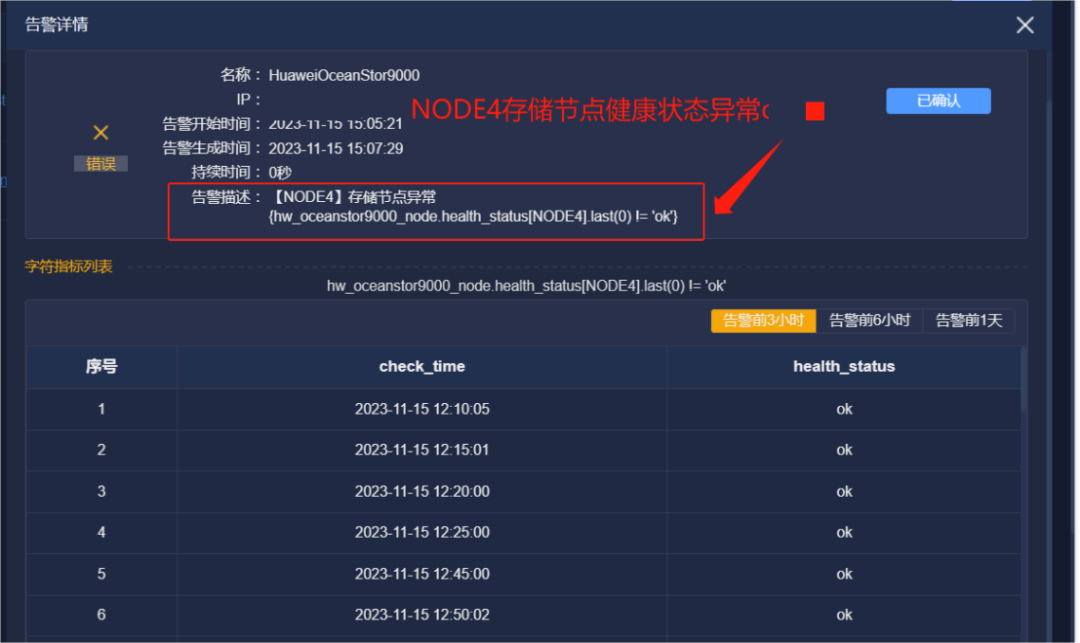
3、厂家持续远程观察该设备运行状况,并将日志回传进一步分析。
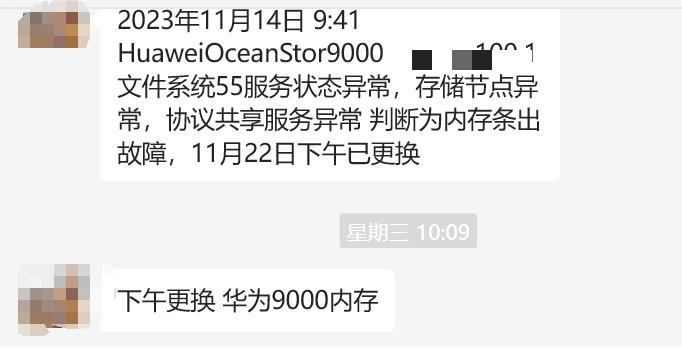
4、在持续观察以及日志分析后,判断内存条问题导致14日Node1节点和文件系统告警。更换掉内存条后,问题得以解决。
三、案例小结
这个案例的细节惊喜在于告警闪现5分钟后快速恢复,如果没有MOC值守工程师的关注,很容易忽视这个异常告警,MOC工程师快速响应沟通现场,联系厂家进行设备检查,跟进故障修复进度,隐患问题最终得到解决。
LinkSLA智能运维平台抓住瞬间闪现的故障,将问题扼杀在萌芽中。充分体现平台对故障的敏锐度,没有空穴来风的报警,只有尚未明确的问题。