目录
前言
一、StarRocks在贝壳的应用现状
1.1 历史的数据分析架构
1.2 OLAP选型
1.2.1 离线场景
1.2.2 实时场景
1.2.3 StarRocks 的引入
二、StarRocks 在贝壳的分析实践
2.1 指标分析
2.2 实时业务
2.3 可视化分析
三、未来规划
3.1 StarRocks集群的稳定性
3.2 StarRocks 新特性采用
原文大佬的这篇贝壳找房数仓实践的文章整体写的很深入,这里摘抄下来用作学习和知识沉淀。
前言
贝壳找房是国内最大的在线房产交易平台之一,利用大数据技术进行房源的挖掘和匹配,通过数据分析和挖掘,更准确地了解用户需求,并为用户提供个性化的房源推荐和交易服务。
随着数据和业务规模的增长,传统数仓的分析能力面临很大的挑战,贝壳需要引入新兴的数据湖技术来支撑业务的发展。在指标分析场景、实时业务场景采用StarRocks替换原有的Kylin、Clickhouse 等组件,业务性能上有 5-6 倍性能提升;同时,贝壳也开始推动 StarRocks 替换 Presto 的场景,进一步简化架构,实现分析层的统一,与 StarRocks 社区共建极速统一的湖仓新范式。
一、StarRocks在贝壳的应用现状
1.1 历史的数据分析架构
早期为了支持多样化的分析能力,引入了多种OLAP引擎以支持不同的场景,其中包括:
-
Kylin、Druid:用于高QPS的指标查询、报表系统等(高并发)
-
Presto、Impala:基于Hive数据分析
-
ClickHouse :用于支撑用户分析、风控等实时业务
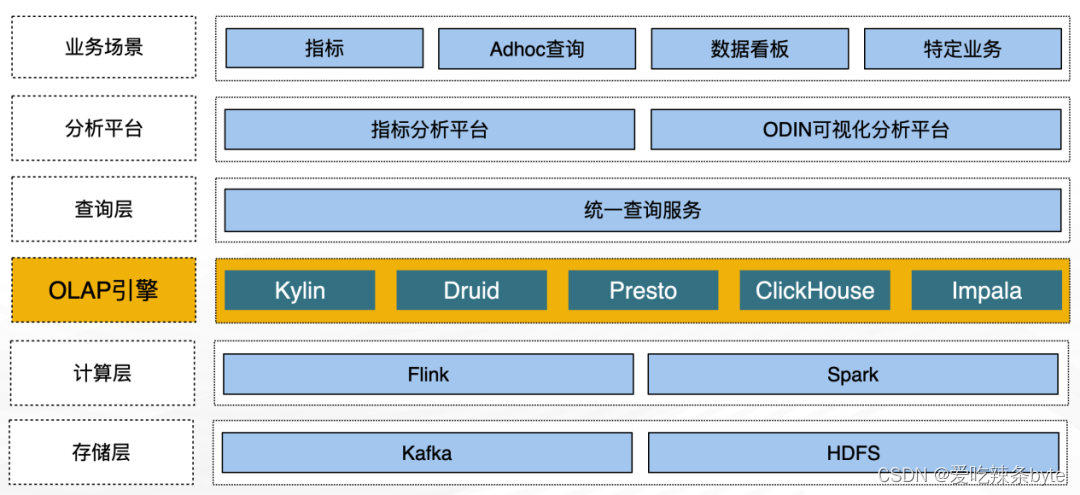
随着使用规模的扩大,维护成本越来越高,在扩展引擎数量的同时,必须要考虑上下游配套产品的兼容性改造,由于每个引擎的特殊性,适配的开发成本也很高,随着引擎数量的增加和特性迭代,这方面的工作量越来越大。尽管数据开发平台已经在很大程度上屏蔽了引擎的使用细节,但随着业务的深入使用,某些场景可能需要使用引擎的高级特性支持。一些业务逻辑需要沉淀到引擎底层,增加了业务模型的开发维护成本。
1.2 OLAP选型
1.2.1 离线场景
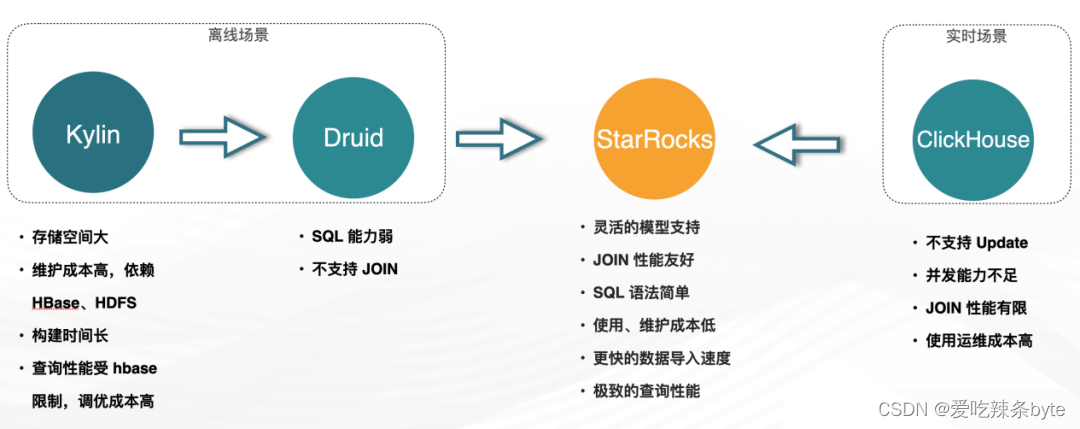
最初使用kylin进行指标分析,Kylin是一种空间换时间的方案,并且依赖于HDFS 和HBase。此外,Kylin在维度计算方面需要较长的构建时间,查询性能受到HBase的限制,调优成本较高。
Druid的引入虽然解决了以上问题,Druid 的引入虽然解决了以上问题,但Druid本身也存在一些局限性,比如 SQL 能力较弱,不支持JOIN操作。对于数据分析产品来说,如果只能使用宽表,但宽表模型的问题较为显著,即一旦维度有所变化,其回溯的成本是很高的。
1.2.2 实时场景
ClickHouse 主要是支撑实时分析场景,但在运维成本、更新操作,高并发和Join等场景有诸多限制。
从总体来看面临以下比较严重问题:
- 复杂、灵活的业务模型要求
- 高性能的查询和高稳定性
- 多引擎的高运维成本
1.2.3 StarRocks 的引入
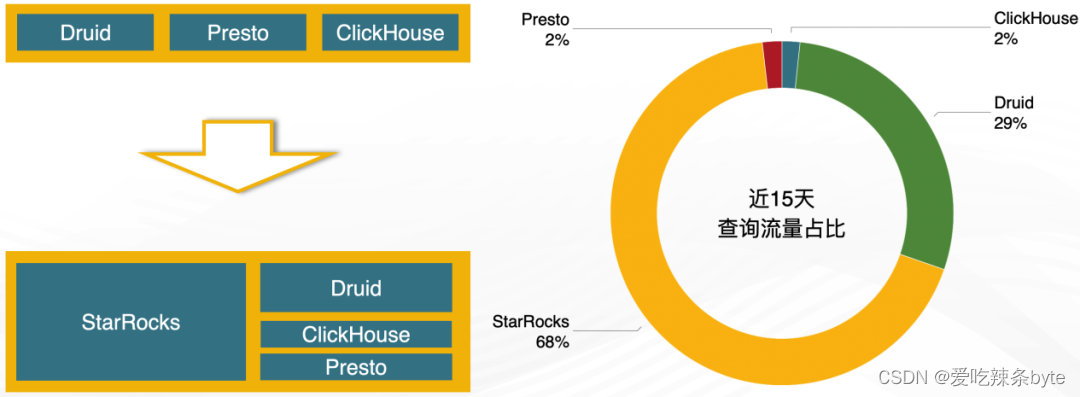
带着这些问题开始调研市场上新兴的 OLAP 技术,发现 StarRocks 能够完全解决以上痛点。2021 年 StarRocks 在贝壳落地,截止 2022 年底,StarRocks 在占据了近 70% 的流量份额。生产环境共有 10 集群在使用,大规模集群 BE节点 40个,小规模集群 BE 节点数 5~10个。
规模:
- 存储总量80TB
- 日均写入的数据量12TB,其中离线7TB,实时5TB
- 日均的查询量是1400万次
二、StarRocks 在贝壳的分析实践
引入StarRocks最要的目标是解决多引擎的问题,接下来通过 3 个场景来介绍各引擎如何统一到 StarRocks 上。
2.1 指标分析
离线分析场景:Druid To StarRocks
指标开发分为3个阶段:
- 数据准备:数据开发人员准备 Hive 表和 StarRocks 表
- 指标开发:基于元数据进行模型和指标开发
- 模型构建:将模型转换到具体引擎的实现
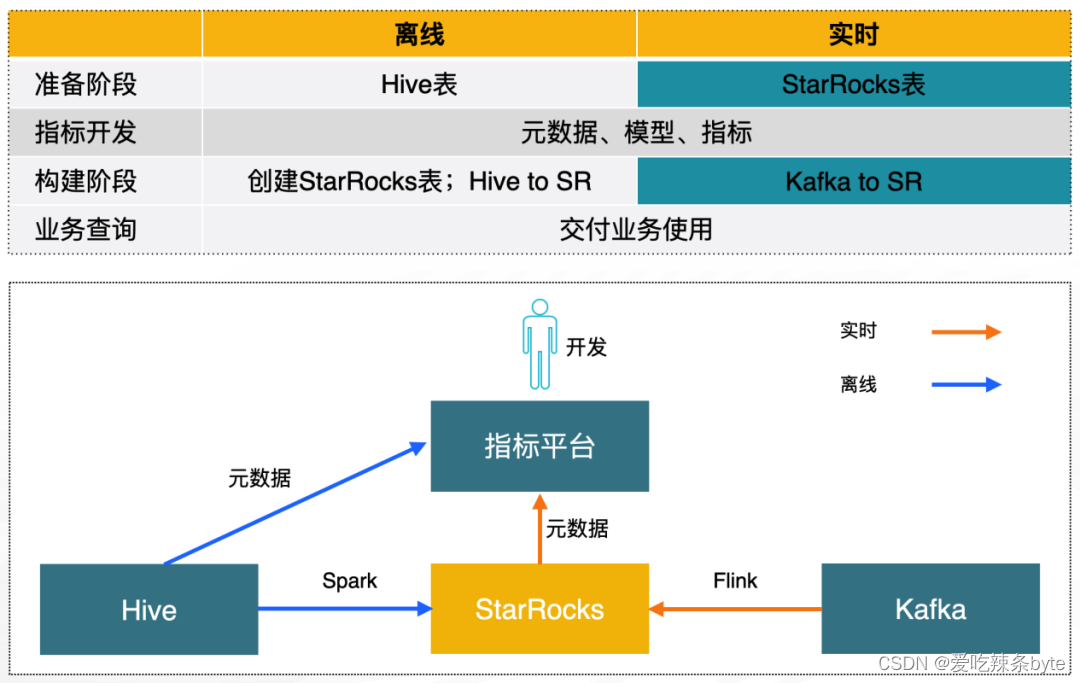
在模型构建阶段,使用 Spark任务将Hive数据同步到StarRocks 中,使用Flink同步Kafka中的数据。
在指标分析场景中引入StarRocks,需要关注的主要问题有两个:
(1)建表:
- 离线场景:数据来源于Hive,可以进行数据内容探测,根据数据量自动计算分桶数(StarRocks自动分桶策略),根据实践经验,慢查询sql中有很大一部分是模型问题导致(模型表选择、分区分桶选择等),智能化建表模式能更好的适配业务。
- 实时场景:虽然可以预估数据规模来生成表模型,但是业务的增长和发展是难以预估的,因此,对事实表通过添加定期巡检任务进行周期性的检测,根据历史数据规模评估表的分区和分桶是否合理,定时向用户反馈,协助用户进行模型优化。
(2)数据导入:
- 临时分区:采用临时分区来解决导入期间无法查询的问题
- 预聚合:Spark任务将Hive数据同步到StarRocks的过程中,先在spark阶段对数据进行部分计算,以降低导入过程中BE节点的资源消耗,由于大量的导入通常发生在晚上0点至凌晨6点之间,并伴随着离线导入的高峰期,提前进行聚合可以减轻compaction的压力。
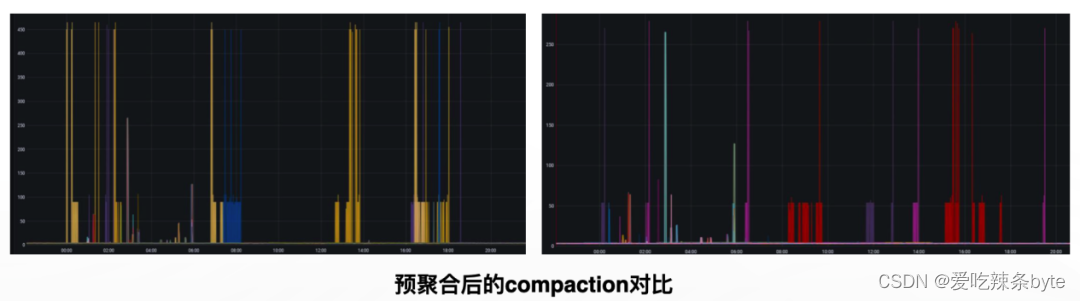
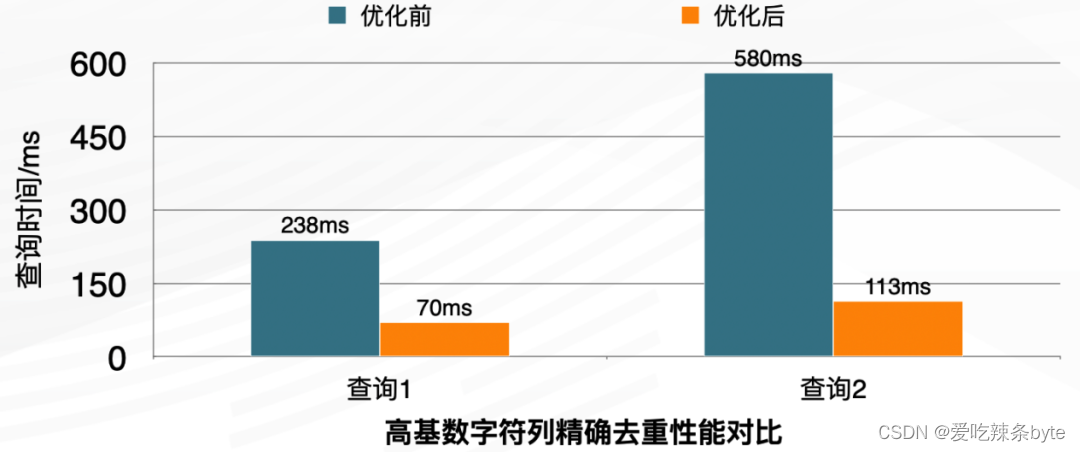
- 高基数的字符列精确去重:需要兼容之前的字符精确去重场景( Kylin、 Druid)使用 Hive 的全局字典来实现去重列编码。去重计数列使用bitmap类型,查询性能提高约3到4倍,在高QPS场景下,集群吞吐能力提升明显。
2.2 实时业务
实时分析场景:ClickHouse To StarRocks
ClickHouse不支持直接的update操作,因此需要通过使用视图和 argMax() 函数计算最新数据以达到实时更新的目的。对一个复杂的模型而言,需要为每一张表都创建对应的视图,最终要多张表和视图才能实现,如图 7 所示:

ClickHouse 涉及到本地表、分布式表和视图等不同层级的结构,最顶层的视图view相当于用户指标建模时所用的表,从开发角度来看相当复杂:
-
开发门槛较高:数据开发人员需要对 ClickHouse 有较高的掌握程度
-
维护迭代成本高:对于频繁迭代的业务来说,模型的修改和数据验证过程会变得比较复杂
-
底表数据量大:底层表存储了所有变更记录,在频繁变更的场景,低表的数据量会变得很大
-
并发场景下Scan高:底层每次执行都需要扫描大量数据,导致集群的I/O压力较高,读写互相影响
-
Join性能有限:在复杂场景下,多张表的关联查询性能不及预期
StarRocks 原生支持update、高性能的Join,高QPS这些特性可以解决以上所有痛点;针对目前ClickHouse中存量的模型,可以通过以下方式平滑迁移到StarRocks:
- 模型:使用 Duplicate 模型对应 ClickHouse 中的MergeTree模型,StarRocks 中与 argMax() 函数对应的有 row_number()
-
查询:查询层通过查询服务直接转换到StarRocks语法结构
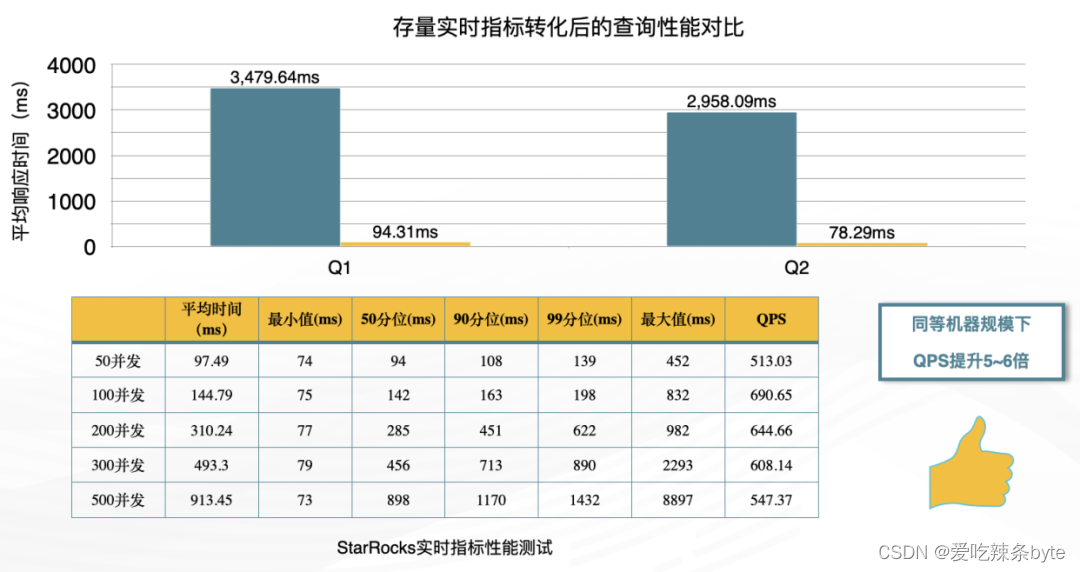
下图是迁移后查询性能对比结果,平均响应时间大幅下降。通过相同集群规模的并发压测,QPS提升了5倍以上。
2.3 可视化分析
ad-hoc场景:Presto To StarRocks
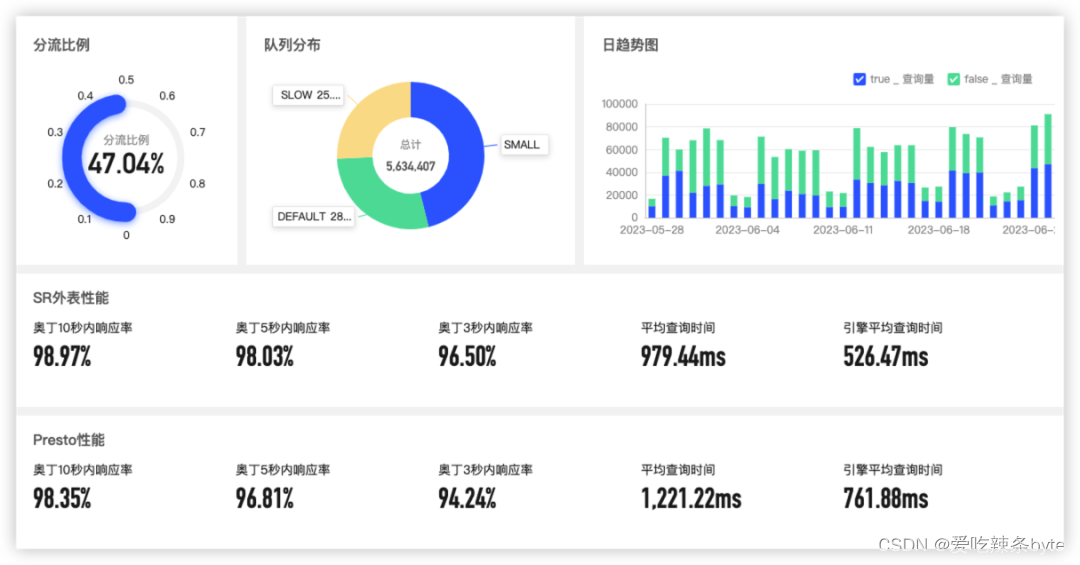
贝壳内部的BI 产品ODIN分析平台提供了基于Hive的分析能力,底层通过Presto引擎查询,用户通过PrestoSql进行建模分析,模型和引擎耦合性非常紧密,无法轻易转换成到其他引擎的查询。 StarRocks支持了 Hive 外表的功能,相比Presto有 3 倍以上的性能提升,使得 StarRocks 在贝壳有能力统一 OLAP 场景。目前已开始将分流到 StarRocks 做测试验证,后续随着 StarRocks Trino/Presto 兼容能力的进一步提升,会继续提升 StarRocks 的流量占比,实现 StarRocks 在分析层的完全统一。
三、未来规划
贝壳找房引入 StarRocks已经有两年时间了,从实践结果来看,StarRocks能满足90% 以上的需求场景。引入StarRocks对贝壳整个分析链路的建设起到了关键性作用,达到了极速统一的目标,并且带来了显著的性能收益,极大提升了OLAP分析场景的能力和效率。以下是未来的发展规划:
3.1 StarRocks集群的稳定性
对大规模集群的运维,需要从以下几个方面加强稳定性建设:
- 细化监控维度,增加重要指标的监控告警
- 集群上下游链路的阻断控制能力:阻断能力在稳定性保障中非常重要,监控的目的是更好地发现问题,一旦发现问题,就需要有效的手段来控制降级,比如查询降级,危险SQL拦截,写入限制等。
- 多集群数据源的故障恢复自动化:对于一个核心业务,已经建立了双链路保障策略,出现问题时能够自动切换,不需要人工干预。
3.2 StarRocks 新特性采用
当前我们比较关注 StarRocks 新特性主要是物化视图、Trino 语法兼容和 LakeHouse 架构。
- 物化视图在OLAP场景下对查询的性能提升非常大,目前社区在物化视图的多表,异步,自动更新等方面已经有了很丰富的功能支持,如何将这些功能结合业务场景,自动探测查询模式生成对应的物化视图将是未来的重点工作。
-
从 StarRocks 3.0 版本开始,StarRocks 支持Trino方言,这一点对存量的 Presto模型迁移来说,降低了迁移和使用成本,同时有不错的查询性能提升。
- LakeHouse架构是StarRocks3.0 的新架构模式,相比2.0版本的资源隔离能力,全新的存算分离架构支持硬资源隔离,这个特性使得现在的多个小规模集群模式可以统一成大规模集群,进一步降低资源和维护成本;弹性计算能力可以满足不同业务的使用场景。此外,StarRocks也支持了Apache Hudi、Apache Iceberg 和 Delta Lake 主流数据湖,统一湖仓查询场景不再是问题。
参考文章:
性能全面飙升!StarRocks 在贝壳找房的极速统一实践
















)


