环境配置
vgpu-smi 查看显卡资源使用情况

新开一个终端执行下面的命令实时观察 GPU 资源的使用情况。
watch vgpu-smi
复制环境到我们自己的 conda 环境
/root/share/install_conda_env_internlm_base.sh lmdeploy
激活环境
conda activate lmdeploy
安装依赖库
# 解决 ModuleNotFoundError: No module named 'packaging' 问题
pip install packaging
# 使用 flash_attn 的预编译包解决安装过慢问题
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whlpip install 'lmdeploy[all]==v0.1.0'
服务部署
这一部分主要涉及本地推理和部署。我们先看一张图。
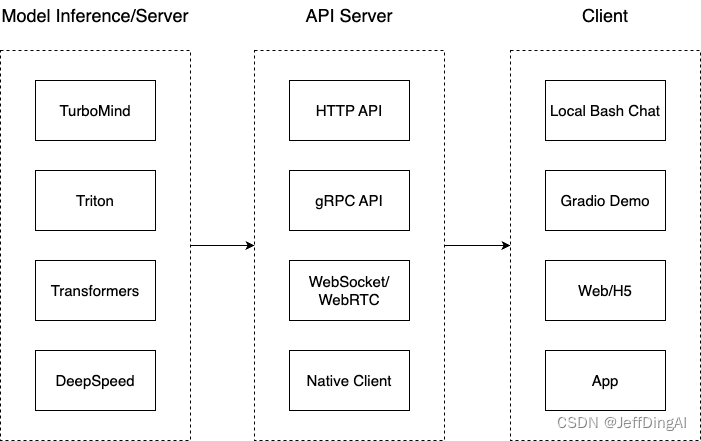
我们把从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- Client。可以理解为前端,与用户交互的地方。
- API Server。一般作为前端的后端,提供与产品和服务相关的数据和功能支持。
值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“API Server”合并,有的甚至是三个流程打包在一起提供服务。
接下来,我们看一下lmdeploy提供的部署功能。
模型转换
在线转换
lmdeploy chat turbomind /share/temp/model_repos/internlm-chat-7b/ --model-name internlm-chat-7b
运行效果

离线转换
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/
TurboMind 推理+命令行本地对话
# Turbomind + Bash Local Chat
lmdeploy chat turbomind ./workspace
TurboMind推理+API服务
启动服务
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \--server_name 127.0.0.1 \--server_port 23333 \--instance_num 64 \--tp 1
执行命令
# ChatApiClient+ApiServer(注意是http协议,需要加http)
lmdeploy serve api_client http://localhost:23333
ssh打开
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p <你的ssh端口号>
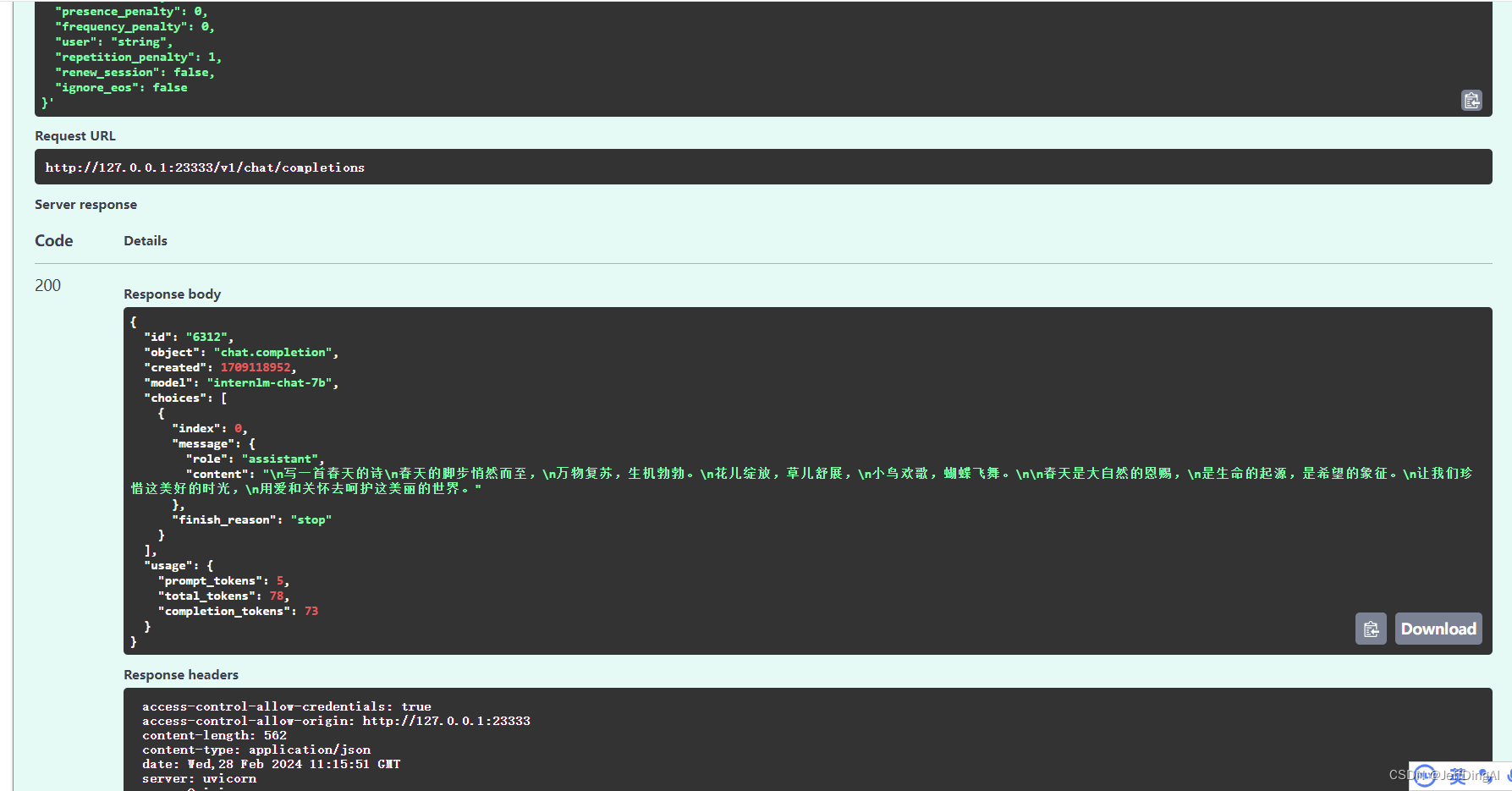
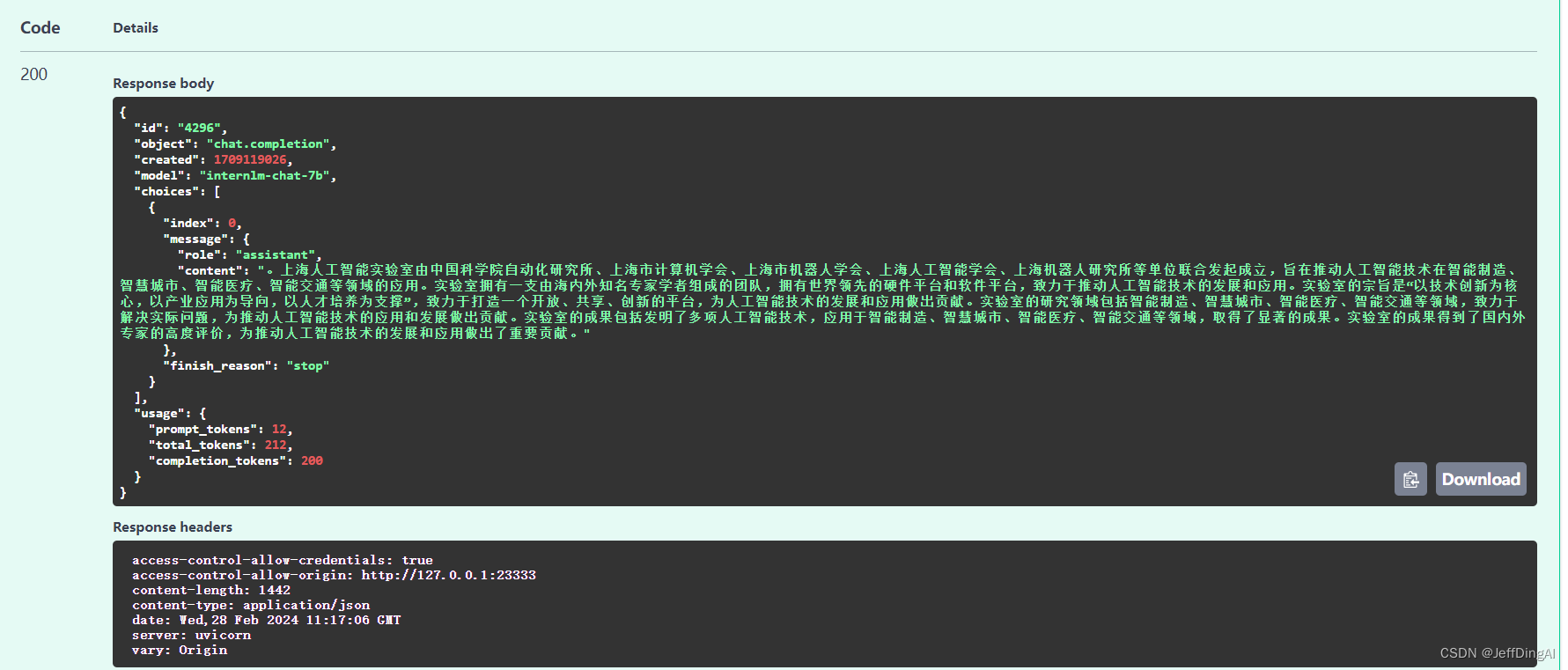
v1/chat/completions 接口为例,简单试一下
{"model": "internlm-chat-7b","messages": "写一首春天的诗","temperature": 0.7,"top_p": 1,"n": 1,"max_tokens": 512,"stop": false,"stream": false,"presence_penalty": 0,"frequency_penalty": 0,"user": "string","repetition_penalty": 1,"renew_session": false,"ignore_eos": false
}
运行效果
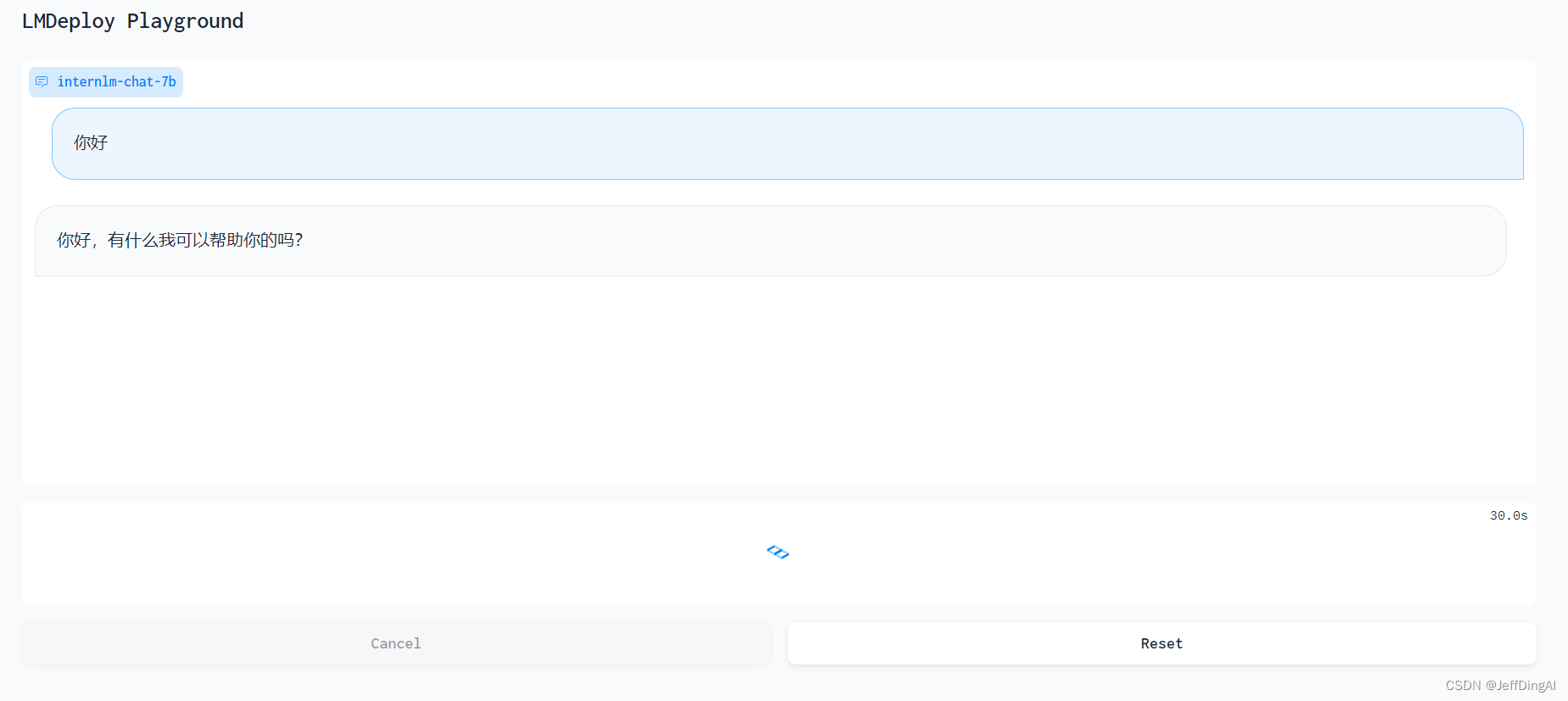
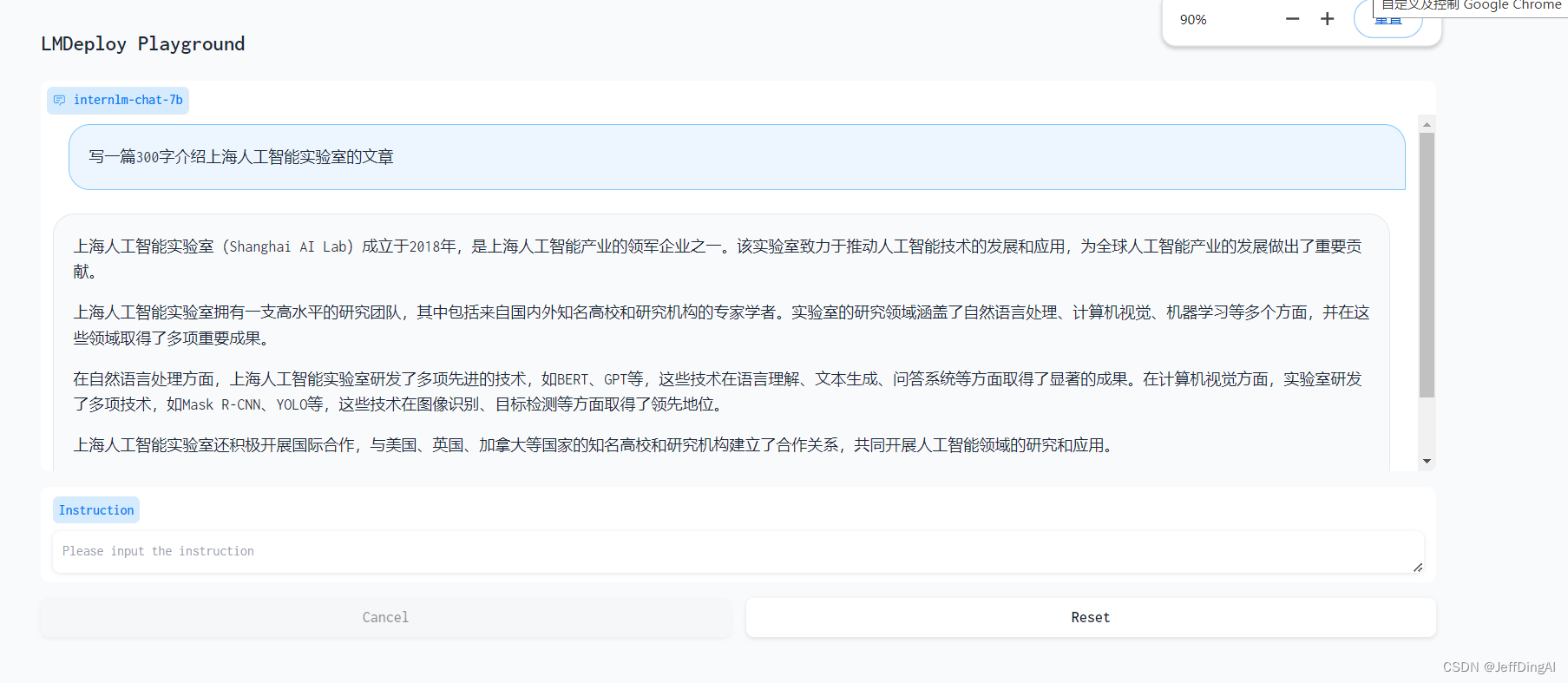
网页 Demo 演示
TurboMind 服务作为后端
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \--server_name 0.0.0.0 \--server_port 6006 \--restful_api True
运行效果:
作业
本地对话

API形式
web形式:
)




)










实现反向代理客户端 IP透传)

)
)