本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure Synapse】系列。
前言
Azure Synapse Link for SQL 可以提供从SQL Server或者Azure SQL中接近实时的数据加载。通过这个技术,使用SQL Server/Azure SQL中的新数据能够几乎实时地传送到Synapse(SQL DW)中。然后进行后续的数据分析。
这个过程通过change feed技术最小化对Azure SQL/SQL Server的影响。
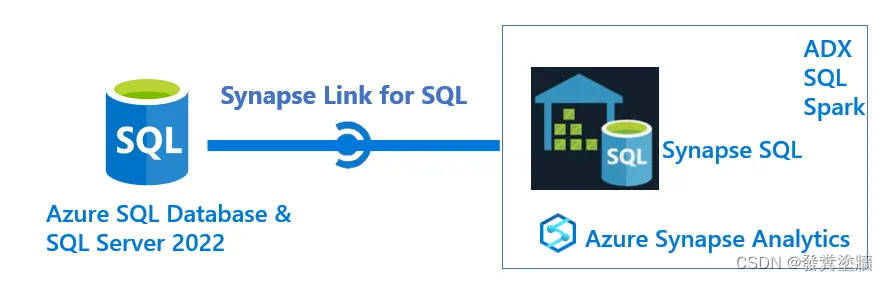
在这个移动过程中,会使用ADLS Gen2 作为暂存,然后再加载到Synapse dedicated pool中。在初始化阶段,先会全量加载然后后续再进行增量加载。
实操
假定已经有了一个Azure SQL ,和Synapse workspace, 前者相对简单,下面演示创建Synapse workspace的简要步骤,因为这是演示所以会跳过一些正式环境中必须的配置。
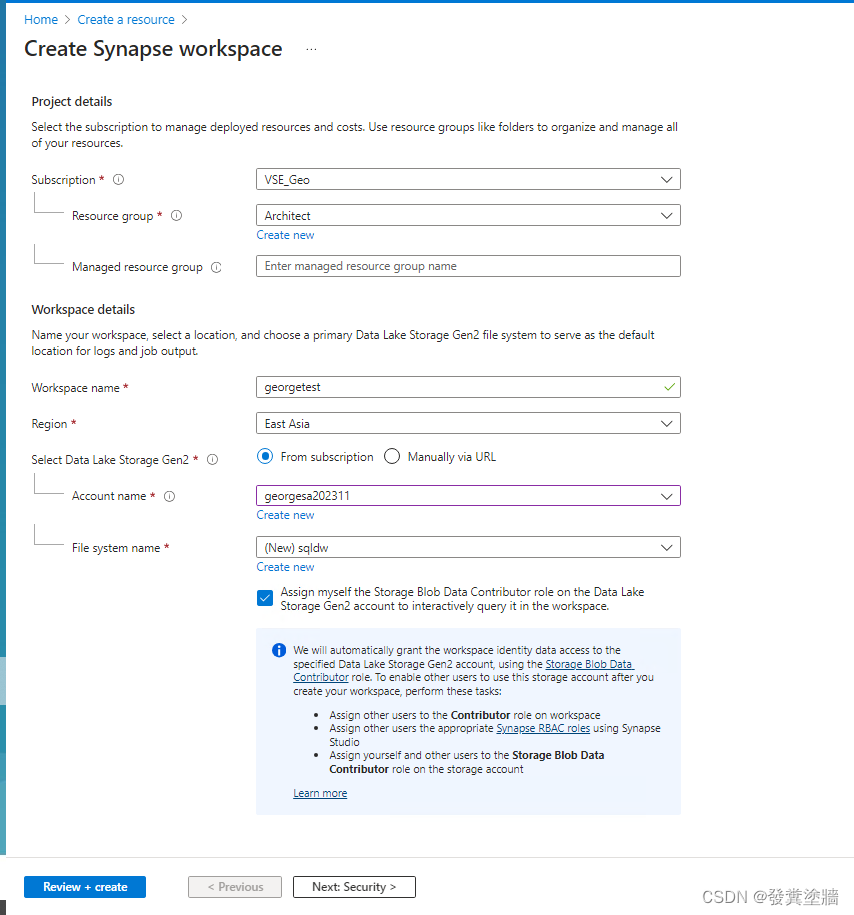
创建Synapse workspace
从下图可以看出它会要求创建或使用现有的一个ADLS Gen2,并指定File System name(Container)
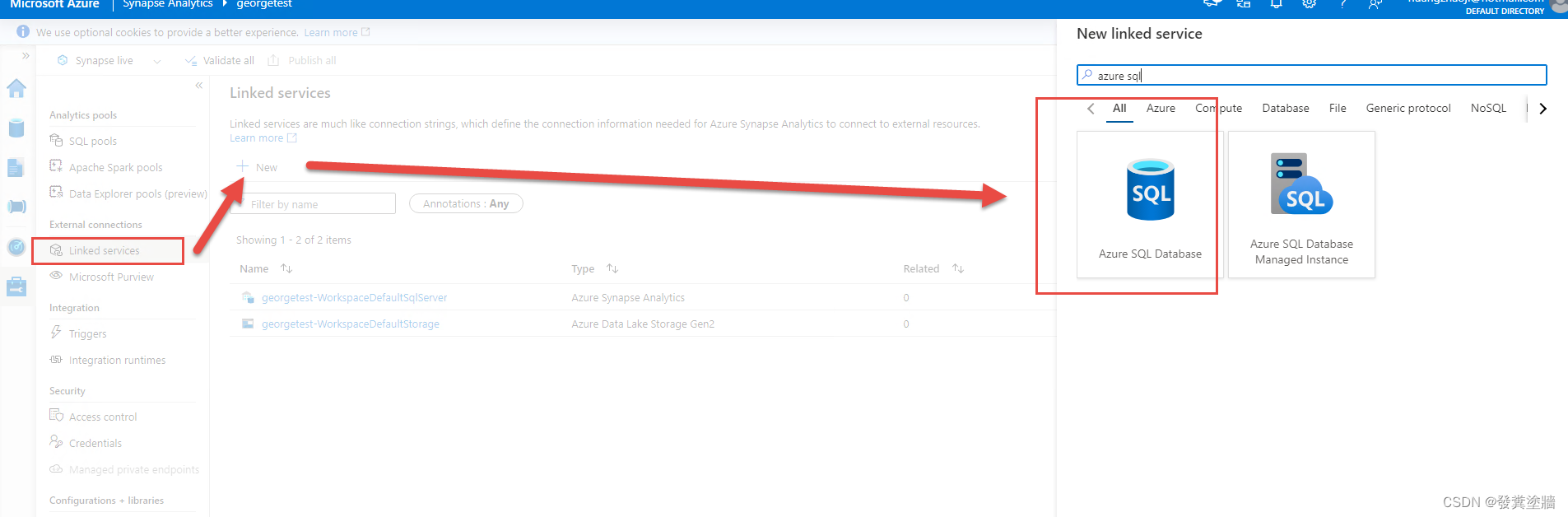
搭建连接
登陆进去之后,从【管理】-> 【Linked Services】->【新建】-> 选择Azure SQL:
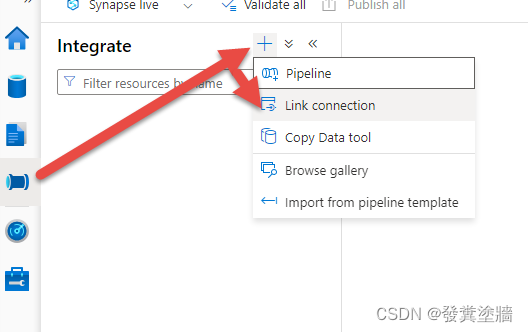
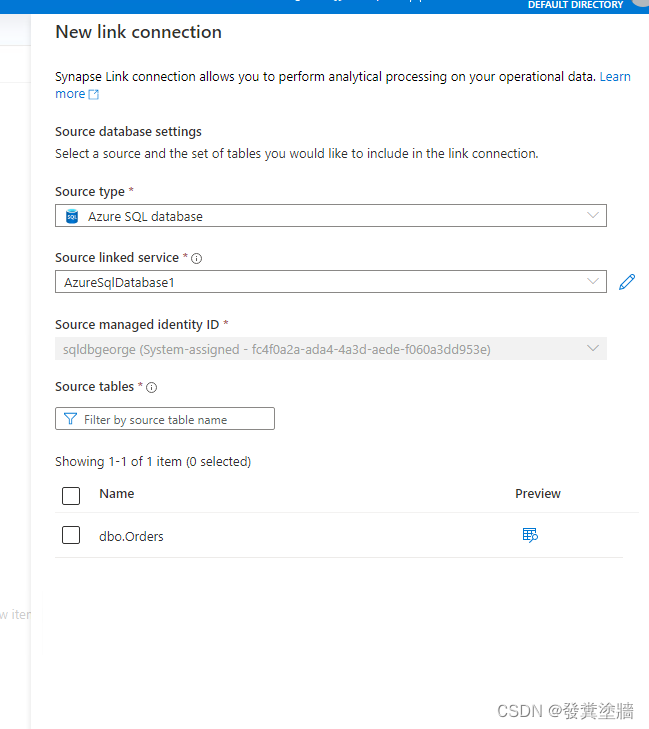
输入信息之后,从【集成/Integrate】中新建一个Link connection。
在新建过程中如果看到下面报错"The selected source cannot be used without a system-assigned managed identity",意味着你需要启用源系统的sysem MI。
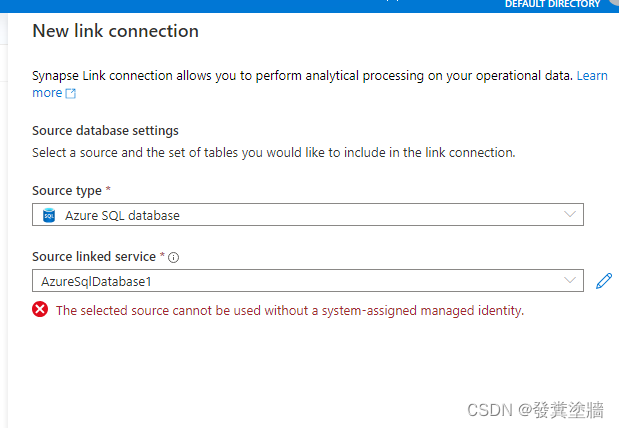
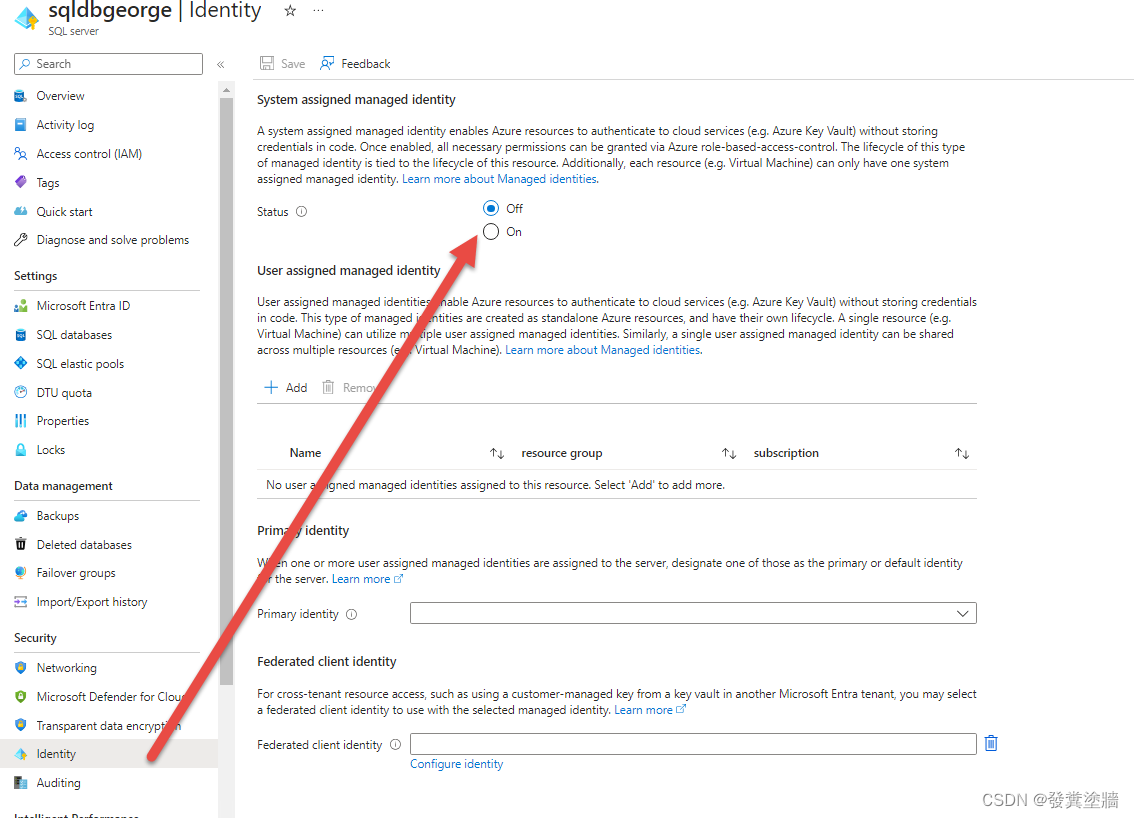
在下图所示的地方启用。
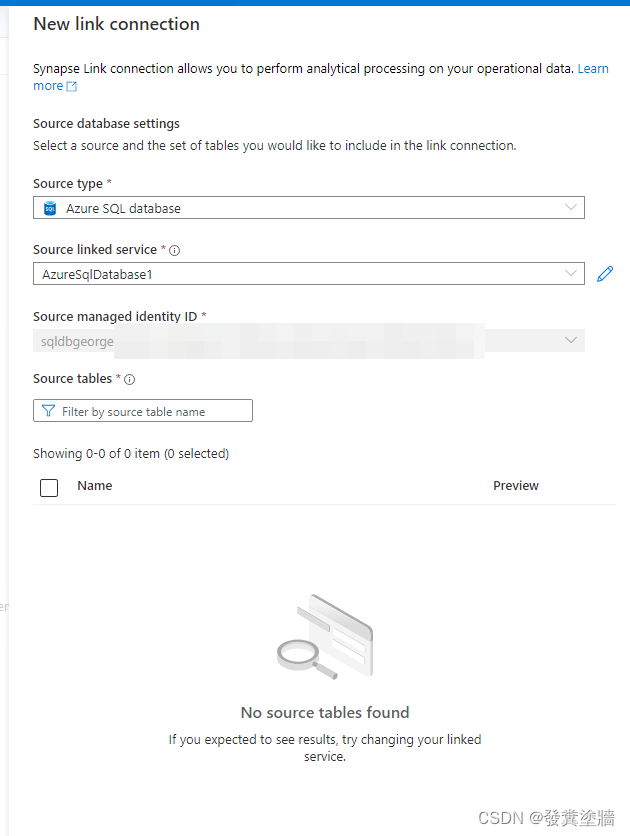
刷新之后可以看到报错信息消失。但是此时源系统还没有表。
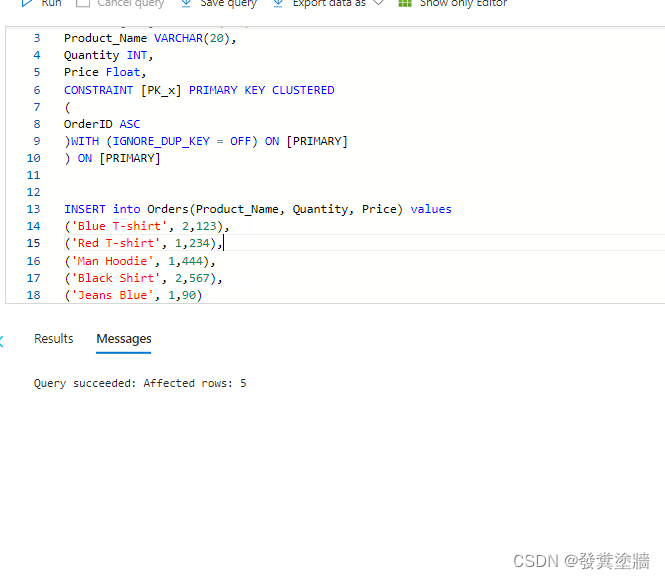
登陆Azure SQL, 然后建一个测试表:
Create Table Orders(
OrderID [int] IDENTITY(1,1) NOT NULL,
Product_Name VARCHAR(20),
Quantity INT,
Price Float,
CONSTRAINT [PK_x] PRIMARY KEY CLUSTERED
(
OrderID ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
并插入一些测试数据。
在Synapse中再次刷新可以看到新建的表出现了。
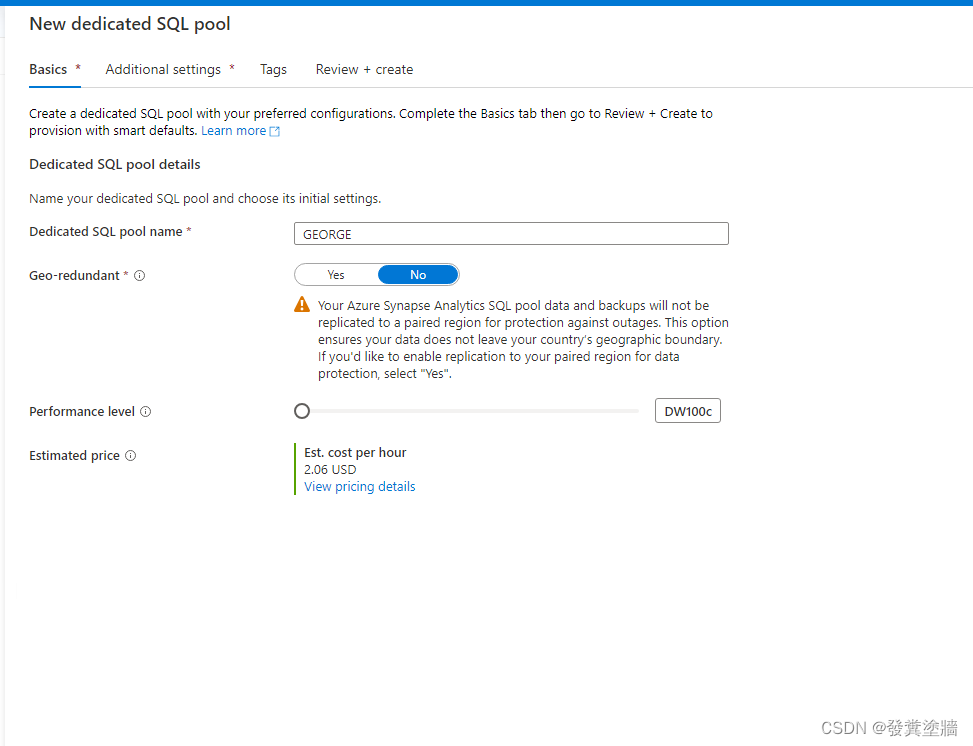
建立专用SQL pool
成本考虑选择最低配。
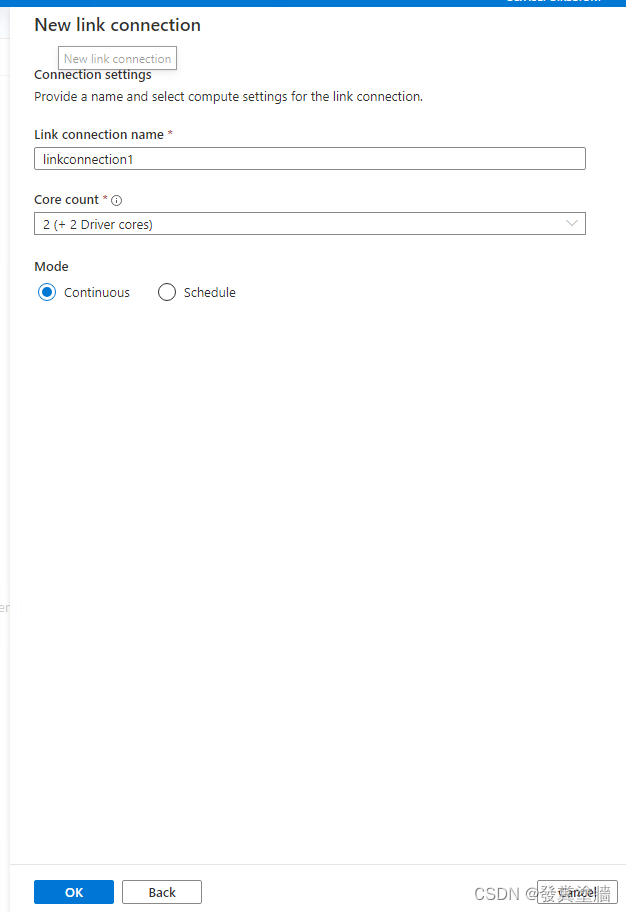
可以选择连续运行或者按计划运行。
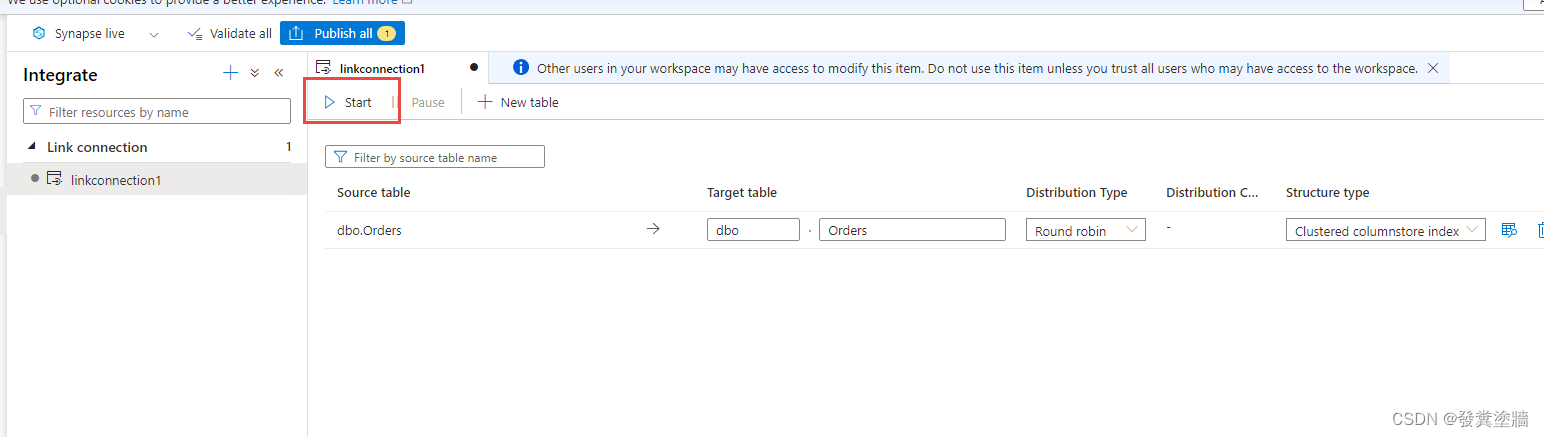
配置好之后,点击【start】启动,首次运行需要点时间。这个过程也会在Synapse中自动创建目标表。
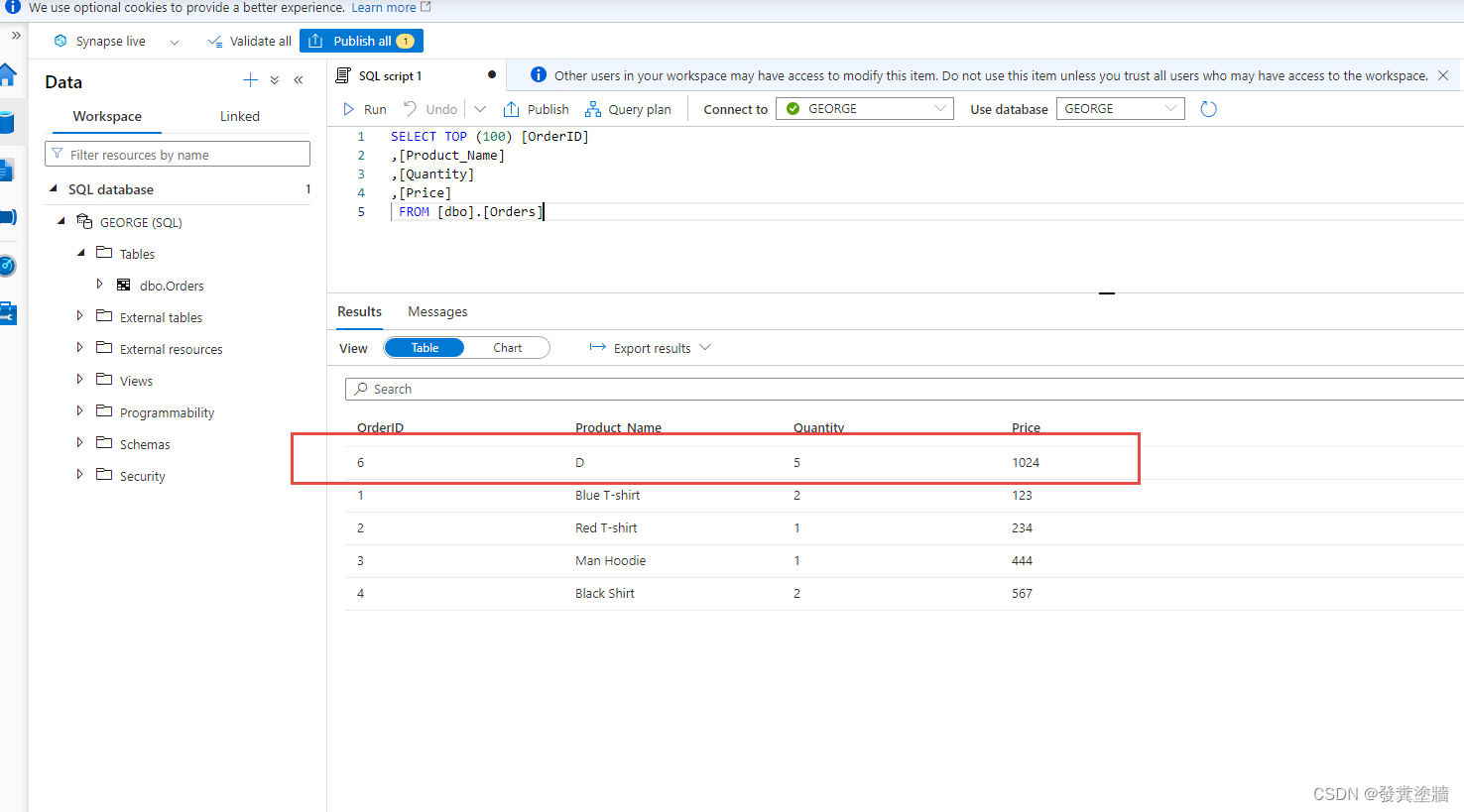
等待初始化完毕之后可以在下图中查询到数据同步情况。
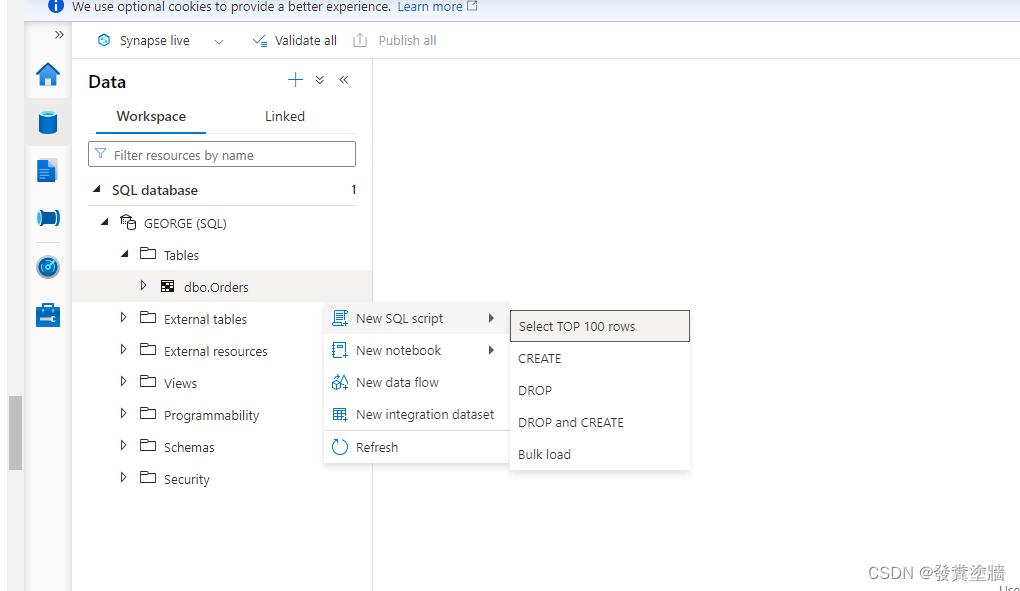
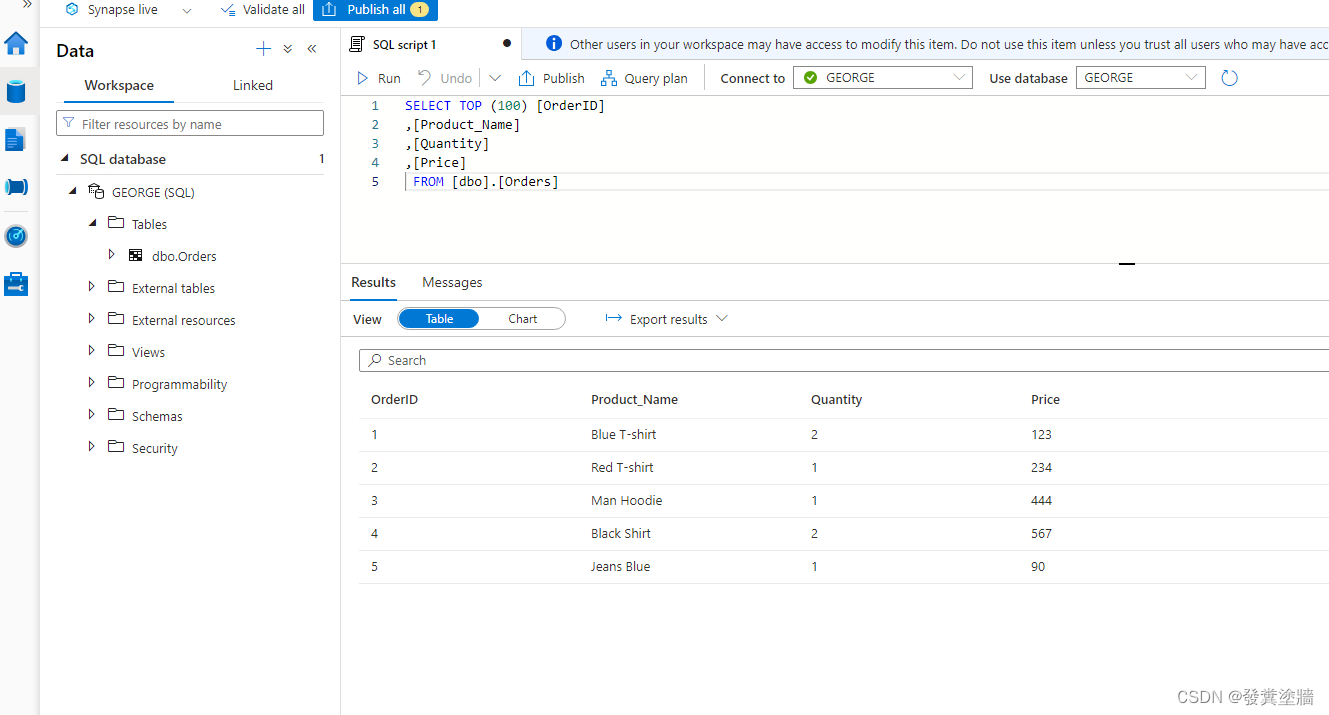
我们尝试在源系统删除一行数据之后再次查询发现数据是可以同步的。
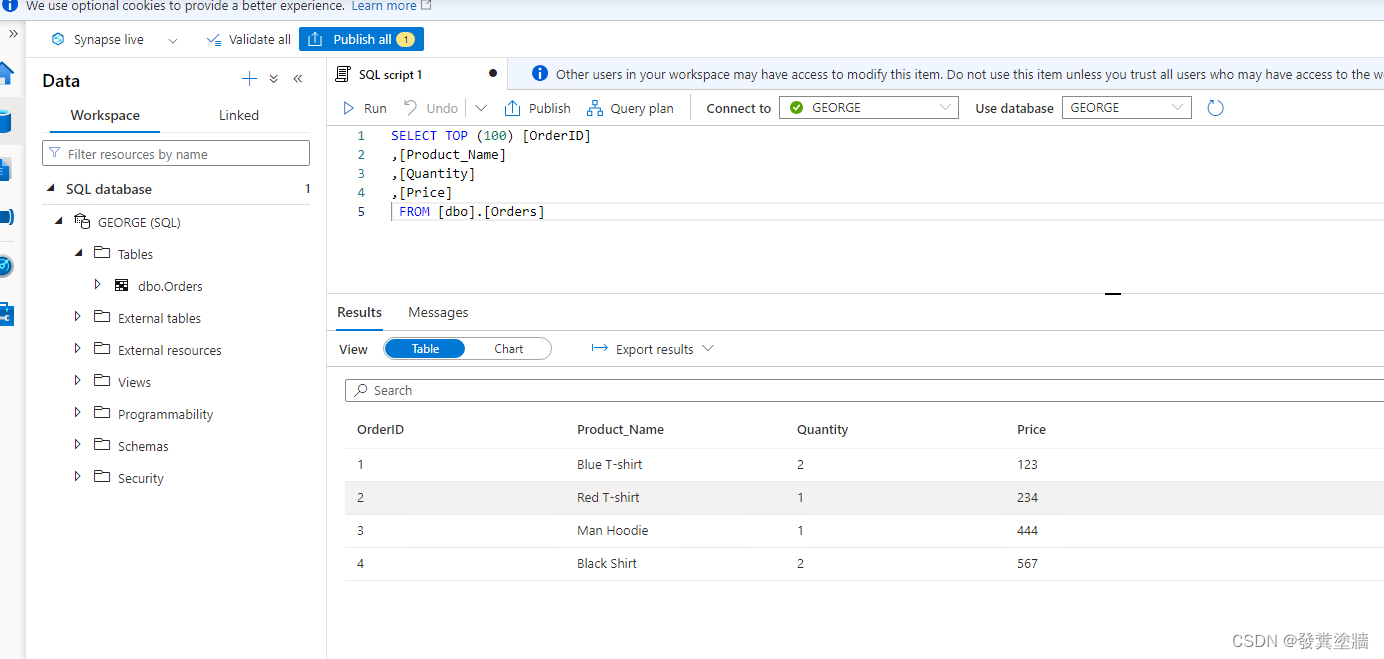
再次测试:
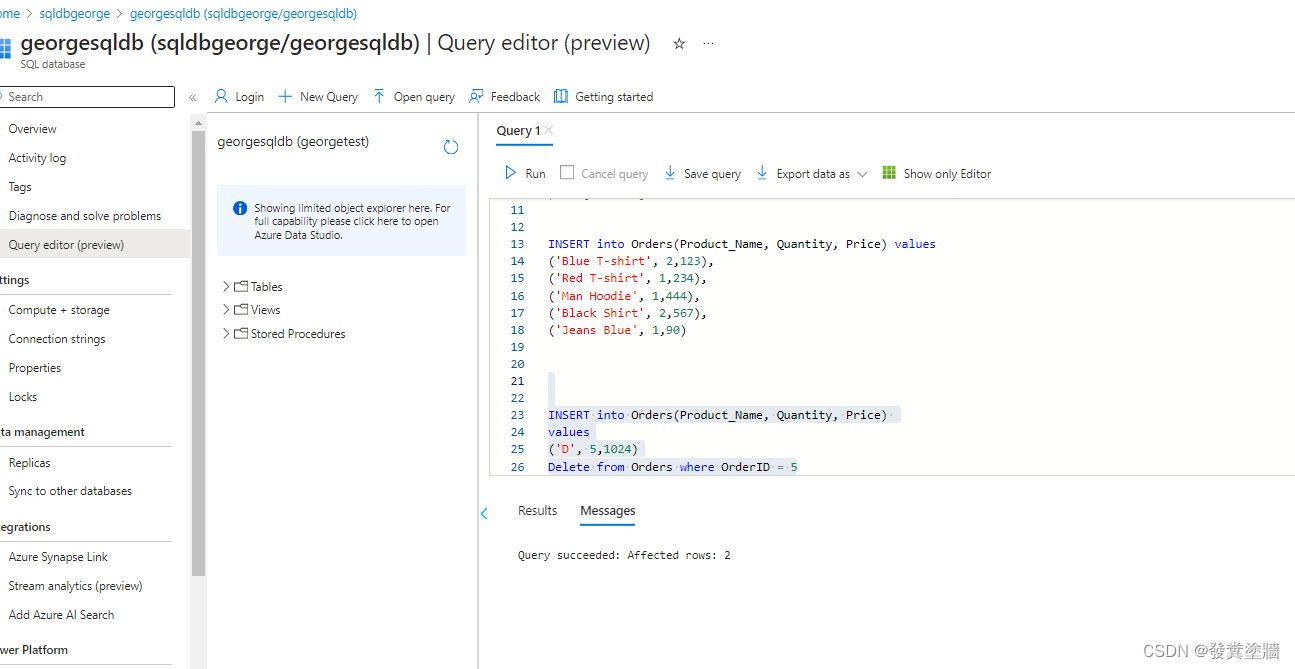
结果依然可以同步。
注意事项
- 源数据表必须有主键。
- 对于源表启用了CDC(Change Data Capture) , Temporal history table, Always Encrypted, In-Memory OLTP, Column store Index, Graph等,都不支持Azure Synapse Link for SQL, 简单来说就只能用于常规未进行处理的表。
- 在同步过程中,表名会与源系统一致,但是架构名则只是dbo, 所以对于那些非dbo的表,需要提前建立。
- 慎重停止Link Connection,因为需要删除目标表,并且后续重新搭建和同步。
- 由于数据是分布式处理,所以如果使用了类似row_number()等窗口函数,序号可能会与源不一致。
)



)



)




)


![[Flutter]设置应用包名、名称、版本号、最低支持版本、Icon、启动页以及环境判断、平台判断和打包](http://pic.xiahunao.cn/[Flutter]设置应用包名、名称、版本号、最低支持版本、Icon、启动页以及环境判断、平台判断和打包)


