
1、写作动机:
调整大语言模型已经变得越来越耗资源,或者在模型权重是私有的情况下是不可能的。作者引入了代理微调,这是一种轻量级的解码时算法,它在黑盒 大语言模型 之上运行,以达到直接微调模型的结果,但只访问其在输出词汇上的预测。
2、主要贡献:
微调一个较小的语言模型,然后应用小型微调和未微调语言模型之间预测的差异,以将基础模型的原始预测朝向调整方向移动,同时保留更大规模预训练的好处。这个工作展示了使用小型调整语言模型通过解码时指导高效定制大型、潜在专有语言模型的前景。
3、方法:
假设有一个大型预训练模型 M,我们希望对其进行微调。对于输入 M 的任意输入,我们假设我们可以访问整个词汇表的输出 logit。我们假设存在一个小的预训练模型 M−,将直接微调它以获得 M+。请注意,M− 不需要与 M 属于同一模型系列;我们只需要它们共享相同的词汇表。代理微调通过为每个token添加一个 logit 偏移量来操作 M 关于下一个词的输出分布,该偏移量由 M− 和 M+ 的 logits 之间的差异确定。这是解码时专家的应用,其中 M+ 充当“专家”(其 logits 被加性组合),而 M− 则充当“反专家”(其 logits 被负组合),与基础模型 M 相结合。形式上,在每个时间步 t,我们将基础模型 M、专家 M+ 和反专家 M− 在提示 x<t 下进行条件设置,以获得 logit 分数(即,语言建模头部在整个词汇表上的最终未归一化分数)sM、sM+ 和 sM−。代理微调模型M~ 的概率分布由以下公式给出:
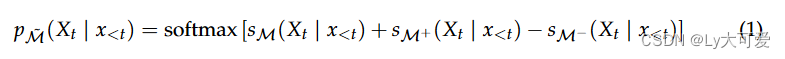
请注意,在概率空间中,我们有以下关系:

4、实验:
4.1指令微调实验:
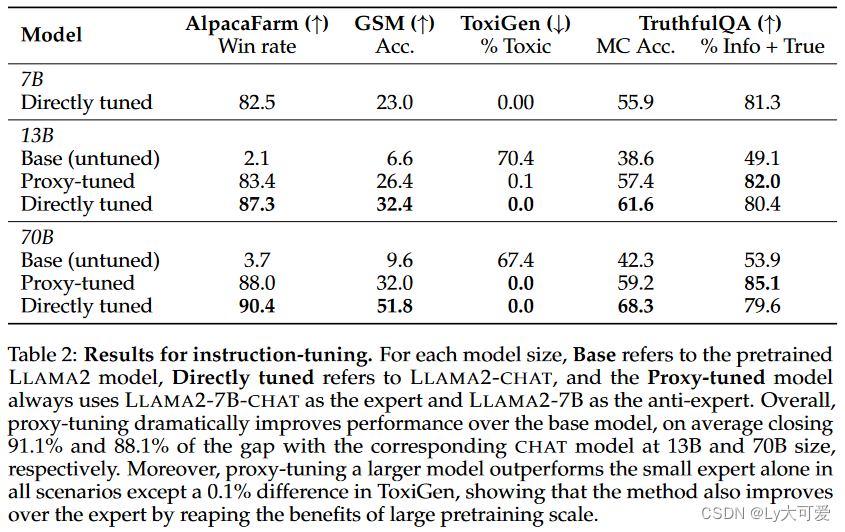
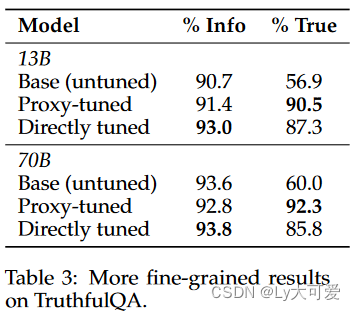
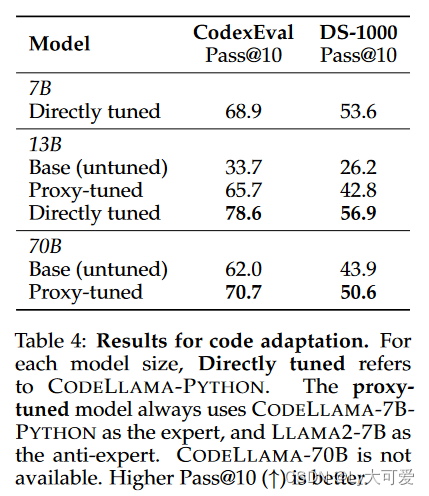
4.2代码相关实验:
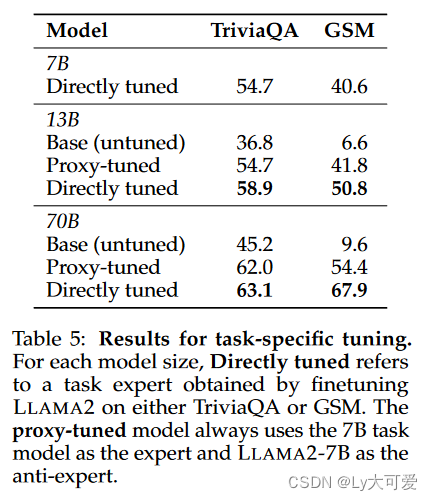
4.3任务微调实验:



)
)
)
)












