Python算法题集_随机链表的复制
- 题138:随机链表的复制
- 1. 示例说明
- 2. 题目解析
- - 题意分解
- - 优化思路
- - 测量工具
- 3. 代码展开
- 1) 标准求解【双层循环】
- 2) 改进版一【字典哈希】
- 3) 改进版二【单层哈希】
- 4) 改进版三【递归大法】
- 4. 最优算法
本文为Python算法题集之一的代码示例
题138:随机链表的复制
1. 示例说明
-
给你一个长度为
n的链表,每个节点包含一个额外增加的随机指针random,该指针可以指向链表中的任何节点或空节点。构造这个链表的 深拷贝。 深拷贝应该正好由
n个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的next指针和random指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。例如,如果原链表中有
X和Y两个节点,其中X.random --> Y。那么在复制链表中对应的两个节点x和y,同样有x.random --> y。返回复制链表的头节点。
用一个由
n个节点组成的链表来表示输入/输出中的链表。每个节点用一个[val, random_index]表示:val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点
head作为传入参数。示例 1:
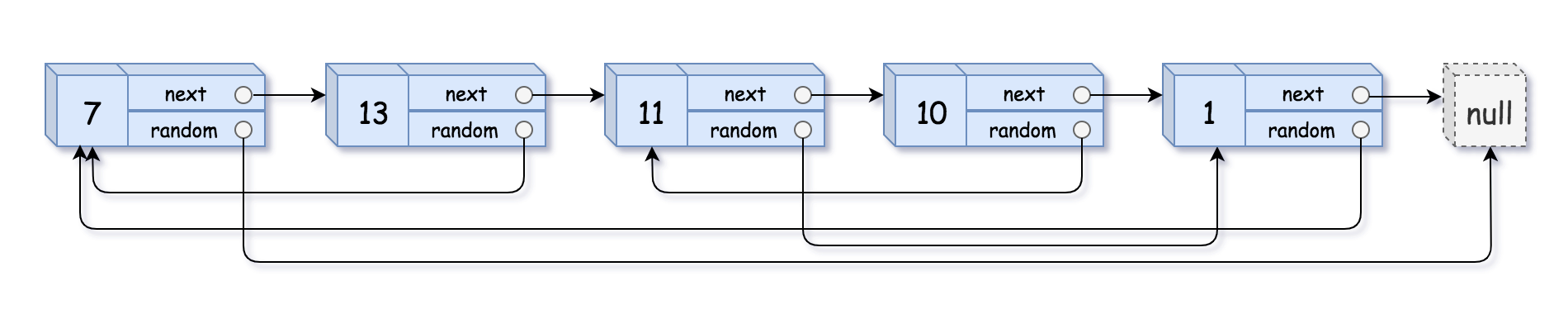
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]示例 2:

输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]示例 3:

输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]提示:
0 <= n <= 1000-104 <= Node.val <= 104Node.random为null或指向链表中的节点。
2. 题目解析
- 题意分解
- 本题为对链表中的节点进行复制,节点包括下一节点链接和随机节点链接
- 本题的主要计算是2块,1是链表遍历,2是随机节点链接检索
- 基本的解法是双层循环,复制链表1层循环,随机节点检索1层循环,所以基本的时间算法复杂度为O(n^2)
- 优化思路
-
通常优化:减少循环层次
-
通常优化:增加分支,减少计算集
-
通常优化:采用内置算法来提升计算速度
-
分析题目特点,分析最优解
-
标准方法是双层循环,先复制,再检索
-
可以用哈希法【字典】优化查询
-
可以用递归法进行节点复制的解析,但是递归法有最大层次,超过就会报错
-
- 测量工具
- 本地化测试说明:LeetCode网站测试运行时数据波动很大,因此需要本地化测试解决这个问题
CheckFuncPerf(本地化函数用时和内存占用测试模块)已上传到CSDN,地址:Python算法题集_检测函数用时和内存占用的模块- 本题很难超时,本地化超时测试用例自己生成,详见【最优算法章节】
3. 代码展开
1) 标准求解【双层循环】
外层遍历,内层检索,网站性能良好,本地性能不堪
性能良好,超越83%
import CheckFuncPerf as cfpclass Solution:@staticmethoddef copyRandomList_base(head):if not head: return Nonelist_origin, idx_origin = [], []while head:list_origin.append(head)idx_origin.append(-1)head = head.nextilen = len(list_origin)for iIdx in range(ilen):if list_origin[iIdx].random:idx_origin[iIdx] = list_origin.index(list_origin[iIdx].random)list_dist = []for iIdx in range(ilen):tmpNode = Node(list_origin[iIdx].val)list_dist.append(tmpNode)for iIdx in range(ilen-1):list_dist[iIdx].next = list_dist[iIdx+1]for iIdx in range(ilen):if idx_origin[iIdx] > -1:list_dist[iIdx].random = list_dist[idx_origin[iIdx]]return list_dist[0]result = cfp.getTimeMemoryStr(Solution.copyRandomList_base, ahead)
print(result['msg'], '执行结果 = {}'.format(result['result'].val))# 运行结果
函数 copyRandomList_base 的运行时间为 115717.23 ms;内存使用量为 17536.00 KB 执行结果 = 0
2) 改进版一【字典哈希】
双字典,将原链表、复制链表均存入字典,通过哈希优化检索
性能良好,超过81%
import CheckFuncPerf as cfpclass Solution:@staticmethoddef copyRandomList_ext1(head):if not head: return Nonedict_origin = {} dict_new = {} nodepre = Node(0) newnode = nodepreoriginhead = head idx = 0 while originhead:dict_origin[originhead] = idx newnode.next = Node(originhead.val)newnode = newnode.nextdict_new[idx] = newnode idx += 1 originhead = originhead.nextdict_new[idx] = None newnode = nodepre.nextoriginhead = headwhile originhead:random_node = originhead.randomnodepos = dict_origin[random_node] if random_node else idxnode = dict_new[nodepos] newnode.random = nodenewnode = newnode.nextoriginhead = originhead.nextreturn nodepre.next result = cfp.getTimeMemoryStr(Solution.copyRandomList_ext1, ahead)
print(result['msg'], '执行结果 = {}'.format(result['result'].val))# 运行结果
函数 copyRandomList_ext1 的运行时间为 390.09 ms;内存使用量为 19492.00 KB 执行结果 = 0
3) 改进版二【单层哈希】
将原链表、复制链表存入一个字典,通过哈希优化定位
马马虎虎,超过69%
import CheckFuncPerf as cfpclass Solution:@staticmethoddef copyRandomList_ext2(head):if not head: return Nonecurnode = headdict_nodes = {} while curnode:dict_nodes[curnode] = Node(curnode.val)curnode = curnode.next curnode = headwhile curnode:dict_nodes[curnode].next = dict_nodes[curnode.next] if curnode.next else Nonedict_nodes[curnode].random = dict_nodes[curnode.random] if curnode.random else Nonecurnode = curnode.nextreturn dict_nodes[head]result = cfp.getTimeMemoryStr(Solution.copyRandomList_ext2, ahead)
print(result['msg'], '执行结果 = {}'.format(result['result'].val))# 运行结果
函数 copyRandomList_ext2 的运行时间为 170.04 ms;内存使用量为 12820.00 KB 执行结果 = 0
4) 改进版三【递归大法】
采用递归方式进行节点复制,本地性能都不好,不管是否报错
性能优良,超越85%
import CheckFuncPerf as cfpclass Solution:@staticmethoddef copyRandomList_ext3(head):def copyNode(head, dict_nodes):if not head: return Nonewhile head not in dict_nodes.keys():headNew = Node(head.val) # 拷贝新节点dict_nodes[head] = headNew # 记录到哈希表中headNew.next = copyNode(head.next, dict_nodes)headNew.random = copyNode(head.random, dict_nodes)return dict_nodes[head]dict_nodes = {}return copyNode(head, dict_nodes)result = cfp.getTimeMemoryStr(Solution.copyRandomList_ext3, ahead)
print(result['msg'], '执行结果 = {}'.format(result['result'].val))# 运行结果
Traceback (most recent call last):......
[Previous line repeated 991 more times]
RecursionError: maximum recursion depth exceeded
4. 最优算法
根据本地日志分析,最优算法为第3种copyRandomList_ext2
ilen = 100000
list_node =[]
for iIdx in range(ilen):tmpListnode = Node(iIdx)list_node.append(tmpListnode)
for iIdx in range(ilen-1):list_node[iIdx].next = list_node[iIdx+1]
for iIdx in range(ilen):list_node[iIdx].random = list_node[random.randint(1, ilen)-1]
ahead = list_node[0]
result = cfp.getTimeMemoryStr(Solution.copyRandomList_base, ahead)
print(result['msg'], '执行结果 = {}'.format(result['result'].val))# 算法本地速度实测比较
# 链表长度900
函数 copyRandomList_base 的运行时间为 10.00 ms;内存使用量为 296.00 KB 执行结果 = 0
函数 copyRandomList_ext1 的运行时间为 1.00 ms;内存使用量为 196.00 KB 执行结果 = 0
函数 copyRandomList_ext2 的运行时间为 1.00 ms;内存使用量为 128.00 KB 执行结果 = 0
函数 copyRandomList_ext3 的运行时间为 2.00 ms;内存使用量为 1104.00 KB 执行结果 = 0
# 链表长度10W
函数 copyRandomList_base 的运行时间为 115717.23 ms;内存使用量为 17536.00 KB 执行结果 = 0
函数 copyRandomList_ext1 的运行时间为 390.09 ms;内存使用量为 19492.00 KB 执行结果 = 0
函数 copyRandomList_ext2 的运行时间为 170.04 ms;内存使用量为 12820.00 KB 执行结果 = 0
Traceback (most recent call last): # 递归法 copyRandomList_ext3 超时......[Previous line repeated 991 more times]
RecursionError: maximum recursion depth exceeded
一日练,一日功,一日不练十日空
may the odds be ever in your favor ~


 2024 首聚香江)
--H. Mad City--基环树博弈)





)

和toROSMsg()不能正确处理xyz之外其他field的数据长度)




测占空比)


数据准备的流程)