文章目录
- 介绍
- 小结
介绍
ChatGPT 之所以成为ChatGPT,基于人类反馈的强化学习是其中重要的一环。而ChatGPT 的训练工程称得上是复杂而又神秘的,迄今为止,OpenAl也没有开源它的训练及调优的细节。
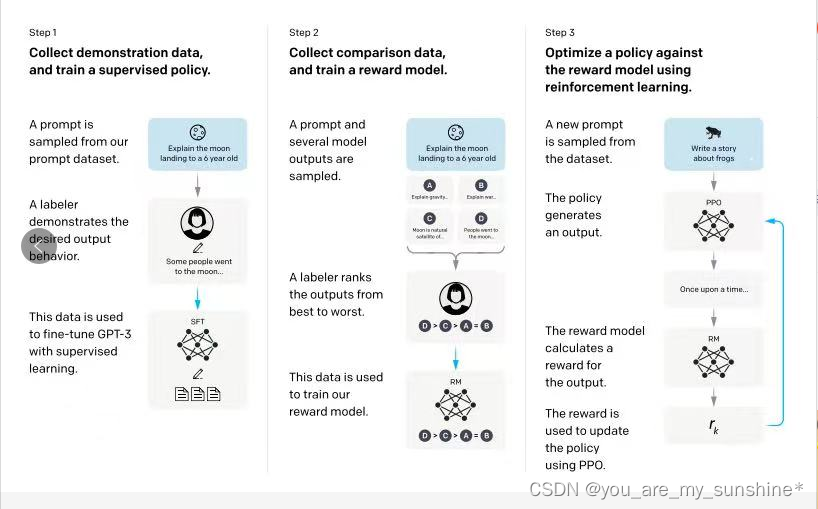
从 OpenAl已经公开的一部分信息推知,ChatGPT的训练主要由三个步骤组成,如下图所示。
原文:
译文:
-
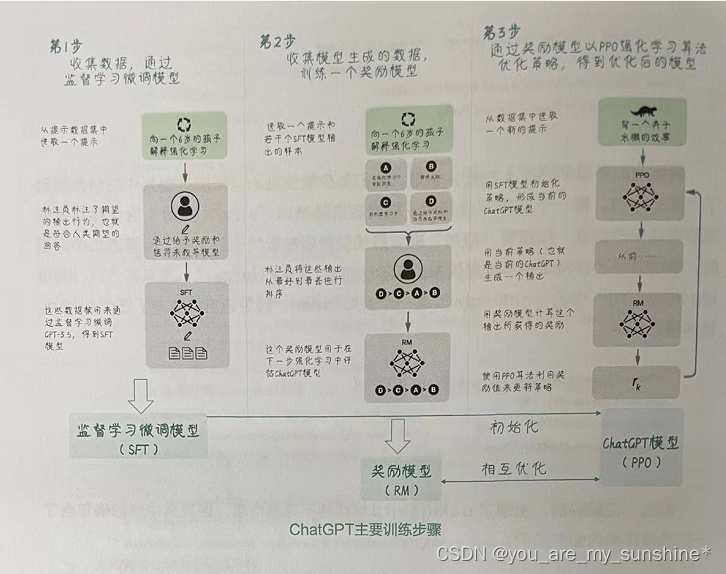
第1步,先使用大量数据(从Prompt数据库中抽样)通过监督学习在预训练的 GPT-3.5基础上微调模型,得到一个初始模型,就是监督学习微调模型(Supervised Fine-Tune Model,SFT)——暂且把它命名为“弱弱的ChatGPT”。
-
第2步,请标注人员为初始模型“弱弱的ChatGPT”对同一问题给出的不同答案排序,评估这些答案的质量,并为它们分配一个分数。然后使用这些数据训练出一个具有人类偏好的奖励模型(Reward Model,RM)–这个奖励模型能够代替人类评估 ChatGPT 的回答大概会得到多少奖励。
-
第3步,初始化“弱弱的ChatGPT”模型,从Prompt数据库中抽样,与模型进行对话。然后使用奖励模型对“弱弱的ChatGPT”模型的输出进行打分。再将结果反馈给“弱弱的 ChatGPT”模型,通过近端策略优化(Proximal Policy Optimization, PPO)算法进一步优化模型。
不过,这还没完,此时ChatGPT模型经过优化,能生成更高质量的回答,那么,再回到第1步用优化后的ChatGPT初始化模型,就得到更好的SFT模型;用更好的 SFT 在第2步中取样,又得到更好的回答;对更高质量的回答进行排序、评分后,就能训练出更好的奖励模型,于是获得更好的反馈……这样不断循环,ChatGPT 就一步接着一步,在接受人类的反馈的同时,不断自我优化,一波接一波,越变越强。
小结
ChatGPT训练三阶段:
阶段1:收集数据,通过监督学习微调模型
阶段2:收集模型生成的数据,训练一个奖励模型
阶段3:通过奖励模型以PPO强化学习算法优化策略,得到优化后的模型
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…
-----存储芯片与CPU的连接)



)
:做单手数设计)


![[BIZ] - 1.金融交易系统特点](http://pic.xiahunao.cn/[BIZ] - 1.金融交易系统特点)


与exec_()的区别)
)


)



