深入探索Pandas读写XML文件的完整指南与实战read_xml、to_xml
XML(eXtensible Markup Language)是一种常见的数据交换格式,广泛应用于各种应用程序和领域。在数据处理中,Pandas是一个强大的工具,它提供了read_xml和to_xml两个方法,使得读取和写入XML文件变得简单而直观。

读取XML文件 - read_xml方法
参数说明:
1. path(必需)
- 指定XML文件的路径或URL。
2. xpath(可选)
- 用于定位XML文档中的数据的XPath表达式。默认为根节点。
3. namespaces(可选)
- 命名空间字典,用于处理XML文档中的命名空间。
4. converters(可选)
- 字典,指定将XML元素值转换为特定数据类型的转换器函数。
5. element_index(可选)
- 指定XML文档中用于作为索引的元素名称或XPath表达式。
代码实例:
import pandas as pd# 读取XML文件
xml_path = 'example.xml'
df = pd.read_xml(xml_path)# 打印DataFrame
print(df)
写入XML文件 - to_xml方法
参数说明:
1. path_or_buffer(必需)
- 指定XML文件的路径或可写入的对象,如文件对象或字节流。
2. index(可选)
- 控制是否包含行索引。默认为True。
3. mode(可选)
- 写入模式,支持’w’(覆盖)和’a’(追加)。默认为’w’。
4. force_cdata(可选)
- 是否强制将文本包装在CDATA块中。默认为False。
代码实例:
import pandas as pd# 创建示例DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)# 写入XML文件
xml_output_path = 'output.xml'
df.to_xml(xml_output_path, index=False)# 打印成功信息
print(f'XML文件已成功写入:{xml_output_path}')
代码解析:
- 读取XML文件时,
pd.read_xml方法会根据提供的路径解析XML文档并返回一个DataFrame。 - 写入XML文件时,
df.to_xml方法将DataFrame转换为XML格式并保存到指定路径。
通过这两个方法,Pandas为处理XML数据提供了方便而灵活的工具,使得数据的读取和写入更加轻松。通过合理使用参数,可以满足不同XML结构和数据需求的处理。
处理复杂XML结构
在实际工作中,我们经常会面对复杂的XML结构,其中包含多层嵌套、属性等复杂情形。Pandas的read_xml方法可以通过适当的XPath表达式和命名空间来应对这些情况。
代码示例:
假设有以下XML文件(example_complex.xml):
<root><person><name>Alice</name><age>25</age><address><city>New York</city><state>NY</state></address></person><person><name>Bob</name><age>30</age><address><city>San Francisco</city><state>CA</state></address></person>
</root>
使用read_xml读取:
import pandas as pd# 读取XML文件,指定XPath和命名空间
xml_path_complex = 'example_complex.xml'
df_complex = pd.read_xml(xml_path_complex, xpath='/root/person', namespaces={'ns': None})# 打印DataFrame
print(df_complex)
在这个例子中,通过xpath='/root/person'指定了XPath,将/root/person作为一个记录的路径。同时,由于XML文件没有命名空间,通过namespaces={'ns': None}将命名空间设为None。
自定义数据转换
converters参数可以用于自定义XML元素值的转换,以便更好地适应数据类型的需求。
代码示例:
假设有以下XML文件(example_custom.xml):
<records><record><value>123</value></record><record><value>456</value></record>
</records>
使用read_xml并自定义转换:
import pandas as pd# 自定义转换器函数
def custom_converter(value):return int(value) * 2# 读取XML文件,指定自定义转换器
xml_path_custom = 'example_custom.xml'
df_custom = pd.read_xml(xml_path_custom, converters={'value': custom_converter})# 打印DataFrame
print(df_custom)
在这个例子中,converters={'value': custom_converter}通过自定义转换器函数将value元素的值转换为整数,并乘以2。
通过这些技巧,可以更好地处理复杂的XML数据结构和满足特定的数据类型转换需求。Pandas的read_xml方法提供了强大的灵活性,使得XML数据的读取和处理更为便捷。
处理XML文件中的属性
有时,XML文件中的信息可能包含在元素的属性中。Pandas的read_xml方法可以通过指定XPath表达式和attr参数来读取元素的属性信息。
代码示例:
假设有以下XML文件(example_attributes.xml):
<students><student id="1"><name>Alice</name><age>25</age></student><student id="2"><name>Bob</name><age>30</age></student>
</students>
使用read_xml读取元素属性:
import pandas as pd# 读取XML文件,指定XPath和属性
xml_path_attributes = 'example_attributes.xml'
df_attributes = pd.read_xml(xml_path_attributes, xpath='/students/student', attr=['id'])# 打印DataFrame
print(df_attributes)
在这个例子中,通过xpath='/students/student'指定XPath,将/students/student作为一个记录的路径。同时,通过attr=['id']指定了需要读取的元素属性。
定制XML文件写入
在使用to_xml方法写入XML文件时,可以通过一些参数来定制XML的生成方式,以满足不同的需求。
代码示例:
import pandas as pd# 创建示例DataFrame
data_custom = {'Name': ['Alice', 'Bob'],'Age': [25, 30],'City': ['New York', 'San Francisco']}
df_custom_write = pd.DataFrame(data_custom)# 写入XML文件,定制写入方式
xml_output_path_custom = 'output_custom.xml'
df_custom_write.to_xml(xml_output_path_custom, index=False, mode='a', force_cdata=True)# 打印成功信息
print(f'XML文件已成功写入:{xml_output_path_custom}')
在这个例子中,通过mode='a'将写入模式设置为追加,force_cdata=True强制将文本包装在CDATA块中。
通过这些例子,我们展示了如何处理XML文件中的属性信息以及如何通过参数定制XML文件的写入方式。Pandas的XML处理功能为用户提供了强大的工具,适用于不同类型和结构的XML数据。
处理缺失数据和嵌套结构
在实际数据中,常常会遇到缺失数据和嵌套结构的情况。Pandas的read_xml方法允许我们通过合理的参数设置来处理这些情况。
处理缺失数据
在XML文件中,可能存在某些元素在部分记录中缺失的情况。通过pd.read_xml的errors参数,我们可以控制对于缺失数据的处理方式。
代码示例:
import pandas as pd# 示例XML文件(example_missing.xml)
# <students>
# <student>
# <name>Alice</name>
# <age>25</age>
# </student>
# <student>
# <name>Bob</name>
# </student>
# </students># 读取XML文件,处理缺失数据
xml_path_missing = 'example_missing.xml'
df_missing = pd.read_xml(xml_path_missing, xpath='/students/student', errors='coerce')# 打印DataFrame
print(df_missing)
在这个例子中,通过errors='coerce'参数,将缺失数据替换为NaN。
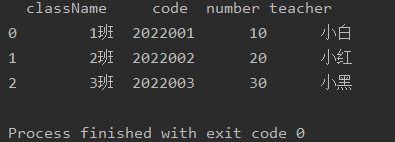
处理嵌套结构
当XML文件中存在嵌套结构时,pd.read_xml方法也能够处理这种情况。通过适当的XPath表达式,我们可以提取嵌套结构中的信息。
代码示例:
import pandas as pd# 示例XML文件(example_nested.xml)
# <students>
# <student>
# <name>Alice</name>
# <info>
# <age>25</age>
# <city>New York</city>
# </info>
# </student>
# <student>
# <name>Bob</name>
# <info>
# <age>30</age>
# <city>San Francisco</city>
# </info>
# </student>
# </students># 读取XML文件,处理嵌套结构
xml_path_nested = 'example_nested.xml'
df_nested = pd.read_xml(xml_path_nested, xpath='/students/student', flatten=True)# 打印DataFrame
print(df_nested)
在这个例子中,通过flatten=True参数,将嵌套结构中的信息平铺在一行中。
通过这些例子,我们演示了如何处理缺失数据和嵌套结构,使得Pandas在处理真实世界的XML数据时更加灵活和适应性强。
处理命名空间和复杂XML结构
在实际的XML文件中,命名空间和复杂的结构是比较常见的情况。Pandas的read_xml方法提供了参数来处理这些复杂情况。
处理命名空间
命名空间在XML中用于避免元素名的冲突。使用pd.read_xml时,需要通过namespaces参数来处理命名空间。
代码示例:
import pandas as pd# 示例XML文件(example_namespace.xml)
# <ns:students xmlns:ns="http://example.com">
# <ns:student>
# <ns:name>Alice</ns:name>
# <ns:age>25</ns:age>
# </ns:student>
# <ns:student>
# <ns:name>Bob</ns:name>
# <ns:age>30</ns:age>
# </ns:student>
# </ns:students># 读取XML文件,处理命名空间
xml_path_namespace = 'example_namespace.xml'
df_namespace = pd.read_xml(xml_path_namespace, xpath='/ns:students/ns:student', namespaces={'ns': 'http://example.com'})# 打印DataFrame
print(df_namespace)
在这个例子中,通过namespaces={'ns': 'http://example.com'}参数,指定了命名空间的前缀和URI。

处理复杂XML结构
对于包含复杂结构的XML文件,我们可以使用适当的XPath表达式来定位所需的数据。
代码示例:
import pandas as pd# 示例XML文件(example_complex_structure.xml)
# <root>
# <person>
# <name>Alice</name>
# <details>
# <age>25</age>
# <address>
# <city>New York</city>
# <state>NY</state>
# </address>
# </details>
# </person>
# <person>
# <name>Bob</name>
# <details>
# <age>30</age>
# <address>
# <city>San Francisco</city>
# <state>CA</state>
# </address>
# </details>
# </person>
# </root># 读取XML文件,处理复杂结构
xml_path_complex_structure = 'example_complex_structure.xml'
df_complex_structure = pd.read_xml(xml_path_complex_structure, xpath='/root/person', namespaces={'ns': None})# 打印DataFrame
print(df_complex_structure)
在这个例子中,通过xpath='/root/person'指定XPath,将/root/person作为一个记录的路径。
通过这些例子,我们展示了如何处理命名空间和复杂的XML结构,使得Pandas在处理各种XML文件时更加灵活和适应性强。
总结
通过本文,我们深入探讨了Pandas库中的read_xml和to_xml方法,以及它们在处理XML文件时的灵活性和强大功能。我们学习了如何读取包含命名空间、属性、缺失数据、嵌套结构等复杂情况的XML文件,并通过详细的代码示例进行了演示。
在读取XML文件时,我们了解了read_xml方法的关键参数,如path、xpath、namespaces、converters等,并展示了如何处理不同类型的XML结构。同时,我们介绍了如何使用to_xml方法将Pandas DataFrame写入XML文件,并演示了一些定制写入的参数,如index、mode、force_cdata等。
在实际应用中,我们经常会遇到复杂的XML文件,包括命名空间、属性、嵌套结构等。Pandas的XML处理功能通过提供灵活的参数和功能,使得我们能够轻松地应对不同情况,处理真实世界中的XML数据变得更加高效。
总体而言,Pandas的read_xml和to_xml方法为处理XML数据提供了便捷而强大的工具,为数据科学家和分析师在处理各种数据源时提供了更多选择和灵活性。希望通过本文的介绍,读者能更加熟练地运用这些方法,从而更好地应对实际工作中的XML数据处理需求。





![[缓存] - 1.缓存共性问题](http://pic.xiahunao.cn/[缓存] - 1.缓存共性问题)


)





——06. 红绿灯仿真(二))




