
今天给大家分享一个加速视觉分割大模型的工作:EfficientViT-SAM。这是一种新的加速SAM系列。保留了SAM的轻量级提示编码器和mask解码器,同时用EfficientViT替换了沉重的图像编码器。对于训练,首先从SAM-ViT-H图像编码器到EfficientViT的知识蒸馏开始。随后在SA-1B数据集上进行端到端训练。由于EfficientViT的效率和容量,EfficientViT-SAM在A100 GPU上的TensorRT加速比SAM-ViT-H高出48.9倍,而且不会牺牲性能。

开源地址:https://github.com/mit-han-lab/efficientvit
文章链接:https://arxiv.org/pdf/2402.05008
介绍
SAM是一系列在高质量数据集上预训练的图像分割模型,该数据集包含1100万张图像和10亿个mask。SAM提供了令人惊叹的zero-shot图像分割性能,并且具有许多应用,包括AR/VR、数据标注、交互式图像编辑等。 尽管性能强大,但SAM的计算密集性很高,限制了其在时间敏感场景中的适用性。特别是,SAM的主要计算瓶颈是其图像编码器,在推理时每个图像需要2973 GMACs。
为了加速SAM,已经进行了大量努力,将SAM的图像编码器替换为轻量级模型。例如,MobileSAM 将SAM的ViT-H模型的知识蒸馏成一个微型视觉Transformer。EdgeSAM 训练了一个纯CNN模型来模仿ViT-H,采用了一个精心的蒸馏策略,其中包括提示编码器和mask解码器参与过程。EfficientSAM 利用MAE预训练方法来提高性能。
虽然这些方法可以降低计算成本,但它们都在性能上存在显著下降(上图1)。本文介绍了EfficientViT-SAM来解决这个限制,通过利用EfficientViT 来替换SAM的图像编码器。同时保留了SAM的轻量级提示编码器和mask解码器架构。训练过程分为两个阶段。首先,使用SAM的图像编码器作为老师,训练EfficientViT-SAM的图像编码器。其次,使用整个SA-1B数据集对EfficientViT-SAM进行端到端训练。
在一系列zero-shot基准测试上对EfficientViT-SAM进行了彻底评估。EfficientViT-SAM在所有先前的SAM模型上都提供了显著的性能/效率提升。特别是,在COCO数据集上,与SAM-ViT-H相比,EfficientViT-SAM在A100 GPU上实现了48.9倍的吞吐量提高,而mAP没有下降。
相关工作
SAM
SAM 在计算机视觉领域获得了广泛认可,展示了其在图像分割中的卓越性能和泛化能力。SAM将图像分割定义为一个可提示的任务,旨在给定任何分割提示生成有效的分割mask。为实现此目标,SAM利用图像编码器和提示编码器处理图像并提供提示。两个编码器的输出然后输入到mask解码器中,生成最终的mask预测。SAM在一个包含超过1100万张图像和超过10亿个高质量mask的大规模分割数据集上进行训练,实现了稳健的zero-shot开放世界分割。SAM在各种下游应用中显示了其高度的多功能性,包括图像修补 、目标跟踪和3D生成。然而,SAM的图像编码器组件会带来显著的计算成本,导致高延迟,限制了其在时间敏感场景中的实用性。近期的工作 [2–4, 14] 集中于改善SAM的效率,旨在解决其计算限制问题。
高效深度学习计算
当在边缘和云平台上部署深度神经网络时,提高其效率至关重要。我们的工作与高效模型架构设计相关,旨在通过将低效的模型架构替换为高效的模型架构来改善性能和效率之间的平衡。我们的工作还与知识蒸馏相关,该方法使用预训练的教师模型来指导学生模型的训练。此外,可以将EfficientViT-SAM与其他并行技术结合使用,进一步提高效率,包括剪枝、量化和硬件感知神经架构搜索。
方法
EfficientViT-SAM,利用EfficientViT 加速SAM。具体来说,我们的方法保留了SAM的提示编码器和mask解码器架构,同时将图像编码器替换为EfficientViT。设计了两个系列的模型,EfficientViT-SAM-L 和 EfficientViT-SAM-XL,提供了速度和性能之间的平衡。随后,使用SA-1B数据集对EfficientViT-SAM进行端到端训练。
EfficientViT
EfficientViT是一系列用于高效高分辨率密集预测的视觉Transformer模型。其核心构建模块是多尺度线性注意力模块,可以通过硬件高效的操作实现全局感受野和多尺度学习。具体来说,它用轻量级的ReLU线性注意力替换了低效的softmax注意力,从而实现了全局感受野。通过利用矩阵乘法的关联属性,ReLU线性注意力可以将计算复杂度从二次降低到线性,同时保持功能性。此外,它通过卷积增强了ReLU线性注意力,以减轻其在局部特征提取方面的局限性。
EfficientViT-SAM
模型架构。 EfficientViT-SAM-XL 的宏观架构如下图2所示。其骨干网络由五个阶段组成。与EfficientViT类似,在前几个阶段使用卷积块,而在最后两个阶段使用EfficientViT模块。通过上采样和加法融合来融合最后三个阶段的特征。融合的特征被输入到由多个融合MBConv块组成的neck中,然后传递到SAM头部。

训练。 为了初始化图像编码器,首先将SAM-ViT-H的图像嵌入蒸馏到EfficientViT中。采用L2损失作为损失函数。对于提示编码器和mask解码器,通过加载SAM-ViT-H的权重来初始化它们。然后,以端到端的方式在SA-1B数据集上对EfficientViT-SAM进行训练。
在端到端训练阶段,以相等的概率随机选择box状提示和点状提示之间。对于点状提示,从mask真值中随机选择1-10个前景点,以确保我们的模型对各种点配置的执行效果良好。对于box状提示,利用真值边界框。将最长边缩放到512/1024用于EfficientViT-SAM-L/XL模型,并相应地填充较短的边。每张图像最多选择64个随机采样的mask。为了监督训练过程,使用焦点损失和Dice损失的线性组合,焦点损失与Dice损失的比例为20:1。与SAM中采用的方法相似,为了减少歧义,同时预测三个mask,并仅反向传播最低损失。还通过添加第四个输出token来支持单个mask输出。在训练过程中,我们随机交替两种预测模式。
在SA-1B数据集上对EfficientViT-SAM进行了2个epoch的训练,使用批量大小为256。采用AdamW优化器,动量为β1 = 0.9和β2 = 0.999。初始学习率设置为2e−6/1e−6,针对EfficientViT-SAM-L/XL,通过余弦衰减学习率调度衰减到0。关于数据增强,使用随机水平翻转。
实验
在本节中,首先在第1节对EfficientViT-SAM的运行时效率进行了全面分析。随后,评估了EfficientViT-SAM在COCO和LVIS数据集上的zero-shot能力,这些数据集在训练过程中未遇到。执行了两个不同的任务:下一个节中的单点有效mask评估和再下一节中的box状提示实例分割。这些任务分别评估了EfficientViT-SAM的点状提示和盒状提示特性的有效性。我们还供了SGinW基准测试的结果。
运行时效率
我们比较了EfficientViT-SAM与SAM和其他加速工作的模型参数、MACs和吞吐量。结果如下表1所示。在单个NVIDIA A100 GPU上进行了TensorRT优化的吞吐量测量。结果显示,与SAM相比,我们实现了令人印象深刻的加速,速度提升了17到69倍。此外,尽管EfficientViT-SAM的参数比其他加速工作多,但由于其有效利用硬件友好的操作符,它表现出了显着更高的吞吐量。

zero-shot点提示分割
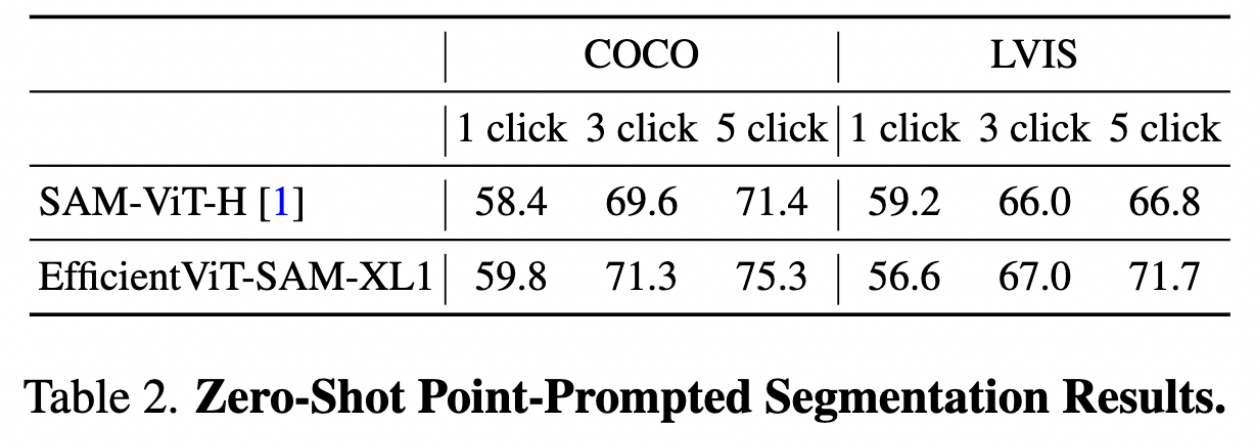
我们评估了EfficientViT-SAM根据点提示分割对象的zero-shot性能,结果如下表2所示。我们采用了[1]中描述的点选择方法。即初始点被选择为距离对象边界最远的点。每个后续点被选择为距离误差区域边界最远的点,误差区域被定义为真值和先前预测之间的区域。使用COCO和LVIS数据集上的1/3/5次点击进行性能报告,mIoU作为指标。结果表明,与SAM相比,我们在提供额外点提示时表现出了更优异的性能。
zero-shot框提示分割
我们评估了EfficientViT-SAM在使用边界框进行对象分割时的zero-shot性能。首先将真值边界框输入到模型中,并将结果呈现在下表4中。报告了所有对象的mIoU,以及分别为小、中、大对象。我们的方法在COCO和LVIS数据集上都明显优于SAM。

接下来,我们使用一个目标检测器ViT-Det,并利用其输出框作为模型的提示。下表5中的结果表明,EfficientViT-SAM相比SAM实现了更优异的性能。值得注意的是,即使是EfficientViT-SAM的最轻版本也明显优于其他加速工作的性能。

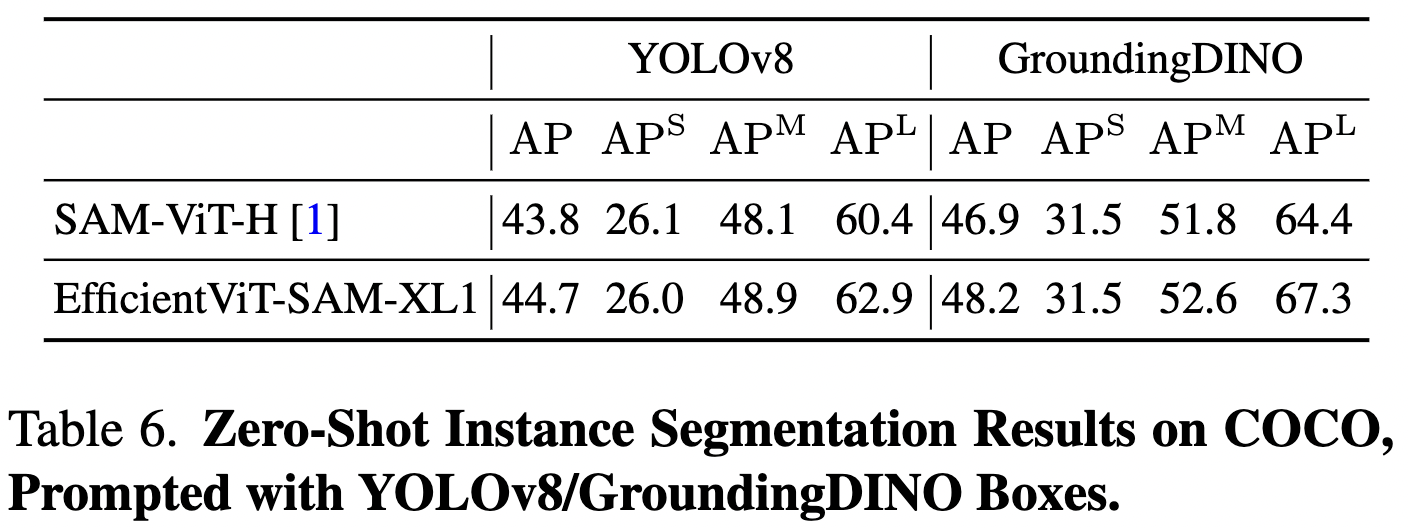
此外,使用YOLOv8和GroundingDINO作为目标检测器,在COCO数据集上评估了EfficientViT-SAM的性能。YOLOv8是一个适用于实际应用的实时目标检测器。另一方面,GroundingDINO能够使用文本提示检测目标,使能够根据文本线索进行对象分割。下表6中呈现的结果显示了EfficientViT-SAM相对于SAM的出色性能。
zero-shot自然环境分割
自然环境分割基准包括25个zero-shot自然环境分割数据集。我们将Grounding-DINO作为框提示,为EfficientViT-SAM提供了zero-shot分割。每个数据集的全面性能结果见下表3。SAM的mAP为48.7,而EfficientViT-SAM的得分更高,为48.9。

定性结果
下图3展示了EfficientViT-SAM在提供点提示、框提示和全分割模式下的定性分割结果。结果表明,EfficientViT-SAM不仅在分割大目标方面表现出色,而且在有效处理小目标方面也表现出色。这些发现突显了EfficientViT-SAM出色的分割能力。


结论
EfficientViT-SAM利用EfficientViT替换了SAM的图像编码器。EfficientViT-SAM在各种zero-shot分割任务中实现了显著的效率提升,而不会牺牲性能。已将预训练模型开放源代码发布在GitHub上。
参考文献
[1] EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss
更多精彩内容,请关注公众号:AI生成未来







对话系统)


的设置)
前端实现主题切换、动态换肤的两种简单方式)








