https://www.bilibili.com/video/BV1UG411p7zv?p=118


Delta Tuning,尤其是在自然语言处理(NLP)和机器学习领域中,通常指的是对预训练模型进行微调的一种策略。这种策略不是直接更新整个预训练模型的权重,而是仅针对模型的一部分权重进行微小的调整,这部分权重通常被称为“delta权重”或“微调参数”。
具体到NLP任务中,Delta Tuning可以应用于:
-
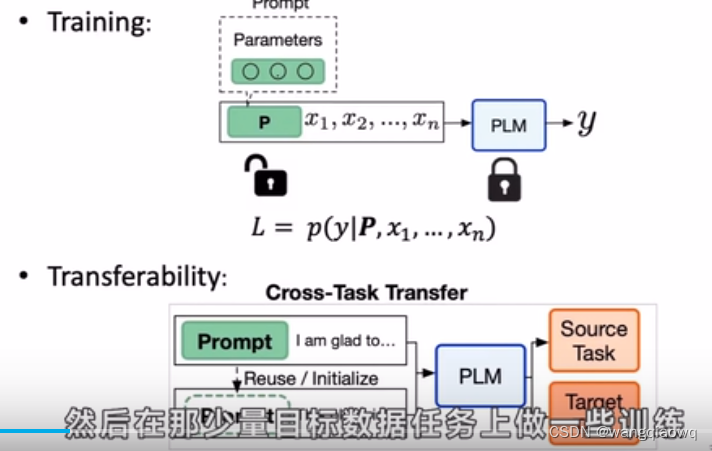
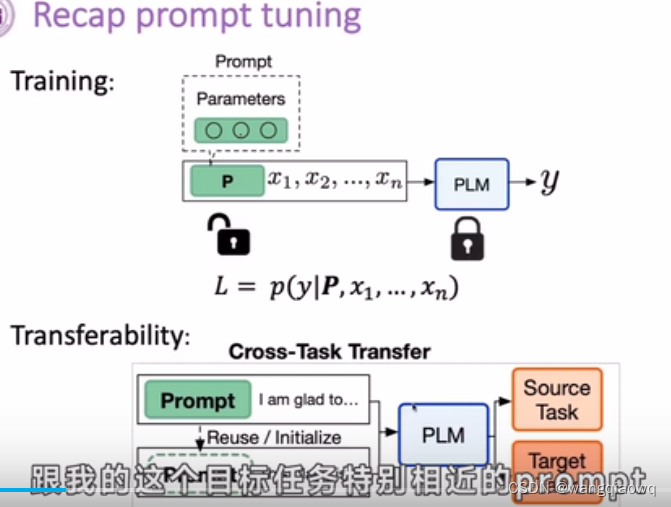
Soft Prompt Tuning:在基于Transformer的预训练模型中,通过添加一组可学习的连续向量(软提示)来适应特定任务,而不仅仅是调整原始模型的所有参数。
-
Adapter-based Fine-Tuning:在预训练模型的每一层插入小型模块(适配器),仅对这些适配器进行训练以适应新任务,而不改变模型原来的主体结构和大部分权重。
-
Parameter-efficient Fine-Tuning:在有限资源条件下,只对一小部分关键参数进行优化,以实现高效且节省资源的模型微调。
Delta Tuning的主要优势在于能够更好地保留预训练模型学到的通用知识,并减少过拟合的风险以及计算资源的需求。



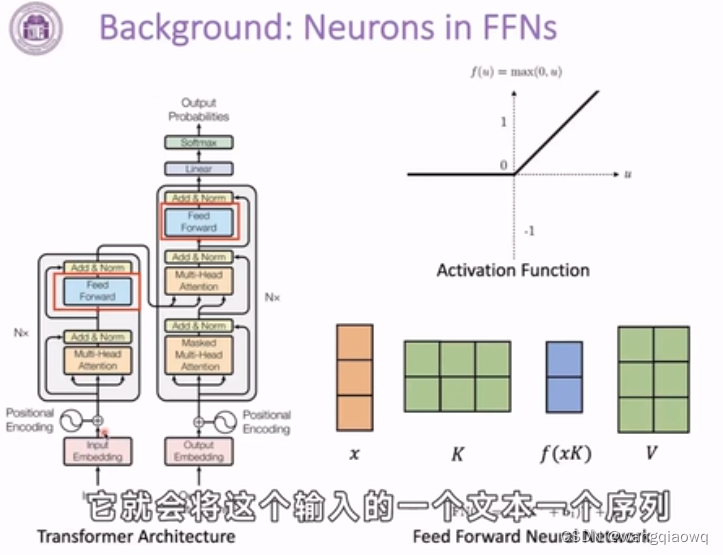


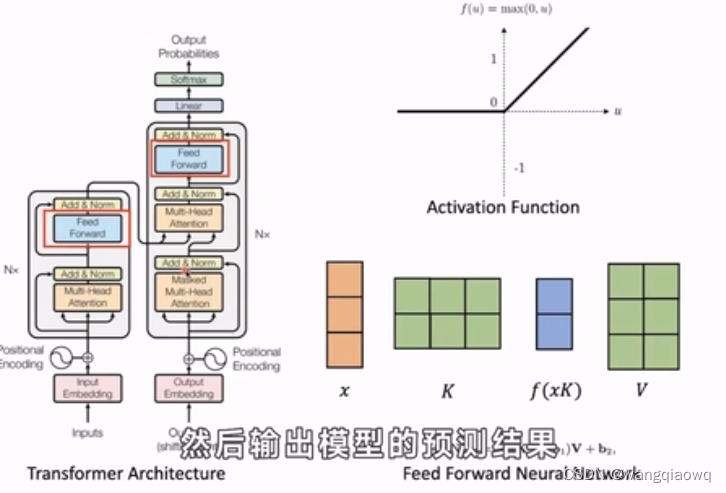
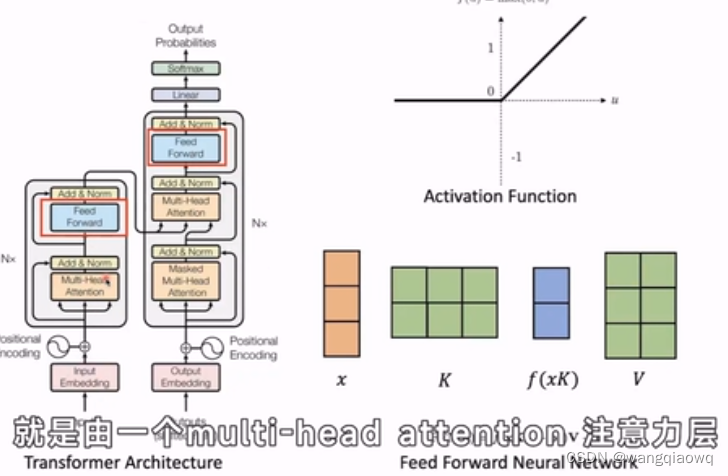

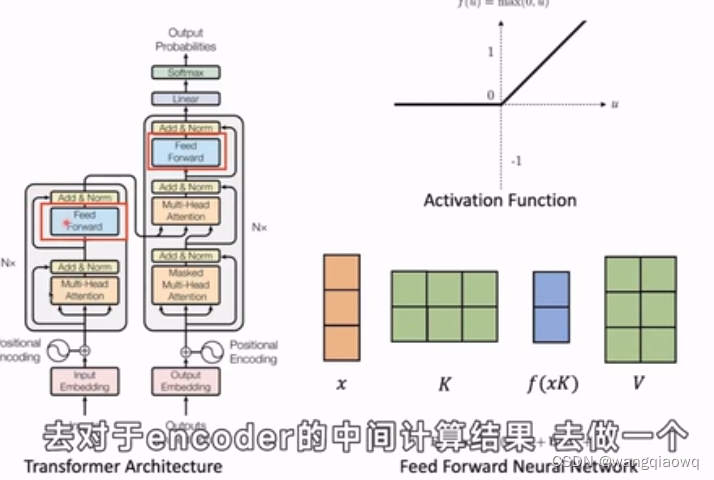
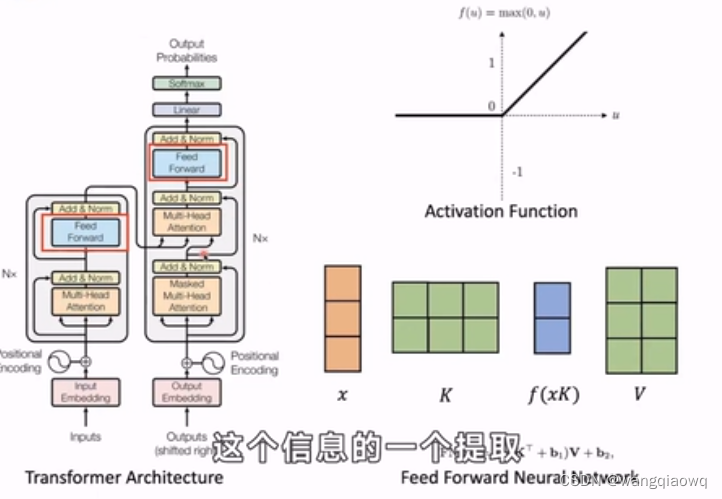
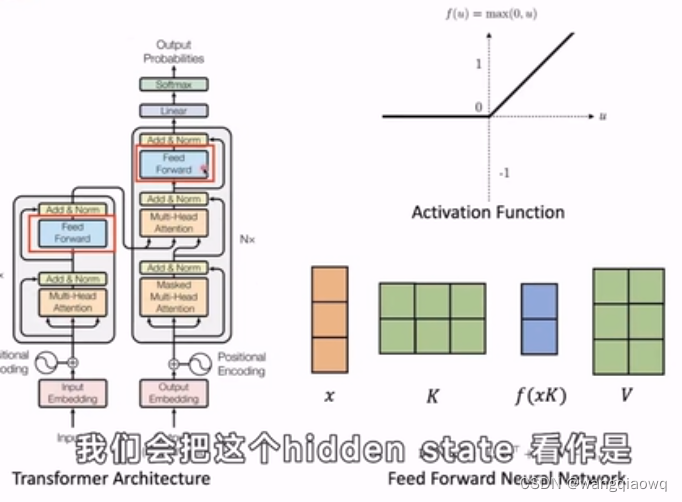
在自然语言处理(NLP)和深度学习中,"hidden state"(隐藏状态)通常是指循环神经网络(RNNs)或者Transformer等模型中,在计算过程中产生的内部表示。这些隐藏状态用来捕捉输入序列中的历史信息和上下文依赖。
对于循环神经网络(如LSTM、GRU等):
- 隐藏状态是时间步之间传递的关键信息载体。在每个时间步,RNN都会根据当前输入和上一时间步的隐藏状态计算出一个新的隐藏状态。这个新的隐藏状态不仅包含了当前时刻的信息,还累积了到目前为止整个序列的历史信息。
对于Transformer模型:
- 虽然Transformer不是递归结构,但它也有类似的概念——“隐状态”体现在自注意力机制下各层的输出中,每一层的隐状态可以看作是对输入序列的多层次、多角度的理解或表征。
在不同的上下文中,隐藏状态能够捕获文本序列中的不同模式和特征,并被用于下游任务如分类、生成、翻译等。


MLP 是“Multilayer Perceptron”的缩写,中文通常翻译为多层感知器或多层神经网络。它是一种前馈神经网络(Feedforward Neural Network),由多个相互连接的神经元层组成,每一层都包含若干个节点(或称神经元)。在 MLP 中,信息从输入层经过一系列隐藏层处理后,在输出层产生最终结果。
MLP 的基本结构包括:
- 输入层:接收原始特征数据,并将其转换成向量形式。
- 隐藏层:每个隐藏层中的神经元都会对上一层的输出进行非线性变换,这个过程通常涉及加权求和以及一个激活函数(如ReLU、sigmoid、tanh等)的应用,用于引入模型的非线性表达能力。
- 输出层:最后一层提供网络的预测结果,其节点数量取决于任务类型,例如对于分类问题,节点数对应类别数目,且常常会使用softmax函数来归一化输出概率。
MLPs 通过反向传播算法训练权重参数,以最小化预测输出与实际目标之间的差异(即损失函数)。它们广泛应用于各种机器学习任务,包括分类、回归分析及函数逼近等。


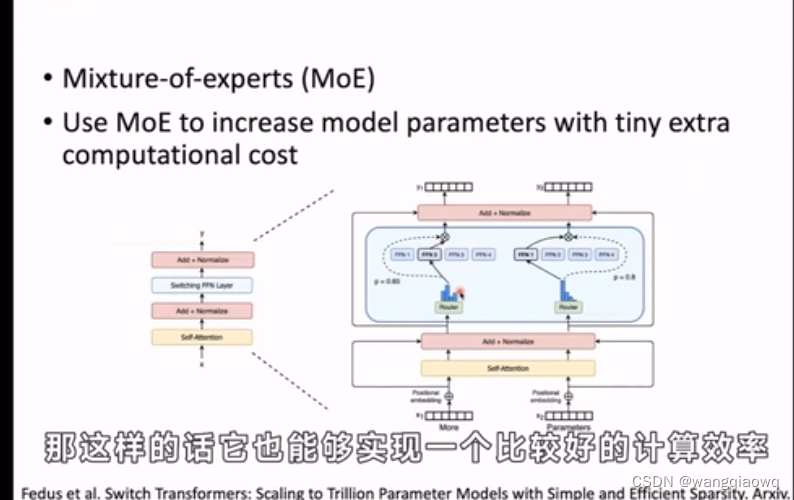
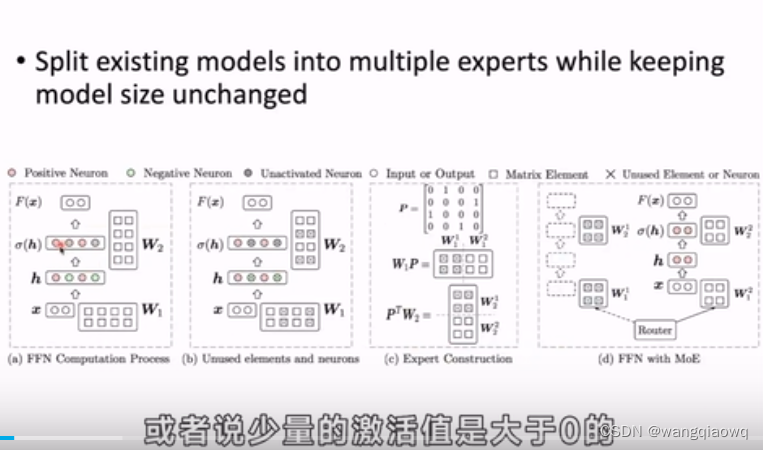

在自然语言处理(NLP)中,"embedding"(嵌入或词嵌入)是一种将词汇表征为连续向量的技术。这种技术旨在将离散的、高维的词汇转换成低维且稠密的向量形式,以便于计算机理解和处理。
具体来说:
-
词嵌入:每个单词都被映射到一个固定维度的向量空间中的一个点,使得语义相似的词在该空间中的距离较近,而不相关的词则相对较远。例如,通过训练如Word2Vec、GloVe或FastText等模型可以得到词嵌入。
-
句子/文档嵌入:除了单词级别的嵌入外,还可以生成整个句子或文档的向量表示,这些通常是基于单词嵌入并通过加权平均、池化操作或者更复杂的深度学习结构(如Transformer)来计算得出。
词嵌入的主要优势在于它们能够捕捉词汇之间的语义和语法关系,从而极大地提升了NLP任务的性能,比如文本分类、情感分析、问答系统、机器翻译等等。




在自然语言处理(NLP)的神经网络模型中,激活函数(activation function)是应用于每个神经元上的非线性转换函数。这个函数的作用是引入非线性特性到模型中,这对于解决复杂问题如文本分类、语义分析、机器翻译等至关重要,因为自然语言本身具有高度的非线性特征。
在一个典型的人工神经元结构中,在计算了输入信号与权重的加权和之后(这可以看作是模拟生物神经元的多个突触接收到信号后的整合),会将该加权和通过一个激活函数来得到神经元的输出值。这个输出值随后被作为下一层神经元的输入。
常见的激活函数包括:
- Sigmoid:输出介于0和1之间,常用于二元分类问题的最后一层,但其饱和性会导致梯度消失问题。
- ReLU (Rectified Linear Unit):输出大于0时为线性,小于等于0时为0,广泛应用于隐藏层,缓解了梯度消失的问题。
- Tanh (双曲正切函数):输出范围在-1至1之间,相比Sigmoid有更均匀的梯度分布,因此在某些深度学习架构中更为常用。
- GELU (Gaussian Error Linear Units):近似实现,尤其在Transformer等现代NLP模型中表现良好,因为它能够保持较好的线性区间的梯度同时引入非线性。
这些激活函数的选择取决于特定任务的需求和模型设计的考量,旨在优化模型的学习能力和泛化性能。
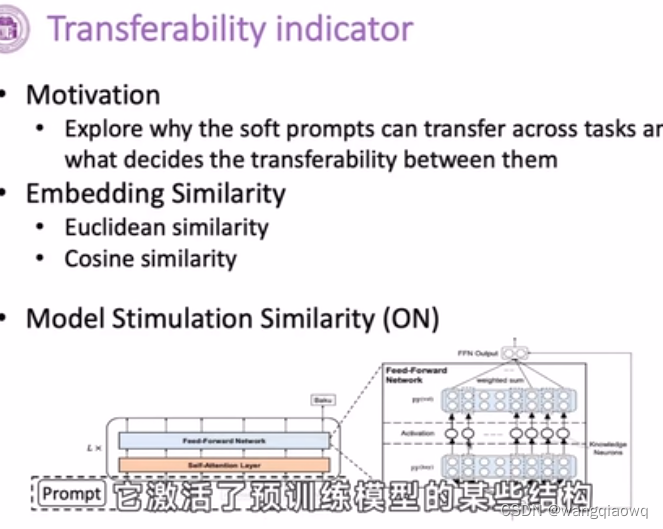
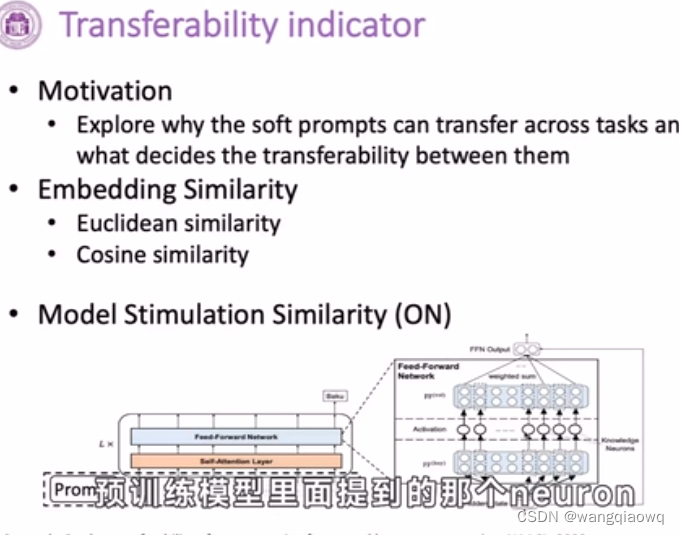
在自然语言处理(NLP)中,"neuron" 通常指的是神经网络模型中的一个计算单元。在深度学习的背景下,神经元是对生物神经元的一种抽象模拟,其基本工作原理如下:
-
输入层:在NLP任务中,每个神经元接收来自上一层或原始输入数据的信号,对于文本数据而言,这些信号可能代表词嵌入、字符特征或其他预处理后的特征。
-
加权和:神经元将接收到的所有信号与对应的权重相乘后求和。例如,在NLP任务中,词嵌入经过矩阵乘法(权重矩阵W)得到一个加权和。
-
激活函数:对上述加权和应用非线性激活函数(如ReLU、Sigmoid、Tanh等),生成该神经元的输出值。激活函数引入了模型的非线性特性,使其能够学习并捕获复杂的数据关系。
-
传播:神经元的输出随后作为下一层神经元的输入,这一过程不断迭代直至到达输出层,最终用于预测任务目标,如分类标签、情感得分、翻译结果等。
在NLP的各种深度学习模型中,如循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)以及Transformer等,神经元是构成整个模型的基础单元,通过大量神经元的堆叠和连接,模型得以理解和处理复杂的自然语言信息。





)
潜力)

![[office] Excel2019函数MAXIFS怎么使用?Excel2019函数MAXIFS使用教程 #知识分享#微信#经验分享](http://pic.xiahunao.cn/[office] Excel2019函数MAXIFS怎么使用?Excel2019函数MAXIFS使用教程 #知识分享#微信#经验分享)


)





)






