提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 1. ClickHouse 简介
- 1.1 大数据处理场景
- 1.2 什么是 ClickHouse
- 1.3 OLAP 场景的特征
- 2. ClickHouse 特性
- 2.1 完备的 DBMS 功能
- 2.2 列式存储
- 行式存储: 在数据==写入==和==修改==上具有优势
- 列式存储: 在数据==读取和解析==、==分析数据==上具有优势
- 列式储存的好处:
- 2.3 数据压缩
- 2.4 向量化执行引擎
- 2.5 关系模型与标准 SQL 查询
- ClickHouse 是==大小写敏感==,SELECT a 和 SELECT A 所代表的语义不同
- 2.6 多样化的表引擎
- 2.7 多线程与分布式
- 2.8 多主架构
- 2.9 交互式查询
- 2.10 数据分片与分布式查询
1. ClickHouse 简介
1.1 大数据处理场景
在大数据处理场景中,流处理和批处理使用到的技术大致如下:
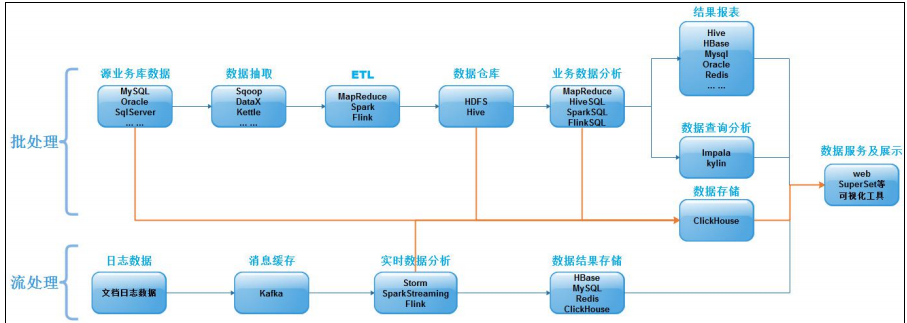



1.2 什么是 ClickHouse
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C++语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告
- ClickHouse 是一个开源的,用于联机分析(OLAP)的列式数据库管理系统(DBMS-database manager system), 它是面向列的,并允许使用 SQL 查询,实时生成分析报告。ClickHouse 最初是一款名Yandex.Metrica 的产品,主要用于 WEB流量分析。ClickHouse 的全称是 Click Stream,Data WareHouse,简称 ClickHouse。
- ClickHouse 不是一个单一的数据库,它允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器。ClickHouse 同时支持列式存储和数据压缩,这是对于一款高性能数据库来说是必不可少的特性。
一个非常流行的观点认为,如果你想让查询变得更快,最简单且有效的方法是减少数据扫描范围和数据传输时的大小,而列式存储和数据压缩就可以帮助我们实现上述两点,列式存储和数据压缩通常是伴生的,因为一般来说列式存储是数据压缩的前提
1.3 OLAP 场景的特征
绝大多数是读请求。
数据以相当大的批次(> 1000 行)更新,而不是单行更新;或者根本没有更新。
已添加到数据库的数据不能修改。
对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
宽表,即每个表包含着大量的列。
查询相对较少(通常每台服务器每秒查询数百次或更少)。
对于简单查询,允许延迟大约 50 毫秒。
列中的数据相对较小:数字和短字符串(例如,每个 URL 60 个字节)。
处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)。
事务不是必须的。
对数据一致性要求低。有副本情况下,写入一个即可,后台自动同步。
每个查询有一个大表。除了他以外,其他的都很小。
查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务
器的 RAM 中。
通过以上 OLAP 场景分析特点很容易可以看出,OLAP 场景与其他通常业务场景(例如,OLTP 或 K/V)有很大的不同, 因此想要使用 OLTP 或 Key-Value 数据库去高效的处理分析查询场景,并不是非常完美的适用方案。例如,使用 OLAP 数据库去处理分析请求通常要优于使用 MongoDB 或 Redis 去处理分析请求。
2. ClickHouse 特性
2.1 完备的 DBMS 功能
- ClickHouse 是一个数据库管理系统,而不仅是一个数据库,作为数据库管理系统具备完备的管理功能:

2.2 列式存储
目 前 大 数 据 存 储 有 两 种 方 案 可 以 选 择 , 行 式 存 储 (Row-Based) 和 列 式 存 储(Column-Based)
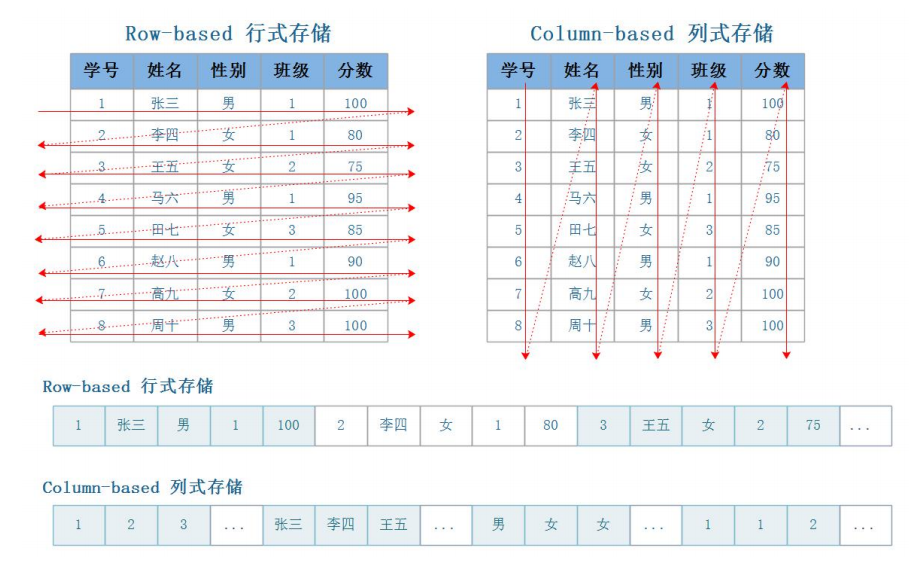
行式存储: 在数据写入和修改上具有优势

列式存储: 在数据读取和解析、分析数据上具有优势


案例
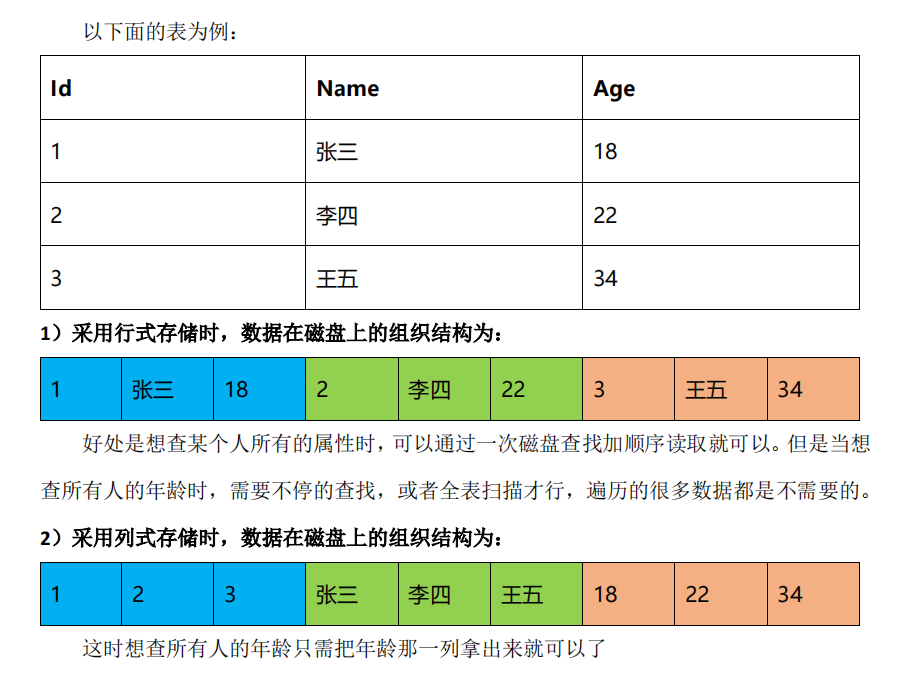
列式储存的好处:
- 对于列的聚合,计数,求和等统计操作原因优于行式存储。
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
- 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于 cache 也有了更大的 发挥空间。
2.3 数据压缩

2.4 向量化执行引擎



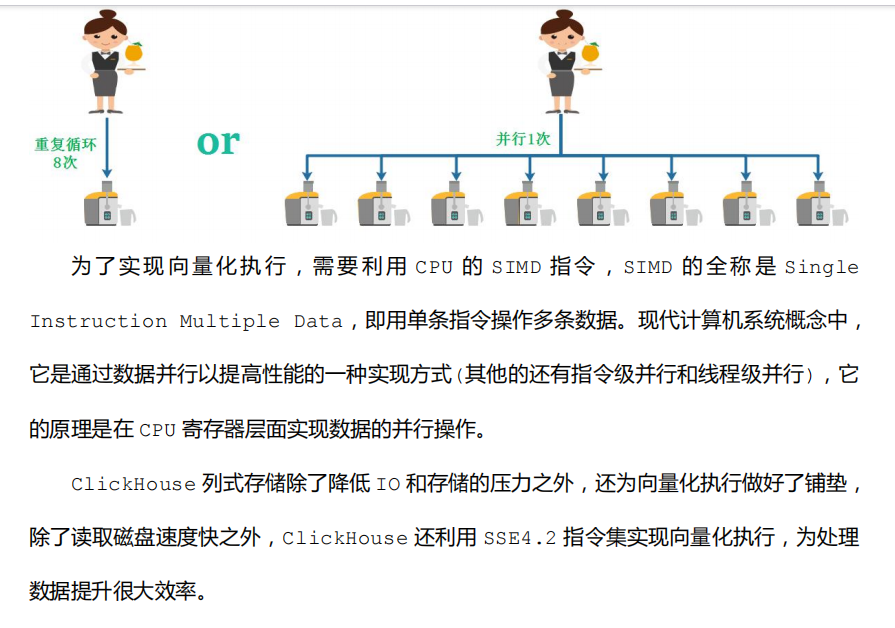
2.5 关系模型与标准 SQL 查询

ClickHouse 是大小写敏感,SELECT a 和 SELECT A 所代表的语义不同
2.6 多样化的表引擎

2.7 多线程与分布式

2.8 多主架构

2.9 交互式查询

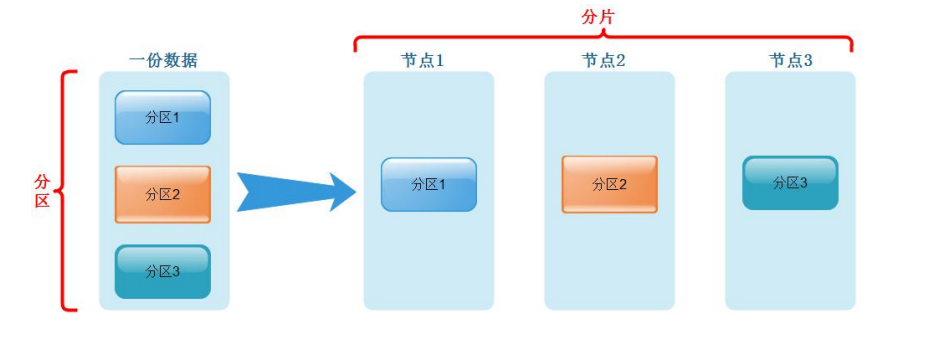
2.10 数据分片与分布式查询

)
——哈希算法)







)



 方法)
)




汉明距离)