众所周知在分布式系统中CAP,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三个指标不可兼得,只能在三个指标中选择两个。假如此时已经实现了一套AP型的分布式系统,并在此基础上实现了最终一致性。如果想要将最终一致性改为强一致性,因为已经实现的是一套AP型分布式系统,想要引入强一致性,要么改变CAP选型(改造成本巨大),要么引入Quorum NWR算法。
通过调配Quorum NWR算法中N、W和R三者之间关系可以自定义一致性级别,如当W + R > N时,就可以实现强一致性。
Quorum NWR三要素
Quorum NWR算法中其名后跟的NWR就是其算法的三要素,N表示副本数、W表示写一致性级别、R表示读一致性级别。N、W、R值的不同组合,会产生不同的一致性:
- W + R > N,分布式系统保证强一致性,一定能返回更新后的数据。
- W + R <= N,分布式系统保证最终一致性,可能会返回旧数据。
其三者的关系可以总结为:N(副本数)是一切的源头,有了它才能进行后续的操作;W(写一致性级别)保证更新数据的
N(副本数)
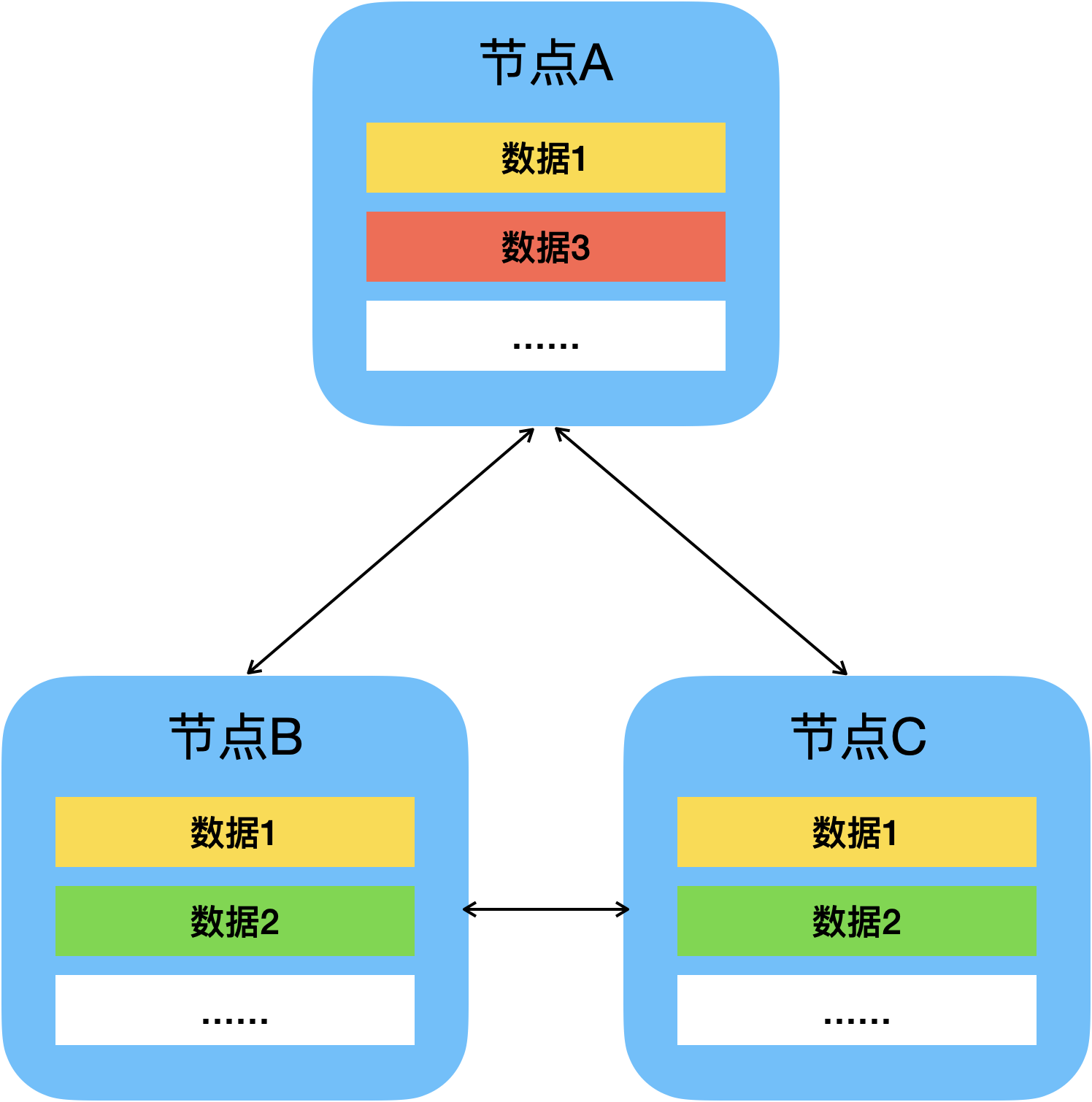
N可叫做复制因子(Replication Factor),表示同一份数据在分布式系统中的副本数。数据的副本数可以不等于节点数,且不同的数据可以有不同的副本数。
如下图所示,数据1分别在节点A、节点B和节点C一共拥有三个副本,数据2在节点B和节点C共拥有两个副本,数据3就只在节点A中拥有一个副本。
W(写一致性级别)
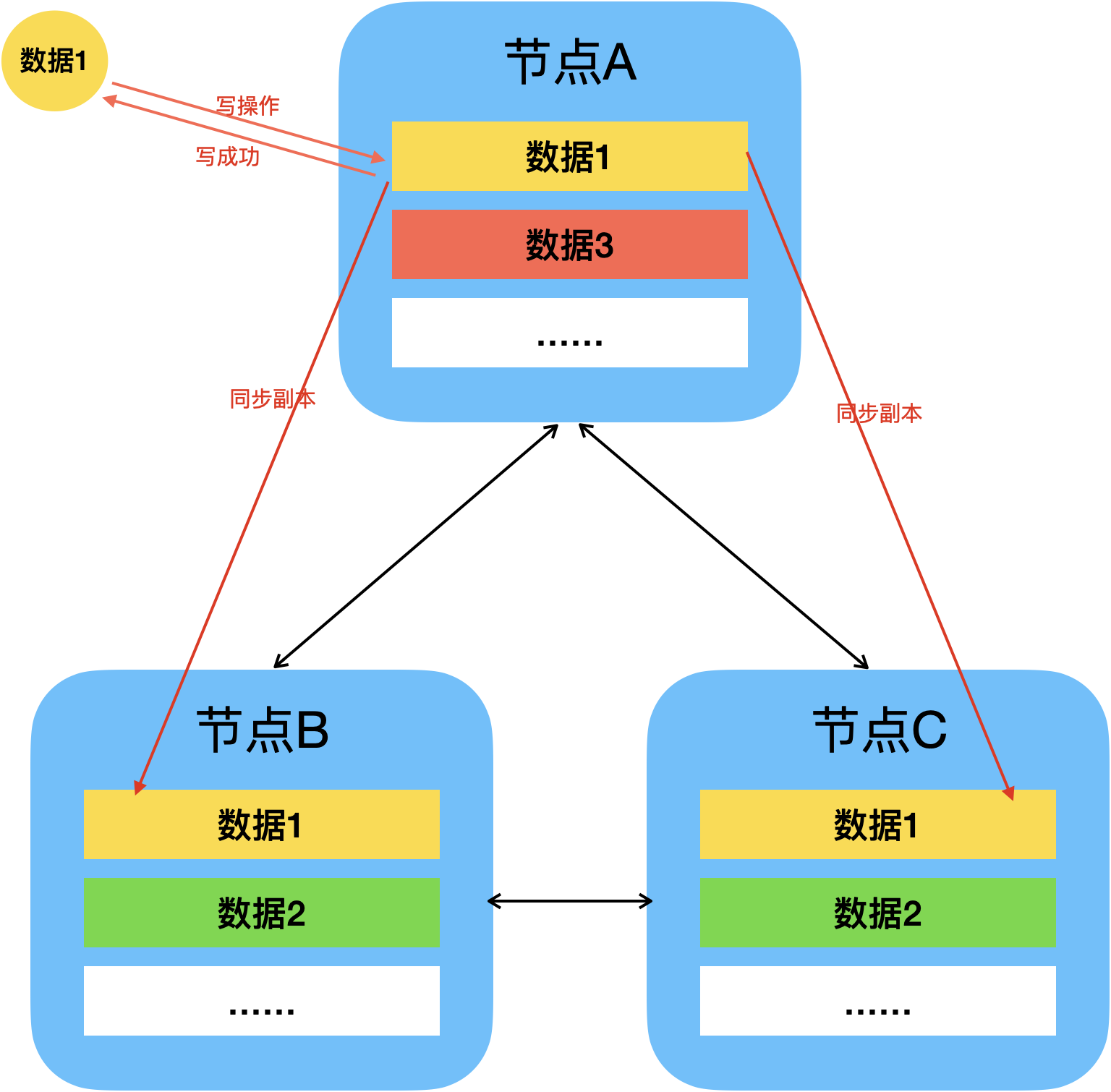
W可叫做写一致性级别(Write Consistency Level),表示一份数据在分布式集群中成功更新了多少个副本才算本次写操作成功。
假如数据1的W=3,那么数据1只有成功更新三个节点的副本才算数据1写操作成功。
R(读一致性级别)
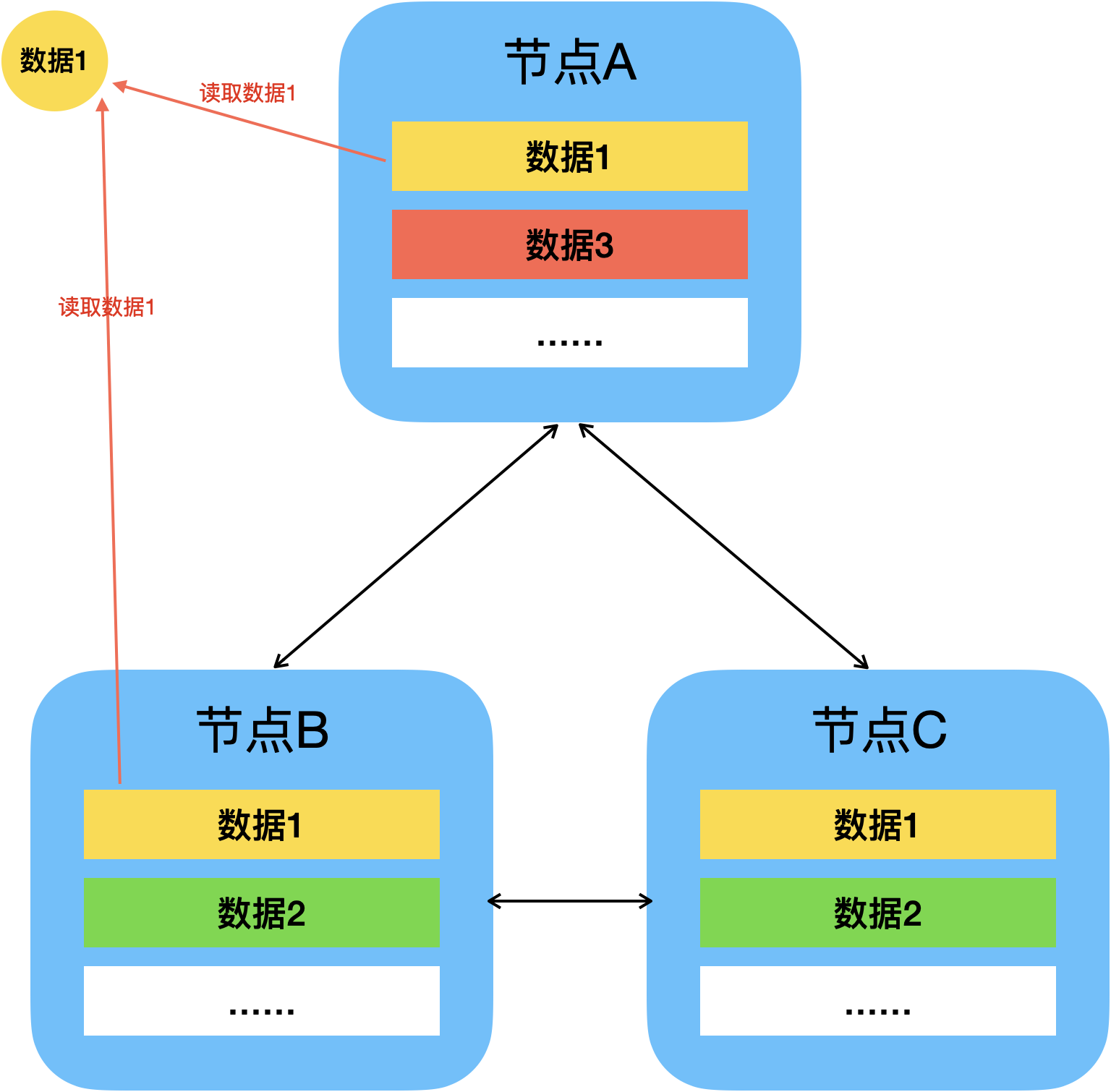
R可叫做读一致性级别(Read Consistency Level),表示读取一个数据需要读的副本数。即读取一个数据,首先从分布式集群中读R个副本出来,然后取这R个副本中最新的那份数据。
假如数据1的R=2,那么读取数据1时必须要从分布式集群中读取两个副本的数据,然后取其二者较新的那一份数据。
小结
综上Quorum NWR是非常实用的一个算法,能弥补AP型分布式系统缺乏强一致性的问题,进而提供自定义一致性级别的能力。在实际使用过程中有两点建议:
- 不推荐副本数超过当前分布式集群中的节点数,因为当副本数据超过节点数时,就会出现同一个节点存在多个副本的情况。如果这个节点发生故障,就会有多个副本受到影响。
- W + R > N可以实现强一致性,在设置 N、W、R值时,如果设置 W = N读性能比较好;如果设置 R = N写性能比较好;如果设置 W = (N + 1) / 2、R = (N + 1) / 2,容错能力比较好,能容忍(N - 1) / 2个节点发生故障。

)






)

vector常用接口详解)

![P2036 [COCI2008-2009 #2] PERKET题解](http://pic.xiahunao.cn/P2036 [COCI2008-2009 #2] PERKET题解)






