为什么要用消息队列
- 解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
- 缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
- 灵活性与峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
- 异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
为什么选择了kafka
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒。
- 可扩展性:kafka集群支持热扩展。
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
- 容错性:允许集群中节点故障(若副本数量为n,则允许n-1个节点故障)。
- 高并发:支持数千个客户端同时读写。
kafka的组件与作用(架构)

- Producer :消息生产者,就是向kafka broker发消息的客户端。
- Consumer :消息消费者,向kafka broker取消息的客户端。
- Consumer Group (CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
- Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic。
- Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
- leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
- follower:每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的follower。
kafka为什么要分区
- 方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了。
- 可以提高并发,因为可以以Partition为单位读写。
Kafka生产者分区策略
- 指明 partition 的情况下,直接将指明的值直接作为partiton值。
- 没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值。
- 既没有partition值又没有key值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到partition值,也就是常说的round-robin算法。
kafka的数据可靠性怎么保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。所以引出ack机制。
ack应答机制(可问:造成数据重复和丢失的相关问题)
Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
acks参数配置:
- 0:producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据。
- 1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据。

- -1(all):producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复。

副本数据同步策略
| 方案 | 优点 | 缺点 |
| 半数以上完成同步,就发送ack | 延迟低 | 选举新的leader时,容忍n台节点的故障,需要2n+1个副本 |
| 全部完成同步,才发送ack | 延迟高 |
选择最后一个的原因:
- 同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
- 虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
ISR
如果采用全部完成同步,才发送ack的副本的同步策略的话:
提出问题:leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
Controller维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,follower就会给leader发送成功应答。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
故障处理(LEO与HW)

LEO:指的是每个副本最大的offset。
HW:指的是消费者能见到的最大的offset,ISR队列中最小的LEO。
follower故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
leader故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
kafka的副本机制
参考上一个问题(副本数据同步策略)。
kafka的消费分区分配策略
一个consumer group中有多个consumer,一个topic有多个partition,所以必然会涉及到partition的分配问题,即确定那个partition由哪个consumer来消费 Kafka有三种分配策略,一是RoundRobin,一是Range。高版本还有一个StickyAssignor策略 将分区的所有权从一个消费者移到另一个消费者称为重新平衡(rebalance)。当以下事件发生时,Kafka 将会进行一次分区分配:
同一个 Consumer Group 内新增消费者。
消费者离开当前所属的Consumer Group,包括shuts down或crashes。
Range分区分配策略
Range是对每个Topic而言的(即一个Topic一个Topic分),首先对同一个Topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。然后用Partitions分区的个数除以消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。假设n=分区数/消费者数量,m=分区数%消费者数量,那么前m个消费者每个分配n+1个分区,后面的(消费者数量-m)个消费者每个分配n个分区。假如有10个分区,3个消费者线程,把分区按照序号排列
0,1,2,3,4,5,6,7,8,9
消费者线程为
C1-0,C2-0,C2-1
那么用partition数除以消费者线程的总数来决定每个消费者线程消费几个partition,如果除不尽,前面几个消费者将会多消费一个分区。在我们的例子里面,我们有10个分区,3个消费者线程,10/3 = 3,而且除不尽,那么消费者线程C1-0将会多消费一个分区,所以最后分区分配的结果看起来是这样的:
C1-0:0,1,2,3
C2-0:4,5,6
C2-1:7,8,9
如果有11个分区将会是:
C1-0:0,1,2,3
C2-0:4,5,6,7
C2-1:8,9,10
假如我们有两个主题T1,T2,分别有10个分区,最后的分配结果将会是这样:
C1-0:T1(0,1,2,3) T2(0,1,2,3)
C2-0:T1(4,5,6) T2(4,5,6)
C2-1:T1(7,8,9) T2(7,8,9)
RoundRobinAssignor分区分配策略
RoundRobinAssignor策略的原理是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序,然后通过轮询方式逐个将分区以此分配给每个消费者. 使用RoundRobin策略有两个前提条件必须满足:
同一个消费者组里面的所有消费者的num.streams(消费者消费线程数)必须相等;
每个消费者订阅的主题必须相同。
加入按照 hashCode 排序完的topic-partitions组依次为
T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4, T1-7, T1-6, T1-9
我们的消费者线程排序为
C1-0, C1-1, C2-0, C2-1
最后分区分配的结果为:
C1-0 将消费 T1-5, T1-2, T1-6 分区
C1-1 将消费 T1-3, T1-1, T1-9 分区
C2-0 将消费 T1-0, T1-4 分区
C2-1 将消费 T1-8, T1-7 分区
StickyAssignor分区分配策略
Kafka从0.11.x版本开始引入这种分配策略,它主要有两个目的:
分区的分配要尽可能的均匀,分配给消费者者的主题分区数最多相差一个
分区的分配尽可能的与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标。鉴于这两个目的,StickyAssignor策略的具体实现要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多。
假设消费组内有3个消费者
C0、C1、C2
它们都订阅了4个主题:
t0、t1、t2、t3
并且每个主题有2个分区,也就是说整个消费组订阅了
t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1这8个分区
最终的分配结果如下:
消费者C0:t0p0、t1p1、t3p0
消费者C1:t0p1、t2p0、t3p1
消费者C2:t1p0、t2p1
这样初看上去似乎与采用RoundRobinAssignor策略所分配的结果相同
此时假设消费者C1脱离了消费组,那么消费组就会执行再平衡操作,进而消费分区会重新分配。如果采用RoundRobinAssignor策略,那么此时的分配结果如下:
消费者C0:t0p0、t1p0、t2p0、t3p0
消费者C2:t0p1、t1p1、t2p1、t3p1
如分配结果所示,RoundRobinAssignor策略会按照消费者C0和C2进行重新轮询分配。而如果此时使用的是StickyAssignor策略,那么分配结果为:
消费者C0:t0p0、t1p1、t3p0、t2p0
消费者C2:t1p0、t2p1、t0p1、t3p1
可以看到分配结果中保留了上一次分配中对于消费者C0和C2的所有分配结果,并将原来消费者C1的“负担”分配给了剩余的两个消费者C0和C2,最终C0和C2的分配还保持了均衡。
如果发生分区重分配,那么对于同一个分区而言有可能之前的消费者和新指派的消费者不是同一个,对于之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。StickyAssignor策略如同其名称中的“sticky”一样,让分配策略具备一定的“粘性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗以及其它异常情况的发生。
到目前为止所分析的都是消费者的订阅信息都是相同的情况,我们来看一下订阅信息不同的情况下的处理。
举例,同样消费组内有3个消费者:
C0、C1、C2
集群中有3个主题:
t0、t1、t2
这3个主题分别有
1、2,3个分区
也就是说集群中有
t0p0、t1p0、t1p1、t2p0、t2p1、t2p2这6个分区
消费者C0订阅了主题t0
消费者C1订阅了主题t0和t1
消费者C2订阅了主题t0、t1和t2
如果此时采用RoundRobinAssignor策略:
消费者C0:t0p0
消费者C1:t1p0
消费者C2:t1p1、t2p0、t2p1、t2p2
如果此时采用的是StickyAssignor策略:
消费者C0:t0p0
消费者C1:t1p0、t1p1
消费者C2:t2p0、t2p1、t2p2
此时消费者C0脱离了消费组,那么RoundRobinAssignor策略的分配结果为:
消费者C1:t0p0、t1p1
消费者C2:t1p0、t2p0、t2p1、t2p2
StickyAssignor策略,那么分配结果为:
消费者C1:t1p0、t1p1、t0p0
消费者C2:t2p0、t2p1、t2p2
可以看到StickyAssignor策略保留了消费者C1和C2中原有的5个分区的分配:
t1p0、t1p1、t2p0、t2p1、t2p2。
从结果上看StickyAssignor策略比另外两者分配策略而言显得更加的优异,这个策略的代码实现也是异常复杂。
kafka的offset怎么维护
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中。

从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。
额外补充:实际开发场景中在Spark和Flink中,可以自己手动提交kafka的offset,或者是flink两阶段提交自动提交offset。
kafka为什么这么快
- Kafka本身是分布式集群,同时采用分区技术,并发度高。
- 顺序写磁盘
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。
- 零拷贝技术
零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数。通常是说在IO读写过程中。
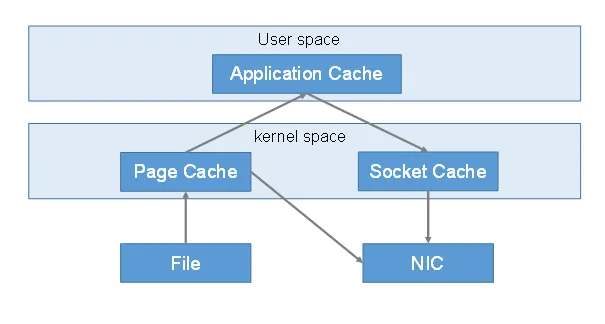
传统IO流程:
第一次:将磁盘文件,读取到操作系统内核缓冲区。
第二次:将内核缓冲区的数据,copy到application应用程序的buffer。
第三步:将application应用程序buffer中的数据,copy到socket网络发送缓冲区(属于操作系统内核的缓冲区)
第四次:将socket buffer的数据,copy到网卡,由网卡进行网络传输。
传统方式,读取磁盘文件并进行网络发送,经过的四次数据copy是非常繁琐的。实际IO读写,需要进行IO中断,需要CPU响应中断(带来上下文切换),尽管后来引入DMA来接管CPU的中断请求,但四次copy是存在“不必要的拷贝”的。
重新思考传统IO方式,会注意到实际上并不需要第二个和第三个数据副本。应用程序除了缓存数据并将其传输回套接字缓冲区之外什么都不做。相反,数据可以直接从读缓冲区传输到套接字缓冲区。
显然,第二次和第三次数据copy 其实在这种场景下没有什么帮助反而带来开销,这也正是零拷贝出现的意义。
所以零拷贝是指读取磁盘文件后,不需要做其他处理,直接用网络发送出去。
Kafka消费能力不足怎么处理
- 如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
- 如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。
kafka事务是怎么实现的
Kafka从0.11版本开始引入了事务支持。事务可以保证Kafka在Exactly Once语义的基础上,生产和消费可以跨分区和会话,要么全部成功,要么全部失败。
Producer事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。
为了管理Transaction,Kafka引入了一个新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态。Transaction Coordinator还负责将事务所有写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
Consumer事务
对于Consumer而言,事务的保证就会相对较弱,尤其是无法保证Commit的信息被精确消费。这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事务的消息可能会出现重启后被删除的情况。
Kafka中的数据是有序的吗
单分区内有序。
多分区,分区与分区间无序。
Kafka可以按照时间消费数据吗
可以,提供的API方法:
KafkaUtil.fetchOffsetsWithTimestamp(topic, sTime, kafkaProp)
Kafka单条日志传输大小
kafka对于消息体的大小默认为单条最大值是1M但是在我们应用场景中, 常常会出现一条消息大于1M,如果不对kafka进行配置。则会出现生产者无法将消息推送到kafka或消费者无法去消费kafka里面的数据, 这时我们就要对kafka进行以下配置:server.properties
replica.fetch.max.bytes: 1048576 broker可复制的消息的最大字节数, 默认为1M
message.max.bytes: 1000012 kafka 会接收单个消息size的最大限制, 默认为1M左右message.max.bytes必须小于等于replica.fetch.max.bytes,否则就会导致replica之间数据同步失败Kafka参数优化
Broker参数配置(server.properties)
1、日志保留策略配置
# 保留三天,也可以更短 (log.cleaner.delete.retention.ms)
log.retention.hours=722、Replica相关配置
default.replication.factor:1 默认副本1个3、网络通信延时
replica.socket.timeout.ms:30000 #当集群之间网络不稳定时,调大该参数
replica.lag.time.max.ms= 600000# 如果网络不好,或者kafka集群压力较大,会出现副本丢失,然后会频繁复制副本,导致集群压力更大,此时可以调大该参数。Producer优化(producer.properties)
compression.type:none gzip snappy lz4
#默认发送不进行压缩,推荐配置一种适合的压缩算法,可以大幅度的减缓网络压力和Broker的存储压力。Kafka内存调整(kafka-server-start.sh)
默认内存1个G,生产环境尽量不要超过6个G。
export KAFKA_HEAP_OPTS="-Xms4g -Xmx4g"Kafka适合以下应用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer。
- 消息系统:解耦生产者和消费者、缓存消息等。
- 用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库。
- 运营指标:kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
- 流式处理:比如spark和flink。
Exactly Once语义
将服务器的ACK级别设置为-1,可以保证Producer到Server之间不会丢失数据,即At Least Once语义。相对的,将服务器ACK级别设置为0,可以保证生产者每条消息只会被发送一次,即At Most Once语义。
At Least Once可以保证数据不丢失,但是不能保证数据不重复;
相对的,At Most Once可以保证数据不重复,但是不能保证数据不丢失。
但是,对于一些非常重要的信息,比如说交易数据,下游数据消费者要求数据既不重复也不丢失,即Exactly Once语义。在0.11版本以前的Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。
0.11版本的Kafka,引入了一项重大特性:幂等性。
开启幂等性enable.idempotence=true。
所谓的幂等性就是指Producer不论向Server发送多少次重复数据,Server端都只会持久化一条。幂等性结合At Least Once语义,就构成了Kafka的Exactly Once语义。即:
At Least Once + 幂等性 = Exactly Once
Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条。
但是PID重启就会变化,同时不同的Partition也具有不同主键,所以幂等性无法保证跨分区跨会话的Exactly Once。
补充,在流式计算中怎么Exactly Once语义?以flink为例
- souce:使用执行ExactlyOnce的数据源,比如kafka等
内部使用FlinkKafakConsumer,并开启CheckPoint,偏移量会保存到StateBackend中,并且默认会将偏移量写入到topic中去,即_consumer_offsets Flink设置CheckepointingModel.EXACTLY_ONCE
- sink
存储系统支持覆盖也即幂等性:如Redis,Hbase,ES等
存储系统不支持覆:需要支持事务(预写式日志或者两阶段提交),两阶段提交可参考Flink集成的kafka sink的实现。
----发布/订阅消息)
)






)


将消息数据写入Kafka系统--生产者【异步发送、同步发送、单线程发送、多线程发送、配置生产者属性、自定义序列化、自定义主题分区】)
)
 MySQL常用命令)





