前言
在 ChatGPT 出现之时,社区内也出现过 把 React 官方文档投喂给它 ,然后对它进行提问的实践。但是,由于每次 ChatGPT 对话能接受的文本内容对应的 Token 是有上限的,所以这种使用方式存在一定的手动操作成本和不能复用的问题。
而 Documate 的出现则是通过工具链的集成,仅需使用 CLI 提供的命令和部署服务端的代码,就可以很轻松地实现上述的数据投喂模型 + 提问 ChatGPT 过程的自动化,让你的文档(VitePress、Docusaurus、Docsify)站点具备 AI 对话功能。
Documate 的官网文档对如何使用它进行现有文档站点的接入介绍的很为详尽,并且其作者(月影)也专门写了【黑科技】让你的 VitePress 文档站支持 AI 对话能力文章介绍,对接入 Documate 感兴趣的同学可以自行阅读文档或文章。
相信很多同学和我一样,对如何基于文档的内容实现 AI Chat 留有疑问,那么接下来,本文将围绕 Documate 的实现原理分别展开介绍:
- Documate 运行机制
- Documate 服务端
一、Documate 运行机制
Documate 主要由 2 部分构成,Documate CLI 和服务端(Backend)接口实现,其中 Documate CLI 主要职责是获取本地文档过程的文档和构造指定结构的文档数据,最终上传数据到 upload 接口,而服务端主要职责是提供 upload 和 ask 接口,它们分别的作用:
upload接口,接收来自 CLI 上传的文档数据,对数据进行 Token 化、分片入库等操作ask接口,接收来自文档站点的提问内容,校验内容合法性、生成内容的矢量坐标,基于所有文档进行矢量搜索、进行 Chat 提问获取结果并返回等操作
整体实现机制如下图所示:
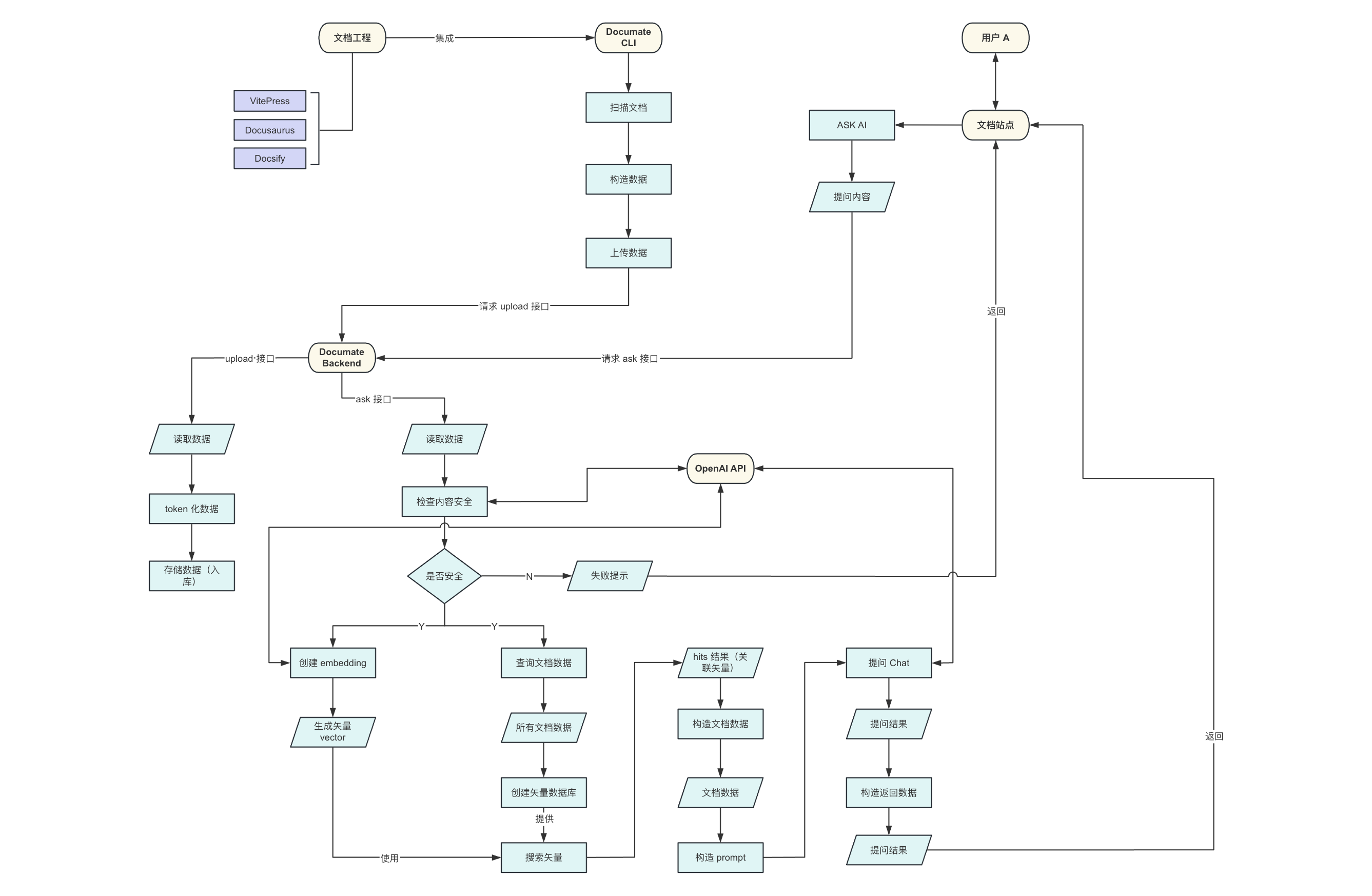
其中,关于 Documate CLI 主要支持了 init 和 upload 等 2 个命令,init 负责向文档工程注入 Documate 运行的基础工程配置,upload 负责上传文档工程的文档内容到服务端,2 者的实现并不复杂,有兴趣的同学可以自行了解。
相比较 CLI,在 Documate 的服务端实现的一系列能力是支持文档内容对话的关键技术点,那这些能力又是如何通过代码实现的?下面,我们来分别从代码层面深入认识下 Documate 服务端的各个能力的实现。
二、Documate 服务端
Documate 服务端主要负责接收并存储 documate upload 命令上传的文档内容、根据对话的提问内容返回与之关联的回答:

其中,后者需要使用 OpenAI 提供的 Text Embeddings 来实现 AI 对话的功能,所以,我们先来对 OpenAI Text Embeddings 建立一个基础的认知。
2.1 OpenAI Text Embeddings
在 OpenAI 的开发者平台 提供了很多功能的 API 给开发者调用:
- Text generation,生成文本和调用函数
- Prompt engineering,Prompt 的最佳工程实践
- Embeddings,搜索、分类和比较文本
- Speech to text,语音转文本
- Image generation,使用 DALL·E 生成或者操作图像
- Fine-tuning,为应用定制模型
- Text to speech,将文本转为逼真的语音
- Vision,使用 GPT-4 理解图像
基于文档内容的 AI 对话的实现本质是根据关键词搜索得到答案,所以需要使用到 Embeddings,Embedding 主要用于衡量文本字符串之间的关联性,一个 Embedding 是由浮点数字构成的矢量数组,例如 [0.938293, 0.284951, 0.348264, 0.948276, 0.564720]。2 个矢量之间的距离表示它们的关联性。距离小表示它们之间的关联性高,反之关联性低。
2.2 文档内容存储
文档内容的存储主要分为 2 个步骤:
1、根据模型每次能接受的 Token 最大长度去对内容进行分片 chunks
OpenAI 的模型调用所能接收的 Token 的长度是有限的,对应的 text-embedding-ada-002 模型可接收的 Token 最大长度是 1536。所以,在接收到 CLI 上传的文档内容后,需要根据 Token 的最大长度 1536 来对文档内容进行分片:
const tokenizer = require('gpt-3-encoder');
// Split the page content into chunks base on the MAX_TOKEN_PER_CHUNK
function getContentChunks(content) {// GPT-2 and GPT-3 use byte pair encoding to turn text into a series of integers to feed into the model.const encoded = tokenizer.encode(content);const tokenChunks = encoded.reduce((acc, token) => (acc[acc.length - 1].length < MAX_TOKEN_PER_CHUNK? acc[acc.length - 1].push(token): acc.push([token]),acc),[[]],);return tokenChunks.map(tokens => tokenizer.decode(tokens));
}
首先,会先使用 gpt-3-encoder 来对文档内容进行 Byte Pair Encoding,将文档从文本形式转成一系列数字,从而用于后续投喂(Feed)给模型。其中, BPE 算法 的实现:
- 把文本内容拆分成一个个字符,计算字符出现频率
- 合并相邻重复出现的字符和对应的出现频率
- 对最终拆分的字符编码成数字,也就是 Token 的值,然后构造字符到数字映射的一个词汇表
- 根据词汇表将原有的文本内容转为对应的 Token 表示
由于 BPE 编码后的结果 encoded 是一个 Token 数组,且模型每次能投喂是有最大长度的限制,所以根据 Token 最大长度进行分片,也就是代码中的 acc,acc 初始值是一个二维数组,每个值是一个 Token,每个元素数组主要用于存储模型最大 Token 限制下的数据,即将一个大的 Token 分片成模型允许传入的小 Token。
对文档内容进行分片的目的是用于后续将文档内容投喂(Feed)给模型的时候是有效(不会超出 Token 最大长度)和连续的。
2、构造指定的数据结构 ChunkItem 存入数据库中,ChunkItem 数据结构
因为,将文档的所有内容全部投喂给模型是有成本(Token 计费)并且收益低(问答内容关联性低),所以,需要在提问的环节通过矢量数据库查询的方式,查出关联的文档内容,然后再将对应的文档内容投喂给模型,模型根据对关联文档上下文和问题给出合理的回答。
那么,在前面根据 BPE 生成的 Token 和分片生成的基础上,需要将该结果按指定的数据结构(路径、标题等)存入数据库中,用于后续提问的时候查询矢量数据库:
const aircode = require('aircode');
const PagesTable = aircode.db.table('pages');// 根据 BPE 和模型的 Token 上限限制去划分 chunk
const chunks = getContentChunks(content);
// 构造出存到数据库中的数据结构
const pagesToSave = chunks.map((chunk, index) => ({project,// 文档文件路径path,title,// 文件内容生成的 hash 值checksum,chunkIndex: index,// 内容content: chunk,embedding: null,
}))// Save the result to database
for (let i = 0; i < pagesToSave.length; i += 100) {await PagesTable.save(pagesToSave.slice(i, i + 100));
}
这里会使用到 AirCode 提供的表操作的 PagesTable.save API,用于将构造好的数据入库。
2.3 根据提问进行 AI 对话
OpenAI 要求输入的内容是需要符合它们规定的内容政策的,所以需要先对输入的问题进行内容检查,OpenAI 也提供相应的 API 用于检查内容安全,而 OpenAI 的 API 调用可以通过 OpenAI Node 来实现:
const OpenAI = require('openai');// 创建 OpenAI 的实例
const openai = new OpenAI({apiKey: process.env.OPENAI_API_KEY,
});// 提问内容
const question = params.question.trim();
// https://platform.openai.com/docs/api-reference/moderations
const { results: moderationRes } = await openai.moderations.create({input: question,
});
if (moderationRes[0].flagged) {console.log('The user input contains flagged content.', moderationRes[0].categories);context.status(403);return {error: 'Question input didn\'t meet the moderation criteria.',categories: moderationRes[0].categories,};
}
如果,返回的结果 moderationsRes[0].flagged 则视为不符合,标识为错误的请求。反之符合,接着使用 Embeddings 来获取提问内容所对应的矢量坐标:
// https://platform.openai.com/docs/api-reference/embeddings/object
const { data: [ { embedding }] } = await openai.embeddings.create({model: 'text-embedding-ada-002',input: question.replace(/\n/g, ' '),
});
那么,有了矢量坐标后,我们需要用先前存储到数据库的分片文本创建矢量数据库,这可以使用 Orama 完成,它提供了全文和矢量搜索的能力。
首先,需要先从数据库中查询出所有的文档数据:
const { project = 'default' } = params;
const pages = await PagesTable.where({ project }).projection({ path: 1, title: 1, content: 1, embedding: 1, _id: 0 }).find();
然后,通过 Orama 提供的 create 方法初始化一个矢量数据库 memDB,并且将文档内容 pages 插入到数据库中:
const memDB = await create({// 建立好索引的 `schema`schema: {path: 'string',title: 'string',content: 'string',embedding: 'vector[1536]',},
});
await insertMultiple(memDB, pages);
有了文档内容对应的矢量数据库后,我们就可以用前面 Emdeedings 根据提问内容生成的矢量坐标进行搜索,使用 Orama 提供的 searchVector 进行搜索:
const { hits } = await searchVector(memDB, {vector: embedding,property: 'embedding',similarity: 0.8, // Minimum similarity. Defaults to `0.8`limit: 10, // Defaults to `10`offset: 0, // Defaults to `0`
});
那么,为什么使用的是矢量搜索而不是文本搜索? 因为,矢量搜索的作用是为了搜索到和文本对应的矢量位置相近的内容,用于生成上下文本 GPT 整理最终的回答。
其中 hits 的数据结构:
{count: 1,elapsed: {raw: 25000,formatted: '25ms',},hits: [{id: '1-19238',score: 0.812383129,document: {title: 'The Prestige',embedding: [0.938293, 0.284951, 0.348264, 0.948276, 0.564720],}}]
}
由于,先前将文档内容根据 Embeddings 的 Token 最大长度分片进行存储,所以,这里需要将 hits 中的数据获取的内容组合起来:
let tokenCount = 0;
let contextSections = '';for (let i = 0; i < hits.length; i += 1) {const { content } = hits[i].document;// 注意 encode,用于组合分片const encoded = tokenizer.encode(content);tokenCount += encoded.length;// 判断是否达到 token 上限if (tokenCount >= MAX_CONTEXT_TOKEN && contextSections !== '') {break;}contextSections += `${content.trim()}\n---\n`;
}
到这里,我们已经有了问题和问题关联的内容,可以用它们构造一个 Prompt 用于后续 AI 对话使用:
const prompt = `You are a very kindly assistant who loves to help people. Given the following sections from documatation, answer the question using only that information, outputted in markdown format. If you are unsure and the answer is not explicitly written in the documentation, say "Sorry, I don't know how to help with that." Always trying to anwser in the spoken language of the questioner.Context sections:
${contextSections}Question:
${question}Answer as markdown (including related code snippets if available):`
下面,我们就可以调用 OpenAI 的 API 进行 AI 对话:
const messages = [{role: 'user',content: prompt,
}];const response = await openai.chat.completions.create({messages,model: 'gpt-3.5-turbo',max_tokens: 512,temperature: 0.4,stream: true,
})
其中,response 是一个 OpenAI API 调用返回的自定义数据结构的 Streaming Responses,直接将 response 返回给 ask 接口请求方肯定是不合理的(请求方只需要拿到答案)。那么,这里可以使用这里可以使用 Vercel 团队实现的 ai 提供的 OpenAIStream 函数来完成:
const { OpenAIStream } = require('ai');const stream = OpenAIStream(response);
return stream;
OpenAIStream 会自动将 OpenAI Completions 返回的结果解析成可以正常读取的 Streaming Resonsese,如果使用的是 AirCode 则可以直接返回 stream,如果使用的是普通的 Node Server,可以进一步使用 ai 提供的 streamToResponse 函数来将 stream 转为 ServerResponse 对象:
const { OpenAIStream, streamToResponse } = require('ai');const stream = OpenAIStream(response);
streamToResponse(stream);
结语
通过学习 Documate 内部的实现原理,我们可以知道了如何从实际的问题出发,结合使用 OpenAI API 提供的模型解决问题。在这个基础上,我们也可以去做别的场景探索,让 AI 成为现在或者将来我们解决问题的一种技术手段或尝试,而不是仅仅局限于会使用 ChatGPT 提问和获取答案。
我是五柳,喜欢创新、捣鼓源码,专注于源码(Vue 3、Vite)、前端工程化、跨端等技术学习和分享,欢迎关注我的微信公众号 Code center 或 GitHub。
)


)





![[力扣 Hot100]Day23 反转链表](http://pic.xiahunao.cn/[力扣 Hot100]Day23 反转链表)


)
【超详细】)
索引(3)索引失效与索引区分度)




